设计模式笔记
设计模式的目的

设计模式的七大原则
单一职责原则

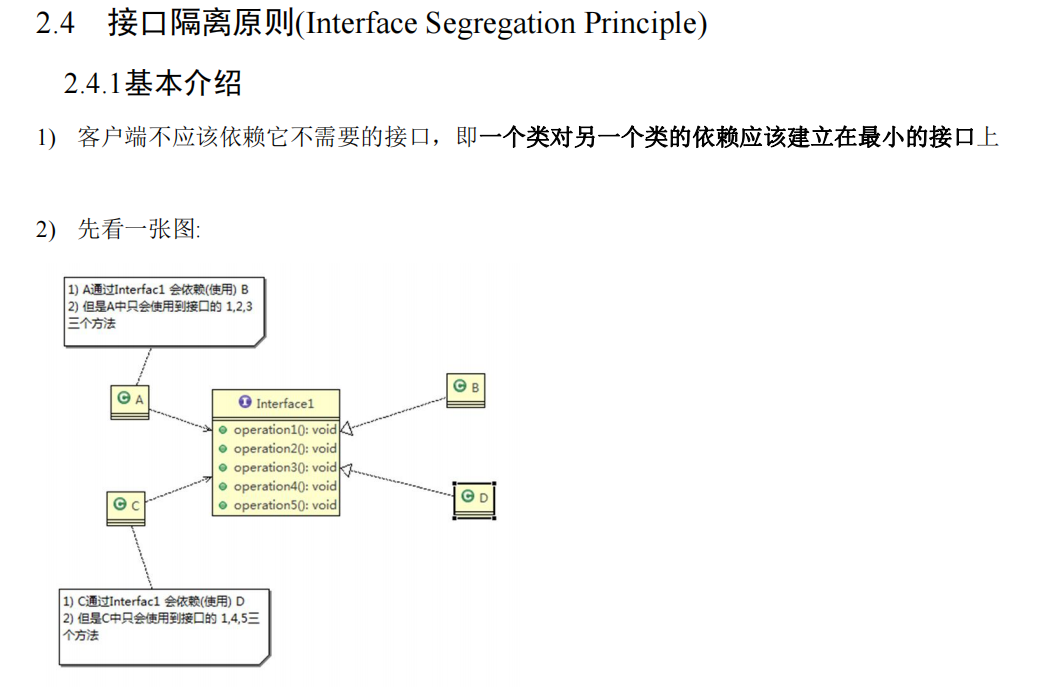
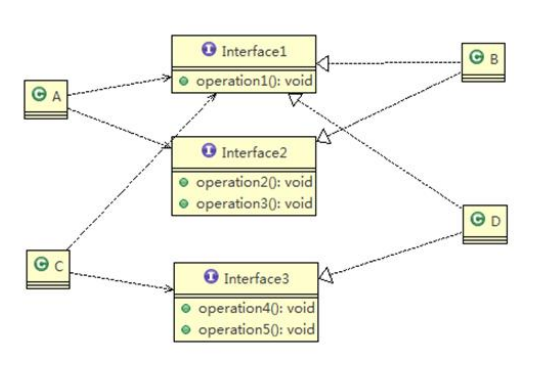
接口隔离原则
依赖倒转原则

具体来讲就是,关联的情况下,传入方法中的实例,应该上升为接口或者其父类,这样可以避免依赖具体的对象。
里氏替换原则

就是别重写父类方法就完事了。
开闭原则

就是那种工厂模式里面,ifelse写到了具体的类里面,这种应该交给工厂而不是每次修改类。
迪米特法则

最少知道原则,只与直接的朋友通信,陌生的类最好不要以局部变量的形式出现在类的内部。
合成复用原则
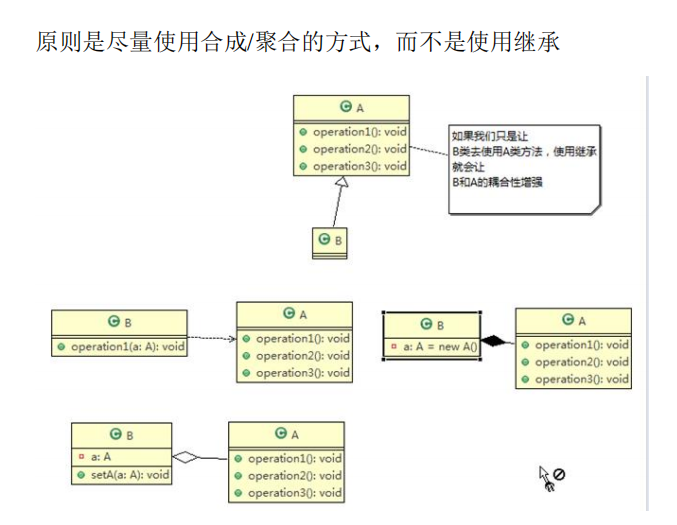
尽量减少继承,里氏替换原则是不要重写。
UML类图概念
线与概念对应关系
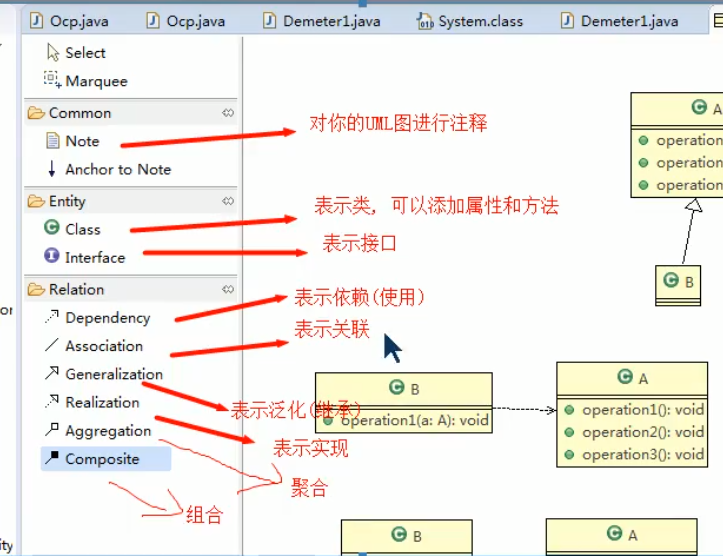
依赖(Dependency)
只要是在类中用到了对方,那么他们之间就存在依赖关系。如果没有对方,连编译都通过不了。
泛化(Generalization)
泛化关系实际上就是继承关系,他是依赖关系的特例。
实现(Implementation)
实现关系实际上就是A类实现B接口,他是依赖关系的特例。
关联(Association)
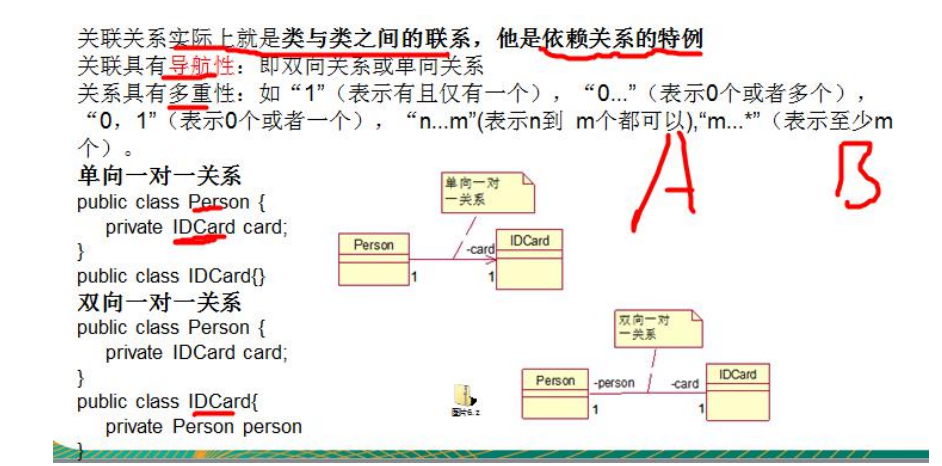
聚合(Aggregation)

组合(Composition)

创建型模式
Singleton(单例)模式
题目:设计一个类,我们只能生成该类的一个实例。
由于第一题主要讲的是C++语言特性,因此直接跳过,开始记录第二题。
单例模式分为懒汉式(需要才去创建对象)和饿汉式(创建类的实例时就去创建对象)。
饿汉式两种,其中Runtime是饿汉式的static类型。懒汉式中推荐enum枚举方法,DCL双重检查volatile,静态内部类。
-
饿汉式
该模式在类被加载时就会实例化一个对象。
-
属性实例化对象
//饿汉模式:线程安全,耗费资源。 public class HugerSingletonTest { //final 该对象的引用不可修改 private static final HugerSingletonTest ourInstance = new HugerSingletonTest(); //static 可以通过HugerSingletonTest.getInstance()实现调用。 //HugerSingletonTest hunger = HugerSingletonTest.getInstance(); public static HugerSingletonTest getInstance() { return ourInstance; } private HugerSingletonTest() {}//private 防止其他类初始化该类 }该模式能简单快速的创建一个单例对象,而且是线程安全的(只在类加载时才会初始化,以后都不会)。但它有一个缺点,就是不管你要不要都会直接创建一个对象,会消耗一定的性能(当然很小很小,几乎可以忽略不计,所以这种模式在很多场合十分常用而且十分简单)
PS:在看这块儿时发现static已经忘得差不多了,重新回顾了一下。。。static关键字的四种用法
-
这里还有一种是用静态代码块的 差不多就不贴了
-
-
懒汉式
该模式只在你需要对象时才会生成单例对象(比如调用getInstance方法)
-
非线程安全
public class Singleton { private static Singleton ourInstance; public static Singleton getInstance() { if (null == ourInstance) { ourInstance = new Singleton(); } return ourInstance; } private Singleton() {} }分析:如果有两个线程同时调用getInstance()方法,则会创建两个实例化对象。所以是非线程安全的。
-
线程安全:给方法加锁(资源消耗较大)
public class Singleton { private static Singleton ourInstance; public synchronized static Singleton getInstance() { if (null == ourInstance) { ourInstance = new Singleton(); } return ourInstance; } private Singleton() {} }分析:如果有多个线程调用getInstance()方法,当一个线程获取该方法,而其它线程必须等待,消耗资源。
这里的消耗资源主要是因为synchronized关键字加在了函数上。
-
线程安全:双重检查锁(DCL Double-Check懒汉式)
public class Singleton { //volatile的作用是:保证可见性、禁止指令重排序,但不能保证原子性 private volatile static Singleton ourInstance; public static Singleton getInstance() { if (null == ourInstance) { synchronized (Singleton.class) { if (null == ourInstance) { ourInstance = new Singleton(); } } } return ourInstance; } private Singleton() {} }分析:为什么需要双重检查锁呢?因为第一次检查是确保之前是一个空对象,而非空对象就不需要同步了,空对象的线程然后进入同步代码块,如果不加第二次空对象检查,两个线程同时获取同步代码块,一个线程进入同步代码块,另一个线程就会等待,而这两个线程就会创建两个实例化对象,所以需要在线程进入同步代码块后再次进行空对象检查,才能确保只创建一个实例化对象。
