ECCV《Colorful Image Colorization》笔记
论文地址:《Colorful Image Colorization》
摘要
这篇论文主要解决的问题:输入灰度图,输出渲染后合理的彩图. 答案显然是不受约束的,因此前人的工作要么依赖于用户对图片渲染的交互,要么会得到不饱和的图片. 这篇论文提出了一个全自动上色方法,使得上色后的图片鲜明且真实. 论文接纳了上色问题潜在的不确定性,将其看做一个分类任务,在训练时使用类平衡(class-rebalancing)来增加输出图片颜色的多样性. 该系统使用了一百多万的彩图进行训练,在测试时使用的是前馈CNN. 论文使用“着色图灵测试”来对算法进行评估,让人类参与者区分一张生成的彩图和真实的彩图. 最终模型成功“欺骗”了32%的参与者,这一比例远远高于之前的方法. 此外,论文还展示了上色过程可以作为一个强有力的托词任务(pretext task,一种为达到特定训练任务而设计的间接任务),作为一个跨通道编码器,达到自我监督的特征识别。该方法在几个特征学习基准上取得了最先进的性能.
1 介绍
将灰度图上色是一个难题,因为灰度图损失了原图三分之二的色彩信息. 因此论文对灰度的处理是一种“看似合理”的上色,根据场景的语义和物体表面的纹理,比如(从纹理识别出来的)草显然是绿色的,天空是蓝色的,瓢虫大部分是红色为底色;但语义优先(默认某种物体属于某种颜色,比如草是绿色)并不符合所有的对象,比如草地上的一些彩球,渲染后不同的彩球颜色实际上是人为设定的,并不一定反映出真正的彩球颜色. 因此这篇论文并不是为了恢复灰度图原本的色彩,而是对灰度图渲染出合理和谐的颜色.
考虑搭配亮度通道L,该系统预测图像在CIE实验色(CIE Lab)中的相应的a和b通道的值. 论文采用了大规模的训练数据. 训练数据充足(任何彩图均可),将图片的亮度通道L作为输入,输出ab通道的值作为监控信号. 而在前人的工作中,由于训练数据容易获取,前人使用CNNs训练对图片颜色进行预测,然而结果饱和度太低,并不理想. 究其原因,这些模型使用的损失函数是从标准回归问题中继承,模型为了最小化output和label之间的欧氏距离而使得输出图片远远偏离真实图片.
相反,针对着色问题,论文定制了损失函数。考虑到颜色预测本质是一个多模态问题——许多物体可采取多种合理的颜色上色. 比如苹果可以是红的、绿的、黄的,但不可能是蓝的或者橘的. 为了合理地对问题的多模态性质建模,作者对每个像素预测一个可能颜色的分布. 此外,论文通过重新衡量训练时的权重来强调一些稀有颜色. 这就使得模型能够利用大量训练数据中的颜色多样性. 最后,通过分布的退火平均值(the annealed-mean of th distribution),形成最后的上色模型. 最终上色结果更鲜活,在感知方面也比前人成果更加真实.
评估合成图像是众所周知的难,因为论文的终极目标是使得着色图能够使人信服,所以论文引进了“着色图灵测试”,直接让人类参与者对着色图片进行真假判断. 论文展示了一些逼真的着色图,说明甚至有些图片真实到能直接作为后续工作流中的数据,尤其是在另一篇论文中的对象分类工作中.
论文额外探索了图片着色作为自我监督表现学习的形式,在自我监督表现学习中,生数据被作为自身监督的来源.(这段内容还讲了一些摘要提到的、和托词任务相关的内容,由于和我感兴趣的部分没太多关联,大致看了一下,就不做笔记了)
最后提到了在这篇论文的贡献主要在两方面. 第一,推动了自动图片上色,通过a)设计了一个适当的目标函数来处理着色问题的多模态不确定性,并捕获广泛的颜色多样性 b)引进了一个测试着色算法的新颖框架,潜在地可应用到其他图片合成任务中 c)通过训练百万以上的彩图,设定了这项任务一个新的高度;第二,论文将着色任务作为一个具有竞争力和直接的方法引进到自我监督表示学习中,在几个基准上达到了先进的水准.
