流体模拟:NeighborHood Search
流体模拟:NeighborHood Search
前言
领域搜索(NeighborHood Search)对于流体模拟仿真是一个非常重要的问题,实现一个高效的领域搜索可加速流体模拟,因此下面对我了解到的方法进行一定的介绍。
1. Uniform Grids(均一网格)
这个方法使用均匀的网格将模拟的空间细分为一个个大小均匀的单元组成的网格(对于粒子来说一般网格大小与粒子大小相等),这是最简单的一种空间细分方法。我们在查找领域粒子的时候,必须对相邻单元中的粒子(即\(3\times 3 \times 3=27\)个单元格)查找处理,判断粒子是否接触。
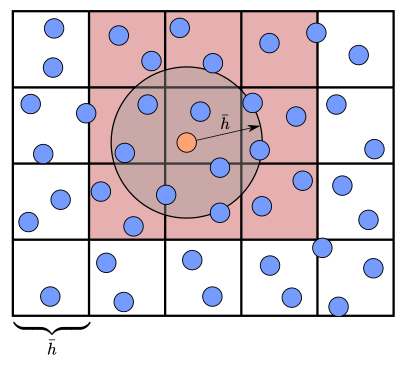
使用这种方法的问题在于其中许多网格是空的,并无粒子存在,空间使用率低。
2. Spatial Hashing(空间哈希)
采用空间哈希的方法,首先我们根据粒子的位置计算对应的空间哈希值,并将粒子对应的线性编号,将cell id与particle id存储在线性数组中,我们便可以得到一个cell id乱序的线性表;然后对cell id进行一个排序,这里我们采用GPU的并行基数排序(可参考我的上一篇博客:DirectX11:GPU基数排序 ),最后我们便可以得到一个cell id有序以及particle id按照cell id排序的两个线性表。如下所示:
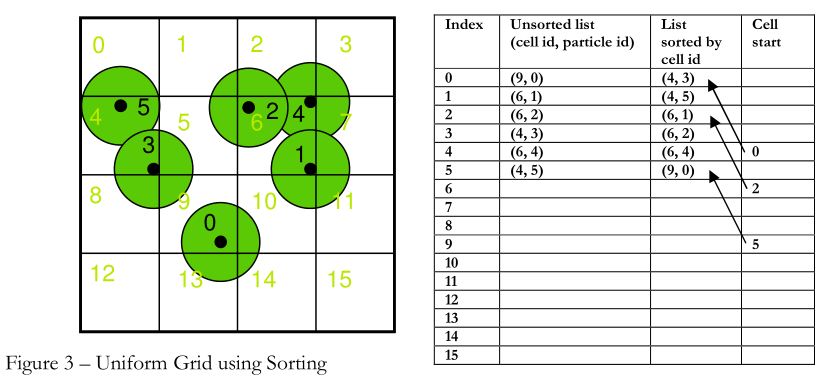
我们仅仅需要记录每个空间单元cell记录的粒子的起始与结束地址,然后根据当前网格得到其周围27个空间单元的cell从而判断其包含粒子与当前粒子是否接触。
在这个方法中,所使用的哈希函数如下:
其中\(p_1=73856093,p_2=19349663,p_3=83492791\),输入\(c=(i,j,k)\)以及\(m\)为哈希表的大小(一般采用粒子数量的两倍大小)。
我所采用的方法也是基于空间哈希的领域搜索方法。
优点:稀疏表示,只存储已填充的单元格
缺点:Cache命中不理想,是因为邻居在内存中不紧凑;大质数(32位无符号整数可能不能准确表达)
3. HLSL核心代码
本人采用的是DirectX11中的computer shader进行实现,所有的缓冲区采用结构化缓冲区,假设你对以下的内容比较了解:
| DirectX11 With Windows SDK完整目录 |
|---|
| 26 计算着色器:入门 |
| 深入理解与使用缓冲区资源 |
| 并行规约算法 |
3.1计算哈希值
//calculate hash
uint hashFunc(int3 key)
{
int p1 = 73856093 * key.x;
int p2 = 19349663 * key.y;
int p3 = 83492791 * key.z;
return p1 ^ p2 ^ p3;
}
uint GetCellHash(int3 cellPos)
{
uint hash = hashFunc(cellPos);
return hash % (2 * g_ParticleNums);
}
[numthreads(THREAD_NUM_X, 1, 1)]
void CS(uint3 DTid : SV_DispatchThreadID )
{
if (DTid.x < g_ParticleNums)
{
float3 currPos = g_ParticlePosition[DTid.x];
int3 cellPos = floor((currPos - g_Bounds[0]) / g_CellSize);
g_cellHash[DTid.x] = GetCellHash(cellPos);
g_cellIndexs[DTid.x] = g_acticeIndexs[DTid.x];
}
else
{
g_cellHash[DTid.x] = -1;
g_cellIndexs[DTid.x] = -1;
}
}
g_Bounds为当前粒子位置各分量的最小/大值,可使用并行规约算法中的上行阶段(reduce阶段)进行比较,从而得到最小的值。如下所示(求的是当前线程组数据的各分量的最小/大值):
groupshared float3 boundmin[THREAD_BOUNDS_X];
groupshared float3 boundmax[THREAD_BOUNDS_X];
[numthreads(THREAD_BOUNDS_X, 1, 1)]
