高质量编程与性能调优实战(三)|青训营笔记
高质量编程与性能调优实战(三)|青训营笔记
这是我参与「第三届青训营 -后端场」笔记创作活动的的第三篇笔记。
本章目录:

这一节更偏向于文档,没有代码,这里就可以看PPT理解。
高质量编程
高质量编程简介
什么是高质量? --编写的代码能够达到正确可靠、简洁清晰的代码是高质量代码。
- 各种边界条件是否考虑完备
- 异常情况处理,稳定性保证
- 易读易维护
编程原则:

--Go语言开发者 Dave Cheney
编码规范
如何编写高质量的Go代码
代码格式
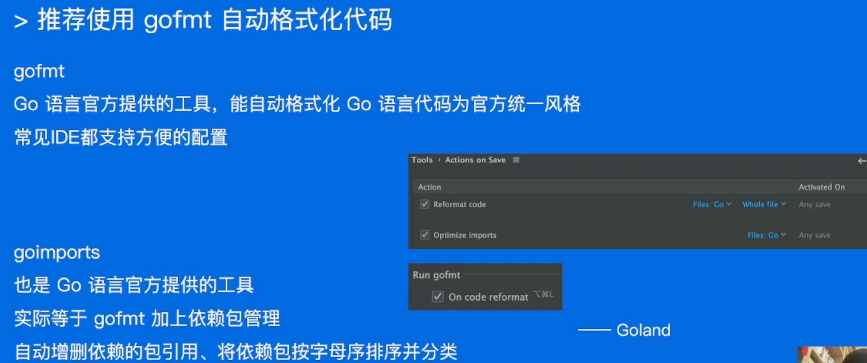
通过使用统一的管理工具,来让所有人的代码看起来一样。
注释
注释应该做的:
-
注释应该解释代码作用
-
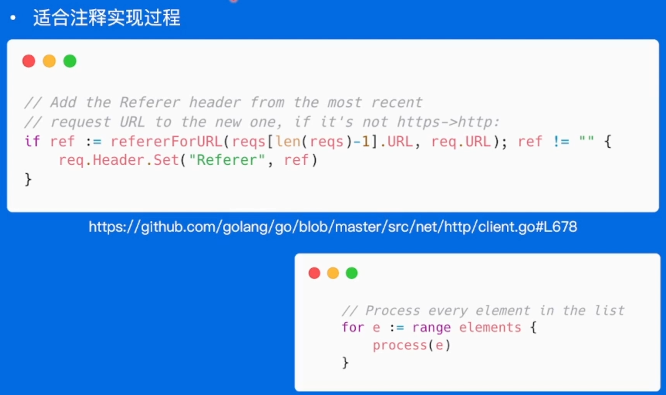
注释应该解释代码如何做的
在代码块儿上写注释。
-
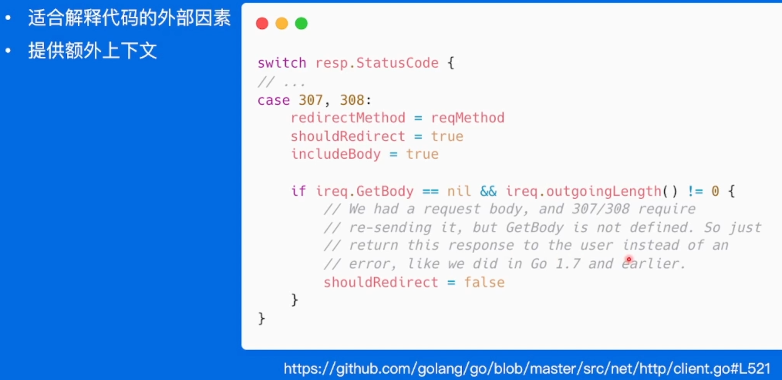
注释应该解释代码实现的原因
有些东西脱离上下文会很难理解,因此要加上上下文和外部因素。
-
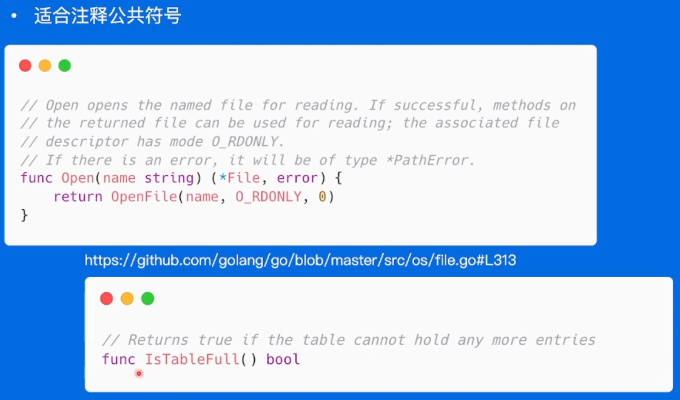
注释应该解释代码什么情况会出错

-
公共符号始终要注释
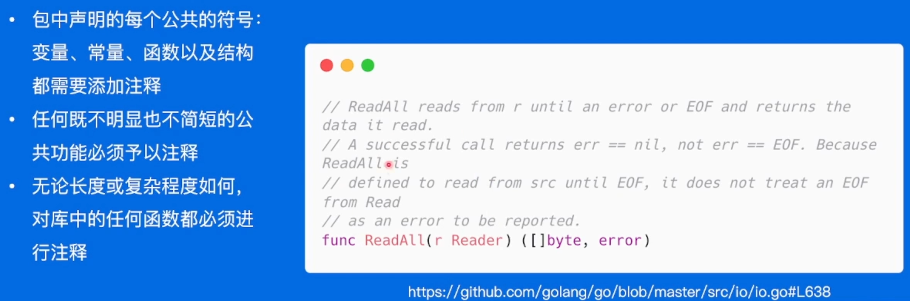
反例:

好的代码有很多注释,坏代码需要很多注释。
命名规范
- variable变量

- function函数

- package包

核心目标是降低阅读理解代码的成本;重点考虑上下文信息,设计简洁清晰的名称。
好的命名就像一个好笑话,如果你必须解释它,那就不好笑了。
控制流程
- 避免嵌套,保持正常流程清晰。

如果两个分支中都有return语句,则可以去除冗余的else。 - 尽量保持正常代码路径为最小缩进

这里嵌套太多,逻辑不清晰了,调整后变成这样。

控制流程小结:
- 线性原理,处理逻辑尽量走直线,避免复杂的嵌套分支。
- 正常流程代码沿着屏幕向下移动。
- 提升代码可维护性和可读性。
- 故障问题大多出现在复杂的条件语句和循环语句中。
错误和异常处理
-
简单错误
-
简单的错误指的是仅出现一次的错误,且在其他地方不需要捕获该错误
-
优先使用errors.New来创建匿名变量来直接表示简单错误
-
如果有格式化的需求,使用fmt.Errorf

-
-
错误的Wrap和Unwrap

-
错误判定
errors.is
用来替代==
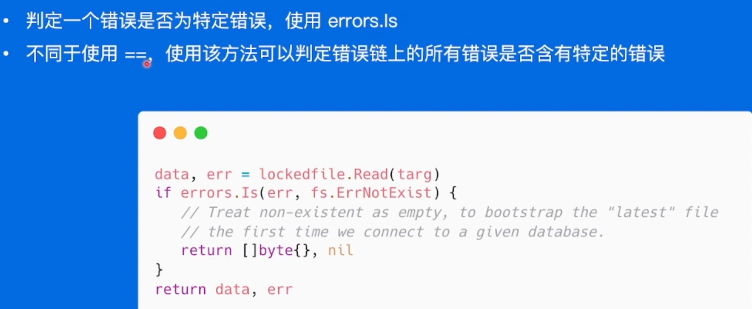
errors.As
可以看到错误信息。
-
panic
无法处理的错误,程序直接终止。

-
recover
当引用别人的包出现panic时,避免影响到自己的逻辑


错误和异常处理小结:

性能优化建议
Benchmark
这里的示例建议下载代码跟着走。
-
代码运行
我们要对strat文件夹下的fib.go进行基准测试,可以把终端切换到fib.go目录下,使用命令go test -bench=. -benchmem
也可以通过运行fib_test.go,里面引入了testing包,可以相当于运行了上面的命令。package start import "testing" // BenchmarkFib10 run 'go test -bench=. -benchmem' to get the benchmark result //这里就说明testing包可以替代语句的意思 func BenchmarkFib10(b *testing.B) { // run the Fib function b.N times for n := 0; n < b.N; n++ { Fib(10) } } -
结果说明

Slice
-
Slice 预分配内存


slice有点像java里的ArrayList,当容量不够的时候会自行进行扩容,如果cap容量够的话,直接加就行了。
扩容也是比较耗费时间的。 -
另一个陷阱:大内容未释放
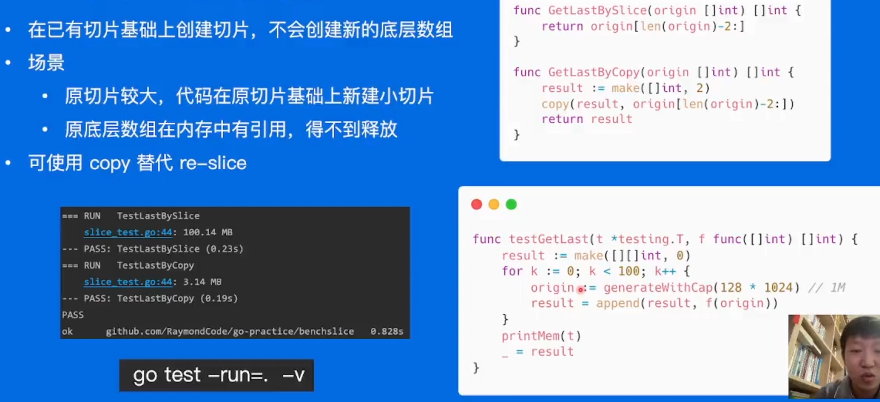
不要用[:2],而是用copy复制。
这种test的不知道为啥,得用命令去测试,也是切换到路径下直接跑就行,没有左边的对勾可以点。 -
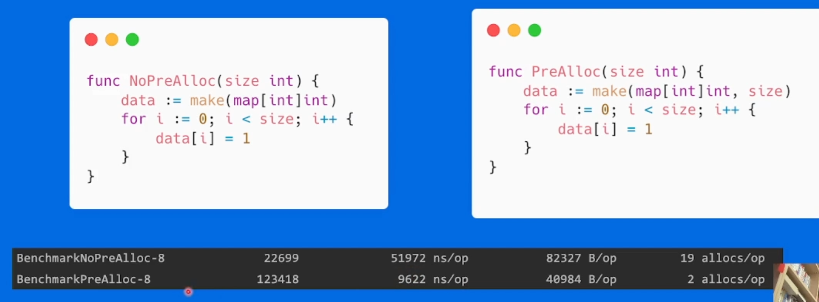
map 预分配内存

