

Kafka架构看这篇就够了
kafka主要作用
- Kafka 为实时日志流而生,要处理的并发和数据量非常大。可见,Kafka 本身就是一个高并发系统,它必然会遇到高并发场景下典型的三高挑战:!!#ff0000 高性能、高可用和高扩展。!!
- 为了简化实现的复杂度,Kafka 最终采用了很巧妙的消息模型:它将所有消息进行了持久化存储,让消费者自己各取所需,想取哪个消息,想什么时候取都行,只需要传递一个消息的 offset 进行拉取即可。
![]()
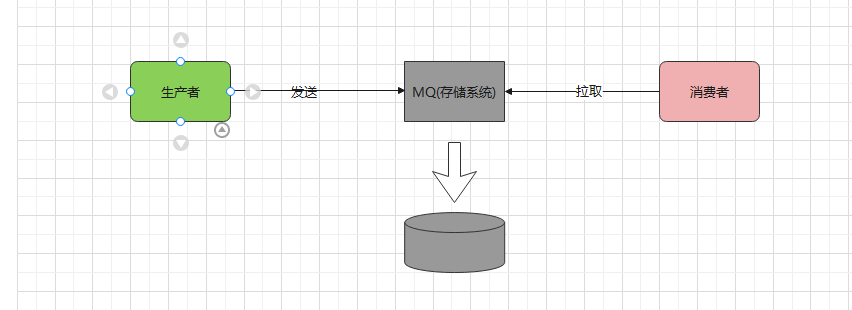
最终 Kafka 将自己退化成了一个!!#ff0000 「存储系统」!!。因此,海量消息的存储问题就是 Kafka 架构设计中的最大技术难点。
Kafka 究竟是如何解决存储问题的
一条消息的流转路径就如下图所示,先走主题路由,然后走分区路由,最终决定这条消息该发往哪个分区:
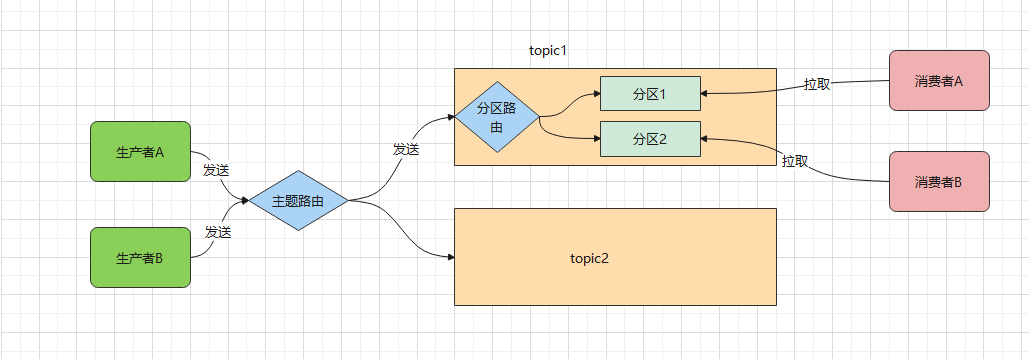
其中分区路由可以简单理解成一个 Hash 函数,生产者在发送消息时,完全可以自定义这个函数来决定分区规则。如果分区规则设定合理,所有消息将均匀地分配到不同的分区中。
通过这样两层关系,最终在 Topic 之下,就有了一个新的划分单位:Partition。先通过 Topic 对消息进行逻辑分类,然后通过 Partition 进一步做物理分片,最终多个 Partition 又会均匀地分布在集群中的每台机器上,从而很好地解决了存储的扩展性问题。
因此,Partition 是 Kafka 最基本的部署单元。
消费组的概念引出
假设现在有两个 Topic,每个 Topic 都设置了两个 Partition,如果 Kafka 集群是两台机器,部署架构将会是下面这样:
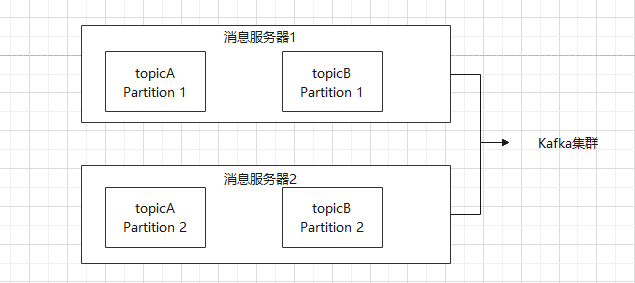
可以看到:同一个 Topic 的两个 Partition 分布在不同的消息服务器上,能做到消息的分布式存储了。但是对于 Kafka 这个高并发系统来说,仅存储可扩展还不够,消息的拉取也必须并行才行,否则会遇到极大的性能瓶颈。
- 广播消费能力:同一个 Topic 可以被多个消费者订阅,一条消息能够被消费多次。
- 集群消费能力:当消费者本身也是集群时,每一条消息只能分发给集群中的一个消费者进行处理。
为了满足这两点要求,Kafka 引出了!!#ff0000 消费组!!的概念
做一个假设,假设主题 A 共有 4 个分区,消费组 2 只有两个消费者,最终这两个消费组将平分整个负载,各自消费两个分区的消息。Kafka 还限定了:!!#ff0000 每个 Partition 只能由消费组中的一个消费者进行消费!!