void CS( uint3 DTid : SV_DispatchThreadID,uint GI:SV_GroupIndex,uint3 GId:SV_GroupID)
{
float3 currPos = float3(0.0f, 0.0f, 0.0f);
if (DTid.x < g_ParticleNums)
{
currPos = g_ParticlePosition[DTid.x];
}
else
{
currPos = g_ParticlePosition[g_ParticleNums - 1];
}
boundmin[GI] = currPos;
boundmax[GI] = currPos;
uint d = 0;
uint offset = 1;
uint totalNum = THREAD_BOUNDS_X;
//min
for (d = totalNum >> 1; d > 0; d >>= 1)
{
GroupMemoryBarrierWithGroupSync();
if (GI < d)
{
uint ai = offset * (2 * GI + 1) - 1;
uint bi = offset * (2 * GI + 2) - 1;
boundmin[bi] = min(boundmin[ai], boundmin[bi]);
boundmax[bi] = max(boundmax[ai], boundmax[bi]);
}
offset *= 2;
}
GroupMemoryBarrierWithGroupSync();
if (GI == 0)
{
float3 min = boundmin[totalNum - 1];
float3 max = boundmax[totalNum - 1];
g_ReadBoundsLower[GId.x] = min;
g_ReadBoundsUpper[GId.x] = max;
}
}
我们用粒子当前位置减去最小值,即可得到粒子在当前流体域中的网格位置信息,从而计算其hash值并进行排序。
3.2 基数排序
详情可见:DirectX11:GPU基数排序
3.3 当前网格的起始与结束地址
我们记录每个空间单元cell记录的粒子的起始与结束地址就变得非常简单,只需将当前的cell id与排序好的线性表前一个的cell id进行比较,若不相同,则说明当前的粒子地址是当前粒子的所在空间单元cell的起始地址并且是前一个粒子所在单元空间cell的终止地址。
//load hashid at pos+1
groupshared uint sharedHash[THREAD_NUM_X+1];
[numthreads(THREAD_NUM_X, 1, 1)]
void CS( uint3 DTid : SV_DispatchThreadID,uint GI:SV_GroupIndex )
{
uint hashValue = 0;
if (DTid.x < g_ParticleNums)
{
hashValue = g_cellHash[DTid.x];
sharedHash[GI + 1] = hashValue;
if (GI == 0 && DTid.x > 0)
{
sharedHash[0] = g_cellHash[DTid.x - 1];
}
}
GroupMemoryBarrierWithGroupSync();
if (DTid.x < g_ParticleNums)
{
//If It's equal to the last one
if (DTid.x == 0 || hashValue != sharedHash[GI])
{
g_CellStart[hashValue] = DTid.x;
if (DTid.x > 0)
{
//the last cell end pos
g_CellEnd[sharedHash[GI]] = DTid.x;
}
}
//thread the last one output
if (DTid.x == g_ParticleNums - 1)
{
g_CellEnd[hashValue] = DTid.x + 1;
}
}
}
参考资料
[1] Green S. Particle simulation using cuda[J]. NVIDIA whitepaper, 2010, 6: 121-128.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号