字符串处理
使用strings.Builder
直接字符相加和builder的对比。

+号 buffer builder对比
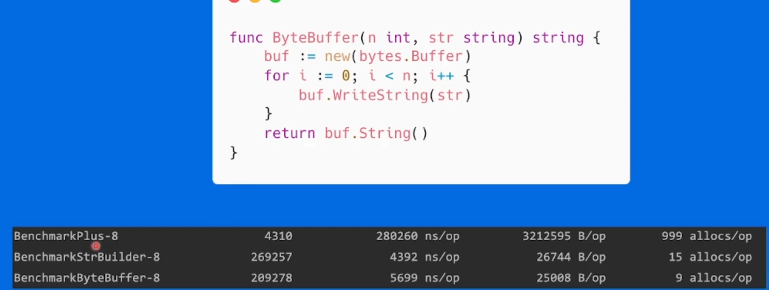

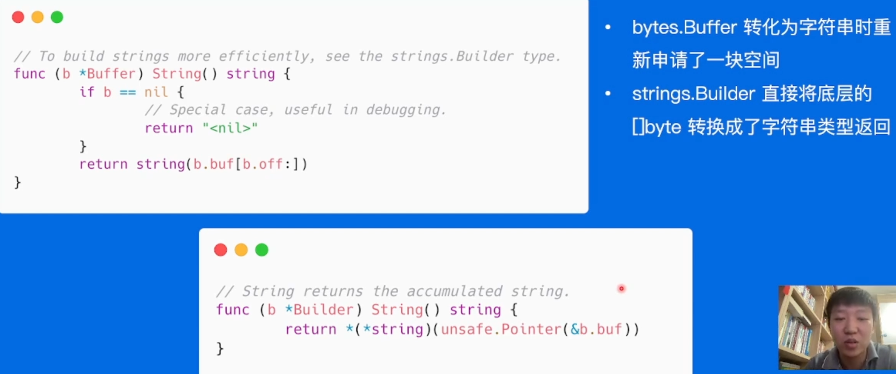
底层分析,buffer多申请了一次内存,builder是unsafe的,少申请一次内存。
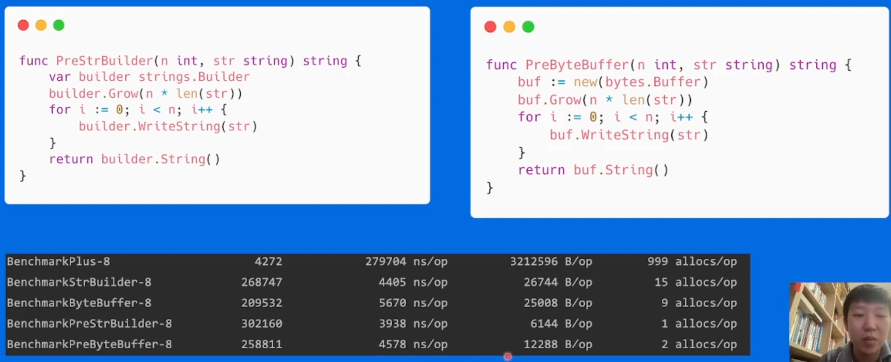
对buffer和builder进行预分配
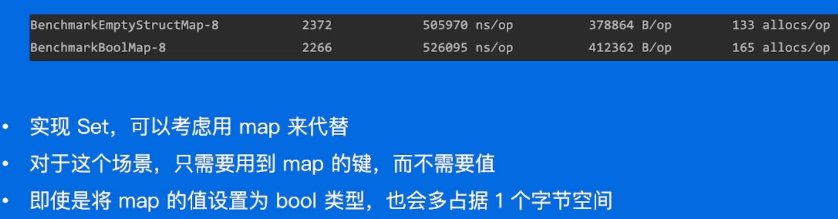
空结构体
使用空结构体节省内存

对两种不同的map空间大小比较,int:空结构体和int:boolean
atomic包
如何使用atomic包
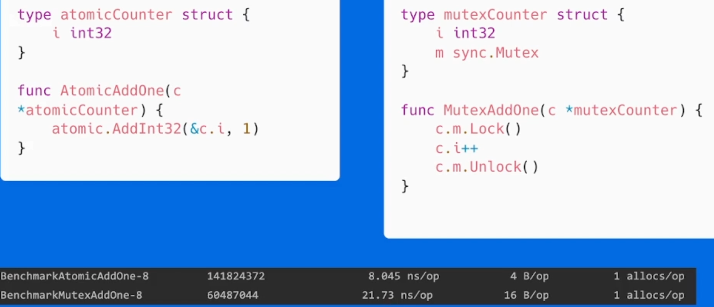
对变量的加原子锁,要比正常的锁好很多。

小结

性能调优实战
性能调优简介
- 要依靠数据不是猜测
- 要定位最大瓶颈而不是细枝末节
- 不要过早优化
- 不要过度优化
性能分析工具pprof实战
这里要先安装graphviz-2.44.1-win32软件,不然后面的图像无法使用。
功能简介
搭建pprof实践项目
运行程序
这里需要提前下载对应的代码,链接在图中。