相较于上一个,因为是在函数内部加锁,所以消耗资源较少。
volatile作用:
- 创建一个对象,往往包含三个过程:对于singleton = new Singleton(),这不是一个原子操作,在 JVM 中包含的三个过程。
- 1.给 singleton 分配内存。memory = allocate();
- 2.调用 Singleton 的构造函数来初始化成员变量,形成实例。instance = (memory); 初始化对象
- 3.将singleton对象指向分配的内存空间(执行完这步 singleton才是非 null 了)。instance = memory;指向地址
- 但是,由于JVM会进行指令重排序,所以上面的第二步和第三步的顺序是不能保证的,最终的执行顺序可能是 1-2-3 也可能是 1-3-2。如果是 1-3-2,则在 3 执行完毕、2 未执行之前,被l另一个线程抢占了,这时 instance 已经是非 null 了(但却没有初始化),所以这个线程会直接返回 instance,然后使用,那肯定就会报错了。
- 针对这种情况,我们有什么解决方法呢?那就是把singleton声明成 volatile。
- volatile的作用是:保证可见性、禁止指令重排序,但不能保证原子性。
-
线程安全:静态内部类(剑指强烈推荐的方法)
public class Singleton { private static class SingletonHodler { private static final Singleton ourInstance = new Singleton(); } public static Singleton getInstance() { return SingletonHodler.ourInstance; } private Singleton() {} }分析:利用静态内部类的特性:只会加载一次。某个线程在调用该方法时会创建一个实例化对象。
下面的枚举和ThreadLocal我暂时看不懂,待到将来看到该部分时,再继续研究。
-
线程安全:枚举
enum SingletonTest { INSTANCE, INSTANCE("aa"), private String bb = "a"; public whateverMethod() { } public SingletonTest(String aa) { aa = bb; } }分析:枚举的方式是《Effective Java》书中提倡的方式,它不仅能避免多线程同步问题,而且还能防止反序列化重新创建新的对象,但是在枚举中的其他任何方法的线程安全由程序员自己负责。还有防止上面的通过反射机制调用私用构造器。不过,由于Java1.5中才加入enum特性,所以使用的人并不多。
-
线程安全:使用ThreadLocal
public class Singleton { private static final ThreadLocal<Singleton> tlSingleton = new ThreadLocal<Singleton>() { @Override protected Singleton initialValue() { return new Singleton(); } // () -> return new Singleton(); lamda表达式 }; public static Singleton getInstance() { return tlSingleton.get(); } private Singleton() {} }分析:ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
-
线程安全:CAS锁
public class Singleton { private static final AtomicReference<Singleton> INSTANCE = new AtomicReference<>(); /** * 用CAS确保线程安全 */ public static Singleton getInstance() { while (true) { Singleton current = INSTANCE.get(); if (current != null) { return current; } current = new Singleton(); if (INSTANCE.compareAndSet(null, current)) { return current; } } } private Singleton() {} }分析:对AtomicReference和AtomicBoolean详解 compareAndSet详解
INSTANCE.compareAndSet(null, current)是将null与INSTANCE中的引用比较,如果相同,返回true,并将current赋给INSTANCE,如果不同,则返回false并且不赋值。此方法使用设置的内存语义更新值,就像将该变量声明为volatile一样,不改变执行语序。
当线程1与线程2同时到达current = new Singleton()时,假设线程1先进入if,此时INSTANCE为null,与形参null相同,因此将current赋值给INSTANCE,并返回current。然后线程2进入if,此时INSTANCE与null相比较为false,跳出循环,重新进入,再次get()后赋值为Singleton对象,在第一个if判断中跳出。
-
参考链接:【设计模式】单例设计模式 深入浅出单实例Singleton设计模式
工厂模式
这里面简单工厂模式并没有算入23种的里面,工厂方法模式和抽象工厂模式是在23种里的。
简单工厂模式
主要是为了不用去管生成sender类的具体过程,告诉工厂参数,工厂直接生产给你一个对象。
就是建立一个工厂类,对实现了同一接口的一些类进行实例的创建。首先看下关系图:
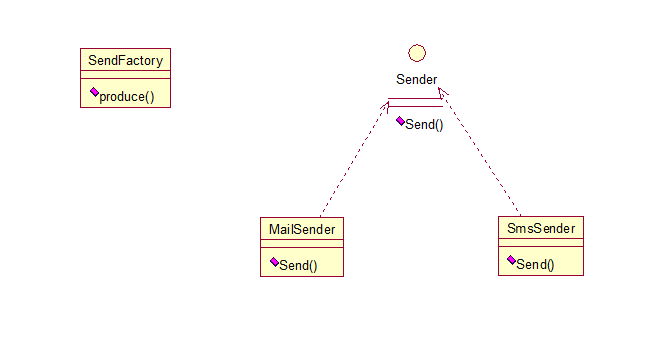
