(继续)完善PS端YOLO网络前向计算函数
继续完善PS端YOLO网络前向计算函数
目标
- 在PS端实现YOLO网络的前向计算
- 对不同的卷积层进行配置和优化
- 比较PS端和Python端的计算结果
前提
- PS端使用卷积计算模块,可以同时处理8个通道的数据
- PS端使用量化模块,可以对数据进行量化和反量化,以减少内存占用和提高运算速度
- PS端使用激活模块,可以对数据进行ReLU或LeakyReLU激活
- PS端使用路由模块,可以对不同层的数据进行拼接或分割
- PS端使用检测模块,可以对最后一层的数据进行解析,得到目标的位置和类别
步骤
layer 12
- layer 12是一个3x3卷积层,输入通道为512,输出通道为1024,没有池化层
- 配置信息如下:
- 卷积类型:0(3x3)
- 输入通道:512
- 输出通道:1024
- 池化类型:0(无)
- 图像尺寸:13x13
- 量化信息:
- mult:17866
- shift:11
- zero_point_in:12
- zero_point_out:48
- 发送地址:0x3000000(layer 11的接收地址)
- 接收地址:0x3100000(新分配的地址)
- 子函数如下:
- 发送配置信息、偏置、权重、命令和数据地址给卷积计算模块
- 接收卷积计算模块返回的数据,并进行量化、激活和发送操作
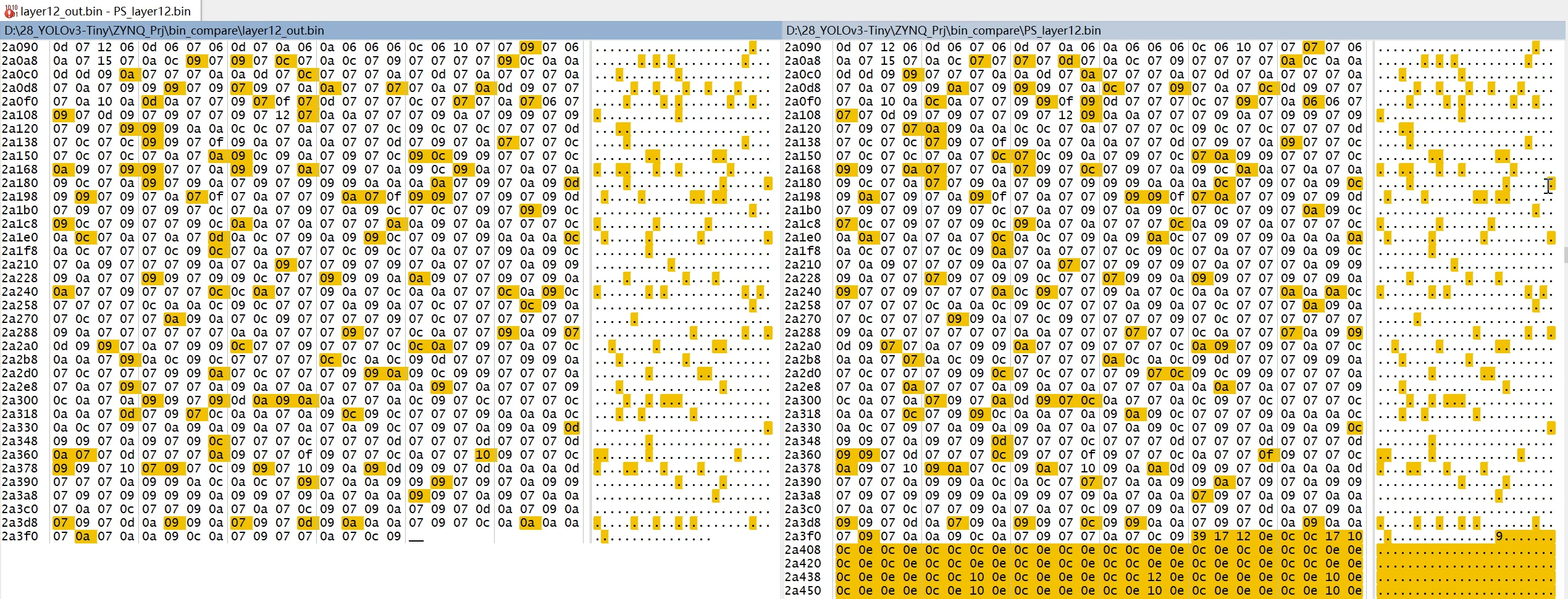
layer 13
- layer 13是一个1x1卷积层,输入通道为1024,输出通道为256,没有池化层
- 配置信息如下:
- 卷积类型:1(1x1)
- 输入通道:1024
- 输出通道:256
- 池化类型:0(无)
- 图像尺寸:13x13
- 量化信息:
- mult:23354
- shift:8
- zero_point_in:7
- zero_point_out:41
- 发送地址:0x3100000(layer 12的接收地址)
- 接收地址:0x3200000(新分配的地址)
- 子函数如下:
- 发送配置信息、偏置、权重、命令和数据地址给卷积计算模块
- 接收卷积计算模块返回的数据,并进行量化、激活和发送操作
![image]()
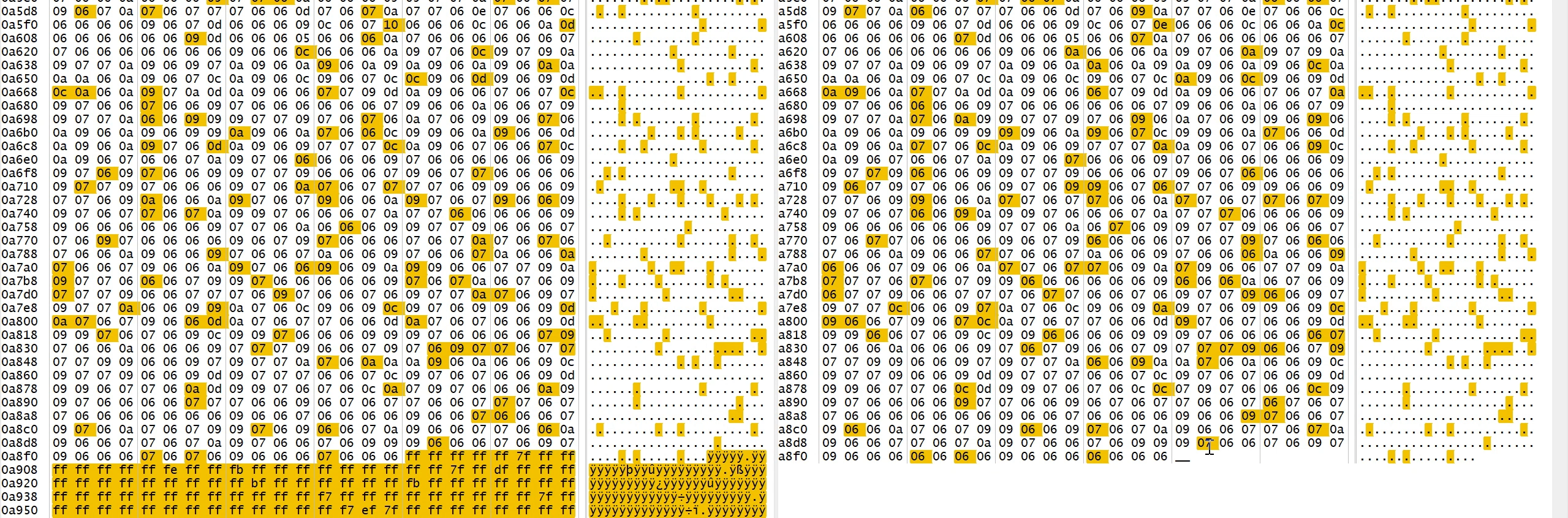
layer 14
- layer 14是一个3x3卷积层,输入通道为256,输出通道为512,没有池化层
- 配置信息如下:
- 卷积类型:0(3x3)
- 输入通道:256
- 输出通道:512
- 池化类型:0(无)
- 图像尺寸:13x13
- 量化信息:
- mult:28523
- shift:8
- zero_point_in:6
- zero_point_out:63
- 发送地址:0x3200000(layer 13的接收地址)
- 接收地址:0x3000000(layer 12的发送地址,覆盖原来的数据)
- 子函数如下:
- 发送配置信息、偏置、权重、命令和数据地址给卷积计算模块
- 接收卷积计算模块返回的数据,并进行量化、激活和发送操作
![image]()
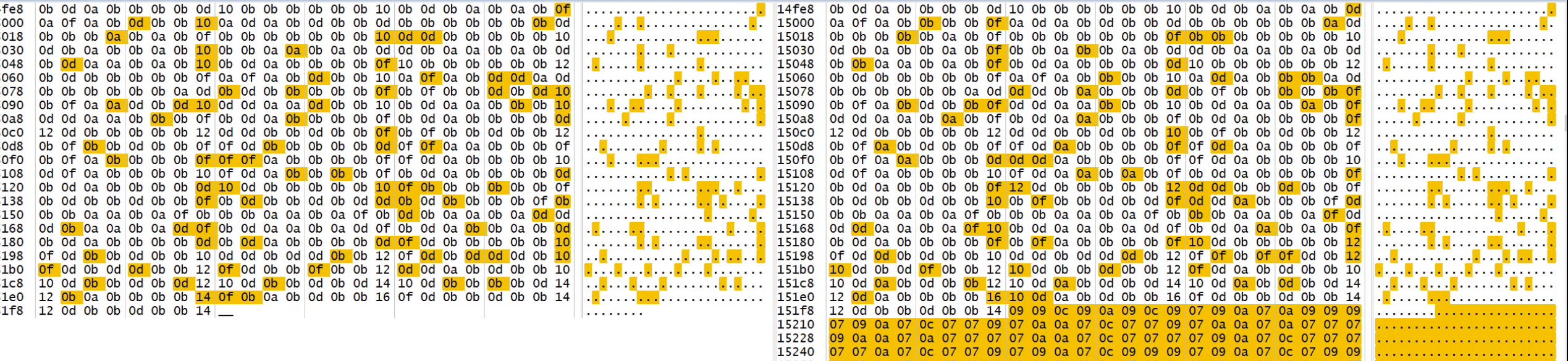
layer 15
-
layer 15是一个1x1卷积层,输入通道为512,输出通道为18(根据类别数计算得到),没有池化层