然后go run main.go,程序就跑起来了。
接下来就可以在浏览器中查看指标
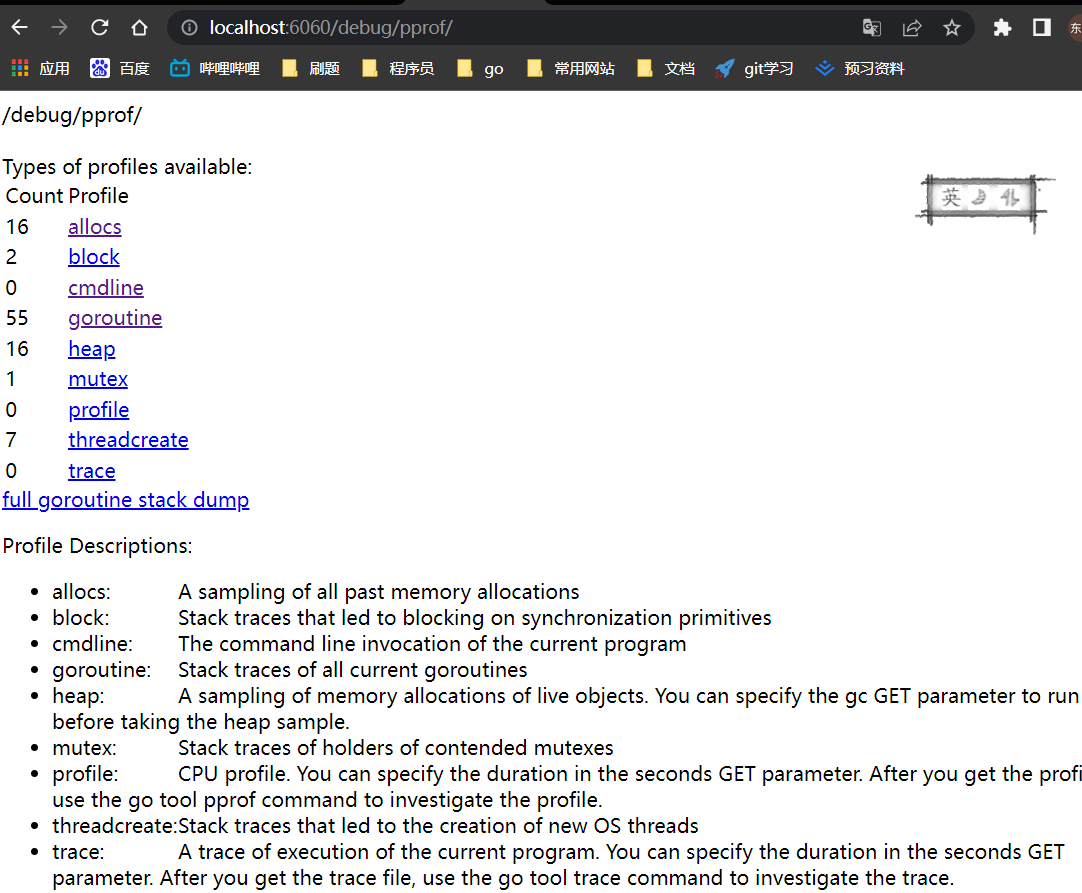
需要在网址中输入对应的链接,http://localhost:6060/debug/pprof/
里面的链接具体是什么内容在下面有英文的介绍,可以点进去看一看,会发现数据平铺出来很难直观的去观察。
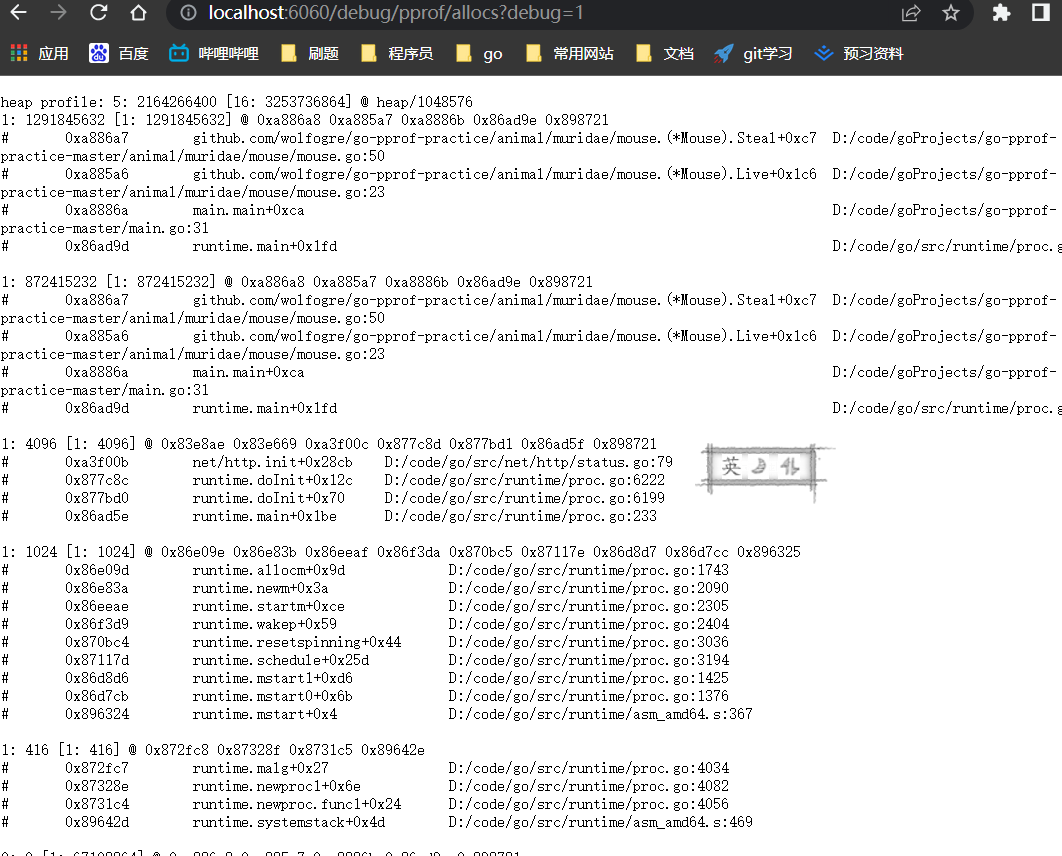
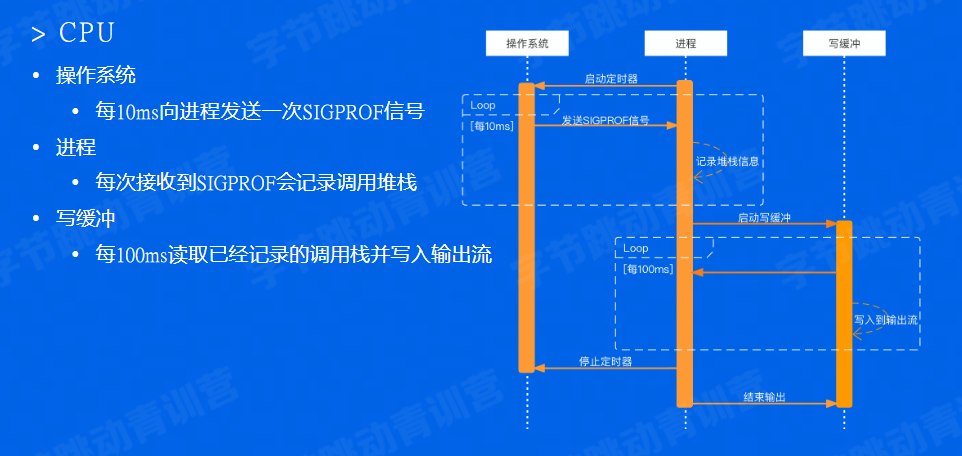
CPU占用情况
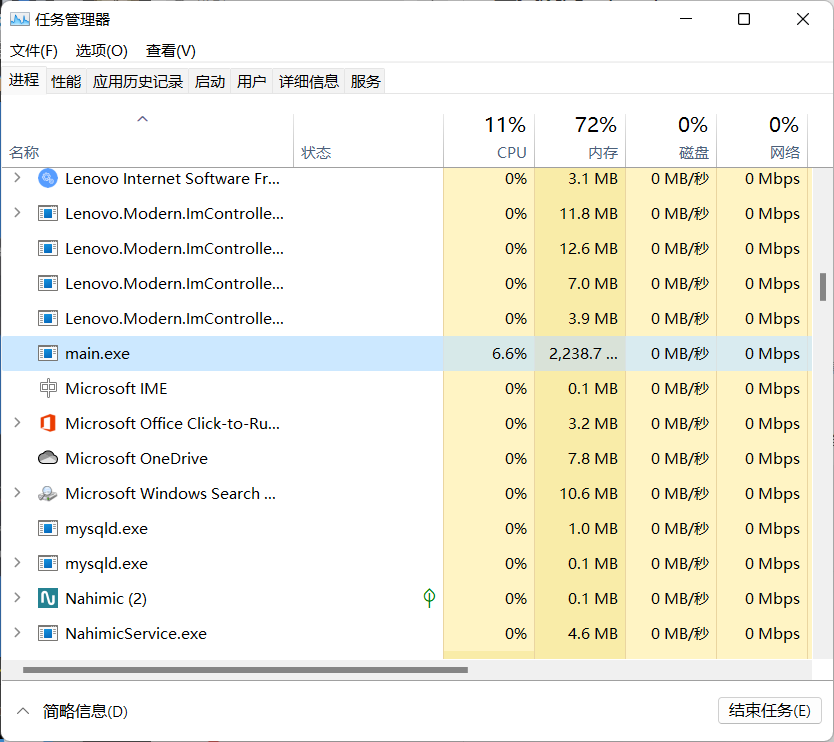
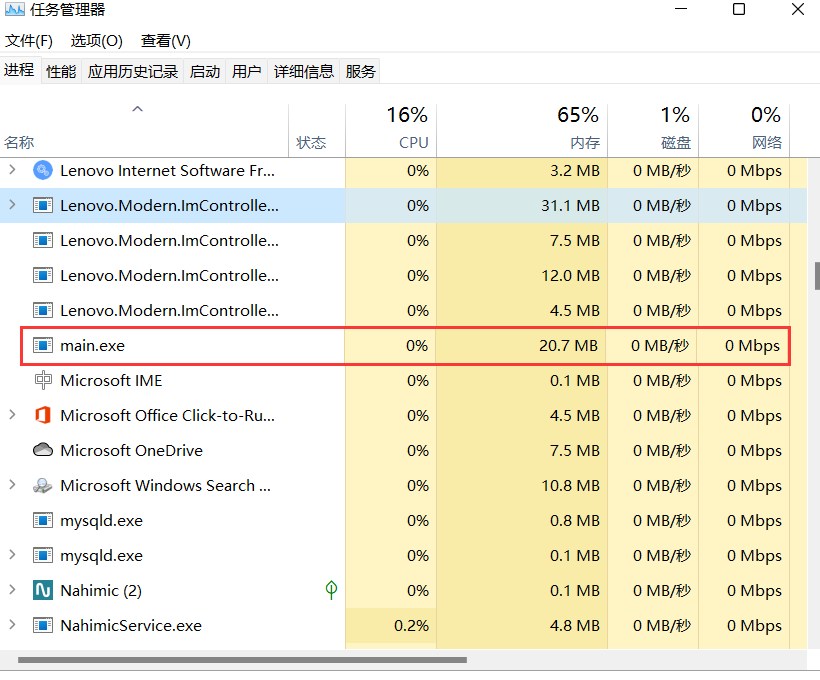
在任务资源管理器中可以看到这个main.exe占用了相当多的CPU和内存。
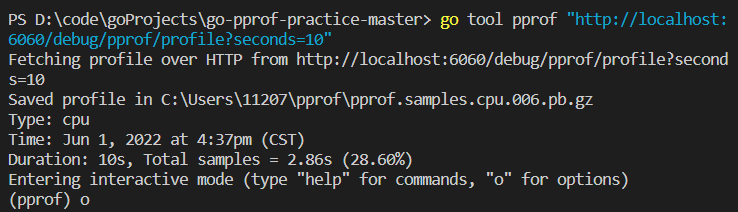
启动完pprof的示例项目后,在命令行输入 以下命令可以查看CPU的占用
go tool pprof "http://localhost:6060/debug/pprof/profile?seconds=10"
命令行会有如下产生:
输入top会得到查看占用资源最多的函数:
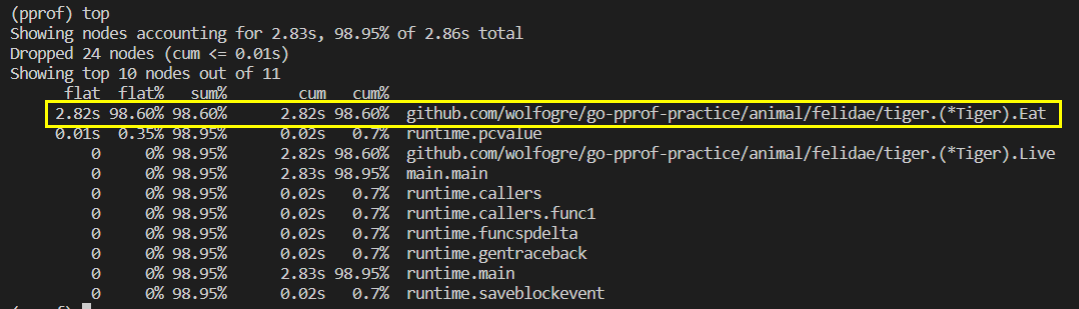
可以看到Tiger.eat函数消耗了最多的资源。表头代表的含义如下:
Flat0代表直接调用了别的函数,自己啥也没有。