着色领域中的前人工作
着色算法远不止为灰度与彩色的映射建模,后者只需要获取和处理数据找到映射. 非参数方法,假设给定灰度图作为输入,会首先定义一个或多个色彩参考图像(由使用者提供或者自动检索)作为数据源使用. 然后,遵循图像类比框架,颜色从参考图像的类似区域转移到输入(的灰度)图像上;参数方法在训练时从大型彩图数据集中学习预测函数,也会面临选择,要么作为连续色彩空间的回归问题,要么对量化的颜色值进行分类. 论文中提出的方法也是对颜色做分类,但是在一个更大的模型上做分类,使用了更多训练数据,并且使用了几个创新的损失函数,最终映射到最后的连续输出上.
着色领域的当前工作
和论文一同的,Larsson等人和Iizuka等人也研究了类似的系统,也采用大规模的数据和CNNs. 只是在CNN结构和损失函数方面使用的方法不同. 论文使用了一个分类损失和再平衡稀有类,Larsson等人使用了一个非再平衡分类损失,Iizuka等人使用了回归损失。在后面部分,论文将不同损失函数与本论文的框架结合,对不同的损失函数及其影响做了一个比较. 此外,CNN结构在某种程度上也不同:Larsson等人在VGG中使用了hypercolumns,Iizuka等人使用了一个双流结构,在双流结构中融合全局和局部特征,而本论文使用的是一个单流、VGG风格网络、增加深度和扩大回旋. 此外,本论文和Larsson等人在ImageNet上训练了各自的模型,Iizuka在另一个数据集(原文[29]处引用)上训练了他们的模型. 在3.1部分,论文提供了与Larsson等人的一个量化的比较.
2 方法
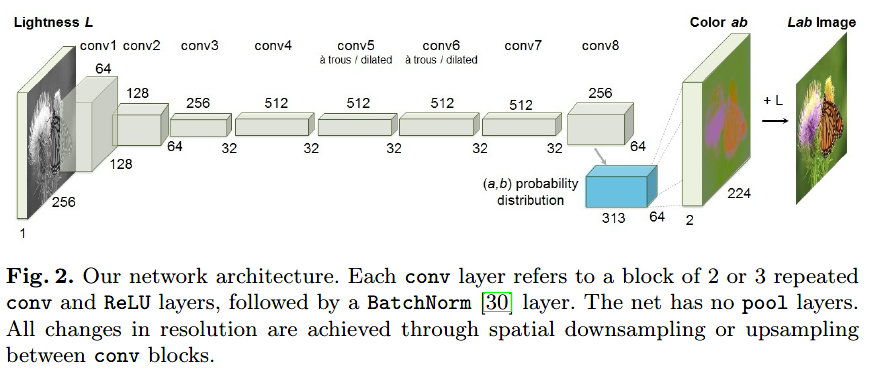
论文训练了一个CNN,将灰度输入映射到一个分布中,该分部使用了上图中的结构量化颜色值。结构细节在论文项目网址的补充材料中有详细说明,且模型公开可用的. 之后,论文将专注于目标函数的设计和从预测颜色分布中推断像素点颜色估计的技术.
2.1 目标函数
考虑一个输入亮度通道 \(X\in \mathbb{R} ^{H\times W\times 1}\) , 论文目标是学习一个映射 \(\hat{\mathrm{Y}} =\mathcal{F}(\mathrm{X})\) , 映射到两个关联颜色通道 \(Y\in \mathbb{R} ^{H\times W\times 2}\), 其中H,W是图像维度(高和宽), \(\hat{·}\) 代表预测结果,而没有该符号代表实际结果. 论文在CIE实验色彩空间中建立模型. 因为在该空间模型中,感知距离是预测结果和真实结果的一个欧氏距离损失函数\(L_{2}\): $$ L_{2}(\hat{Y},Y) = \frac{1}{2} \sum_{h,w}^{} \left | Y_{h,w} - \hat{Y_{h,w}} \right | _{2}^{2} $$
然而,这一损失函数对着色问题本质存在的模糊和多模态性的处理并不稳健. 如果一个对象能取一组区别明显的ab值,那么欧氏损失的最优解将会是该集合的几何平均值. 在颜色预测中,这种平均影响会倾向于灰化的不饱和结果. 此外,看似合理的着色集合如果是非凸的,那么着色结果将会超出集合范围,产生不合理的结果.