我们只检测人脸,所以目标类别只有一个,每个网格单元预测三个边界框,所以输出通道数是 3×(1+5)=183×(1+5)=18,其中 11 是类别数,55 是边界框的参数(中心坐标、宽高和置信度)。但是由于 PS 端内部是同时运行八个通道的卷积计算,所以我们需要将输出通道数填充为八的整数倍,即 24 -
配置信息如下:
- 卷积类型:1(1x1)
- 输入通道:512
- 输出通道:24(填充为8的整数倍)
- 池化类型:0(无)
- 图像尺寸:13x13
- 量化信息:
- mult:27118
- shift:6
- zero_point_in:11
- zero_point_out:51
- 发送地址:0x3000000(layer 14的接收地址)
- 接收地址:0x3300000(新分配的地址)
-
子函数如下:
- 发送配置信息、偏置、权重、命令和数据地址给卷积计算模块
- 接收卷积计算模块返回的数据,并进行量化、激活和发送操作
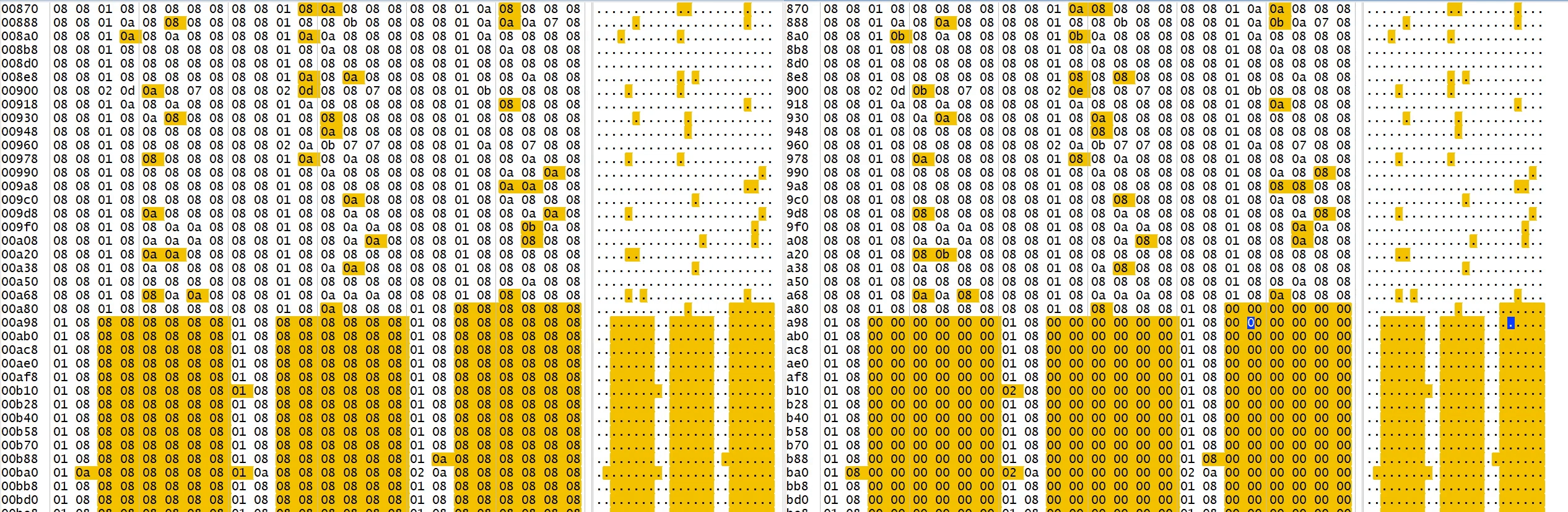
代码清单:
yolo_accel_ctrl.c
char InterruptProcessed = FALSE;
int layers_config[9][9] = {
// conv_type, ch_in, ch_out, is_pool, feature_size, mult, shift, zp_in, zp_out
// conv_type: 0->3x3, 1->1x1
{0, 8, 16, 1, 416, 19290, 9, 0, 65},
{0, 16, 32, 1, 208, 30363, 8, 12, 86},
{0, 32, 64, 1, 104, 31915, 8, 22, 80},
{0, 64, 128, 1, 52, 16639, 7, 19, 57},
{0, 128, 256, 1, 26, 20025, 8, 9, 70},
{0, 256, 512, 1, 13, 23363, 9, 14, 66},
{0, 512, 1024, 0, 13, 17866, 11, 12, 48},
{1, 1024, 256, 0, 13, 23354, 8, 7, 41},
{0, 256, 512, 0, 13, 28523, 8, 6, 63}
};
u32 layers_tx_addr[9] = {
0x1000000, 0x3000000, 0x3100000, 0x3000000, 0x3100000, 0x3000000, 0x3100000, 0x3000000, 0x3200000
};
u32 layers_rx_addr[9] = {
0x3000000, 0x3100000, 0x3000000, 0x3100000, 0x3000000, 0x3100000, 0x3000000, 0x3200000, 0x3000000
};
void update_tx_info()
{
if(feature_size <= 52)
tx_len = (feature_size*feature_size) << 3;
else if(tx_cnt == 0) {
tx_len = (pl_buffer_row_num * feature_size)<<3;