举例如下:(我们举一个发送邮件和短信的例子)
首先,创建二者的共同接口:
public interface Sender {
public void Send();
}
其次,创建实现类:
public class MailSender implements Sender {
@Override
public void Send() {
System.out.println("this is mailsender!");
}
}
public class SmsSender implements Sender {
@Override
public void Send() {
System.out.println("this is sms sender!");
}
}
最后,建工厂类:
public class SendFactory {
public Sender produce(String type) {
if ("mail".equals(type)) {
return new MailSender();
} else if ("sms".equals(type)) {
return new SmsSender();
} else {
System.out.println("请输入正确的类型!");
return null;
}
}
}
我们来测试下:
public class FactoryTest {
public static void main(String[] args) {
SendFactory factory = new SendFactory();
Sender sender = factory.produce("sms");
sender.Send();
}
}
另一个例子:
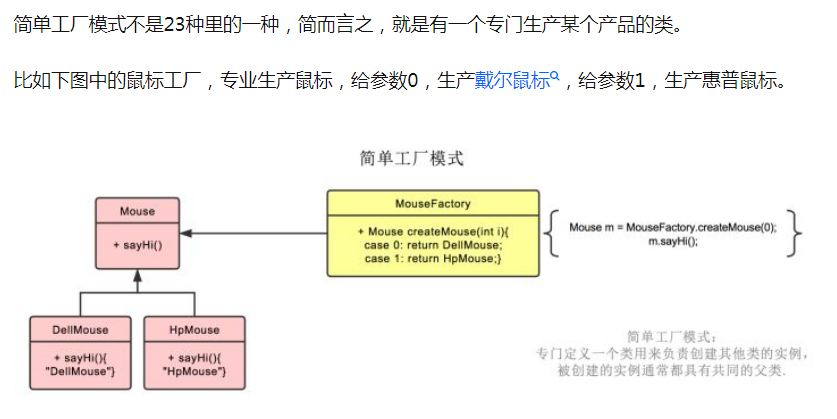
工厂类是整个简单工厂模式的关键。包含了必要的逻辑判断,根据外界给定的信息,决定究竟应该创建哪个具体类的对象。通过使用工厂类,外界可以从直接创建具体产品对象的尴尬局面摆脱出来,仅仅需要负责“消费”对象就可以了。而不必管这些对象究竟如何创建及如何组织的。明确了各自的职责和权利,有利于整个软件体系结构的优化。
但是由于工厂类集中了所有实例的创建逻辑,违反了高内聚责任分配原则,将全部创建逻辑集中到了一个工厂类中;它所能创建的类只能是事先考虑到的,如果需要添加新的类,则就需要改变工厂类了。
当系统中的具体产品类不断增多时候,可能会出现要求工厂类根据不同条件创建不同实例的需求.这种对条件的判断和对具体产品类型的判断交错在一起,很难避免模块功能的蔓延,对系统的维护和扩展非常不利;
为了解决这些缺点,就有了工厂方法模式。
工厂方法模式
工厂模式也就是鼠标工厂是个父类,有生产鼠标这个接口。
戴尔鼠标工厂,惠普鼠标工厂继承它,可以分别生产戴尔鼠标,惠普鼠标。
生产哪种鼠标不再由参数决定,而是创建鼠标工厂时,由戴尔鼠标工厂创建。
后续直接调用鼠标工厂.生产鼠标()即可
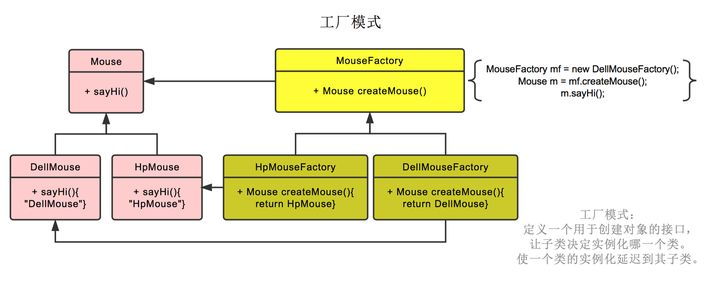
工厂方法模式和简单工厂模式虽然都是通过工厂来创建对象,他们之间最大的不同是——工厂方法模式在设计上完全完全符合“开闭原则”。
在以下情况下可以使用工厂方法模式:
- 一个类不知道它所需要的对象的类:在工厂方法模式中,客户端不需要知道具体产品类的类名,只需要知道所对应的工厂即可,具体的产品对象由具体工厂类创建;客户端需要知道创建具体产品的工厂类。
- 一个类通过其子类来指定创建哪个对象:在工厂方法模式中,对于抽象工厂类只需要提供一个创建产品的接口,而由其子类来确定具体要创建的对象,利用面向对象的多态性和里氏代换原则,在程序运行时,子类对象将覆盖父类对象,从而使得系统更容易扩展。
- 将创建对象的任务委托给多个工厂子类中的某一个,客户端在使用时可以无须关心是哪一个工厂子类创建产品子类,需要时再动态指定,可将具体工厂类的类名存储在配置文件或数据库中。
使用场景
- 日志记录器:记录可能记录到本地硬盘、系统事件、远程服务器等,用户可以选择记录日志到什么地方。
- 数据库访问,当用户不知道最后系统采用哪一类数据库,以及数据库可能有变化时。
- 设计一个连接服务器的框架,需要三个协议,"POP3"、"IMAP"、"HTTP",可以把这三个作为产品类,共同实现一个接口。
- 比如 Hibernate 换数据库只需换方言和驱动就可以
工厂方法模式总结
工厂方法模式是简单工厂模式的进一步抽象和推广。
由于使用了面向对象的多态性,工厂方法模式保持了简单工厂模式的优点,而且克服了它的缺点。
在工厂方法模式中,核心的工厂类不再负责所有产品的创建,而是将具体创建工作交给子类去做。这个核心类仅仅负责给出具体工厂必须实现的接口,而不负责产品类被实例化这种细节,这使得工厂方法模式可以允许系统在不修改工厂角色的情况下引进新产品。
优点:
- 一个调用者想创建一个对象,只要知道其名称就可以了。
- 扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
- 屏蔽产品的具体实现,调用者只关心产品的接口。
缺点:
每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。这并不是什么好事。
抽象工厂模式
抽象工厂模式也就是不仅生产鼠标,同时生产键盘。
也就是PC厂商是个父类,有生产鼠标,生产键盘两个接口。
戴尔工厂,惠普工厂继承它,可以分别生产戴尔鼠标+戴尔键盘,和惠普鼠标+惠普键盘。
创建工厂时,由戴尔工厂创建。
后续工厂.生产鼠标()则生产戴尔鼠标,工厂.生产键盘()则生产戴尔键盘。
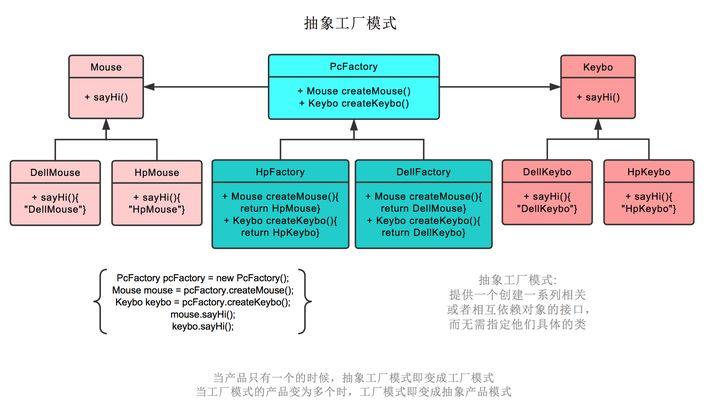
在抽象工厂模式中,假设我们需要增加一个工厂
假设我们增加华硕工厂,则我们需要增加华硕工厂,和戴尔工厂一样,继承PC厂商。
之后创建华硕鼠标,继承鼠标类。创建华硕键盘,继承键盘类。
即可。
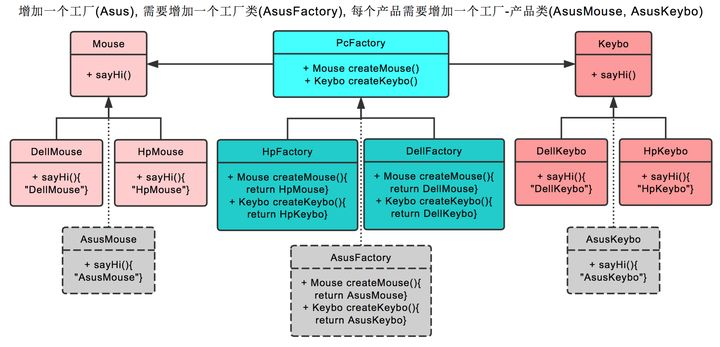
在抽象工厂模式中,假设我们需要增加一个产品
