笔记杂谈
笔记杂谈
快速上传笔记图片
这里每次上传到博客园或者其他网址需要一张一张的传送图片,这种很麻烦。
所以我们需要有一个工具帮助我们上传图片:使用Typora上传博客到博客园,这篇文章告诉我们如何搞。
密码需要更改为密钥,详情见这篇文章https://q.cnblogs.com/q/140122/
注意事项:
- 不要使用Typora的缩放功能,会识别不出来;
- 不要把一篇文章的图放在不同的文件夹,会上传失败。
博客园背景皮肤设置
我们可以方便的获得很好看的界面:通过这篇文章。
设置好之后可以在设置中修改头像之类的。
Latex+VScode
首先根据这篇文章安装TexLive环境:最新TeXLive 环境的安装与配置,中间需要下载Daemon tool lite来运行ISO中的文件,具体操作是安装好后对下载的ISO进行虚拟,然后点击虚拟生成的盘就可以开始安装,安装大概需要二至三个小时,然后这篇文章结束。
然后开始根据编写中文Latex(VSCode+TexLive)这篇文章去配置VSCode,记得在末尾需要配置环境变量,我的是:C:\texlive\2022\bin\win32。
最后是根据这篇文章去学习教程:从零开始的Latex使用教程,里面有很多内容仍待学习。
Anaconda
Anaconda介绍、安装及使用教程
我直接下载了Anaconda 对应python3.9.9的版本 很麻烦 卸了重新下了3.6的。。。记得python也要换成对应版本的 不然会安装的时候一直卡住不动。
安装:Anaconda3对应python版本下载
查看环境:conda info --envs
激活对应环境:conda activate pytorch(pytorch为我的环境名)
启动Jupyter命令:jupyter notebook
Jupyter
Pytorch
先安装CUDA 我的GPU是NVIDA RTX 3050 Laptop GPU 电脑上显示的对应CUDA为11.6.134 由于我去下载了CUDA ToolKit 安装的时候提示告诉我在安装低版本的我就放弃11.6版本了,这期间分别下载了11.6.1和11.6.2均有次提示。于是下载了11.7然后CUDA驱动变成了11.7.57 目前对这个工具包的理解是除了对GPU的加速外还包含着CUDA的驱动,我在下了11.7后使用conda安装失败,
于是卸载11.7后重新尝试11.6.2直接安装 虽然cuda驱动的版本还是17 但是这次换成了pip的方式在pytorch官网拿来下载链接在虚拟环境中下载成功了(这里的虚拟环境可以通过Anaconda创建)。 可以通过torch.cuda.is_available()是否为True判断是否安装成功。
深度学习笔记
知识点和好文章
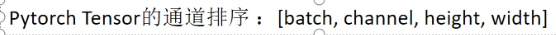

“反向传播算法”过程及公式推导(超直观好懂的Backpropagation)
理解Pytorch的loss.backward()和optimizer.step()
前期环境的准备
-
pytorch环境准备:这里是根据前面的章节进行Anaconda和Pytorch的安装,最后是准备一个conda的环境并安装好对应GPU的torch包
如图:
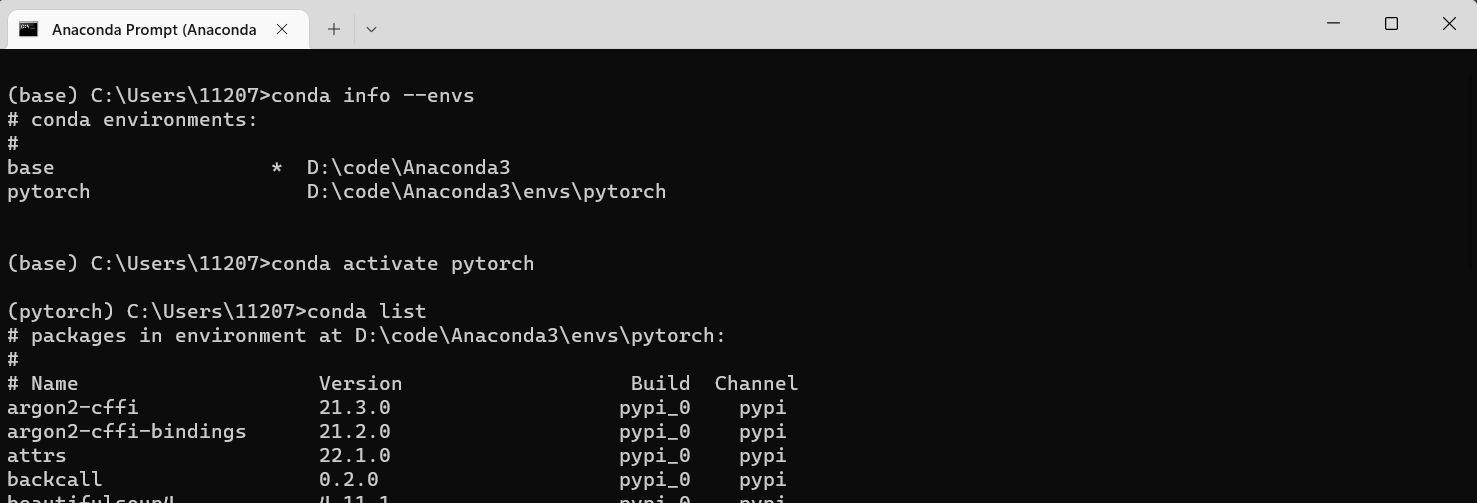
 在查看环境的时候,我们可以知道对应的python路径
在查看环境的时候,我们可以知道对应的python路径 -
为Pycharm配置我们的python环境:深度学习-在pycharm里面使用anaconda环境
-
这时我们可以去找一个代码比较简单的demo去实现 我是开始看霹雳吧啦Wz这个up主的图像分类篇,基础部分直接看视频,可以直接去这个作者的git上下载代码,这里主要解决视频中没有提到但是我遇到了的问题。
LeNet复现
作者代码的路径:deep learning\deep-learning-for-image-processing-master\deep-learning-for-image-processing-master\pytorch_classification\Test1_official_demo
中间遇到问题:matplotlib包不见,我们可以到环境下去conda install matplotlib来下载,pycharm会自动更新我们新加入的包。
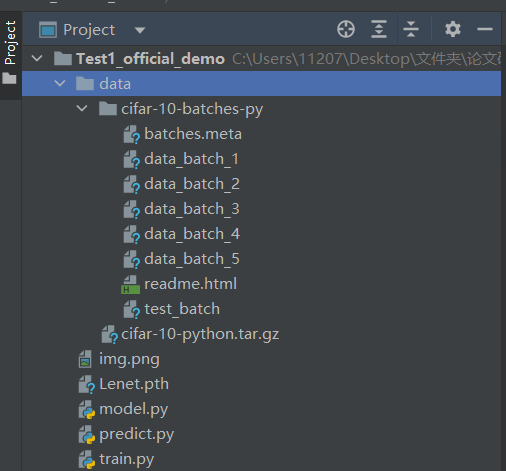
数据集虽然可以让torchvision.datasets.CIFAR10自动下载,但是我的自动下载太慢,配置了镜像源依旧很慢,就自己下载了数据集,解压后放到data文件夹下。
结构如图:
中间我们可以在训练的时候放到GPU上,这样训练的更快,具体的内容见代码:
train.py
import time
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
def main():
# 预处理,将图片转化成向量并进行标准化 将数据映射到一个区间,防止差距过大
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
# 将数据传入DataLoader中 这样每次读取数据都是直接获取一个batch的数据
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=10000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = next(val_data_iter)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# # 展示图片
# def imshow(img):
# # 反向标准化
# img = img / 2 + 0.5 # unnormalize
# # 从torch的tensor格式转换成np的格式
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# # print labels