}
else if(tx_cnt == tx_cnt_end - 1)
tx_len = (tx_last_row_num * feature_size)<<3;
tx_addr = tx_base_addr + ((tx_row_num * feature_size)<<3)*tx_cnt + ((feature_size*feature_size)<<3)*ch_in_batch_cnt;
}
void update_rx_info()
{
rx_addr = rx_addr + rx_len;
if(tx_cnt == 0 && ch_out_batch_cnt == 0)
rx_addr = rx_base_addr;
if(feature_size <= 52) {
if(is_pool == 0) {
rx_len = (feature_size*feature_size) << 3;
rx_left_row_num = 0;
}
else if(pool_stride == 0) {
rx_len = ((feature_size>>1)* (feature_size>>1)) << 3;
rx_left_row_num = 0;
}
else {
rx_len = (feature_size*feature_size) << 3;
rx_left_row_num = 0;
}
}
else if(tx_cnt == 0) {
rx_len = (((pl_buffer_row_num-1)>>1)<<3)*(feature_size>>1);
rx_left_row_num = (pl_buffer_row_num-1)%2;
}
else if(tx_cnt == tx_cnt_end-1) {
rx_len = (((tx_last_row_num-1+rx_left_row_num)>>1)<<3)*(feature_size>>1);
}
else {
rx_len = (((pl_buffer_row_num-2+rx_left_row_num)>>1)<<3)*(feature_size>>1);
rx_left_row_num = (pl_buffer_row_num-2+rx_left_row_num)%2;
}
}
void update_cmd()
{
if(conv_type == 0)
reg_cmd = CONV_TYPE3|IS_PADDING;
else
reg_cmd = CONV_TYPE1;
if(is_pool == 1)
reg_cmd |= IS_POOL;
if(pool_stride == 1)
reg_cmd |= POOL_STRIDE1;
if(feature_size <= 52)
reg_cmd |= SITE_ALL;
else if(tx_cnt == 0)
reg_cmd |= SITE_FIRST;
else if(tx_cnt == tx_cnt_end - 1)
reg_cmd |= SITE_LAST;
else
reg_cmd |= SITE_MIDDLE;
if(ch_in_batch_cnt == (ch_in_batch_cnt_end-1))
reg_cmd |= BATCH_LAST;
else if(ch_in_batch_cnt == 0)
