MapReduce 案例-统计每台智能音箱设备内容播放时长
需求
统计每台智能音箱设备内容播放时长
原始日志格式
日志id 设备id appkey(合作硬件厂商) IP 自有内容时长(s) 第三方内容时长(s) 网络状态码
001 001577c3 kar890809 120.111.222.99 1116 865 200
输出结果
设备id 自有内容时长(s) 第三方内容时长(s) 总时长
001577c3 11160 9540 20700
整体思路分析
Map 阶段:
- 读取一行文本数据,按照制表符切分
- 抽取出自有内容时长,第三方内容时长,设备 id
- 输出:key -> 设备 id,value:封装一个 bean 对象,bean 对象携带自有内容时长,第三方内容、设备id
- 自定义bean对象作为 value 输出,需要实现 writable序列化接口
Reduce阶段 - 在 reduce 方法中直接遍历迭代器,累加时长然后输出即可
生成测试数据
@Test
public void generateData() throws IOException {
String path = "D:\\Code\\Hadoop\\wordCount\\datalog.txt";
File file = new File(path);
if (file.exists()) { // 如果存在则删除
file.delete();
}
BufferedWriter bos = new BufferedWriter(new FileWriter("D:\\Code\\Hadoop\\wordCount\\datalog.txt"));
Random random = new Random();
for (int i = 1; i <= 3000000; i++) {
String driverId = generateWord(4);
String appKey = generateWord(5);
String ip = getRandomIp();
int selfDuration = random.nextInt(1000); // 自有内容时长