因此,论文转而将着色问题看作多项式分类. 将ab输出空间量化为网格大小为10的箱子,保持ab数量对Q=313. 对于给定的\(S\), 论文将映射$\hat{Z}= \mathcal{G}(X) \(到可能颜色\)\hat{Z}\in [0,1]_{H\times W\times Q} $的概率分布,其中Q是量化后ab值的数量.
为了比较\(\hat{Z}\)与真实结果,论文定义了函数\(Z=\mathcal{H}_{gt}^{-1}(Y)\),该函数使用软编码(soft-encoding scheme)将真实颜色\(Y\)转化为向量\(Z\). 然后使用多项式交叉熵损失函数(multinomial cross entropy loss)\(L_{cl}(·,·)\),定义如下:$$L_{cl}(\hat{Z},Z)=-\sum_{h,w}^{}v(Z_{h,w})\sum Z_{h,w,q}\log_{}{(\hat{Z}_{h,w,q} )} $$
其中\(v(·)\)为加权项,能够重新平衡稀有类颜色的损失,详细定义见2.2. 最后,论文通过函数\(\hat{Y} = \mathcal{H}(\hat{Z})\)映射\(\hat{Z}\)到值\(\hat{Y}\),详细讨论见2.3.
2.2 类再平衡
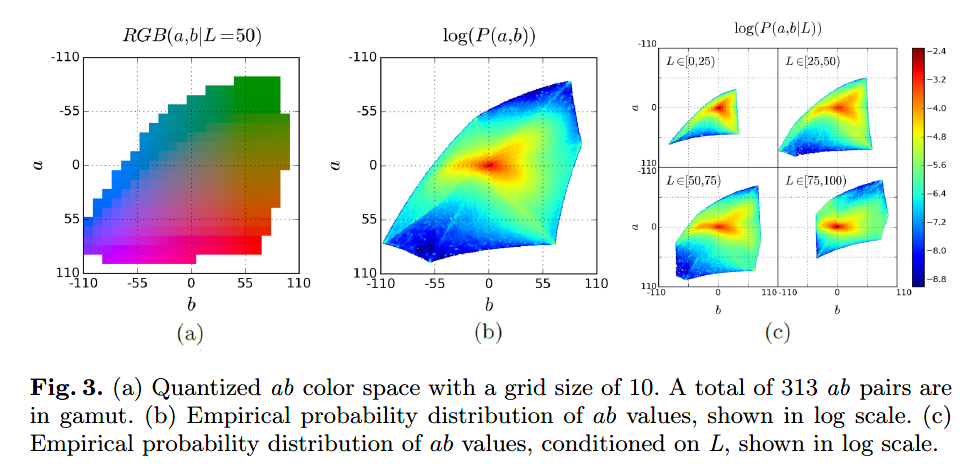
由于图片的背景,例如云、人行道、泥土和墙,原始图片中ab的分布会强烈地偏向于低的ab值. 图3(b)展示了ab空间中像素的经验分布,该分部从ImageNet的130万张训练图片中获得. 可以观察到,原始图片中的不饱和值像素的数量远远高于饱和值的数量. 如果不考虑到这个问题,那么损失函数将会被大量不饱和ab值主导. 论文考虑了这个问题,基于像素颜色的稀有性,在训练时通过调整每个像素损失的权重. 这就渐进地等价于典型的重采样训练空间方法. 基于最接近的ab值,每个像素根据w进行加权,$w\in \mathbb{R}{Q} $. $$v(Z)=W_{q^{}}, where q^{}=arg \max_{q}Z_{h,w,q}
为了获得平滑的经验分布,论文从全部ImageNet训练集和带高斯内核的平滑分布中估计了量化ab空间中颜色的经验概率. 然后利用权重\(\lambda \in [0,1]\)将该分布与均匀分布混合,然后取倒数,对其进行正则化,使期望的权重因子为1。最终模型参数为\(\lambda = \frac{1}{2}\),\(\sigma = 5\)时表现良好,其余比较结果再3.1.