reg_cmd |= BATCH_FIRST;
else
reg_cmd |= BATCH_MIDDLE;
reg_cmd = reg_cmd | SET_COL_TYPE(col_type);
if(feature_size <= 52)
reg_cmd = reg_cmd | SET_ROW_NUM(feature_size);
else if(tx_cnt == tx_cnt_end-1)
reg_cmd = reg_cmd | SET_ROW_NUM(tx_last_row_num);
else
reg_cmd = reg_cmd | SET_ROW_NUM(pl_buffer_row_num);
}
void update_cnt_info()
{
if(ch_in_batch_cnt == ch_in_batch_cnt_end-1) {
ch_in_batch_cnt = 0;
if(tx_cnt == tx_cnt_end-1) {
tx_cnt = 0;
ch_out_batch_cnt++;
}
else
tx_cnt++;
}
else
ch_in_batch_cnt++;
}
void wait_pl_finish()
{
while(InterruptProcessed == FALSE);
InterruptProcessed = FALSE;
}
void yolo_forward_init(int layer_config[], int i)
{
conv_type = layer_config[0];
ch_in = layer_config[1];
ch_out = layer_config[2];
is_pool = layer_config[3];
feature_size = layer_config[4];
mult = layer_config[5];
shift = layer_config[6];
zp_in = layer_config[7];
zp_out = layer_config[8];
if(i == 5) // 判断当前执行的层是否为Layer10,Layer11
pool_stride = 1;
else
pool_stride = 0;
///////////////////////////////////////////////////////////////////
// 获取计数器相关的值
tx_cnt = 0;
ch_out_batch_cnt = 0;
ch_out_batch_cnt_end = ch_out>>3;
ch_in_batch_cnt = 0;
ch_in_batch_cnt_end = ch_in>>3;
if(feature_size <= 52) {
pl_buffer_row_num = feature_size;
tx_row_num = feature_size;
tx_last_row_num = 0;
}
else {
pl_buffer_row_num = PL_BUFFER_LEN / feature_size; // PL端数据BUFFER能存储特征图数据的最大行数量
tx_row_num = pl_buffer_row_num - 2; // PS端每次实际发送特征图数据的行数量