int thirdPartDuration = random.nextInt(1000); // 第三方内容时长
int status = 200;
String line = i + "\t" + driverId + "\t" + appKey + "\t" + ip + "\t" + selfDuration + "\t" + thirdPartDuration + "\t" + status + "\n";
bos.write(line);
}
bos.close();
System.out.println("生成数据文件成功!");
}
/**
* 生成随机用户名
*/
public static String generateWord(Integer count) {
StringBuffer str = new StringBuffer();
for (int i = 1; i <= count; i++) {
str.append((char) (Math.random() * 5 + 'a'));
}
return str.toString();
}
/**
* 获取一个随机IP
*/
public static String getRandomIp() {
// 指定 IP 范围
int[][] range = {
{607649792, 608174079}, // 36.56.0.0-36.63.255.255
{1038614528, 1039007743}, // 61.232.0.0-61.237.255.255
{1783627776, 1784676351}, // 106.80.0.0-106.95.255.255
{2035023872, 2035154943}, // 121.76.0.0-121.77.255.255
{2078801920, 2079064063}, // 123.232.0.0-123.235.255.255
{-1950089216, -1948778497}, // 139.196.0.0-139.215.255.255
{-1425539072, -1425014785}, // 171.8.0.0-171.15.255.255
{-1236271104, -1235419137}, // 182.80.0.0-182.92.255.255
{-770113536, -768606209}, // 210.25.0.0-210.47.255.255
{-569376768, -564133889}, // 222.16.0.0-222.95.255.255
};
Random random = new Random();
int index = random.nextInt(10);
String ip = num2ip(range[index][0] + random.nextInt(range[index][1] - range[index][0]));
return ip;
}
/*
* 将十进制转换成IP地址
*/
public static String num2ip(int ip) {
int[] b = new int[4];
b[0] = (ip >> 24) & 0xff;
b[1] = (ip >> 16) & 0xff;
b[2] = (ip >> 8) & 0xff;
b[3] = ip & 0xff;
// 拼接 IP
String x = b[0] + "." + b[1] + "." + b[2] + "." + b[3];
return x;
}
SpeakBean 实体
package com.orginly.mapreduce.speak;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* map输出kv的value类型 需要实现 Writable 序列化接口
*/
public class SpeakBean implements Writable {
private String driverId; // 设备ID
private Long selfDuration; // 自有内容时长
private Long thirdPartDuration; // 第三方内容时长
private Long totalDuration; // 总时长
