MapReduce 实现统计单数出现次数
工程配置
- 在 windows 中配置 hadoop 及环境变量 HADOOP_
下载 winutils.exe 放入 bin目录中
https://github.com/cdarlint/winutils - 创建 maven 工程 引入依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j</artifactId>
<version>2.14.1</version>
</dependency>
- 编写 log4j 配置文件
参考:https://www.cnblogs.com/orginly/p/14847470.html
整体思路
仿照源码
Map 阶段
- map()方法中把传入的数据转为 String 类型
- 根据空格切分出单词
- 输出<单词,1>
package com.orginly.mapreduce.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 单词记数
* 继承 Mapper 类
* Mapper 类的泛型参数共4个 两个key value
* 第一对kv:map输入参数类型 (LongWritable, Text 文本偏移量,一行文本内容)
* 第二对kv:map输出参数类型 (Text, IntWritable 单词,1)
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// 提升为成员变量避免每次执行 map 方法时都创建一次对象
private final Text word = new Text();
private final IntWritable intWritable = new IntWritable(1);
/**
* map 方法的输入参数,一行文本就调用一次 map 方法
*
* @param key 文本偏移量
* @param value 一行文本内容
* @param context
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 1. 接收到文本内容,转为String 类型
String str = value.toString();
// 2. 按照空格进行拆分单词
String[] words = str.split(" ");
// 3. 输出<单词,1>
for (String s : words) {
word.set(s);