tx_last_row_num = feature_size % tx_row_num; // PS端最后一次发送特征图数据的行数量
}
if(tx_last_row_num == 0)
tx_cnt_end = feature_size / tx_row_num;
else
tx_cnt_end = feature_size / tx_row_num + 1;
///////////////////////////////////////////////////////////////////
bias_buffer_rd_addr = 0;
weight_buffer_rd_addr = 0;
weight_tx_addr = WeightAddr[i];
weight_batch_cnt = 0;
bias_len = ch_out*4;
if(conv_type == 0) {
if(ch_in * ch_out <= 16384)
weight_len = ch_in * ch_out * 9;
else
weight_len = 16384 * 9;
}
else {
if(ch_in * ch_out <= 16384)
weight_len = ch_in * ch_out;
else
weight_len = 16384;
}
///////////////////////////////////////////////////////////////////
tx_base_addr = layers_tx_addr[i];
rx_base_addr = layers_rx_addr[i];
///////////////////////////////////////////////////////////////////
if(feature_size == 416)
col_type = 0;
else if(feature_size == 208)
col_type = 1;
else if(feature_size == 104)
col_type = 2;
else if(feature_size == 52)
col_type = 3;
else if(feature_size == 26)
col_type = 4;
else if(feature_size == 13)
col_type = 5;
}
void yolo_forward()
{
for(int i=0; i<9; i++) {
yolo_forward_init(layers_config[i], i);
state = S_IDLE;
while(state != S_FINISH) {
switch(state) {
case S_IDLE:
Xil_Out32(Lite_Reg2, SET_SHIFT_ZP(shift,zp_out, zp_in));
Xil_Out32(Lite_Reg1, SET_MULT_BUFFER_RDADDR(mult, bias_buffer_rd_addr, weight_buffer_rd_addr));
Xil_Out32(Lite_Reg0, WRITE_BIAS); // 发送bias数据
DMA_Tx(BiasAddr[i], bias_len);
wait_pl_finish();