// 空参(必须)
public SpeakBean() {
}
// 有参构造
public SpeakBean(String driverId, Long selfDuration, Long thirdPartDuration) {
this.driverId = driverId;
this.selfDuration = selfDuration;
this.thirdPartDuration = thirdPartDuration;
this.totalDuration = selfDuration + thirdPartDuration; // 总时长 = 自有时长 + 第三方时长
}
// 序列化方法:将内容输出到网络或写入文本中
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(driverId);
dataOutput.writeLong(selfDuration);
dataOutput.writeLong(thirdPartDuration);
dataOutput.writeLong(totalDuration);
}
// 反序列化方法
@Override
public void readFields(DataInput dataInput) throws IOException {
driverId = dataInput.readUTF();
selfDuration = dataInput.readLong();
thirdPartDuration = dataInput.readLong();
totalDuration = dataInput.readLong();
}
@Override
public String toString() {
return "selfDuration:" + selfDuration + "\t" + "thirdPartDuration:" + thirdPartDuration + "\t" + "totalDuration:" + totalDuration;
}
public Long getSelfDuration() {
return selfDuration;
}
public Long getThirdPartDuration() {
return thirdPartDuration;
}
}
Mapper
package com.orginly.mapreduce.speak;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Mapper的泛型四个参数,两对kv
* 第一对kv:输入参数 key=>一行文本的偏移量 value=>一行文本内容
* 第二对kv:输出参数 key=>map输出的key类型 v:map输出的value类型
*/
public class SpeakMapper extends Mapper<LongWritable, Text, Text, SpeakBean> {
private Text device_id = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, SpeakBean>.Context context) throws IOException, InterruptedException {
// 接收到一行数据转为 String 类型
String str = value.toString();
// 按照 \t 进行分隔得到设备id、自有时长、第三方时长
String[] fields = str.split("\t");
String selfDuration = fields[fields.length - 3];
String thIrdPartDuration = fields[fields.length - 2];
String driverId = fields[1];
// 输出 <设备id,bean对象>
SpeakBean speakBean = new SpeakBean(driverId, Long.parseLong(selfDuration), Long.parseLong(thIrdPartDuration));
device_id.set(driverId);