FlatCum代表没有调用别的函数,全是自己消耗的。
可以使用list命令,根据指定的正则表达式查找代码行。
因为我们是Tiger的Eat函数占用的多,所以我们使用list Eat命令
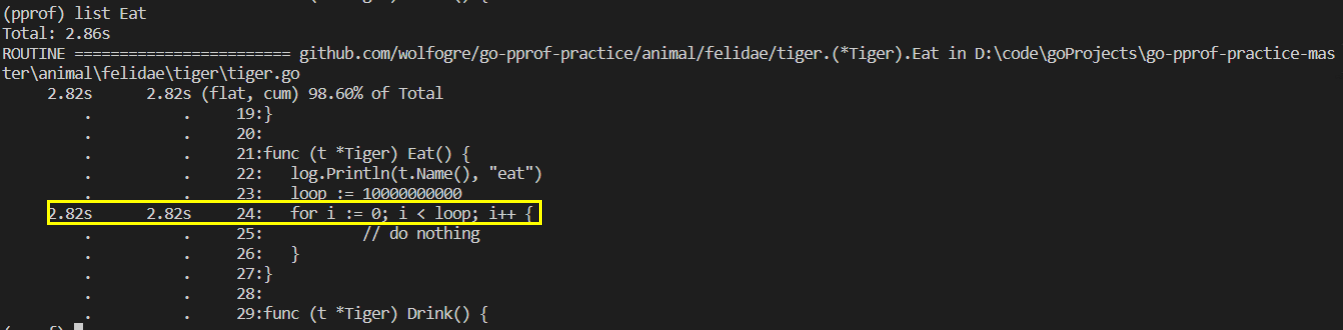
因此可以找到了CPU消耗问题最大的代码。
有的时候命令行不够直观,这个时候,我们可以使用web命令:
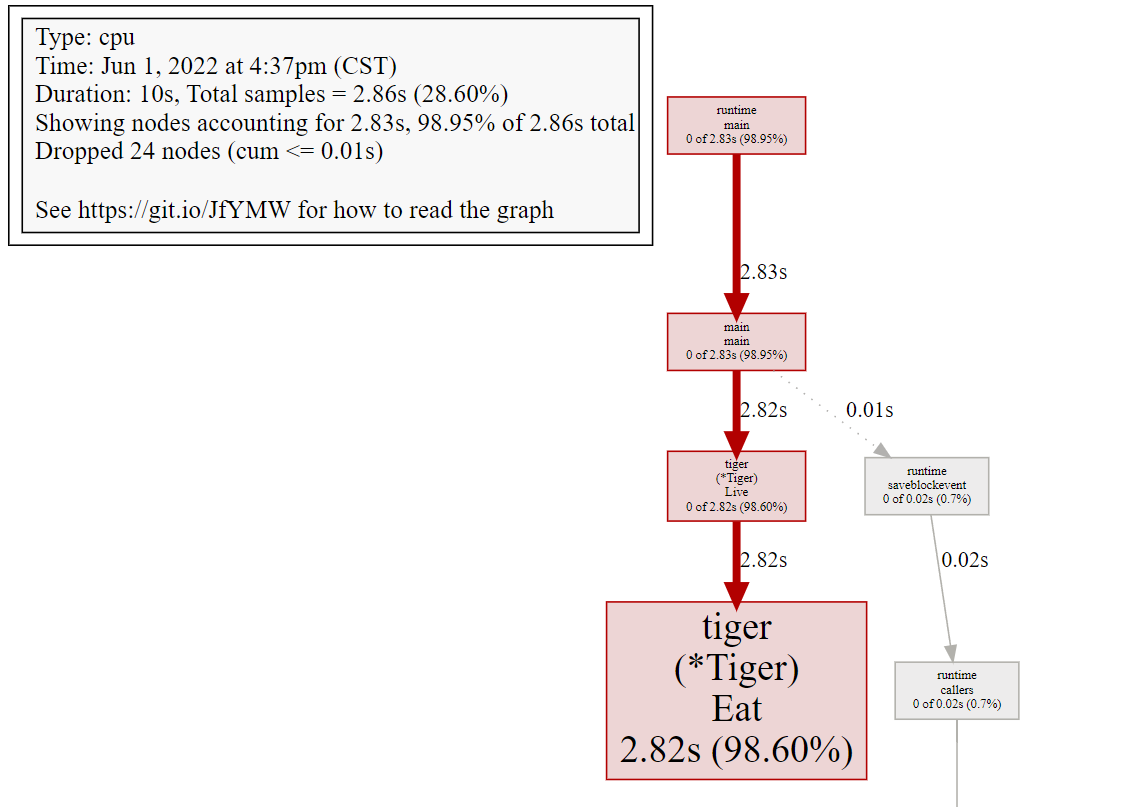
其会打开一个页面,发现这个吃了很多资源的函数。
我们将其注释掉后,重新运行程序并在资源管理器中查看:
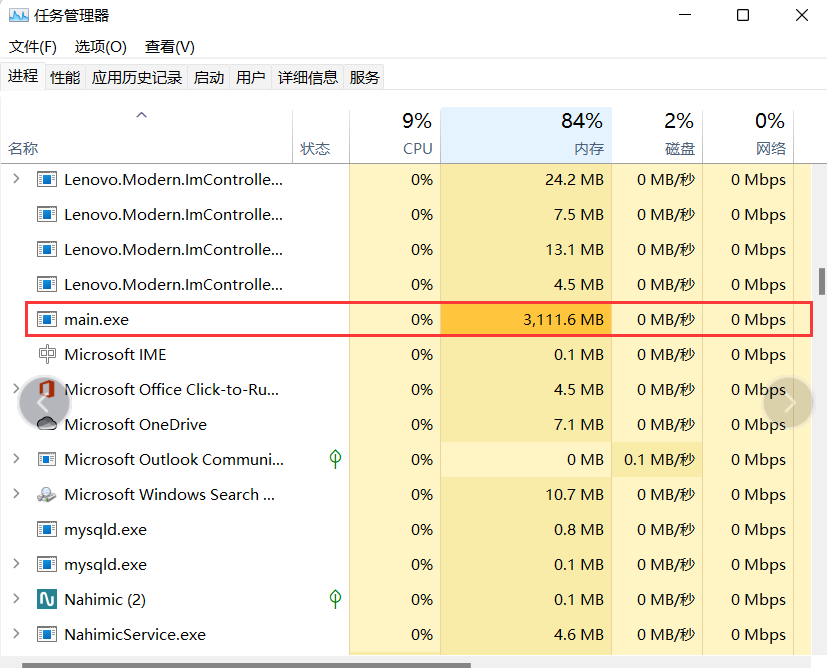
发现CPU的占用问题已经解决,而内存还需要解决。
Heap-堆内存
占用了两个多G的内存,刚才我们使用的是pprof终端的方式,不是很明确,这时我们可以通过页面查看。而且里面的内容都是和内存占用相关的,因为最后的后缀是heap。
go tool pprof -http=:8080 "http://localhost:6060/debug/pprof/heap"
其中http就是要新打开的端口,执行命令后会弹出页面:
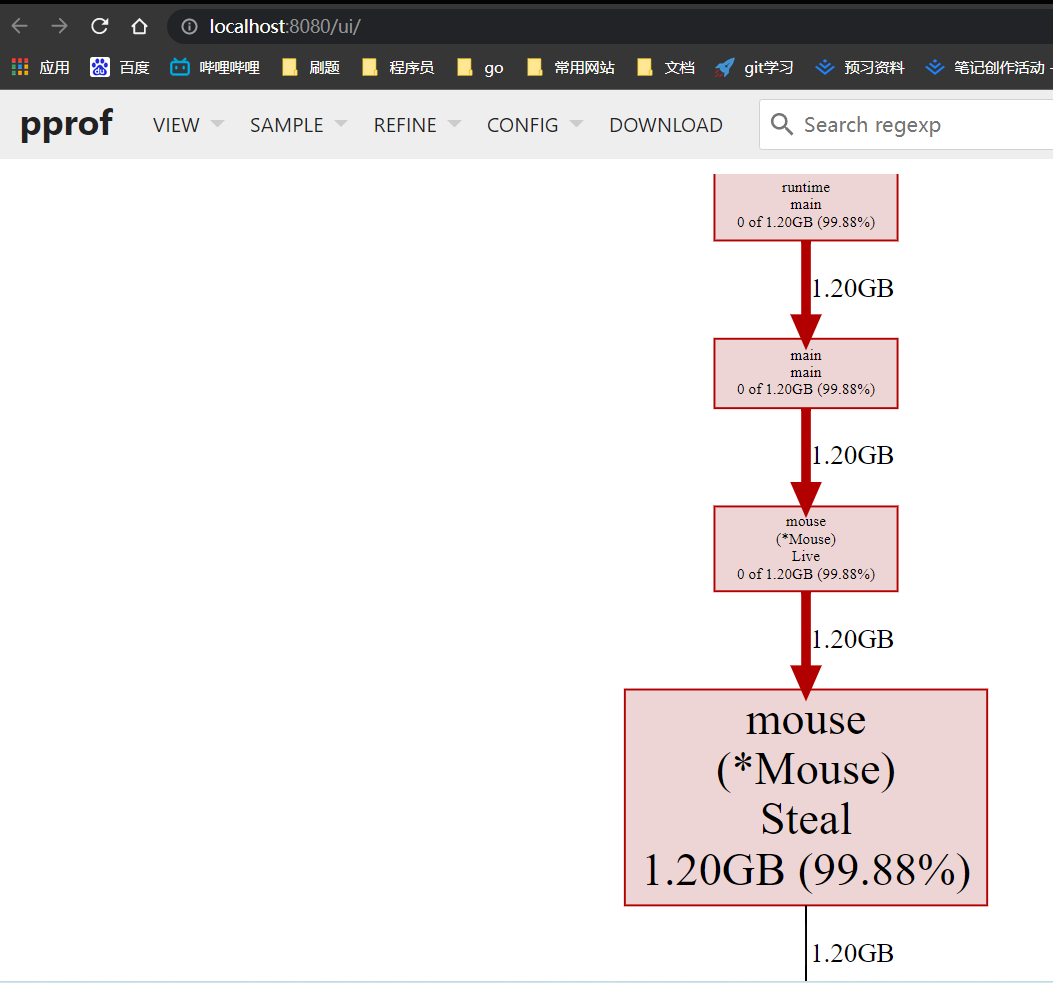
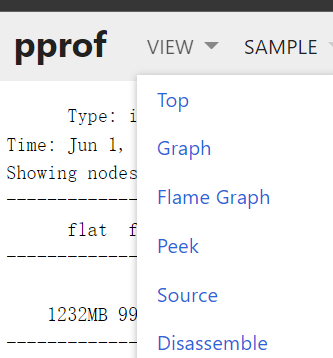
VIEW下面的按钮和终端是类似的,可以直观的查询各种数据。
TOP视图:
Source视图:

在将Mouse中的多余代码注释后,在任务管理器中可以看到内存占用恢复正常:
可以在最右侧发现目前是Unkown inuse_space。
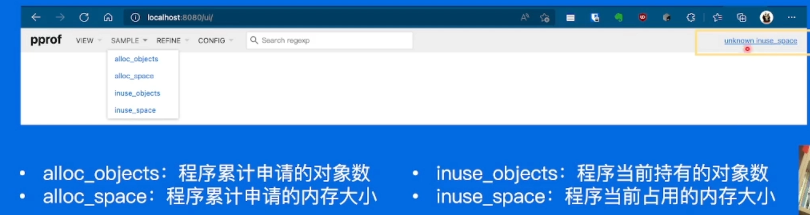
我们可以通过点击SAMPLE切换到Unkown alloc_space,从而发现新的问题。
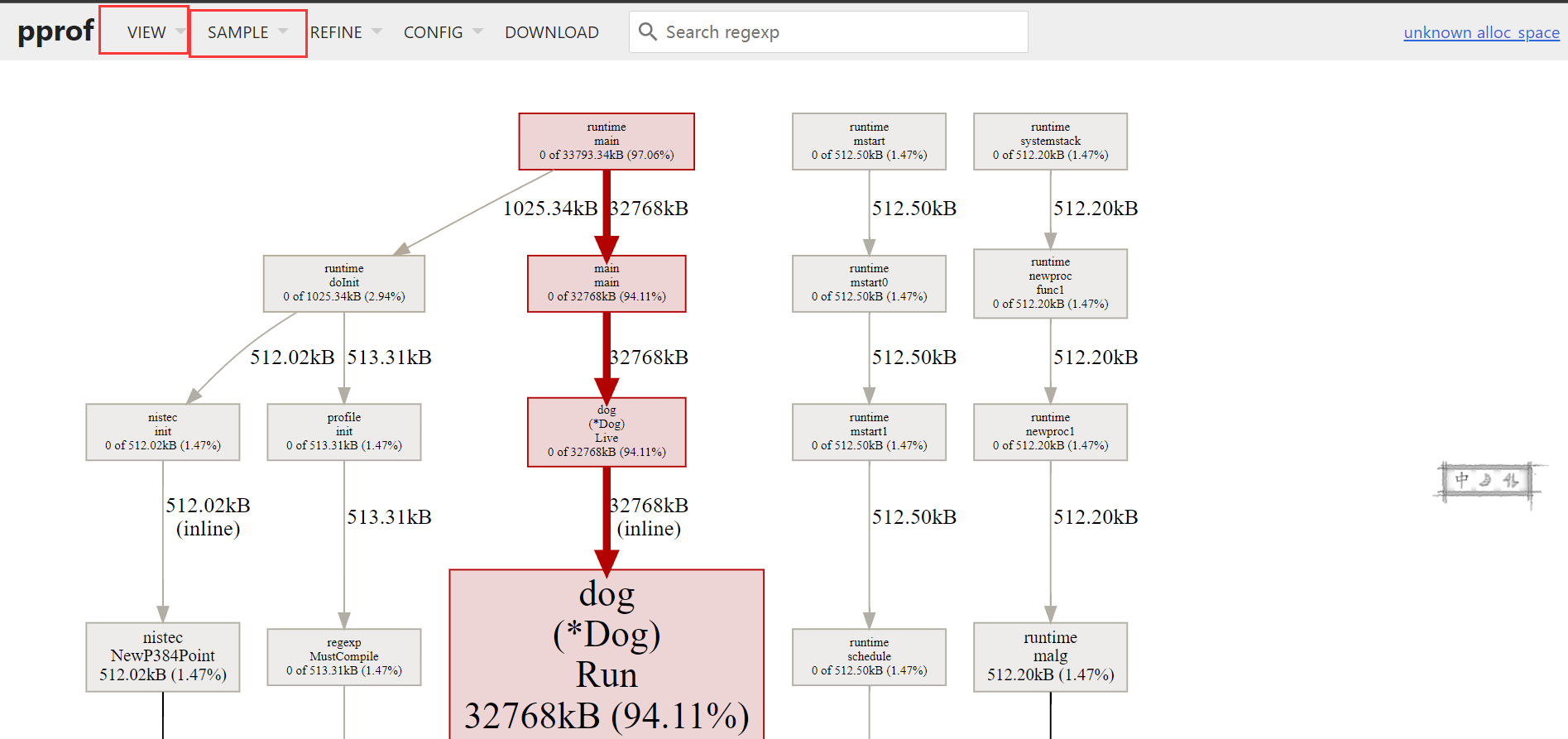
切换到Souce可以找到对应位置的代码:
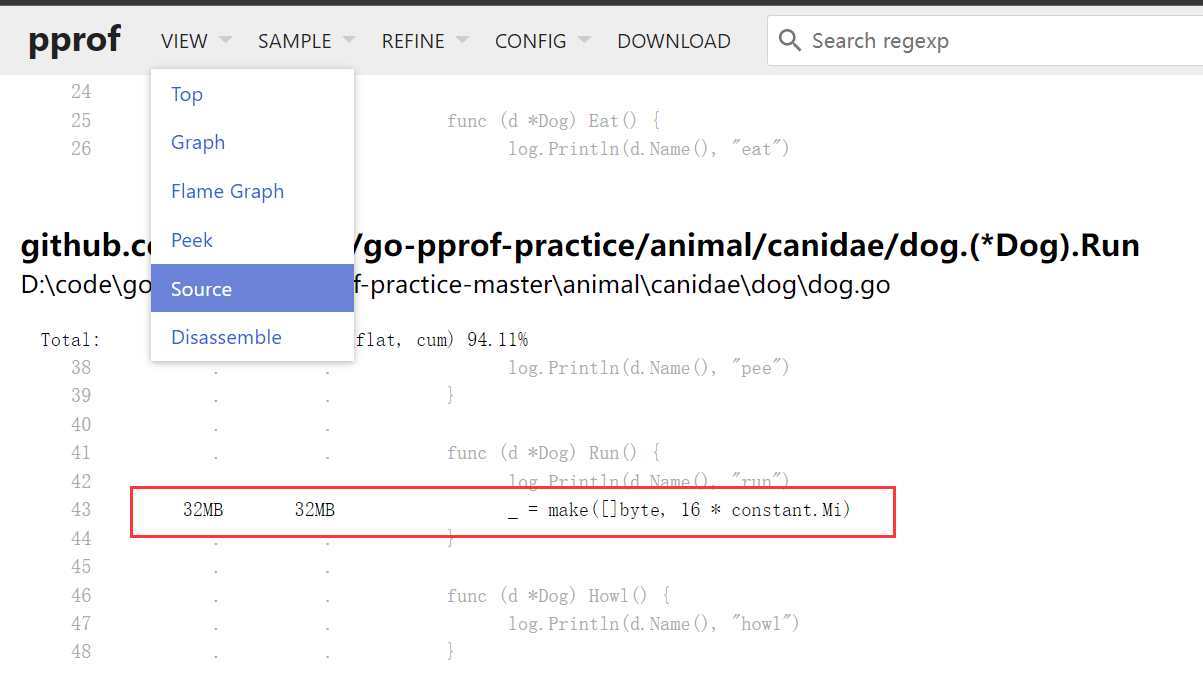
发现每次会申请一个16M的内存
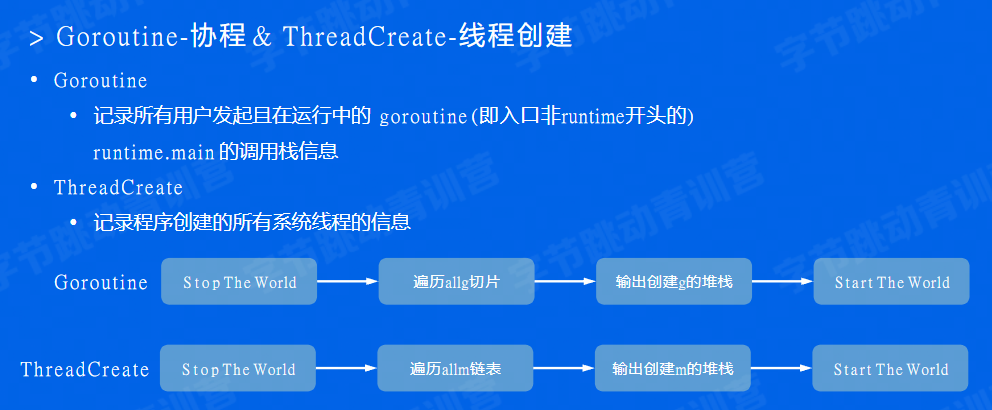
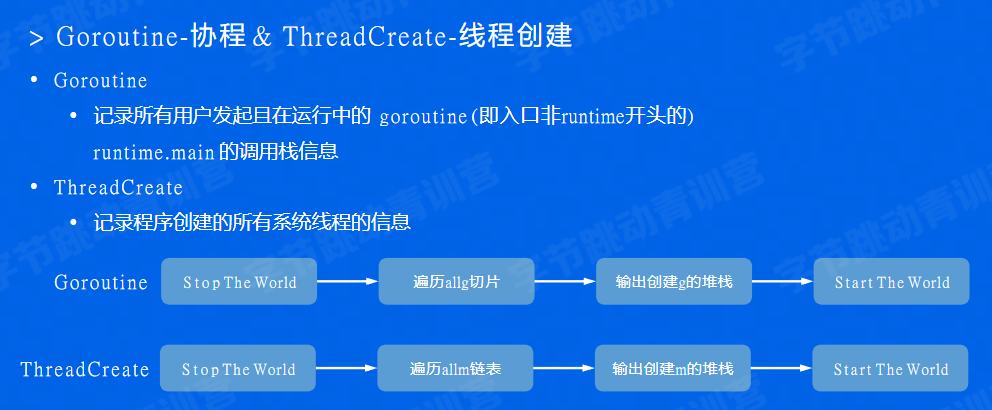
goroutine-协程
goroutine泄露也会导致内存泄露。
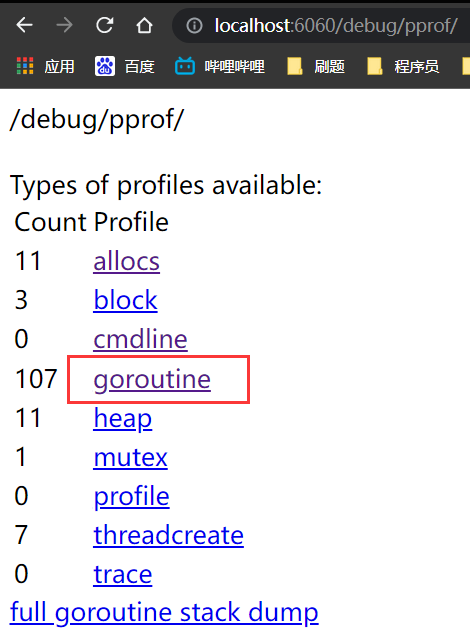
我们可以使用命令:
go tool pprof -http=:8080 "http://localhost:6060/debug/pprof/goroutine"
来查看协程情况:
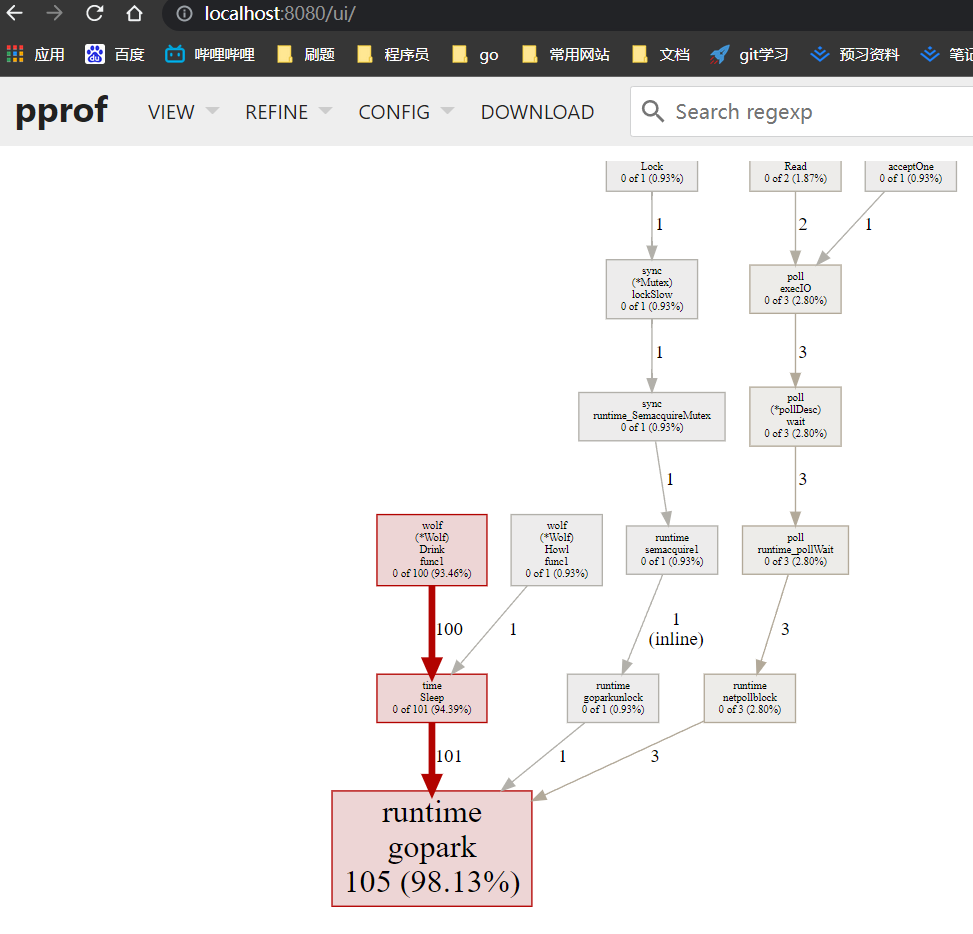
这种图过于长了,对于协程来说,我们可以通过火焰图来查看,即点击VIEW,选中Flame Graph:

火焰图的特性:

鼠标悬浮上去发现,wolf占用了93.46%,切换到Source页面并在搜索框搜索wolf:
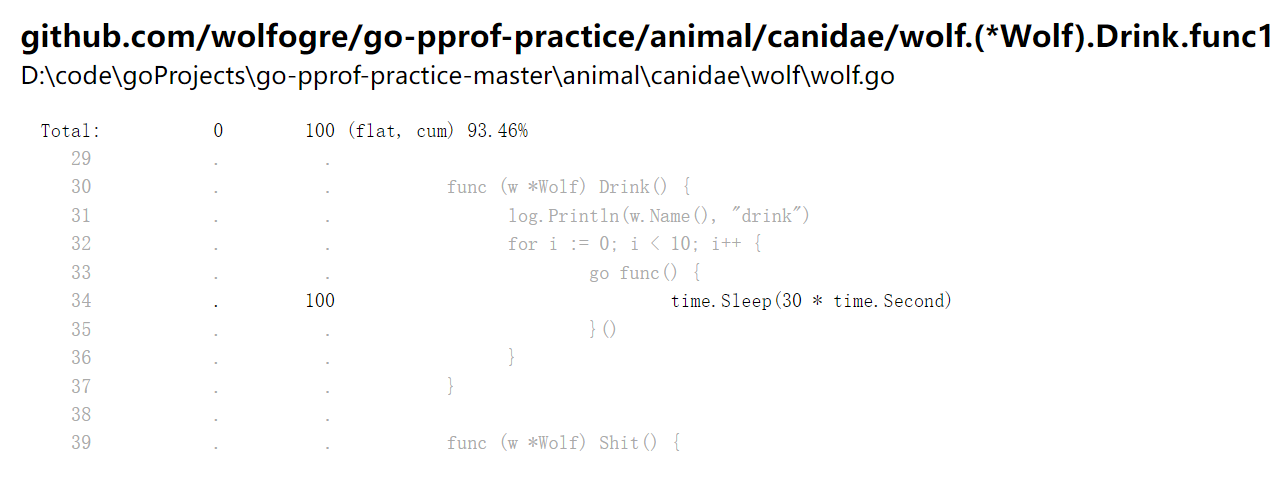
定位到问题所在,把这行代码注释掉,再看,
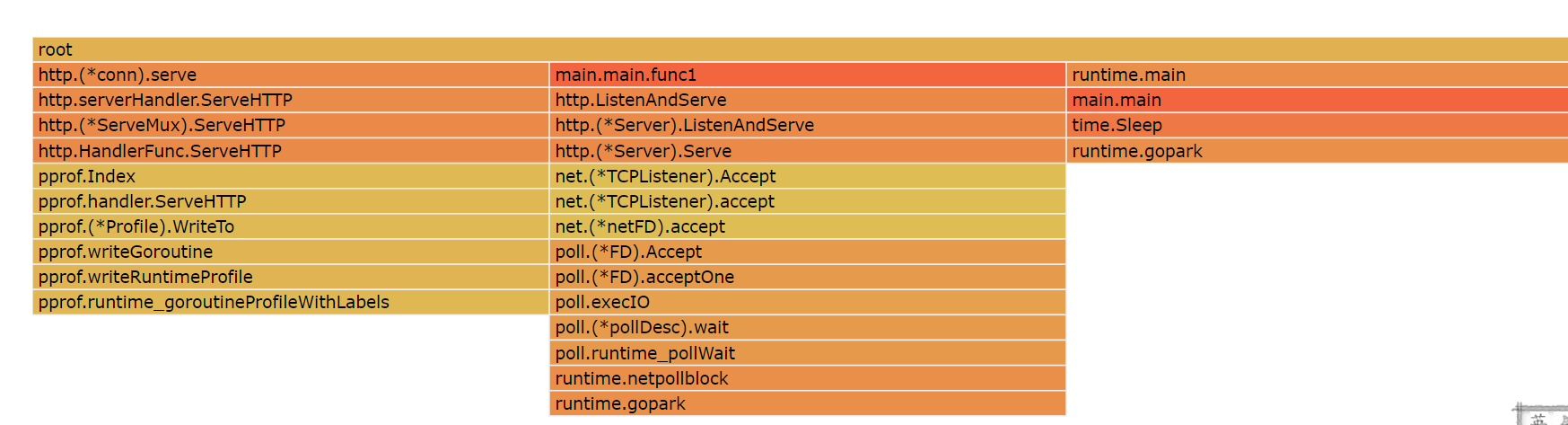
此时火焰图中的长度是比较正常的,没有那种协程大量占用CPU的情况。
mutex-锁
go tool pprof -http=:8080 "http://localhost:6060/debug/pprof/mutex"
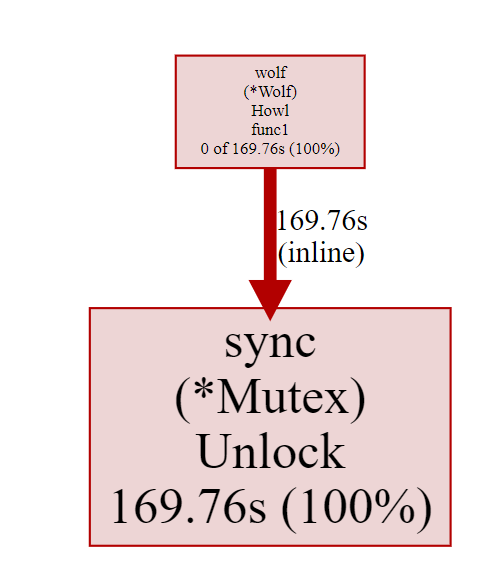