Xil_Out32(Lite_Reg0, WRITE_LEAKY_RELU); // 发送LeakyRelu数据
DMA_Tx(ActAddr[i], 256);
wait_pl_finish();
if(conv_type == 0)
Xil_Out32(Lite_Reg0, WRITE_WEIGHT); // 发送卷积3x3的Weight数据
else
Xil_Out32(Lite_Reg0, WRITE_WEIGHT|CONV_TYPE1); // 发送卷积1x1Weight数据
DMA_Tx(weight_tx_addr, weight_len);
wait_pl_finish();
state = S_FEATURE_CONV;
break;
case S_FEATURE_CONV:
update_tx_info();
update_cmd();
Xil_Out32(Lite_Reg0, reg_cmd|WRITE_FEATURE); // 发送Feature数据
DMA_Tx(tx_addr, tx_len);
wait_pl_finish();
Xil_Out32(Lite_Reg0, reg_cmd|CONV_START); // 卷积计算
wait_pl_finish();
if(ch_in_batch_cnt == ch_in_batch_cnt_end-1)
state = S_DMA_RX;
else {
update_cnt_info();
state = S_FEATURE_CONV;
weight_buffer_rd_addr=ch_in_batch_cnt+ch_out_batch_cnt*ch_in_batch_cnt_end - (weight_batch_cnt<<8);
Xil_Out32(Lite_Reg1, SET_MULT_BUFFER_RDADDR(mult, bias_buffer_rd_addr, weight_buffer_rd_addr));
}
break;
case S_DMA_RX:
update_rx_info();
Xil_Out32(Lite_Reg0, reg_cmd|READ_START); // 将PL端的数据传至PS端
DMA_Rx(rx_addr, rx_len); // 9行数据+1行填充=10行数据 --->卷积后,8个416的数据量---》经过池化后,变成4*208---> 总共8个通道,即最终数据量4*208*8=6656
wait_pl_finish();
Xil_DCacheFlushRange(rx_addr, rx_len);
if(tx_cnt == tx_cnt_end-1 && ch_out_batch_cnt == ch_out_batch_cnt_end-1 && ch_in_batch_cnt == ch_in_batch_cnt_end-1)
state = S_FINISH;
else {
state = S_FEATURE_CONV;
update_cnt_info();
if((ch_out_batch_cnt*ch_in_batch_cnt_end)%256==0 && ch_in_batch_cnt == 0 && tx_cnt == 0){
weight_tx_addr = weight_tx_addr + weight_len;