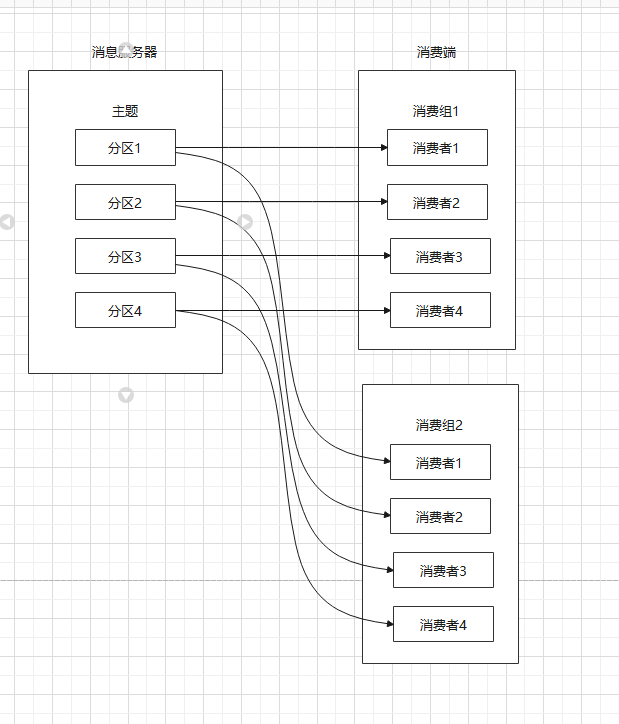
Kafka集群
假设 Kafka 集群中有 4 台服务器,主题 A 和主题 B 都有两个 Partition,且每个 Partition 各有两个副本,那最终的多副本架构将如下图所示:
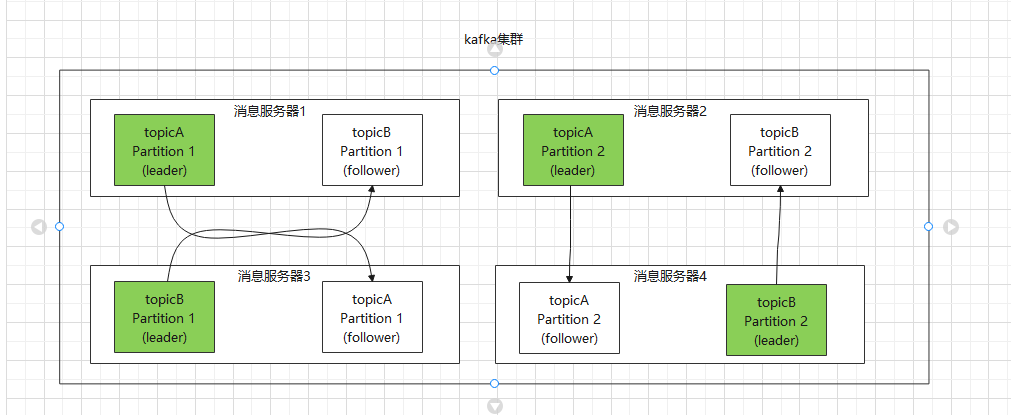
这样任何一个集群宕机了,也不影响Kafka的可用性
kafka整体的架构
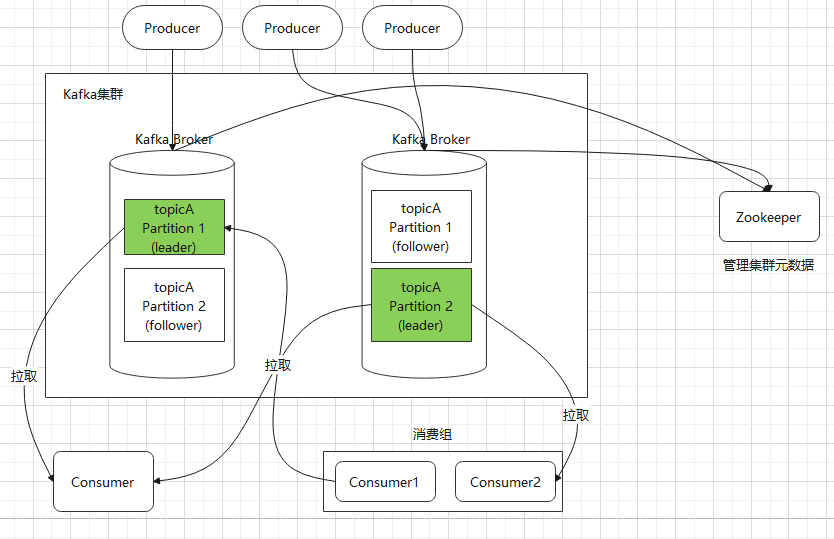
1、Producer:生产者,负责创建消息,然后投递到 Kafka 集群中,投递时需要指定消息所属的 Topic,同时确定好发往哪个 Partition。
2、Consumer:消费者,会根据它所订阅的 Topic 以及所属的消费组,决定从哪些 Partition 中拉取消息。
3、Broker:消息服务器,可水平扩展,负责分区管理、消息的持久化、故障自动转移等。
4、Zookeeper:负责集群的元数据管理等功能,比如集群中有哪些 broker 节点以及 Topic,每个 Topic 又有哪些 Partition 等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号