将对应代码注释后,直接没了,因为没有锁的情况了。
block-阻塞
go tool pprof -http=:8080 "http://localhost:6060/debug/pprof/block"
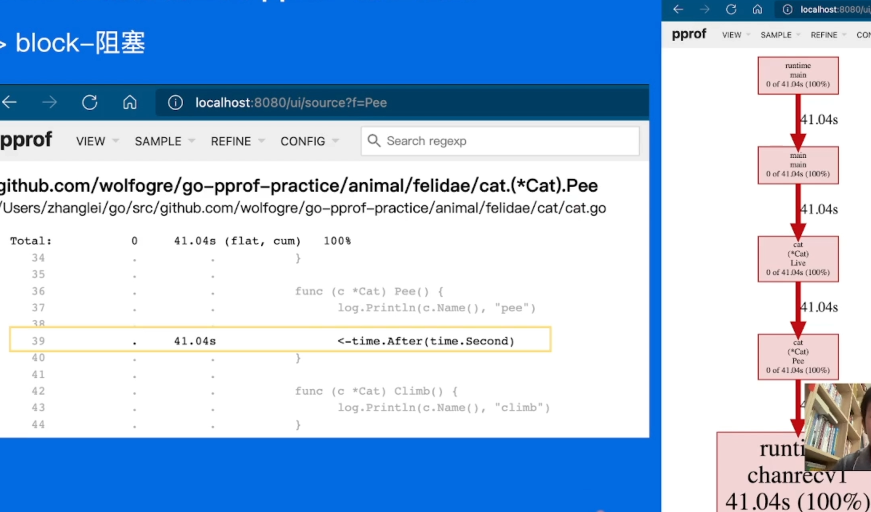
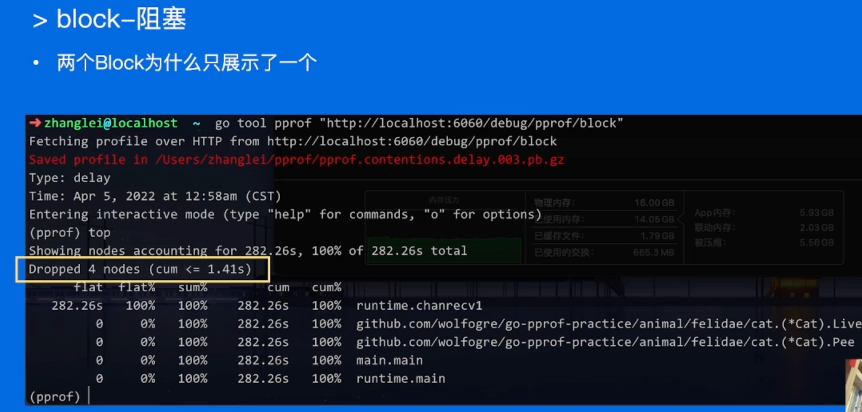
后面好像是删了哪里了,复现不了了。。。大致已经了解怎么做了,记得每次去6060的页面查看还有多少需要修改。
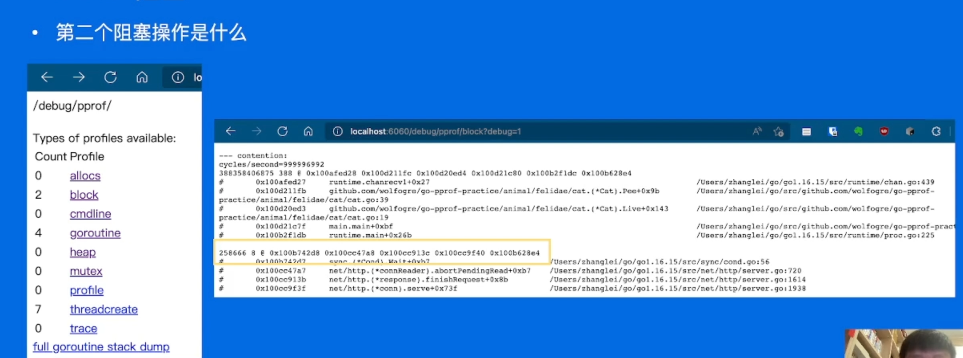
发现是http的那些,不用管了。
小结
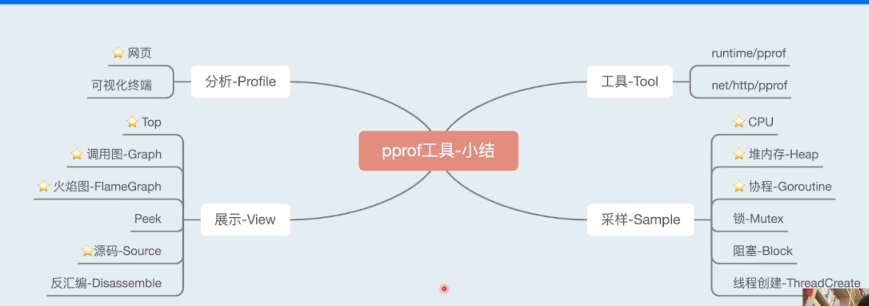
pprof-采样过程和原理