if(conv_type == 0)
Xil_Out32(Lite_Reg0, WRITE_WEIGHT); // 发送卷积3x3的Weight数据
else
Xil_Out32(Lite_Reg0, WRITE_WEIGHT|CONV_TYPE1); // 发送卷积1x1Weight数据
DMA_Tx(weight_tx_addr, weight_len);
wait_pl_finish();
weight_batch_cnt++;
}
bias_buffer_rd_addr = ch_out_batch_cnt;
weight_buffer_rd_addr=ch_in_batch_cnt+ch_out_batch_cnt*ch_in_batch_cnt_end - (weight_batch_cnt<<8);
Xil_Out32(Lite_Reg1, SET_MULT_BUFFER_RDADDR(mult, bias_buffer_rd_addr, weight_buffer_rd_addr));
}
break;
case S_FINISH: break;
default: break;
}
}
}
}
yolo_accel_ctrl.h
int layers_config[9][9];
u8 conv_type ;
u16 ch_in;
u16 ch_out;
u8 is_pool;
u16 feature_size;
u16 mult;
u8 shift;
u8 zp_in;
u8 zp_out;
u8 pool_stride;
u8 col_type;
u8 ch_in_batch_cnt;
u8 ch_in_batch_cnt_end;
u8 ch_out_batch_cnt;
u8 ch_out_batch_cnt_end;
u8 tx_cnt;
u8 tx_cnt_end;
u8 batch_cnt;
u8 batch_cnt_end;
u8 pl_buffer_row_num;
u8 tx_row_num;
u8 tx_last_row_num;
u8 rx_left_row_num;
u8 bias_buffer_rd_addr;
u8 weight_buffer_rd_addr;
u32 weight_tx_addr;
u32 weight_batch_cnt;
u32 layers_tx_addr[9];
u32 layers_rx_addr[9];
u32 tx_base_addr;
u32 rx_base_addr;
u32 reg_cmd;
u32 tx_addr;
u32 tx_len;
u32 rx_addr;
u32 rx_len;
u32 bias_len;
u32 weight_len;
char state;
char InterruptProcessed;
void update_tx_info();
void update_rx_info();
void update_cmd();
void update_cnt_info();
void yolo_forward();
void yolo_forward_init(int layer_config[], int i);
void wait_pl_finish();

 浙公网安备 33010602011771号
浙公网安备 33010602011771号