context.write(word, intWritable);
}
}
}
Reduce 阶段
- 总各个key(单词)的个数,遍历 value 数据进行累加
- 输出 key 的总数
package com.orginly.mapreduce.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 继承 Reducer 类
* 有四个泛型,两对 kv
* 第一对kv要与 Mapper 输出类型一致 (Text,IntWritable)
* 第二对kv自己设计决定输出结果数据是什么类型
*/
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable total = new IntWritable();
/**
* 假设 map 方法 执行三次得到:hello,1 hello,1 hello,1
* reduce 的 key => hello, values => <1,1,1>
* <p>
* 假设 map 方法得到 hello,1 hello,1 hello,1 hadoop,1 reduce,1 hadoop,1
* reduce 方法何时调用:一组 key 相同的 kv 中 value 组成然后调用一次 reduce
* 第一次:key => hello, values => <1,1,1>
* 第一次:key => hadoop, values => <1,1>
* 第三次:key => reduce, values => <1>
*
* @param key 方法输出的key本案例中就是单词
* @param values 一组key相同的kv的value组成的集合
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 遍历 key 对应的 values 进行累加
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
// 直接输出当前 key 对应的 sum 值,结果就是单词出现的总次数
total.set(sum);
context.write(key,total);
}
}
Driver
- 获取配置文件对象,获取 job 对象实例
- 指定程序 jar 的本地路径
- 指定 Mapper / Reduce类
- 指定 Mapper 输出的 kv 数据类型
- 指定 最终输出的 kv 数据类型
- 指定 job 处理的原始数据路径