# print(' '.join(f'{classes[val_label[j]]:5s}' for j in range(4)))
# # show images
# imshow(torchvision.utils.make_grid(val_image))
net = LeNet()
# 转移到GPU上
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net.to(device)
# 最后一层不需要softmax 因为交叉熵损失里面内置了softmax
loss_function = nn.CrossEntropyLoss()
# 优化器 帮助损失找到更好的梯度方向
optimizer = optim.Adam(net.parameters(), lr=0.001)
# 迭代次数
for epoch in range(5): # loop over the dataset multiple times
# 累加的Loss
running_loss = 0.0
time_start = time.perf_counter()
# 遍历训练集样本 step好像是索引 data代表从loader中加载的这一batch的数据
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
# PyTorch中在反向传播前为什么要手动将梯度清零? https://www.zhihu.com/question/303070254
optimizer.zero_grad()
# forward + backward + optimize
# 原本CPU的写法
# outputs = net(inputs)
# loss = loss_function(outputs, labels)
# GPU的写法
outputs = net(inputs.to(device)) # 将inputs分配到指定的device中
loss = loss_function(outputs, labels.to(device)) # 将labels分配到指定的device中
# 反向传播 通过loss 计算梯度
loss.backward()
# 根据每个参数的梯度和学习率 进行参数更新
optimizer.step()
# 每500步 记录一下准确率
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
# with是一个上下文管理器 让with里面的数据都保持着torch.no_grad()去掉梯度的情况
# 这里应该是会自动生成前向的传播图,这会占用大量内存,测试时应该禁用
with torch.no_grad():
# 一次预测中有一个batch,batch中的一条数据是对0~9个数的预测概率,
# outputs = net(val_image) # [batch, 10]
outputs = net(val_image.to(device)) # 将test_image分配到指定的device中
# 其中概率最大的那个位置对应的序号,即相当于classes中对应物品的序号
# max返回两个值0是最大值 1是位置
predict_y = torch.max(outputs, dim=1)[1]
# .sum()之后依旧是一个tensor 需要通过item()来变成数字
# accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
accuracy = (predict_y == val_label.to(device)).sum().item() / val_label.size(0) # 将test_label分配到指定的device中
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
print('%f s' % (time.perf_counter() - time_start))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()
model.py
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
# 这里是当向LeNet中传入数据的时候,会自动根据钩子函数去调用前向传递 返回结果
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
predict.py
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
# m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
# input = torch.randn(20, 16, 50, 100)
# output = m(input)
# print(output.size())
# 预处理网上找的飞机图片 先Resize成标准大小,然后转换H,W,C=>C,H,W,然后标准化
transform = transforms.Compose(
[transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
# 加载参数
net.load_state_dict(torch.load('Lenet.pth'))
im = Image.open('img.png')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]
with torch.no_grad():
outputs = net(im)
# 这里可以是输出最大的类的名字 也可以用softmax输出各种可能的概率
predict1 = torch.max(outputs, dim=1)[1].numpy()
predict = torch.softmax(outputs, dim=1)
print(classes[int(predict1)])
print(predict)
if __name__ == '__main__':
main()
这里是第一次记录,所以会比较细致的注释,后面应该代码就不粘贴了,篇幅比较大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号