假设我们增加耳麦这个产品,则首先我们需要增加耳麦这个父类,再加上戴尔耳麦,惠普耳麦这两个子类。
之后在PC厂商这个父类中,增加生产耳麦的接口。最后在戴尔工厂,惠普工厂这两个类中,分别实现生产戴尔耳麦,惠普耳麦的功能。
以上。
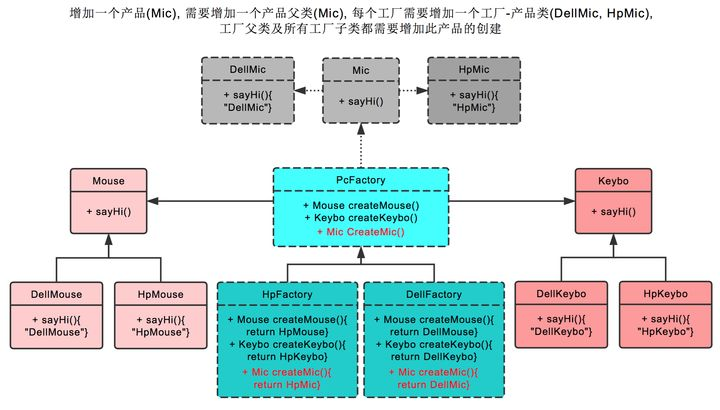
抽象工厂模式和工厂模式的区别
抽象工厂模式把产品进行了两个纬度的划分,其中一个纬度是从产品本身派生出来的,鼠标、键盘、麦克风这些产品类别的划分。另外一个纬度是从工厂派生出来的,有不同品牌的工厂。
而工厂模式只有一个纬度,产品和工厂是完全对应的。
工厂方法模式通过引入工厂等级结构,解决了简单工厂模式中工厂类职责太重的问题,但由于工厂方法模式中的每个工厂只生产一类产品,可能会导致系统中存在大量的工厂类,势必会增加系统的开销。此时,我们可以考虑将一些相关的产品组成一个“产品族”,由同一个工厂来统一生产,这就是抽象工厂模式的基本思想。
定义
为创建一组相关或相互依赖的对象提供一个接口,而且无需指定他们的具体类。
抽象工厂(Abstract Factory)模式,又称工具箱(Kit 或Toolkit)模式。
抽象工厂模式实现方式
抽象工厂模式是工厂方法模式的升级版本,他用来创建一组相关或者相互依赖的对象。他与工厂方法模式的区别就在于,工厂方法模式针对的是一个产品等级结构;而抽象工厂模式则是针对的多个产品等级结构。在编程中,通常一个产品结构,表现为一个接口或者抽象类,也就是说,工厂方法模式提供的所有产品都是衍生自同一个接口或抽象类,而抽象工厂模式所提供的产品则是衍生自不同的接口或抽象类。
在抽象工厂模式中,有一个产品族的概念:所谓的产品族,是指位于不同产品等级结构中功能相关联的产品组成的家族。抽象工厂模式所提供的一系列产品就组成一个产品族;而工厂方法提供的一系列产品称为一个等级结构。
也没骗你,抽象工厂模式确实是抽象。
抽象工厂模式适用场景
抽象工厂模式和工厂方法模式一样,都符合开闭原则。但是不同的是,工厂方法模式在增加一个具体产品的时候,都要增加对应的工厂。但是抽象工厂模式只有在新增一个类型的具体产品时才需要新增工厂。也就是说,工厂方法模式的一个工厂只能创建一个具体产品。而抽象工厂模式的一个工厂可以创建属于一类类型的多种具体产品。工厂创建产品的个数介于简单工厂模式和工厂方法模式之间。
在以下情况下可以使用抽象工厂模式:
- 一个系统不应当依赖于产品类实例如何被创建、组合和表达的细节,这对于所有类型的工厂模式都是重要的。
- 系统中有多于一个的产品族,而每次只使用其中某一产品族。
- 属于同一个产品族的产品将在一起使用,这一约束必须在系统的设计中体现出来。
- 系统结构稳定,不会频繁的增加对象。
“开闭原则”的倾斜性
产品等级结构:代表新增耳机,或者新增主机之类的与鼠标和键盘并列的,叫做产品等级结构。
产品族:代表新增一个工厂,新增了一个华硕工厂,无需改动,叫做产品族。
在抽象工厂模式中,增加新的产品族(新增工厂)很方便,但是增加新的产品等级结构(新增产品)很麻烦,抽象工厂模式的这种性质称为“开闭原则”的倾斜性。“开闭原则”要求系统对扩展开放,对修改封闭,通过扩展达到增强其功能的目的,对于涉及到多个产品族与多个产品等级结构的系统,其功能增强包括两方面:
- 增加产品族:对于增加新的产品族,工厂方法模式很好的支持了“开闭原则”,对于新增加的产品族,只需要对应增加一个新的具体工厂即可,对已有代码无须做任何修改。
- 增加新的产品等级结构:对于增加新的产品等级结构,需要修改所有的工厂角色,包括抽象工厂类,在所有的工厂类中都需要增加生产新产品的方法,违背了“开闭原则”。
正因为抽象工厂模式存在“开闭原则”的倾斜性,它以一种倾斜的方式来满足“开闭原则”,为增加新产品族提供方便,但不能为增加新产品结构提供这样的方便,因此要求设计人员在设计之初就能够全面考虑,不会在设计完成之后向系统中增加新的产品等级结构,也不会删除已有的产品等级结构,否则将会导致系统出现较大的修改,为后续维护工作带来诸多麻烦。
抽象工厂模式总结
抽象工厂模式是工厂方法模式的进一步延伸,由于它提供了功能更为强大的工厂类并且具备较好的可扩展性,在软件开发中得以广泛应用,尤其是在一些框架和API类库的设计中,例如在Java语言的AWT(抽象窗口工具包)中就使用了抽象工厂模式,它使用抽象工厂模式来实现在不同的操作系统中应用程序呈现与所在操作系统一致的外观界面。抽象工厂模式也是在软件开发中最常用的设计模式之一。
优点:
- 抽象工厂模式隔离了具体类的生成,使得客户并不需要知道什么被创建。由于这种隔离,更换一个具体工厂就变得相对容易,所有的具体工厂都实现了抽象工厂中定义的那些公共接口,因此只需改变具体工厂的实例,就可以在某种程度上改变整个软件系统的行为。
- 当一个产品族中的多个对象被设计成一起工作时,它能够保证客户端始终只使用同一个产品族中的对象。
- 增加新的产品族很方便,无须修改已有系统,符合“开闭原则”。
缺点:
增加新的产品等级结构麻烦,需要对原有系统进行较大的修改,甚至需要修改抽象层代码,这显然会带来较大的不便,违背了“开闭原则”。
工厂模式的退化
当抽象工厂模式中每一个具体工厂类只创建一个产品对象,也就是只存在一个产品等级结构时,抽象工厂模式退化成工厂方法模式;当工厂方法模式中抽象工厂与具体工厂合并,提供一个统一的工厂来创建产品对象,并将创建对象的工厂方法设计为静态方法时,工厂方法模式退化成简单工厂模式。
我们身边的工厂模式
- Spring是最大的Bean工厂,IOC通过
FactoryBean对Bean 进行管理。 - 我们使用的日志门面框架
slf4j,点进去就可以看到熟悉的味道
private final static Logger logger = LoggerFactory.getLogger(HelloWord.class);
- JDK 的
Calendar使用了简单工厂模式
Calendar calendar = Calendar.getInstance();
参考文章:抽象工厂模式和工厂模式的区别? 知乎回答
原型模式
原型模式:使用原型实例指定待创建对象的类型,并且通过复制这个原型来创建新的对象!