context.write(device_id, speakBean);
}
}
Reduce
package com.orginly.mapreduce.speak;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 继承 Reducer 类
* 有四个泛型,两对 kv
* 第一对kv要与 Mapper 输出类型一致 (Text,IntWritable)
* 第二对kv自己设计决定输出结果数据是什么类型
*/
public class SpeakReduce extends Reducer<Text, SpeakBean, Text, SpeakBean> {
/**
* @param key map输出的某一个key, driverId
* @param values map输出的kv对中相同key的value的一个集合
* @param context
*/
@Override
protected void reduce(Text key, Iterable<SpeakBean> values, Reducer<Text, SpeakBean, Text, SpeakBean>.Context context) throws IOException, InterruptedException {
// 每一次调用reduce 方法都是 key 相同的一个集合
Long selfDuration = 0L;
Long thirdPartDuration = 0L;
for (SpeakBean speak : values) { // 累加
selfDuration += speak.getSelfDuration();
thirdPartDuration += speak.getThirdPartDuration();
}
// 封装为一个 bean 数据
SpeakBean speakBean = new SpeakBean(key.toString(), selfDuration, thirdPartDuration);
// 输出
context.write(key, speakBean);
}
}
Driver
package com.orginly.mapreduce.speak;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class SpeakDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1. 获取配置文件对象,获取 job 对象实例
Configuration entries = new Configuration();
Job job = Job.getInstance(entries, "speakDriver");
// 2. 指定程序 jar 的本地路径
job.setJarByClass(SpeakDriver.class);
// 3. 指定 Mapper / Reduce类
job.setMapperClass(SpeakMapper.class);
job.setReducerClass(SpeakReduce.class);
// 4. 指定 Mapper 输出的 kv 数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(SpeakBean.class);
// 5. 指定最终输出的 kv 数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(SpeakBean.class);
// 6. 指定 job 处理的原始数据路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 7. 指定 job 输出结果路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 8. 提交 job 作业
long start_time = System.currentTimeMillis();
boolean flag = job.waitForCompletion(true);
long end_time = System.currentTimeMillis();