- 指定 job 输出结果路径
- 提交作业
package com.orginly.mapreduce.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 封装任务并提交运行
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1. 获取配置文件对象,获取 job 对象实例
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "WordCountDriver");
// 2. 指定程序 jar 的本地路径
job.setJarByClass(WordCountDriver.class);
// 3. 指定 Mapper / Reduce类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
// 4. 指定 Mapper 输出的 kv 数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 5. 指定最终输出的 kv 数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6. 指定 job 处理的原始数据路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 7. 指定 job 输出结果路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 8. 提交作业
boolean flag = job.waitForCompletion(true);// 等待完成 true为完成
System.exit(flag ? 0 : 1);
}
}
验证程序
本地验证
使用 IDEA 运行 Drive 中的 main() 方法
如果出现其他异常请查看 https://www.cnblogs.com/orginly/p/15392871.html
- 先自动运行一次,此时会 args 下标异常

- 编辑运行配置添加参数
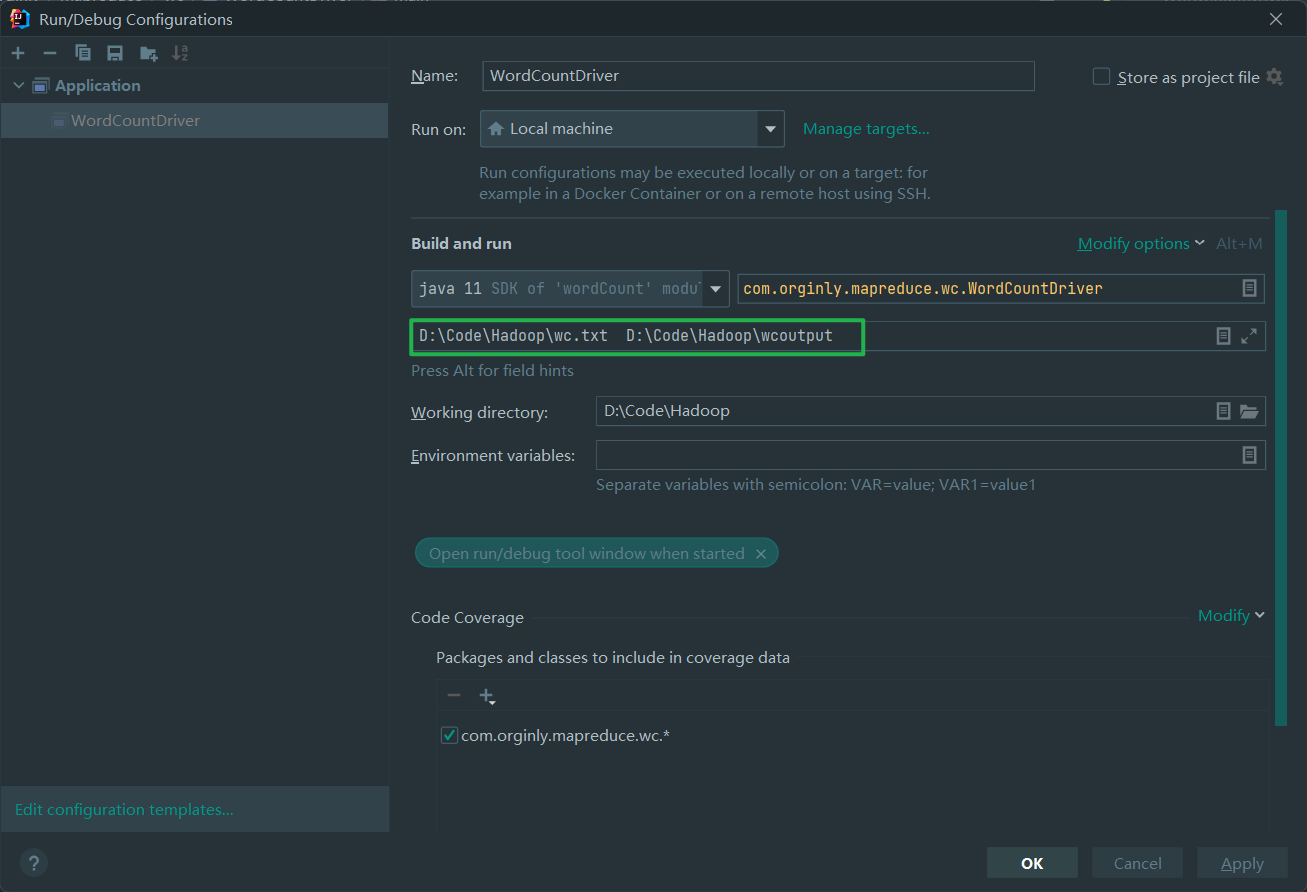
- 重新运行
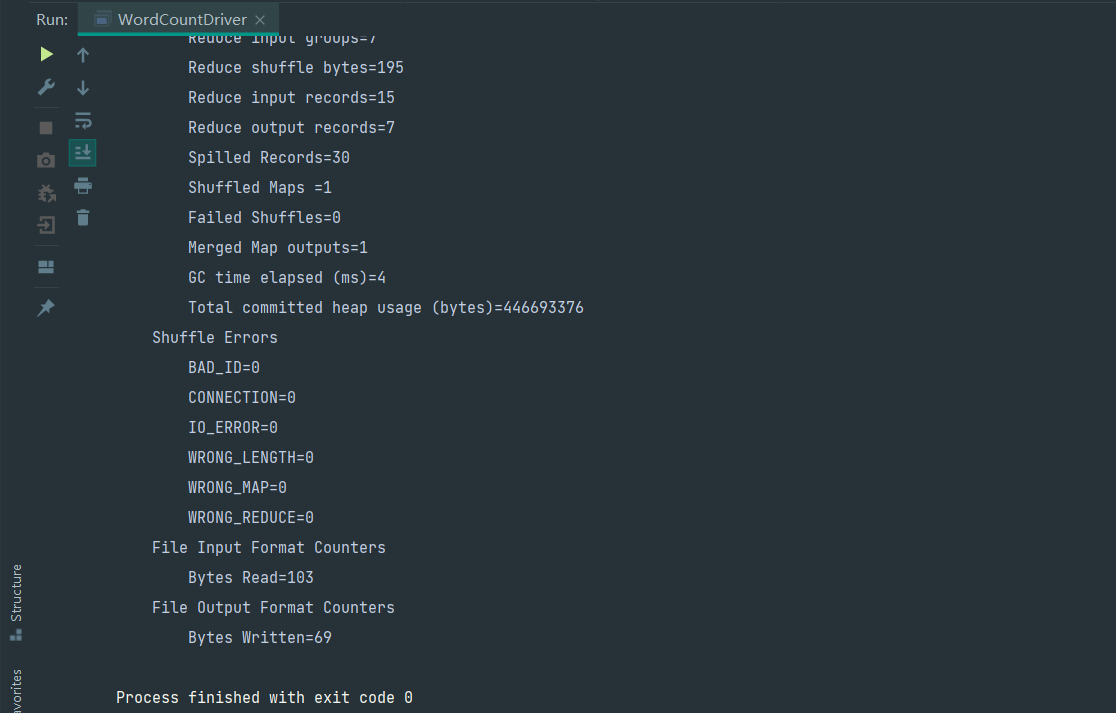
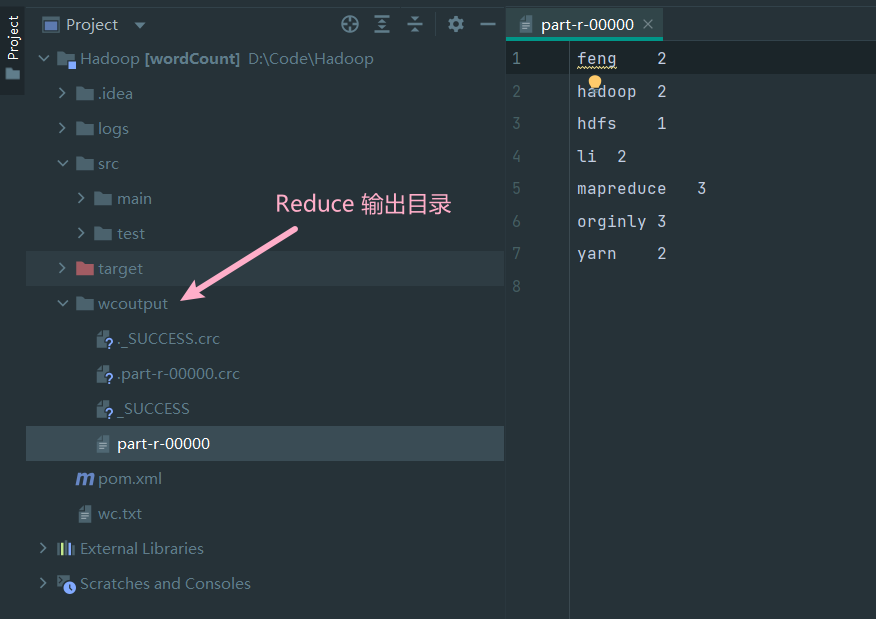
Yarn 集群验证
- 把程序打成 jar 包,改名为 wordCount.jar 上传到 Hadoop 集群