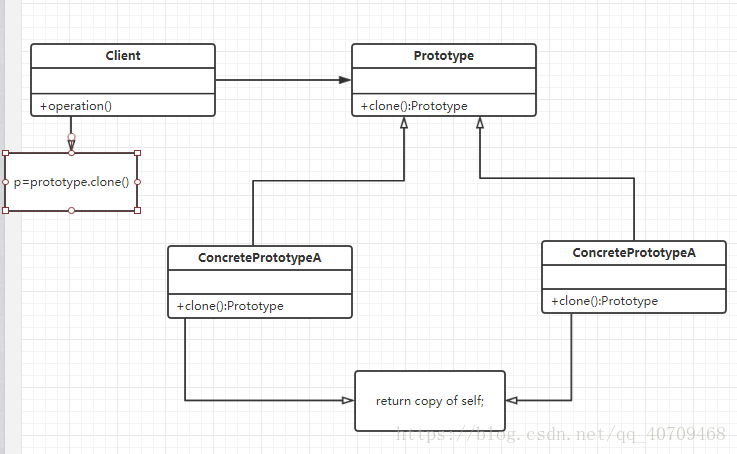
原型模式分三个角色,抽象原型类,具体原型类,客户类。
抽象原型类(prototype):它是声明克隆方法的接口,是所有具体原型类的公共父类,它可以是接口,抽象类甚至是一个具体的实现类。
具体原型类(concretePrototype):它实现了抽象原型类中声明的克隆方法,在克隆方法中返回一个自己的克隆对象。
客户类(Client):在客户类中,使用原型对象只需要通过工厂方式创建或者直接NEW(实例化一个)原型对象,然后通过原型对象的克隆方法就能获得多个相同的对象。由于客户端是针对抽象原型对象编程的所以还可以可以很方便的换成不同类型的原型对象!
在原型模式中有两个概念我们需要了解一下,就是浅克隆和深克隆的概念。按照我的理解,浅克隆只是复制了基础属性,列如八大基本类型以及String类型,然而引用类型实际上没有复制,只是将对应的引用给复制了地址。
附件类:
package prototypePattern;
/**
*
* <p>Title: Attachment</p>
* <p>Description:附件类 </p>
* @author HAND_WEILI
* @date 2018年9月2日
*/
public class Attachment {
private String name; //附件名
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void download() {
System.out.println("下载附件"+name);
}
}
周报类:关键点在于,实现cloneable接口以及用object的clone方法。
package prototypePattern;
/**
*
* <p>Title: WeeklyLog</p>
* <p>Description:周报类充当具体的原型类 </p>
* @author HAND_WEILI
* @date 2018年9月2日
*/
public class WeeklyLog implements Cloneable{
private Attachment attachment;
private String date;
private String name;
private String content;
public Attachment getAttachment() {
return attachment;
}
public void setAttachment(Attachment attachment) {
this.attachment = attachment;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
//实现clone()方法实现浅克隆
public WeeklyLog clone() {
//需要实现cloneable的接口,直接继承object就好,它里面自带一个clone方法!
Object obj = null;
try {
obj = super.clone();
return (WeeklyLog)obj;
} catch (CloneNotSupportedException e) {
// TODO Auto-generated catch block
System.out.println("不支持克隆方法!");
return null;
}
}
}
客户端:
package prototypePattern;
public class Client {
//测试类,客户端
public static void main(String[] args) {
WeeklyLog log_1,log_2;
log_1 = new WeeklyLog(); //创建原型对象
Attachment attachment = new Attachment(); //创建附件对象
log_1.setAttachment(attachment); //将附件添加到周报种去
log_2=log_1.clone(); //克隆周报
System.out.println("周报是否相同"+(log_1==log_2));
System.out.println("附件是否相同"+(log_1.getAttachment()==log_2.getAttachment()));
}
}
浅克隆的结果肯定是周报不同但是附件相同。
深克隆
在JAVA怎么做到深度克隆了?第一种方式是通过再次递归克隆子引用一直到null为止,这种很麻烦不推荐,第二种就是序列化以及反序列化。
通过序列化(Serialization)等方式来进行深度克隆。这个时候要聊一聊什么是序列化了。简单的讲就是序列化就将对象写到流的一个过程,写到流里面去(就是字节流)就等于复制了对象,但是原来的对象并没有动,只是复制将类型通过流的方式进行读取,然后写到另个内存地址中去!
序列化的实现:
首先将附件类修改。将其序列化
package prototypePattern;
import java.io.Serializable;
/**
* <p>Description:附件类 </p>
*/
public class Attachment_2 implements Serializable {//这里实现了序列化接口Serializable
private String name; //附件名
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void download() {
System.out.println("下载附件"+name);
}
}
周报类
package prototypePattern;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
import java.io.Serializable;
/**
*
* <p>Title: WeeklyLog</p>
* <p>Description:周报类充当具体的原型类 </p>
* @author HAND_WEILI
* @date 2018年9月2日
*/
public class WeeklyLog_2 implements Serializable{
private Attachment_2 attachment;
private String date;
private String name;
private String content;
public Attachment_2 getAttachment() {
return attachment;
}
public void setAttachment(Attachment_2 attachment) {
this.attachment = attachment;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
//通过序列化进行深克隆
public WeeklyLog_2 deepclone() throws Exception {
//将对象写入流中,
ByteArrayOutputStream bao = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bao);
oos.writeObject(this);
//将对象取出来
ByteArrayInputStream bi = new ByteArrayInputStream(bao.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bi);
return (WeeklyLog_2)ois.readObject();
}
}
客户类
package prototypePattern;
public class Client_2 {
//测试类,客户端
public static void main(String[] args) {
WeeklyLog_2 log_1,log_2=null;
log_1 = new WeeklyLog_2(); //创建原型对象
Attachment_2 attachment = new Attachment_2(); //创建附件对象
log_1.setAttachment(attachment); //将附件添加到周报种去
try {
log_2=log_1.deepclone();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
} //克隆周报
System.out.println("周报对象是否相同"+(log_1==log_2));
System.out.println("附件对象是否相同"+(log_1.getAttachment()==log_2.getAttachment()));
}
}
原型模式的优缺点
原型模式作为一种快速创建大量相同或相似的对象方式,在软件开发种的应用较为广泛,很多软件提供的CTRL+C和CTRL+V操作的就是原型模式的典型应用!
优点
当创建的对象实例较为复杂的时候,使用原型模式可以简化对象的创建过程!
扩展性好,由于写原型模式的时候使用了抽象原型类,在客户端进行编程的时候可以将具体的原型类通过配置进行读取。
可以使用深度克隆来保存对象的状态,使用原型模式进行复制。当你需要恢复到某一时刻就直接跳到。比如我们的idea种就有历史版本,或则SVN中也有这样的操作。非常好用!
缺点
需要为每一个类配备一个克隆方法,而且该克隆方法位于一个类的里面,当对已有的类经行改造时需要修改源代码,违背了开闭原则。
在实现深克隆的时需要编写较为复杂的代码,而且当对象之间存在多重嵌套引用的时候,为了实现深克隆,每一层对象对应的类都必须支持深克隆,实现相对麻烦。
原型模式适用场景
在以下情况可以考虑使用。
1创建对象成本比较大,比如初始化要很长时间的,占用太多CPU的,新对象可以通过复制已有的对象获得的,如果是相似的对象,则可以对其成员变量稍作修改。
2系统要保存对象状态的,而对象的状态改变很小。
3需要避免使用分层次的工厂类来创建分层次的对象,并且类的对象就只用一个或很少的组合状态!
