
通用网页抓取设计
导言
网页抓取是一个比较简单的工作,主要分为以下三步:一:分析要抓取的网页,获取待抓取的页面地址;二、用下载方式缓存网页,如果网站设置有访问时间限制,就要用这步来缓存;三、分析缓存中的网页,整理数据
在所有步骤中,对于所有的网站,只有获取换取地址、缓存网页、处理网页这几个方式不一定一样,其它的处理方式,都可以认为是一样的
总体接口设计

包括地址抓取、处理、文件缓存、消息传递委托类型,消息类型;
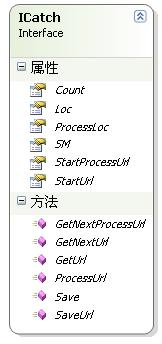
ICatch(抓取接口)
接口说明:
1
 /// <summary>
/// <summary>
2
 /// 抓取地址接口
/// 抓取地址接口3
 /// </summary>
/// </summary>4
 public interface ICatch
public interface ICatch5
{
6
 string StartUrl { set;}
string StartUrl { set;}
7
8
string StartProcessUrl { set;}9
/// <summary>10
/// 显示消息接口11
 /// </summary>
/// </summary>12
ShowMessage SM { set;}13
/// <summary>14
/// 要抓取的地址总数15
/// </summary>16
int Count { get;}17
18
/// <summary>19
/// 当前下载网页的位置20
/// </summary>21
int Loc { get;}22
23
/// <summary>24
/// 当前处理的位置25
/// </summary>26
int ProcessLoc { get;}27
/// <summary>28
/// 保存换取到的数据29
/// </summary>30
/// <param name="data">数据</param>31
/// <param name="FileName">要保存的文件名</param>32
/// <returns></returns>33
bool Save(byte[] data, string FileName);34
/// <summary>35
/// 获取下一个网页地址36
/// </summary>37
/// <returns></returns>38
string GetNextUrl();39
/// <summary>40
/// 保存待抓取的网址41
/// </summary>42
/// <param name="wb">网页</param>43
bool SaveUrl(WebBrowser wb);44
45
/// <summary>46
/// 处理网页47
/// </summary>48
/// <param name="wb">web浏览器</param>49
/// <returns></returns>50
bool ProcessUrl(WebBrowser wb);51
52
/// <summary>53
/// 获取下一个待处理的网页地址54
/// </summary>55
/// <returns></returns>56
string GetNextProcessUrl();57
/// <summary>58
/// 获取下载的地址59
/// </summary>60
/// <returns></returns>61
UrlInfo GetUrl();62
}
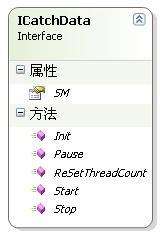
ICatchData(缓存网页接口)
接口:
1
/// <summary>2
/// 缓存数据接口3
/// </summary>4
public interface ICatchData5
{6
/// <summary>7
/// 消息接口8
/// </summary>9
ShowMessage SM { set;}10
/// <summary>11
/// 重设线程数12
/// </summary>13
/// <param name="ThreadCount">线程数</param>14
void ReSetThreadCount(int ThreadCount);15
/// <summary>16
/// 初始化下载17
/// </summary>18
/// <param name="ca">抓取接口</param>19
/// <param name="ThreadCount">线程数</param>20
/// <param name="ThreadSleep">休眠时间</param>21
/// <param name="RetryCount">出错重试次数</param>22
void Init(ICatch ca, int ThreadCount, int ThreadSleep,int RetryCount);23
/// <summary>24
/// 开始下载25
/// </summary>26
void Start();27
/// <summary>28
/// 暂停下载29
/// </summary>30
void Pause();31
/// <summary>32
/// 停止下载33
/// </summary>34
void Stop();35
}
小结
只要根据不同的网站实现上面的两个接口,就可以实现网页的抓取,处理,再也不用管理浏览器的怎样加载文件