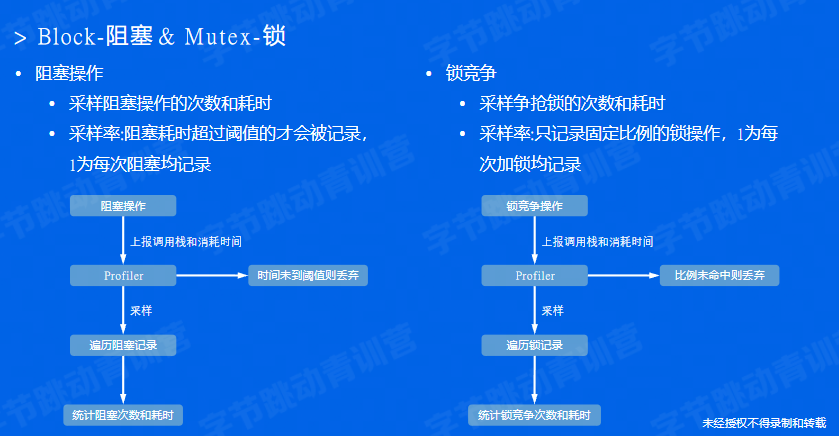

性能调优案例
介绍实际业务服务性能优化的案例;对逻辑相对复杂的程序如何进行性能调优。
概念介绍:
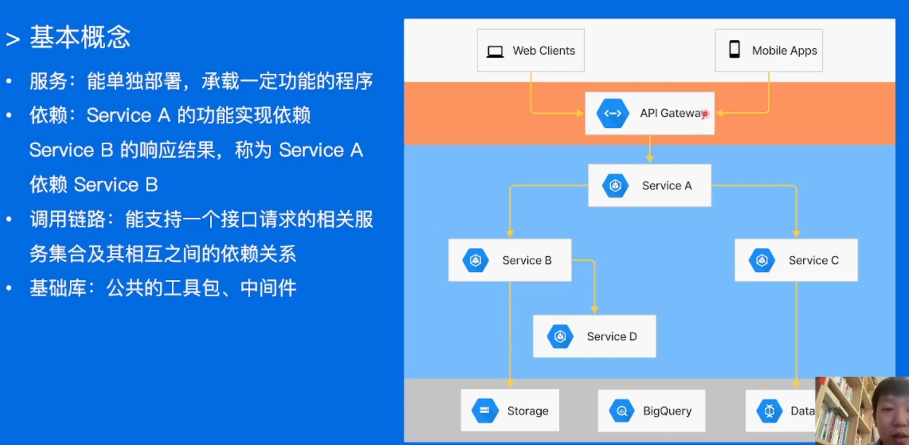
从客户端和手机端发送请求到网关,网关将请求交给服务。假设ServiceD就是日志记录的库,就是基础库。
-
业务服务优化
面向用户提供的一些功能,点赞评论之类的。
流程分四步:-
建立服务性能评估手段
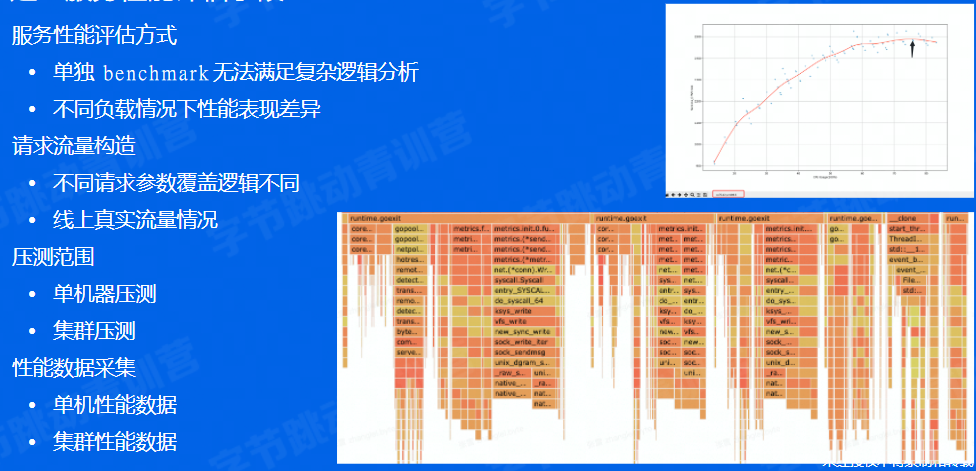
右上角的图:在集群CPU利用率逐渐上升的时候,流量承载能力可能会逐渐到达瓶颈,这个时候可能会需要一些优化之类的。
右下角是一个线上的项目,火焰图可以点,点开看这个节点的子节点情况,很适合线上项目分析。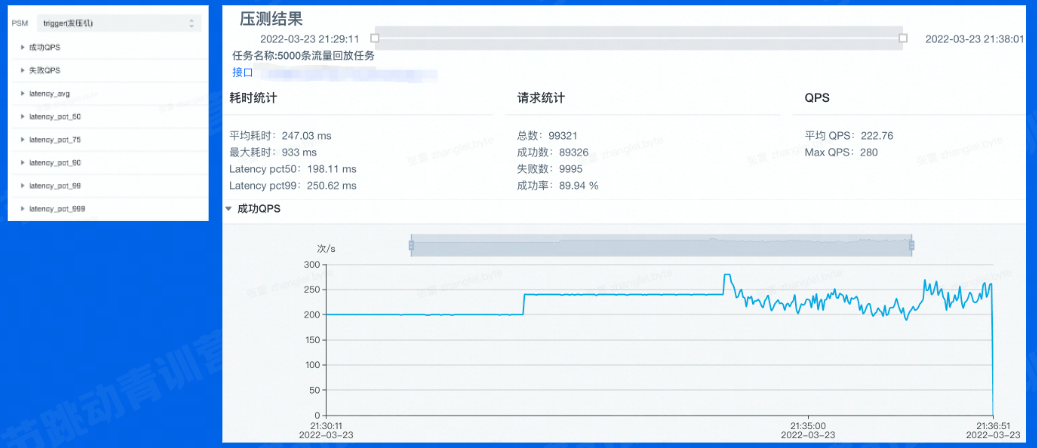
压测会产生一个压测报告,后面压力升上去后会出现波动,说明需要优化。
-
分析性能数据,定位性能瓶颈
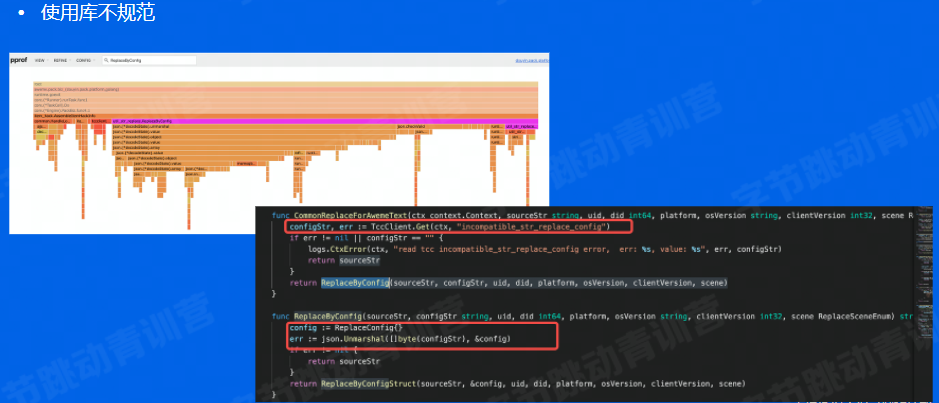
这个火焰图可以看到某个点占用CPU时间很长,定位到代码发现是json解析每次都做,其实是可以变更的时候再做,这样会优化很多。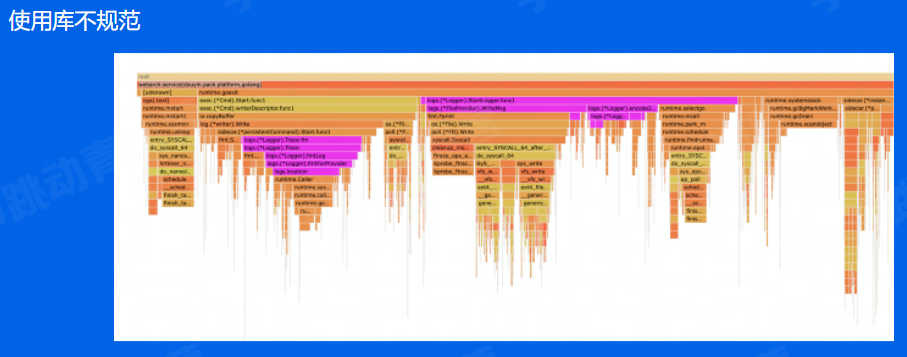
日志如果打印的很多也会出现CPU过高,可以在pprof搜索log来标记那些用了日志服务,占了多久CPU。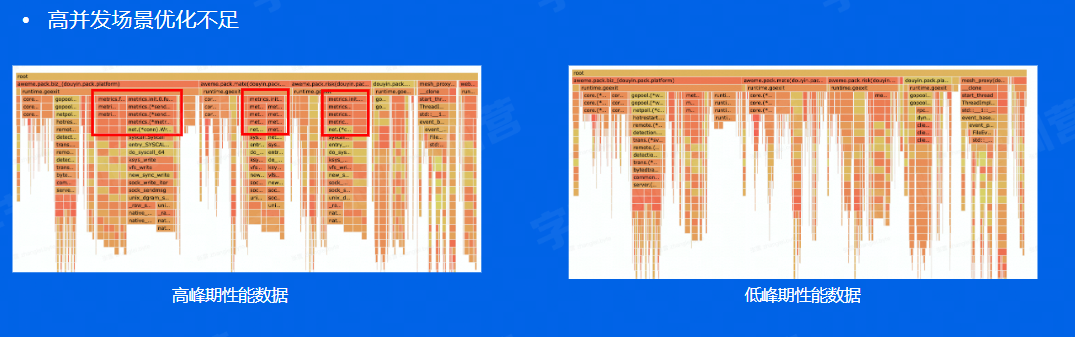
CPU占用率80%和40%各记录一次火焰图,可以找到一些高峰期中性能优化不好的地方,可以看到在标记出来的位置,占用CPU时间显著变长。
原因:matrix库,再上报的时候一直在用同步请求上报,CPU占用率高的时候,打点就比较多,容易触发性能瓶颈,造成阻塞,影响业务处理。
处理方式:因为监控上报并不是一个实时性要求特别高的场景,其实也提供了异步上报的机制,改成异步后就好了。 -
重点优化项改造
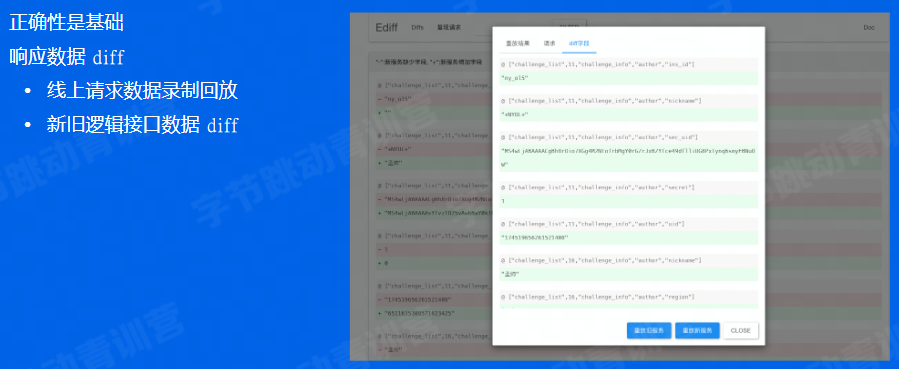
正确性是基础,因此需要一些工具辅助我们进行判断,是否正确。
方式:把线上的流量请求和返回值都录制下来,完成性能优化后,看相同的服务是否能获得同样的结果。(类似于单元测试hhh) -
优化效果验证
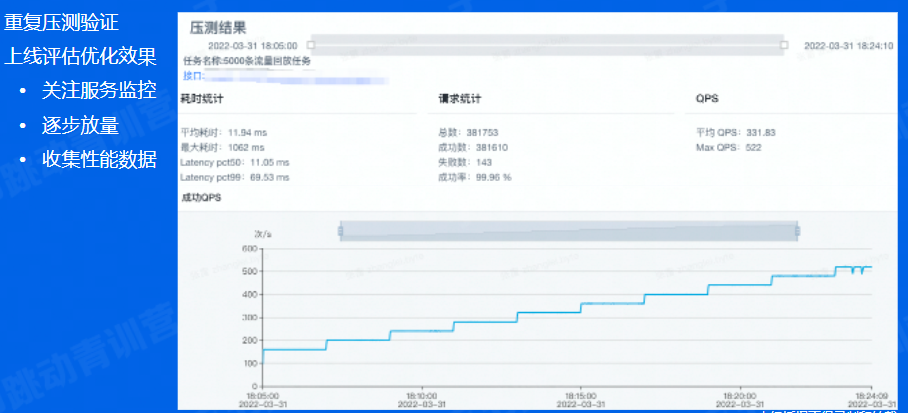
-
进一步优化,服务整体链路分析
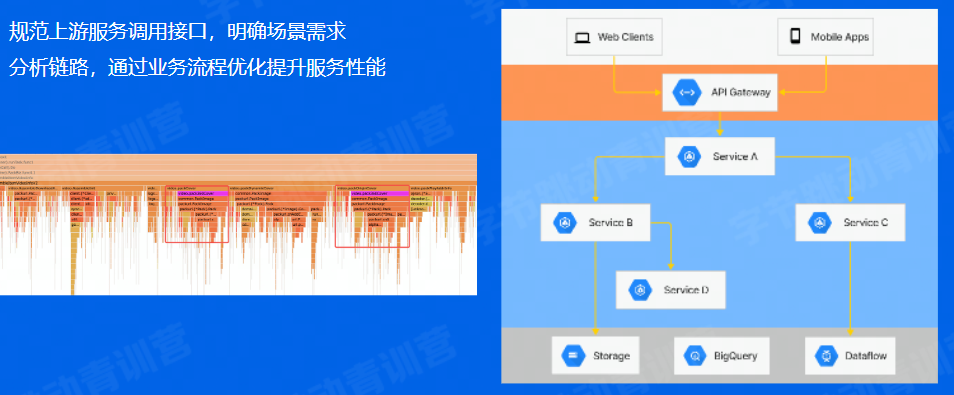
在熟悉了上下游后,可以进一步优化整个服务。
比如在Service A调用Service B的时候,如果有更小的输入集满足Service B的需要,那么这两者之间网络传输的消耗就会更小,就可以获得更快的响应。
比如Service A是否是实时的需要Service B的数据,是不是可以加一个缓冲,缓解压力。
因为A的逻辑比较复杂,可以检查是否多次调用了服务B,这一点也可以通过火焰图来观察,如果在不同位置重复调用了,那对A和B都带来了不必要的压力,可以优化。
这种调用需要对完整的链路进行分析,对具体的场景需要分析。
-
-
基础库优化
监控打点、日志之类的,不会独立的进行部署。
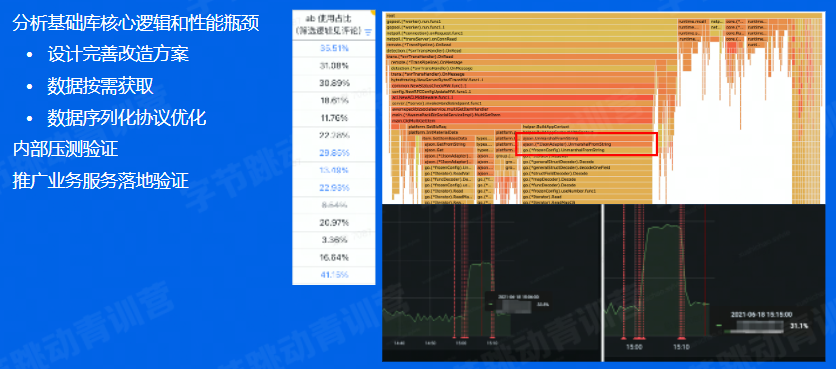
如果程序调用到AB实验的代码,会有记录,可以优化。
右下角就是优化前后的上线后情况。
如果覆盖率上去的话,节省资源还是挺多的。 -
Go语言优化
对Go语言本身的优化。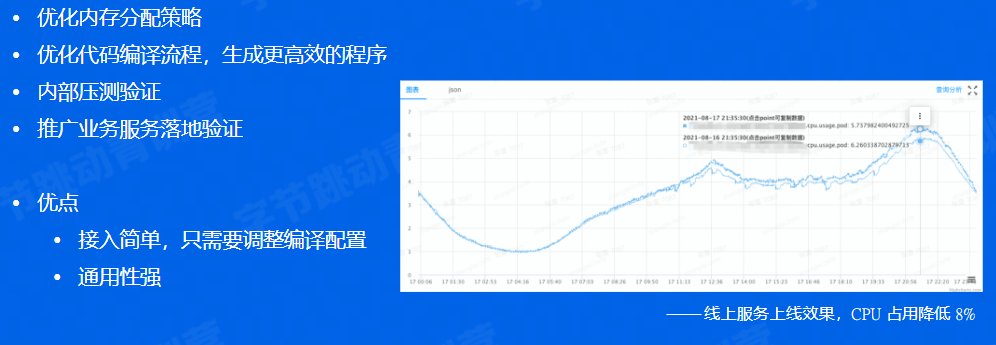
总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号