参考文章:JAVA原型模式
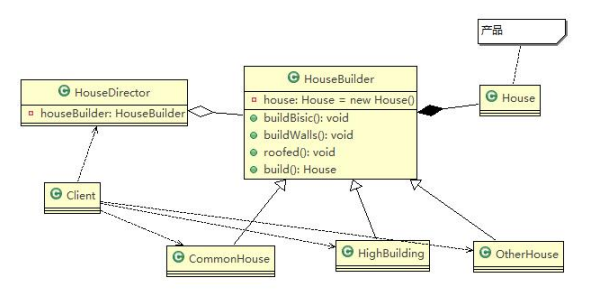
建造者模式
建造者模式又被称呼为生成器模式,这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
使用多个简单的对象一步一步构建成一个复杂的对象,有点像造房子一样一步步从地基做起到万丈高楼。我想这也是为什么被称呼为建造者模式的原因吧!
简介
1、定义:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示
2、主要作用:在用户不知道对象的建造过程和细节的情况下就可以直接创建复杂的对象。
3、如何使用:用户只需要给出指定复杂对象的类型和内容,建造者模式负责按顺序创建复杂对象(把内部的建造过程和细节隐藏起来)
4、解决的问题:
(1)、方便用户创建复杂的对象(不需要知道实现过程)
(2)、代码复用性 & 封装性(将对象构建过程和细节进行封装 & 复用)
5、注意事项:与工厂模式的区别是:建造者模式更加关注与零件装配的顺序,一般用来创建更为复杂的对象
一般有以下几个角色
抽象建造者(builder):描述具体建造者的公共接口,一般用来定义建造细节的方法,并不涉及具体的对象部件的创建。
具体建造者(ConcreteBuilder):描述具体建造者,并实现抽象建造者公共接口。
指挥者(Director):调用具体建造者来创建复杂对象(产品)的各个部分,并按照一定顺序(流程)来建造复杂对象。
产品(Product):描述一个由一系列部件组成较为复杂的对象。
例子
既然是建造者模式,那么我们还是继续造房吧,其实我也想不到更简单的例子。假设造房简化为如下步骤:(1)地基(2)钢筋工程(3)铺电线(4)粉刷。“如果”要盖一座房子,首先要找一个建筑公司或工程承包商(指挥者)。承包商指挥工人(具体建造者)过来造房子(产品),最后验收。
具体步骤
1、创建抽象建造者定义造房步骤
2、创建工人具体实现造房步骤
3、创建承包商指挥工人施工
4、验收,检查是否建造完成
建造者:Builder.java
/**
* Builder.java
* 建造者
*/
abstract class Builder {
//地基
abstract void bulidA();
//钢筋工程
abstract void bulidB();
//铺电线
abstract void bulidC();
//粉刷
abstract void bulidD();
//完工-获取产品
abstract Product getProduct();
}
产品:Product.java
/**
* Product.java
* 产品(房子)
*/
public class Product {
private String buildA;
private String buildB;
private String buildC;
private String buildD;
public String getBuildA() {
return buildA;
}
public void setBuildA(String buildA) {
this.buildA = buildA;
}
public String getBuildB() {
return buildB;
}
public void setBuildB(String buildB) {
this.buildB = buildB;
}
public String getBuildC() {
return buildC;
}
public void setBuildC(String buildC) {
this.buildC = buildC;
}
public String getBuildD() {
return buildD;
}
public void setBuildD(String buildD) {
this.buildD = buildD;
}
@Override
public String toString() {
return buildA+"\n"+buildB+"\n"+buildC+"\n"+buildD+"\n"+"房子验收完成";
}
}
具体建造者:ConcreteBuilder1.java 这里可以有普通房子、高楼房子、低级房子等等种类,客户端主要就是通过传递这种不同的具体建造者多态到抽象建造者完成目的
/**
* ConcreteBuilder1.java
* 具体建造者(普通房子)
*/
public class ConcreteBuilder extends Builder{
private Product product;
public ConcreteBuilder() {
product = new Product();
}
@Override
void bulidA() {
product.setBuildA("普通房子地基");
}
@Override
void bulidB() {
product.setBuildB("普通房子钢筋工程");
}
@Override
void bulidC() {
product.setBuildC("普通房子铺电线");
}
@Override
void bulidD() {
product.setBuildD("普通房子粉刷");
}
@Override
Product getProduct() {
return product;
}
}
ConcreteBuilder2.java
/**
* ConcreteBuilder.java
* 具体建造者(高级房子)
*/
public class ConcreteBuilder extends Builder{
private Product product;
public ConcreteBuilder() {
product = new Product();
}
@Override
void bulidA() {
product.setBuildA("高级房子地基");
}
@Override
void bulidB() {
product.setBuildB("高级房子钢筋工程");
}
@Override
void bulidC() {
product.setBuildC("高级房子铺电线");
}
@Override
void bulidD() {
product.setBuildD("高级房子粉刷");
}
@Override
Product getProduct() {
return product;
}
}
指挥者:Director.java
/**
* Director.java
* 指挥者
*/
public class Director {
//指挥按顺序造房
public Product create(Builder builder) {
builder.bulidA();
builder.bulidB();