2.3 类概率的点估计
最后,论文定义了\(\mathbb{H}\),将预测的分布\(\hat{Z}\)映射到ab空间的点估计\(\hat{Y}\). 一个选择是对每个像素都使用预测的分布,如图4中最右的一列. 这提供了一个颜色鲜活但空间有时会不一致的结果,例如,公共汽车上的红色斑点。另一方面,采取预测的分布的平均值来产生空间连续但低饱和的结果,如图4最左一列,结果展示了一个不自然的褐色色调. 这并不令人震惊,因为在执行分类后采取平均的做法也会遇到一些同样的问题,比如在一个回归框架中优化欧氏损失. 为了得到两种极端下的最好结果,论文通过重新调整softmax分布的温度值\(T\)来差值。这一方法启发于论文[33],因此参考了论文采取的对分布的退火均值(annealed-mean)方法:$$\mathbb{H}(Z_{h,w})= \mathbb{E}[f_{T}(Z_{h,w})], f_{T}(z)= \frac {\exp (\log_{}{(z)}/T )}{\sum_{q} \exp( \log(z_{q})/T)} $$.
设定\(T=1\)使得分布不改变,降低温度\(T\),来产生一个更强烈的减分分布,然后使\(T \to 0\)来影响在分布中的独热编码. 论文发现当\(T=0.38\)时,如图4,能在捕捉到鲜艳画面的同事保持均值空间连续.
论文最后的系统\(\mathbb{F}\)由CNN网络\(\mathbb{G}\)组成,该系统在所有像素的基础上产生一个预测的分布,和一个退火均值\(\mathbb{H}\),该退火均值产生一个最后的预测. 该系统不是完全从头到尾可训练的,但需要注意的是映射\(\mathbb{H}\)是对每个像素进行独立操作,带一个单独参数,而且能被作为CNN的前馈传递中的一部分.

3 Experiment
在3.1,论文评估了算法的图像层面,评估了着色的感知真实性,还有其他准确性的测量. 论文将完整算法与几个变体做了比较,一同比较的还有最近和目前的一些模型. 在3.2中,论文测试了将着色作为一种自我监督表示学习的方法. 最后,在10.1,论文展示了遗留黑白照的高质量结果.
3.1 评估着色质量
论文基于ImageNet的130万训练集上训练了网络,对ImageNet验证集中的第一个10k个图像进行验证,在分离出的10k测试集上验证. 论文在表格1中展示了三个度量上的定量结果. 挑选的成功和失败例子的定性比较见图5. 完整挑选随机图片的比较请前往项目网页查看.
为了显著地测试不同损失函数带来的影响,论文使用了各种损失函数对网络进行训练. 论文此外还与早先和目前的方法做了比较,这两个方法均在ImageNet上训练了CNNs,也均满足一些基本条件:
- 本论文(全部方法),包括分类损失,定义的等式,以及类再平衡. 网络在k均值初始化的基础上进行训练,使用ADAM求解器进行了约45万次迭代
- 本论文(类),使用了类损失但没有类再平衡
- 本论文(L2),网络从头开始训练,带L2回归损失函数,使用等式1,遵循同样的训练协议
- 本论文(L2,ft),网络使用L2回归损失函数进行训练,使用了精调的带再平衡网络的全分类
- Larsson等人,一个CNN网络,也有同样的处理方法
- Dahl等人,一个在VGG特征上使用拉普拉斯算子金字塔的模型,使用L2回归损失函数进行训练
- Gray,灰度图
- Random,从训练集中复制一张随机图片的颜色
众所周知,评估合成图片的质量是一项艰难的任务,比如简单的定量纸标,比如每个像素值的RMS误差,通常不能捕捉到视觉的真实. 为了克服任何个人评估的缺点,本论文测试了三种方法,这些方法能测量不同的质量感觉,结果见表格1.
1.** 感知的真实(Perceptual realism)(AMT)**:对于许多应用,比如图像处理中的,着色的最终测试是这些颜色对人类观察者究竟有多少水浮力. 为了测试这一点,本论文在亚马逊土耳其机器人(AMT)上运行了一个仅有真实与虚假两个强制选项的实验. 实验参与者被展示一系列图片对. 每一对图片由一张真实颜色图片和重上色图片,这些图片由本论文提到的算法生成. 参与者被要求选择出他们认为由计算机程序产生的,包含虚假颜色的图片. 单个像素为256*256的图片对依次展示给参与者,参与者在非限制时间内做出判断. 每个实验会话由十次练习判断(不计入结果)和40个正式判断. 在练习判断中,参与者会被给予答案正确与否的反馈. 40个正式判断中不会有答案反馈. 每个会话一次只测试一个算法,参与者也只被允许完成同一个算法的一次会话. 总共40个参与者会对算法进行评估. 为了确保算法在相同的条件下执行,所有实验会话将会同时进行,并且传递到AMT中.