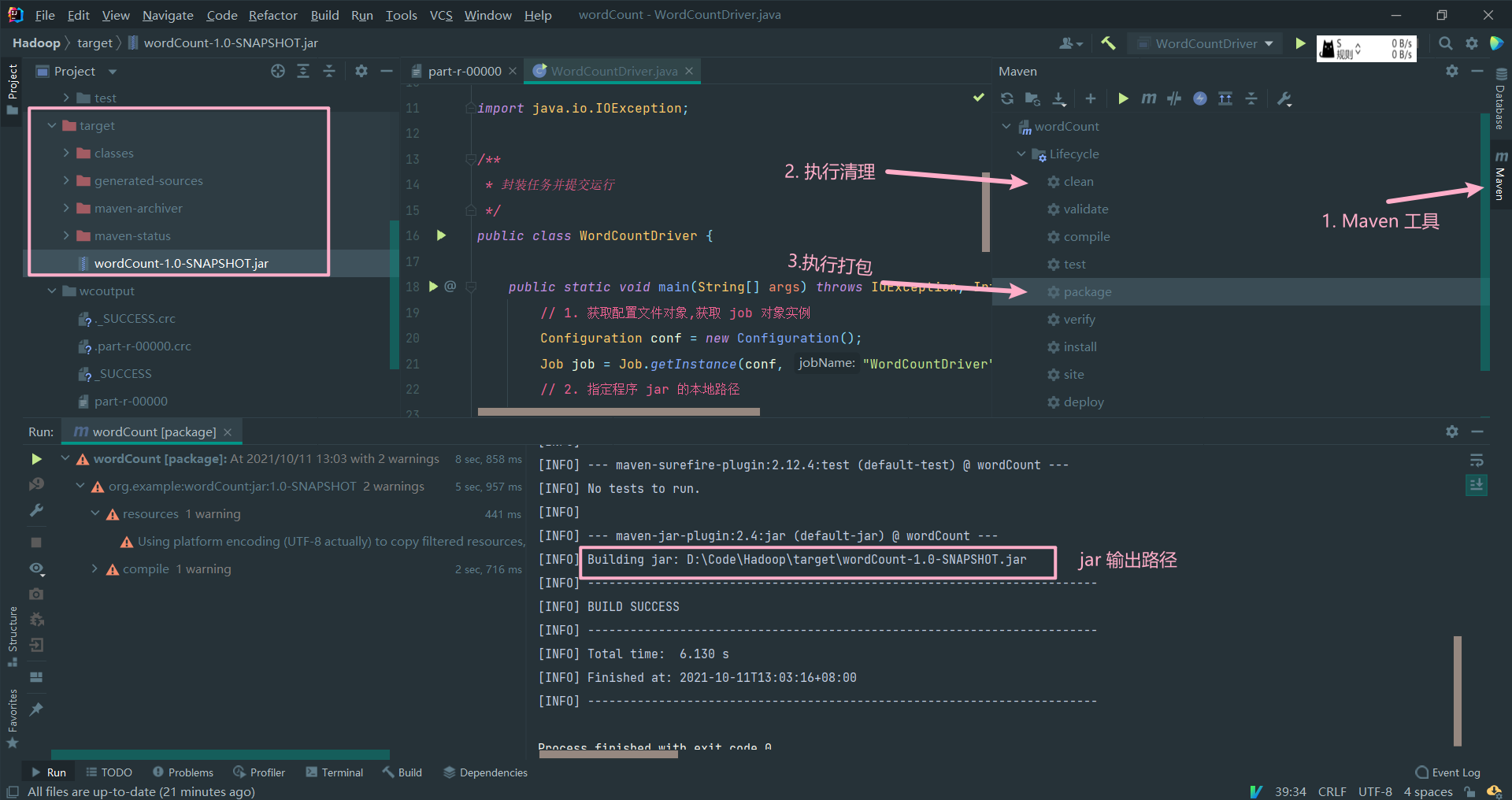
# 上传到服务器
rz
# 重命名
mv wordCount-1.0-SNAPSHOT.jar wordCount.jar
- 启动 Hadoop 集群(Hdfs,Yarn)
- 使用 Hadoop 命令提交任务运行
因为是集群,源文件不能存放在本地目录,需要上传至 HFDS 进行处理
hadoop jar wordCount.jar com.orginly.mapreduce.wc.WordCountDriver /mapReduce/wc.txt /wcoutput
执行成功
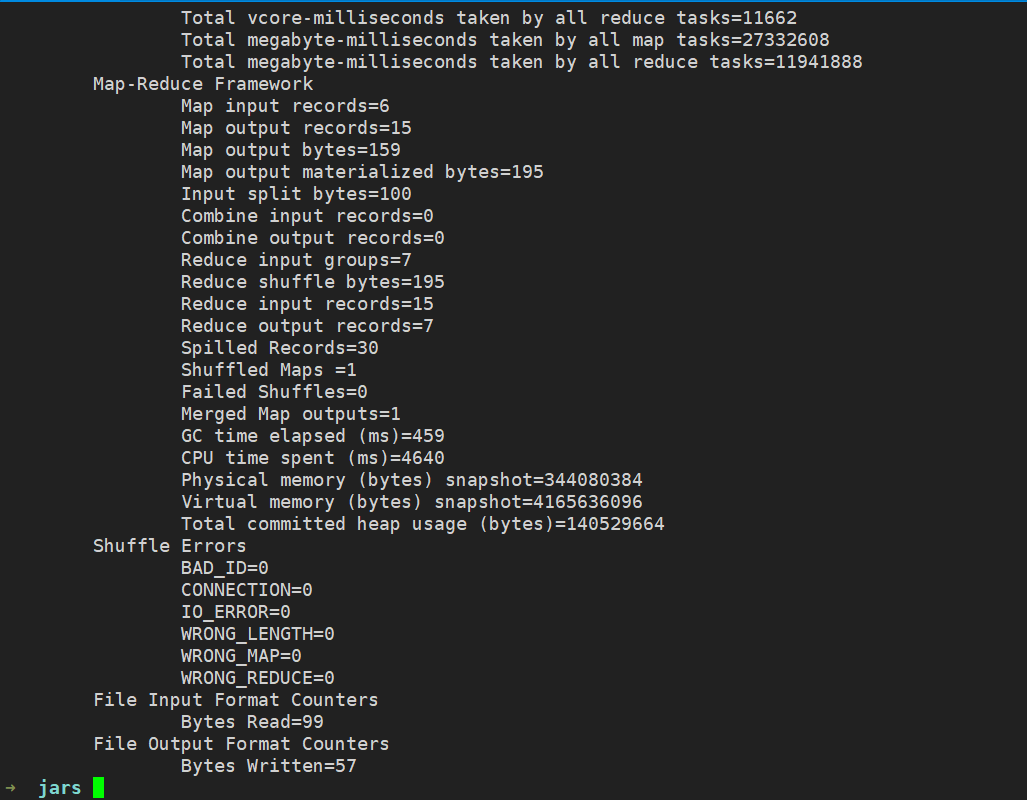
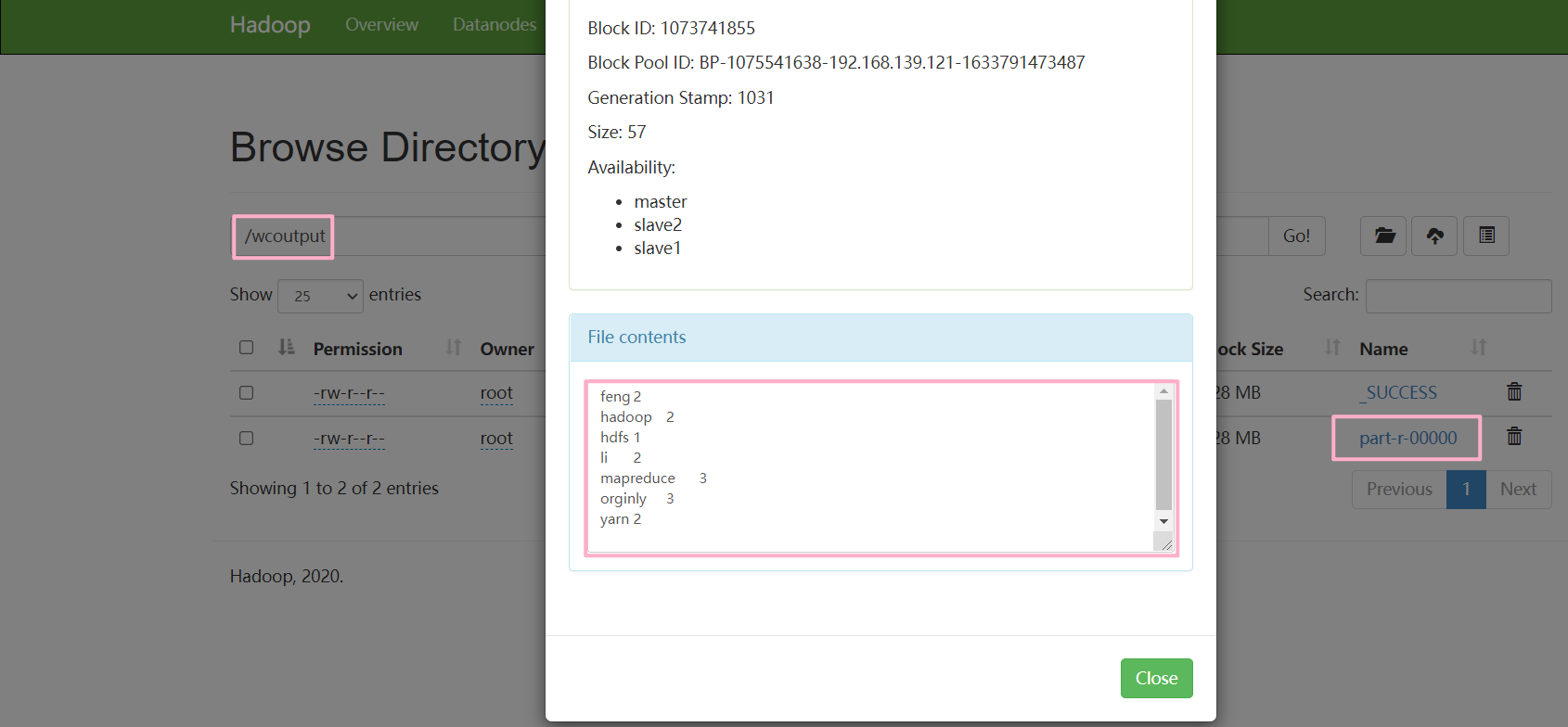
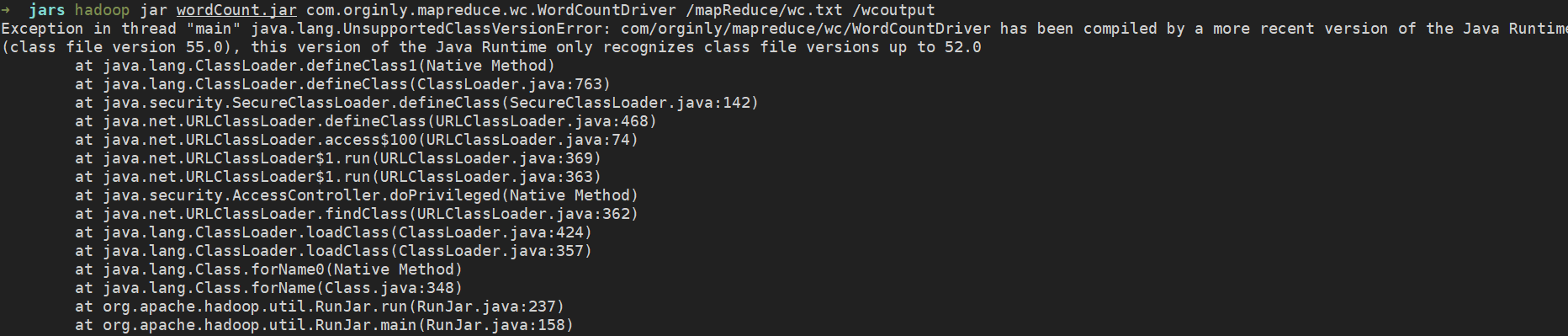
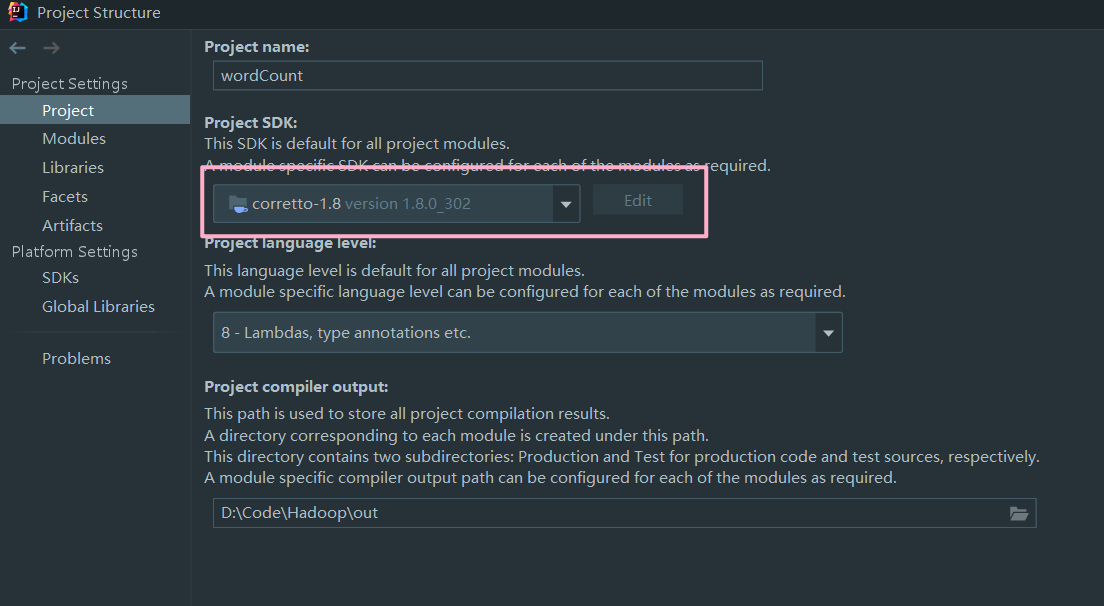
如果执行命令时出现版本过低提示,请安装服务器所使用的 jdk 版本进行 jar 的打包

 浙公网安备 33010602011771号
浙公网安备 33010602011771号