System.out.println("运行时间" + (end_time - start_time) + "ms");
System.exit(flag ? 0 : 1);
}
}
验证程序
本地验证
使用 IDEA 运行 Drive 中的 main() 方法
如果出现其他异常请查看 https://www.cnblogs.com/orginly/p/15392871.html
- 先自动运行一次,此时会 args 下标异常

- 编辑运行配置添加参数
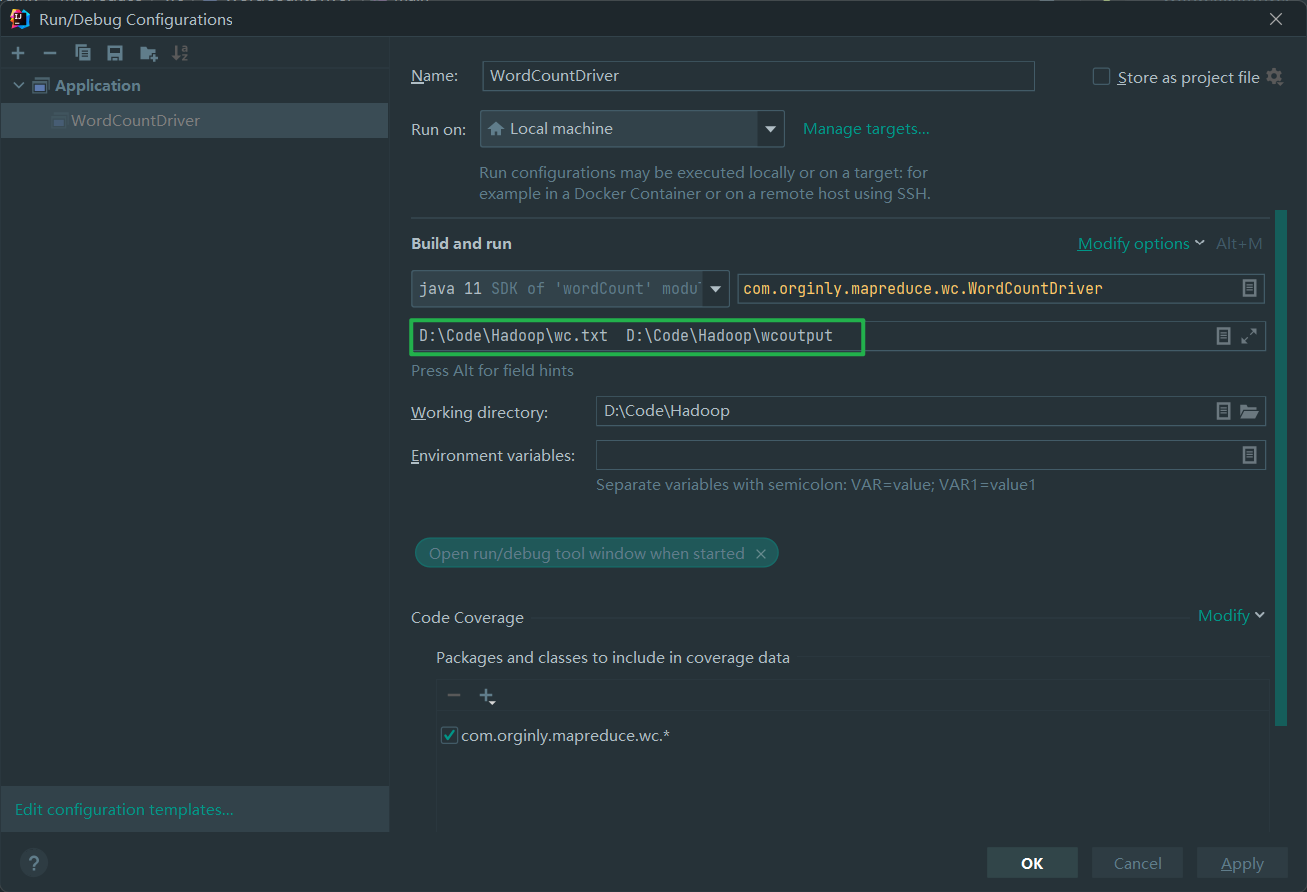
- 重新运行
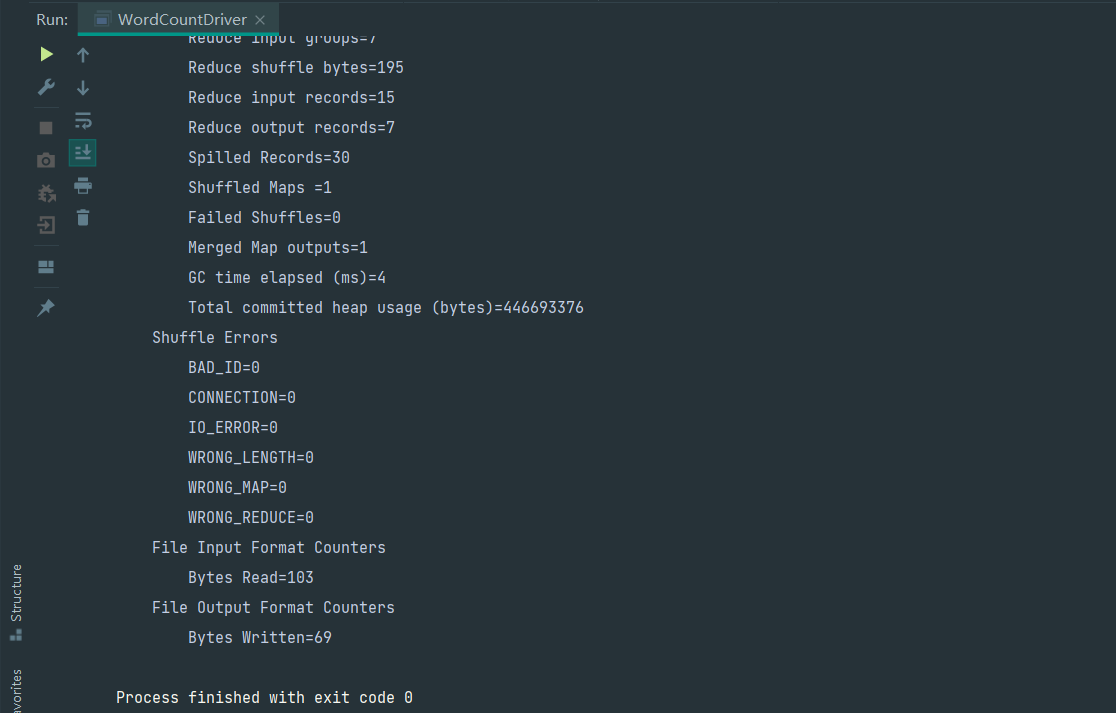
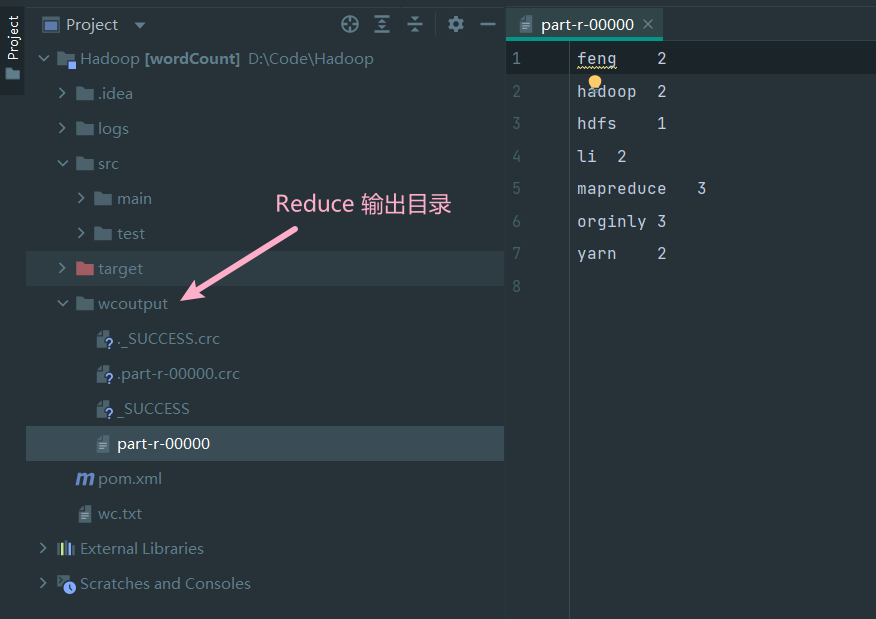
Yarn 集群验证
- 把程序打成 jar 包,改名为 wordCount.jar 上传到 Hadoop 集群
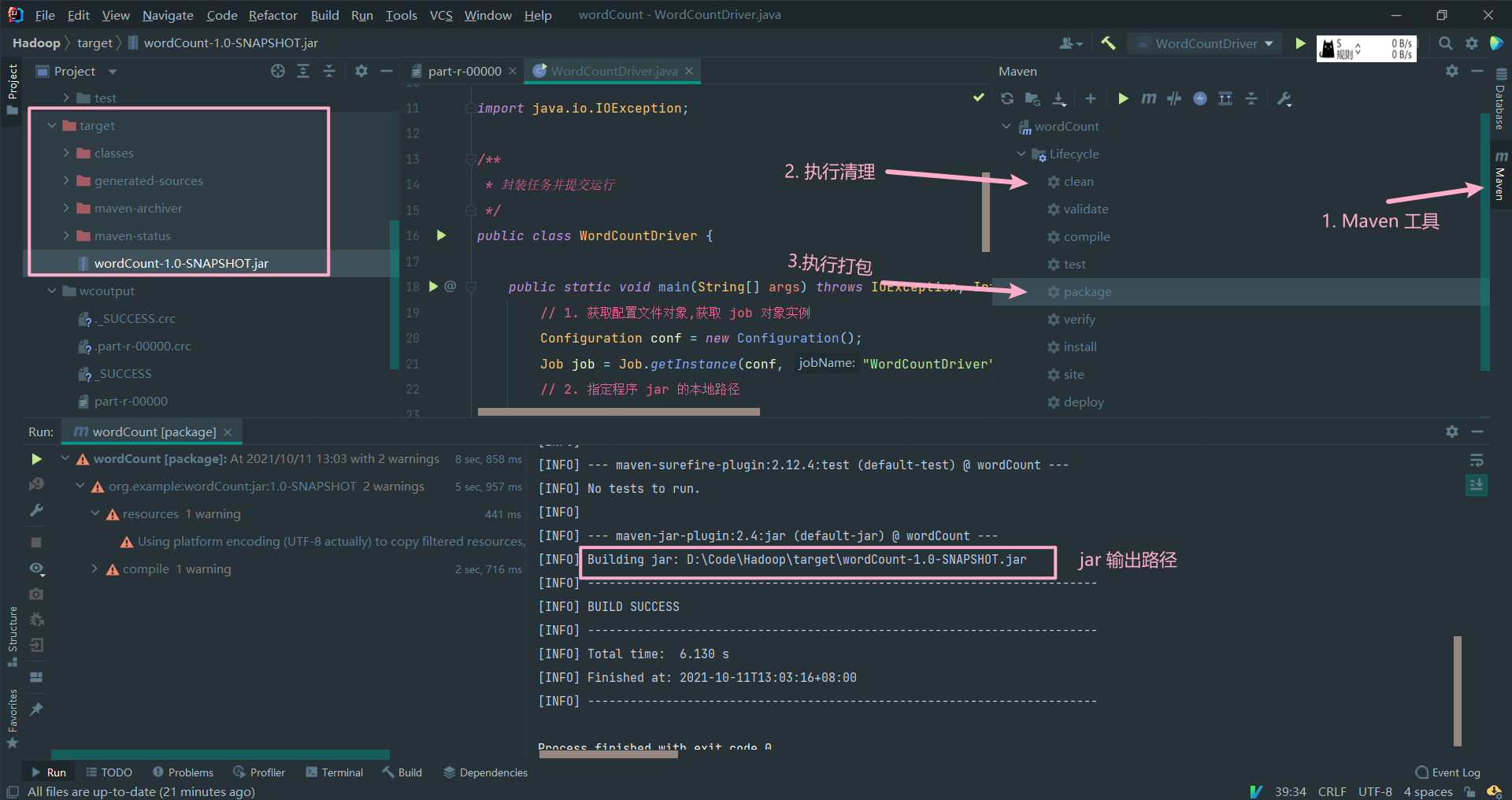
# 上传到服务器
rz
# 重命名
mv wordCount-1.0-SNAPSHOT.jar wordCount.jar
- 启动 Hadoop 集群(Hdfs,Yarn)
- 使用 Hadoop 命令提交任务运行
因为是集群,源文件不能存放在本地目录,需要上传至 HFDS 进行处理
hadoop jar wordCount.jar com.orginly.mapreduce.speak.SpeakDriver /mapReduce/datalog.txt /speakoutput
执行成功
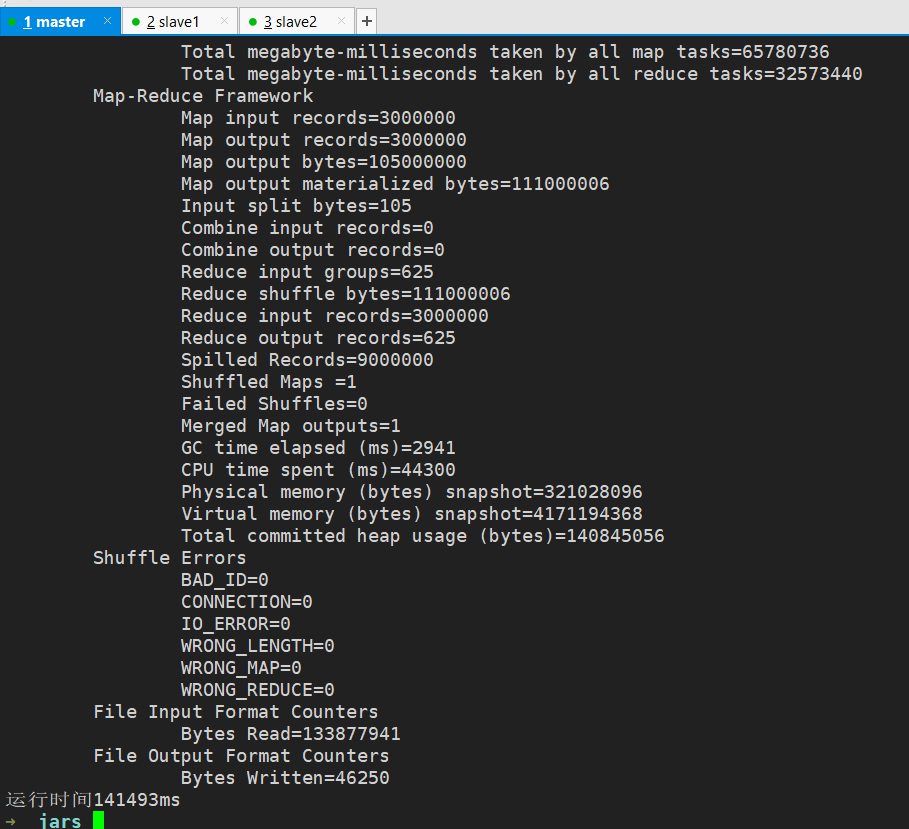
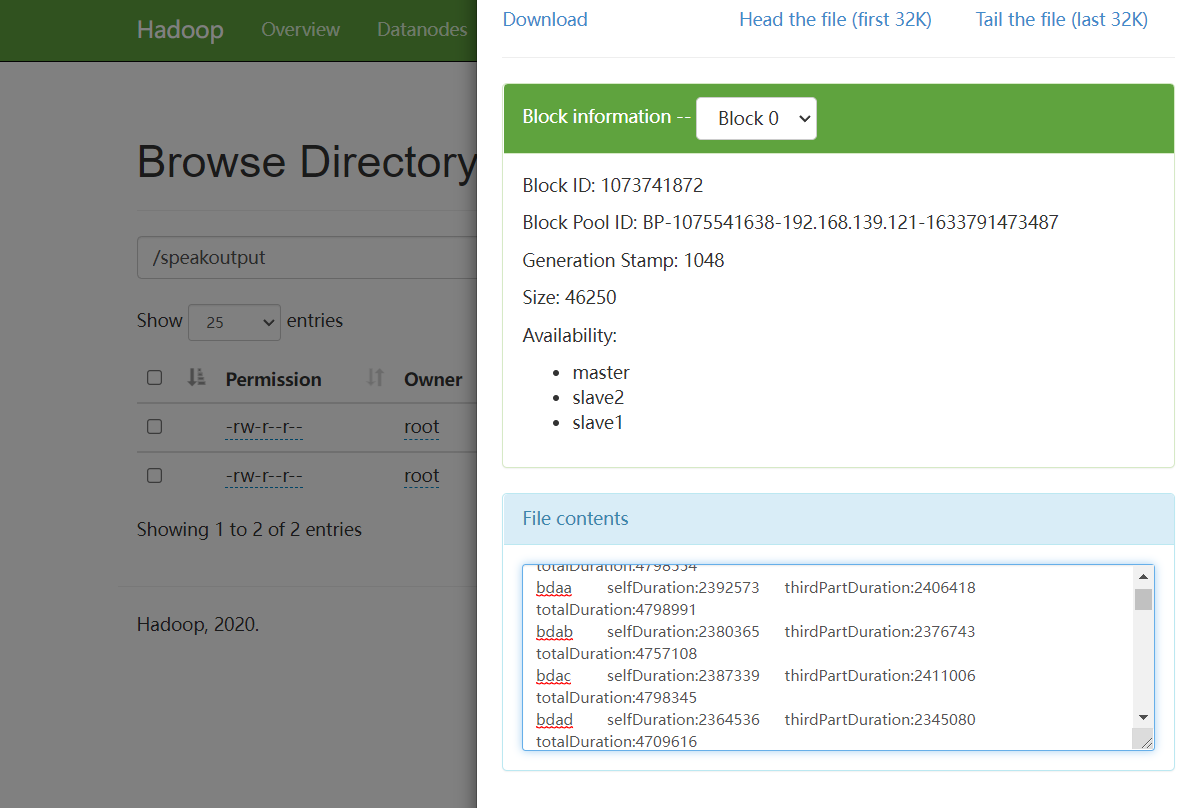
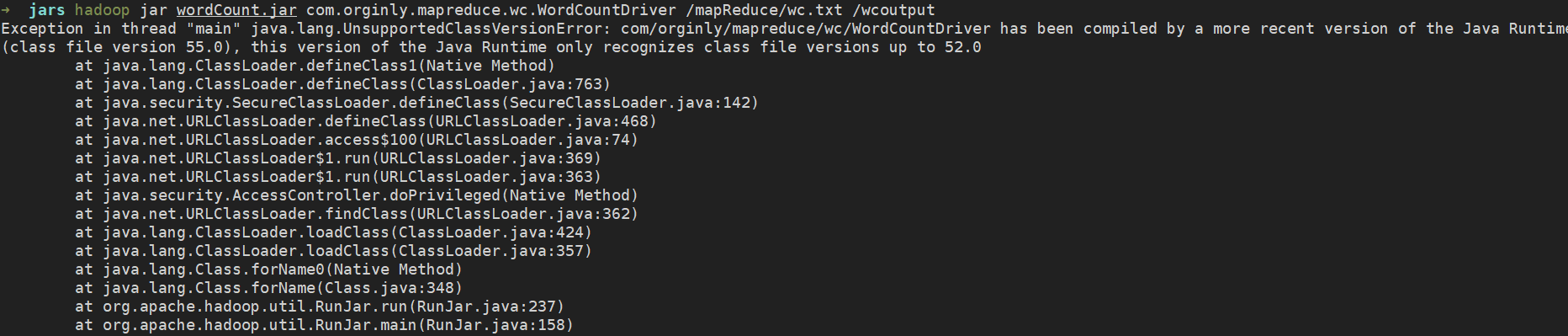
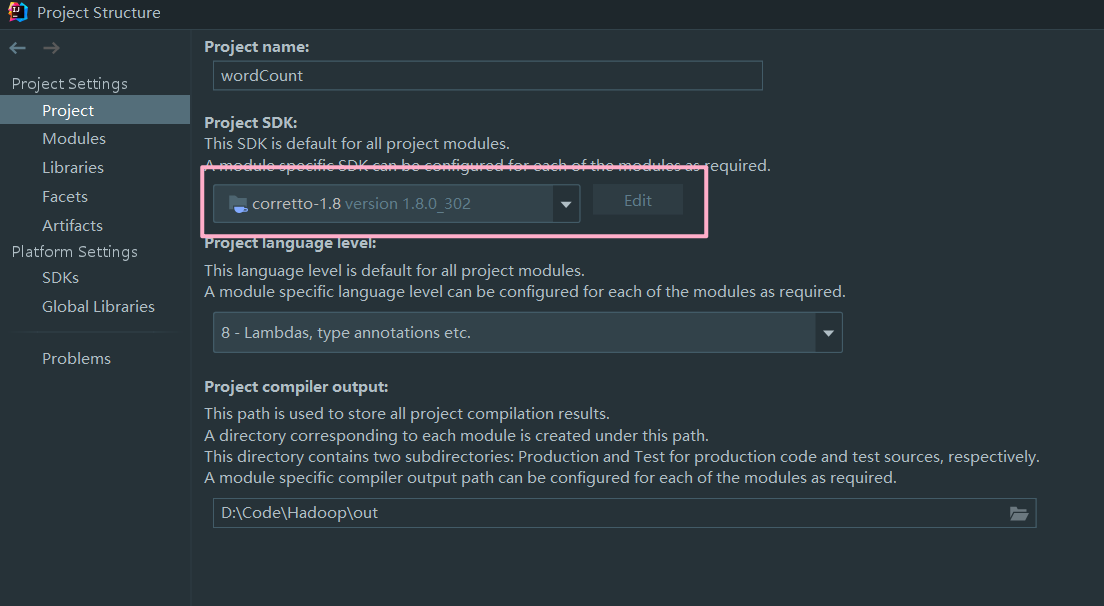
如果执行命令时出现版本过低提示,请安装服务器所使用的 jdk 版本进行 jar 的打包

 浙公网安备 33010602011771号
浙公网安备 33010602011771号