为了检查参与者能否胜任这项工作,10%的判断将真实图片与上面描述的随机基准进行对比. 参赛者成功地辨认出随机图片中87%的虚假着色,这表明参与者能理解这项任务且认真对待.
图片6更直观地展示了参与者察觉出的、本论文算法制造的一些细微的错误. 最右一列展示了参与者在试判断中100%辨认出的虚假图片的样例对. 每一对杨丽对至少被是个参与者进行了打分. 仔细检查会发现在这些图片中,本论文的着色倾向于附赠一些额外的着色,比如两辆卡车上的黄色斑点,破坏了原本不错的结果。
然而,本论文全部的算法欺骗了32%的审判参与者,见表格1. 这一数字远远高于除Larsson等人的所有比较的算法,但与Larsson等人的模型区别并不是很明显. 这些结果验证了同时使用分类损失和再平衡损失的有效性.
需要注意的是,如果本论文的算法生成的图片和真实结果完全一样,那么参与者将会在两张相同图片中作出强制的选择,那么会有50%的事件被愚弄. 有趣的是,我们能找出参与者被愚弄超过50%的时间的例子,这表明本论文的产生的图片结果被认为比真实图片更加真实. 图6中的前三列展示了一些类似的例子. 在许多情况下,真实图片仅仅只是白平衡或者有一些不常见的颜色,而本论文系统能产生一个更原型的样子.
- 语义可解释性(Semantic interpretability(VGG 分类)):本论文方法产生的着色是否真实到足以被现有的对象分类器判断?我们测试了这一猜想,将虚假着色图片投入到VGG网络中,该网络被训练为从真实色彩图片中预测ImageNet类的图片. 如果该分类器表现良好,那就意味着我们的着色系统足够精确到对对象包含有用的信息. 使用现成的分类器来评估合成数据的真实性早在论文[12]中就已经被提出.
结果表明在表格1中右数第二列. 从输入图片去除颜色后,分类器的表现从68.3%降到了52.7%. 在重新使用本论文的完整算法重新着色后,分类器的表现提升到了56%(其他本论文方法的变种能得到一些稍高的结果). Larsson等人的方法表现最好,达到了59.4%. 作为参考,一个精调的VGG分类网络在灰度图上的表现达到了63.5%.
除了作为一个感知度量,这篇分析说明一个本论文算法的实际用途:不需要额外的训练或精调,我们就能提高灰度图分类的表现,所做工作仅仅只是使用我们的算法对图片进行上色,然后把它们传递到一个现成的分类器中.
- 未加工的准确性(Raw accuracy(AuC)):作为一个低水平的测试,我们计算ab颜色空间中在真实图片L2阈值距离内预测像素颜色的百分比。我们扫描了从0到150的阈值来产生一个累积质量函数,如论文[22]中引进的那样,积分求解了曲线(AuC)下的面积,然后正则化. 注意,该AuC度量测量的是未加工的预测准确性,也就是本论文方法追求的看似合理性.
本论文的网络,在分类上训练,没有使用再平衡,胜过本论文L2的变种. 当L2网络反之根据一个颜色分类网络进行精调后,它能比拟分类网络. 这就表明L2度量能达到精确的着色,但一开始就会存在优化难度. Larsson等人的方法达到了稍微更高的精确度. 注意,该度量是被不饱和像素主导,这是由ab值在原始图片中的分布导致. 所以,即使对每个像素预测灰度值做得很好,本论文带类再平衡的完整方法达到了大约同样的结果.
另一方面,图像感知的有趣区域倾向于拥有一个带更高饱和度的ab值的分布. 因此,我们计算了AuC曲线度量的一个类再平衡变种,通过利用颜色类概率(等式4,$\lambda=0 $)反向加权重新加权像素. 在这种度量下,本论文完整方法胜过所有变种模型和作比较的算法,表明类再平衡在训练对象中能够达到预期效果.
3.2 跨通道编码作为自监督的特征学习
除了推动图像着色的任务,本论文评估了着色任务能否作为表征学习的一个代理任务.
(后面内容和感兴趣没太大关联,不记了)
posted on 2020-11-06 10:06 Liiipseoroinis 阅读(1398) 评论(0) 编辑 收藏 举报