builder.bulidC();
builder.bulidD();
return builder.getProduct();
}
}
客户端:Test.java
/**
* Test.java
* 测试类
*/
public class Test {
public static void main(String[] args) {
Director director = new Director();
Product create = director.create(new ConcreteBuilder1());//建了一个普通房子
System.out.println(create.toString());
}
}
总结
优点
1、产品的建造和表示分离,实现了解耦。
2、将复杂产品的创建步骤分解在不同的方法中,使得创建过程更加清晰
3、增加新的具体建造者无需修改原有类库的代码,易于拓展,符合“开闭原则“。
缺点
1、产品必须有共同点,限制了使用范围。
2、如内部变化复杂,会有很多的建造类,难以维护。
应用场景
1、需要生成的产品对象有复杂的内部结构,这些产品对象具备共性;
2、隔离复杂对象的创建和使用,并使得相同的创建过程可以创建不同的产品。
3、需要生成的对象内部属性本身相互依赖。
4、适合于一个具有较多的零件(属性)的产品(对象)的创建过程。

参考资料:Java 设计模式——建造者模式(Builder Pattern)
适配器模式
适配器模式是一种结构型设计模式。适配器模式的思想是:把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。

用电器来打个比喻:有一个电器的插头是三脚的,而现有的插座是两孔的,要使插头插上插座,我们需要一个插头转换器,这个转换器即是适配器。
适配器模式涉及3个角色:
源(Source):需要被适配的对象或类型,相当于插头。
适配器(Adapter):连接目标和源的中间对象,相当于插头转换器。
目标(Target):期待得到的目标,相当于插座。
适配器模式包括3种形式:类适配器模式、对象适配器模式、接口适配器模式(或又称作缺省适配器模式)。
类适配器模式
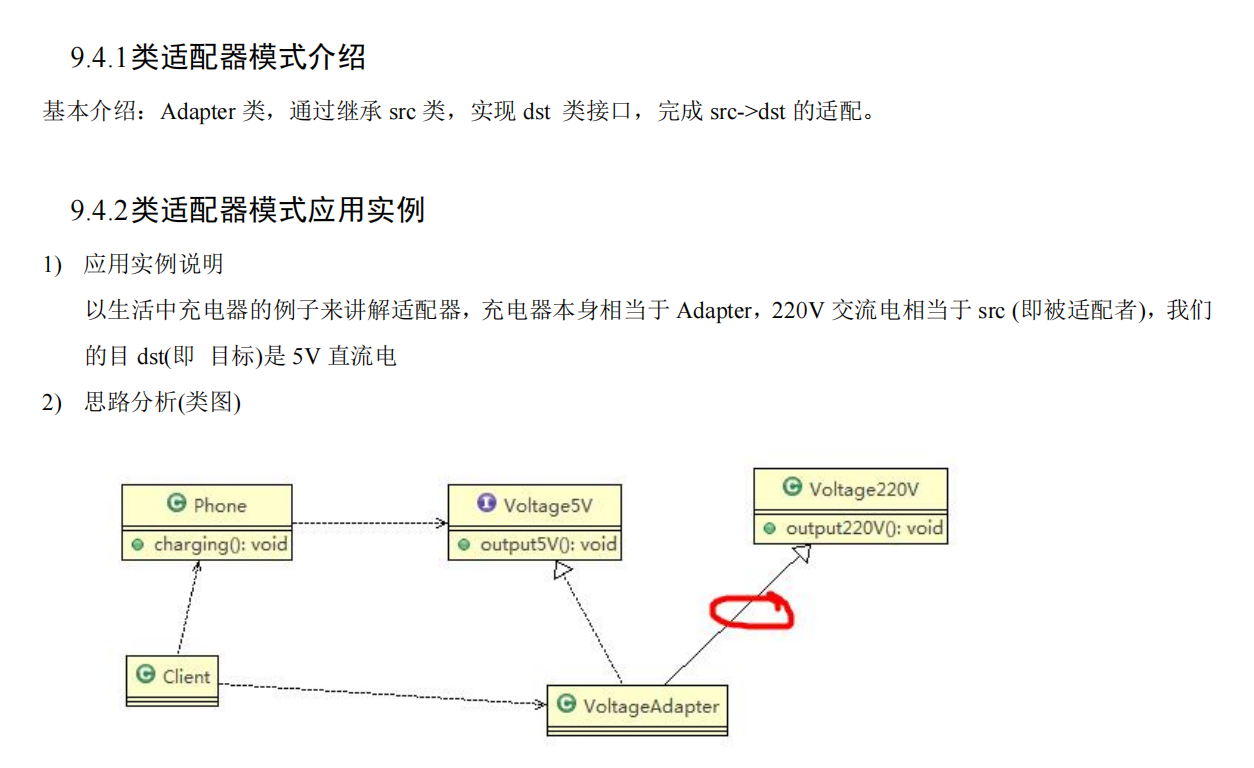
客户端
public class Client {
public static void main(String[] args) {
// TODO Auto-generated method stub
System.out.println(" === 类适配器模式 ====");
Phone phone = new Phone();
phone.charging(new VoltageAdapter());
}
}
适配接口
public interface IVoltage5V {
public int output5V();
}
实体类
public class Phone {
//充电
public void charging(IVoltage5V iVoltage5V) {
if (iVoltage5V.output5V() == 5) {
System.out.println("电压为 5V, 可以充电~~");
} else if (iVoltage5V.output5V() > 5) {
System.out.println("电压大于 5V, 不能充电~~");
}
}
}
被适配的类
//被适配的类
public class Voltage220V {
//输出 220V 的电压
public int output220V() {
int src = 220;
System.out.println("电压=" + src + "伏");
return src;
}
}
适配器类
public class VoltageAdapter extends Voltage220V implements IVoltage5V {
@Override
public int output5V() {
// TODO Auto-generated method stub
// 获取到 220V 电压
int srcV = output220V();
int dstV = srcV / 44; //转成 5v return dstV;
}
}
9.4.3类适配器模式注意事项和细节
- Java 是单继承机制,所以类适配器需要继承 src 类这一点算是一个缺点, 因为这要求 dst 必须是接口,有一定局 限性;
- src 类的方法在 Adapter 中都会暴露出来,也增加了使用的成本。
- 由于其继承了 src 类,所以它可以根据需求重写 src 类的方法,使得 Adapter 的灵活性增强了。
其实就是继承这一点不好,所以改成聚合实例
对象适配器模式

与类适配器只有适配器类有所变化
public class VoltageAdapter implements IVoltage5V {
private Voltage220V voltage220V; // 关联关系-聚合
//通过构造器,传入一个 Voltage220V 实例
public VoltageAdapter(Voltage220V voltage220v) {
this.voltage220V = voltage220v;
}
@Override
public int output5V() {
int dst = 0;
if (null != voltage220V) {
int src = voltage220V.output220V();
System.out.println("使用对象适配器,进行适配~~");
dst = src / 44;
System.out.println("适配完成,输出的电压为=" + dst);
}
return dst;
}
}
对象适配器模式注意事项和细节
-
对象适配器和类适配器其实算是同一种思想,只不过实现方式不同。 根据合成复用原则,使用组合替代继承, 所以它解决了类适配器必须继承 src的局限性问题,也不再要求dst必须是接口。
-
使用成本更低,更灵活。
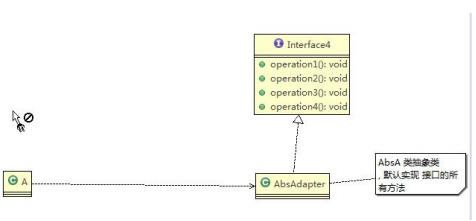
接口适配器模式
-
一些书籍称为:适配器模式(Default Adapter Pattern)或缺省适配器模式。
-
核心思路:当不需要全部实现接口提供的方法时,可先设计一个抽象类实现接口,并为该接口中每个方法提供一个默认实现(空方法),那么该抽象类的子类可有选择地覆盖父类的某些方法来实现需求
-
适用于一个接口不想使用其所有的方法的情况。
适配器模式在 SpringMVC 框架应用的源码剖析
-
SpringMvc 中的 HandlerAdapter, 就使用了适配器模式
-
SpringMVC 处理请求的流程回顾
-
使用 HandlerAdapter 的原因分析:
可以看到处理器的类型不同,有多重实现方式,那么调用方式就不是确定的,如果需要直接调用 Controller 方法,需要调用的时候就得不断是使用 if else 来进行判断是哪一种子类然后执行。那么如果后面要扩展 Controller,就得修改原来的代码,这样违背了 OCP 原则。
-
代码分析+Debug 源码

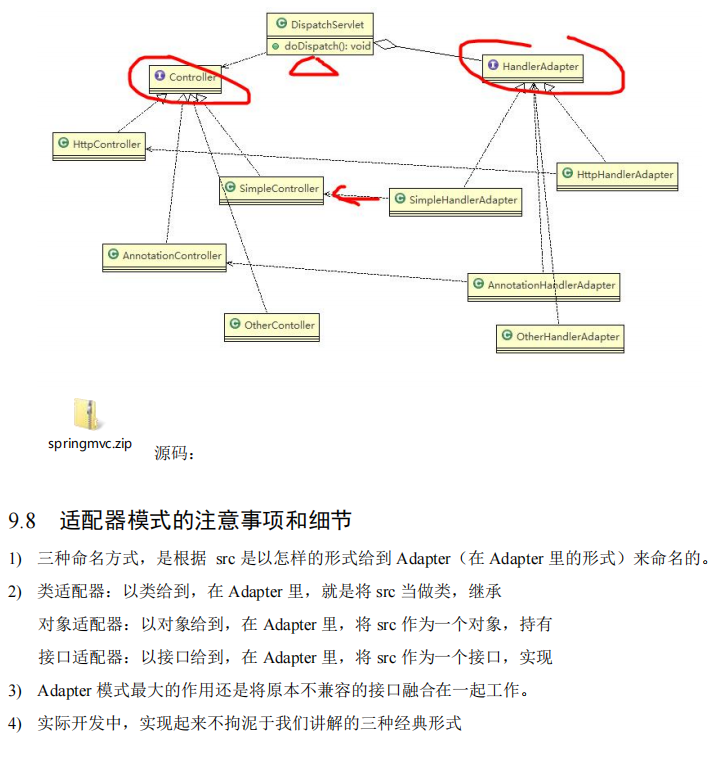
不直接对handler进行处理,而是将handler交给适配器HandlerAdapter去处理,这样DispatcherServlet交互的类就只剩下一个接口,HandlerAdapter,符合迪米特法则,尽可能少的与其他类发生交互;
将handler交给HandlerAdapter处理后,不同类型的handler被对应类型的HandlerAdapter处理,每个HandlerAdapter都只完成单一的handler处理,符合单一职责原则;
如果需要新增一个类型的handler,只需要新增对应类型的HandlerAdapter就可以处理,无需修改原有代码,符合开闭原则。
这样,不同的handler的不同处理方式,就在HandlerAdapter中得到了适配,对于DispatcherServlet来将,只需要统一的调用HandlerAdapter的handle()方法就可以了,无需关注不同handler的处理细节。
桥接模式
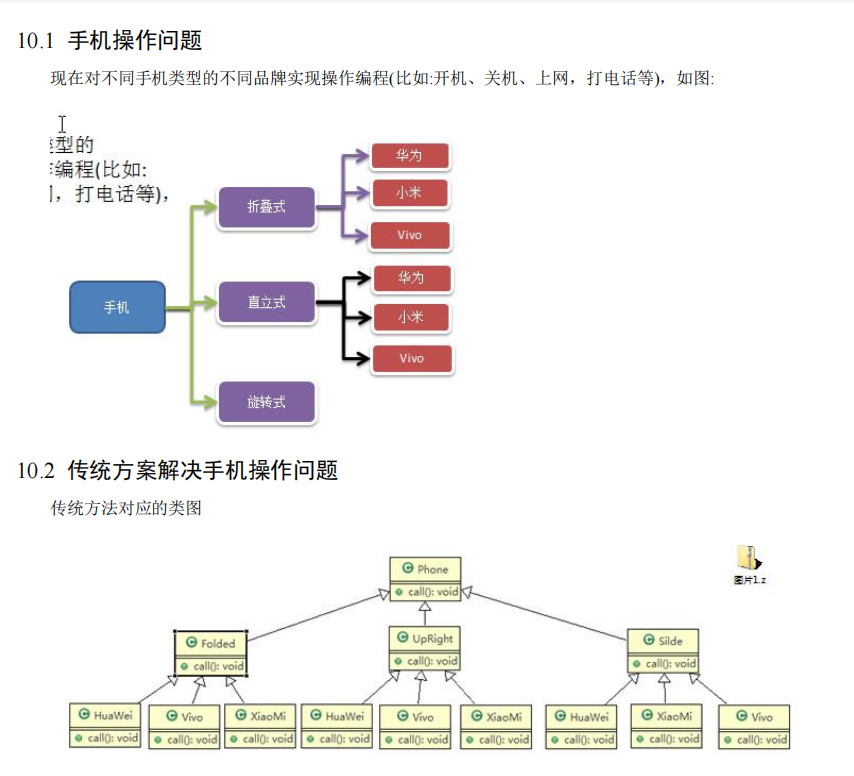
传统方案解决手机操作问题分析
-
扩展性问题(类爆炸),如果我们再增加手机的样式(旋转式),就需要增加各个品牌手机的类,同样如果我们增加一个手机品牌,也要在各个手机样式类下增加。
-
违反了单一职责原则,当我们增加手机样式时,要同时增加所有品牌的手机,这样增加了代码维护成本.
-
解决方案-使用桥接模式
桥接模式(Bridge)-基本介绍
-
桥接模式(Bridge 模式)是指:将实现与抽象放在两个不同的类层次中,使两个层次可以独立改变。
-
是一种结构型设计模式
-
Bridge 模式基于类的最小设计原则,通过使用封装、聚合及继承等行为让不同的类承担不同的职责。它的主要 特点是把抽象(Abstraction)与行为实现(Implementation)分离开来,从而可以保持各部分的独立性以及应对他们的功能扩展
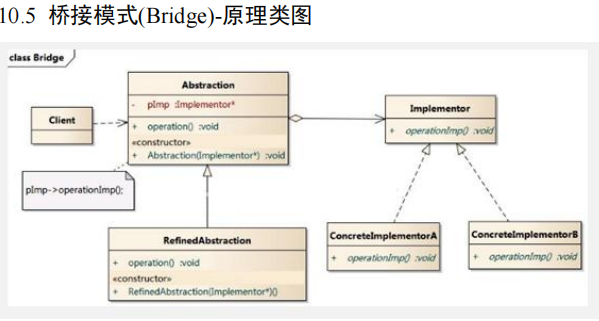
- Client 类:桥接模式的调用者
- 抽象类(Abstraction) :维护了 Implementor / 即它的实现类 ConcreteImplementorA.., 二者是聚合关系, Abstraction充当桥接类
- RefinedAbstraction : 是 Abstraction 抽象类的子类
- Implementor : 行为实现类的接口
- ConcreteImplementorA /B :行为的具体实现类
- 从 UML 图:这里的抽象类和接口是聚合的关系,其实调用和被调用关系
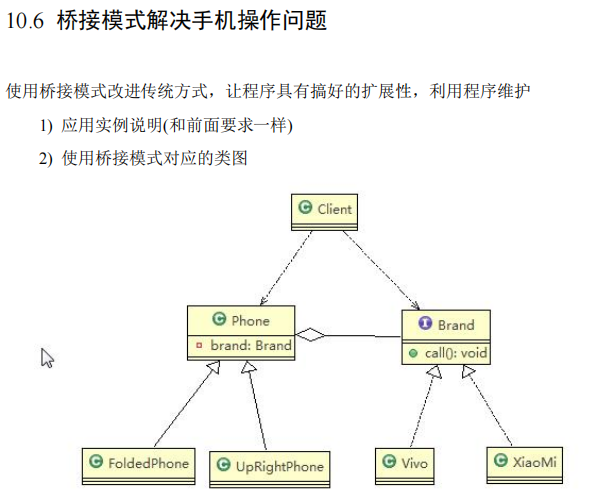
接口类
public interface Brand {
void open();
void close();
void call();
}
客户端
public class Client {
public static void main(String[] args) { //获取折叠式手机 (样式 + 品牌 )
Phone phone1 = new FoldedPhone(new XiaoMi());
phone1.open();
phone1.call();
phone1.close();
System.out.println("=======================");
Phone phone2 = new FoldedPhone(new Vivo());
phone2.open();
phone2.call();
phone2.close();
System.out.println("==============");
UpRightPhone phone3 = new UpRightPhone(new XiaoMi());
phone3.open();
phone3.call();
phone3.close();
System.out.println("==============");
UpRightPhone phone4 = new UpRightPhone(new Vivo());
phone4.open();
phone4.call();
phone4.close();
}
}
折叠式手机类,继承 抽象类 Phone 应该是有3种 差不多
public class FoldedPhone extends Phone {
//构造器 这里很关键 通过泛化用brand替代了具体的品牌类
public FoldedPhone(Brand brand) {
super(brand);
}
public void open() {
super.open();
System.out.println(" 折叠样式手机 ");
}
public void close() {
super.close();
System.out.println(" 折叠样式手机 ");
}
public void call() {
super.call();
System.out.println(" 折叠样式手机 ");
}
}
抽象类 Phone
public abstract class Phone {
//组合品牌
private Brand brand;
//构造器
public Phone(Brand brand) {
super();
this.brand = brand;
}
protected void open() {
this.brand.open();
}
protected void close() {
brand.close();
}
protected void call() {
brand.call();
}
}
Vivo类 实现接口Brand 应该有3个来着
public class Vivo implements Brand {
@Override
public void open() {
System.out.println(" Vivo 手机开机 ");
}
@Override
public void close() {
System.out.println(" Vivo 手机关机 ");
}
@Override
public void call() {
System.out.println(" Vivo 手机打电话 ");
}
}
其中JDBC用到了桥接模式
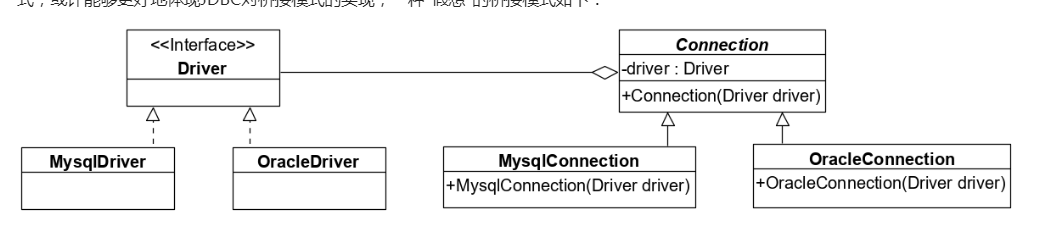
详解:JDBC和桥接模式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号