完善1x1卷积方案
完善1x1卷积方案
-
1x1的卷积和3x3的卷积有什么区别?
1x1卷积是一种特殊的卷积操作,它只对输入数据的每个像素点进行一次乘法和累加,而不需要构造3x3的矩阵。这样可以减少计算量和内存消耗,同时也可以改变输入数据的通道数,实现特征融合或降维。 3x3卷积则是一种常见的卷积操作,它需要对输入数据的每个3x3的区域进行乘法和累加,同时也需要构造3x3的矩阵。这样可以增加计算量和内存消耗,同时也可以提取输入数据的特征和变换,也可以起到平滑或锐化的作用。例子:假设输入数据是8个通道,每个通道是13x13的矩阵,权重是8个通道,每个通道是1x1的矩阵,输出数据也是8个通道,每个通道是13x13的矩阵 - 1x1卷积:对于每个输出通道,只需要将输入数据的同一位置的8个数与权重的8个数相乘再累加,得到一个数,放在输出矩阵的对应位置。重复这个过程169次(13x13),就得到一个输出通道。重复这个过程8次,就得到所有输出通道。 - 3x3卷积:对于每个输出通道,需要先将输入数据填充一圈0,变成15x15的矩阵。然后将输入数据的每个3x3的子矩阵与权重的3x3的矩阵对应相乘再累加,得到一个数,放在输出矩阵的对应位置。重复这个过程169次(13x13),就得到一个输出通道。重复这个过程8次,就得到所有输出通道- 1x1卷积
- 不需要构造3x3矩阵
- 只进行一次乘法和累加
- 可以改变通道数
- 减少计算量和内存消耗
- 3x3卷积
- 需要构造3x3矩阵
- 进行九次乘法和累加
- 保持通道数不变
- 增加计算量和内存消耗
- 3x3卷积需要构造3x3的矩阵,进行9次乘法和累加操作,需要填充数据,输出尺寸会变小
- 1x1卷积只需要进行一次乘法操作,不需要填充数据,输出尺寸不变
- 两者都是让8个卷积通道并行计算,但是1x1卷积会导致一些DSP闲置
- 1x1卷积
-
1x1卷积的特点
-
不需要构造3x3矩阵,直接将数据和权重相乘
-
不需要做填充,输入和输出尺寸不变
-
可以减少特征通道数,增加非线性,提高计算效率
-
YOLO网络中使用1x1卷积的原因有以下几点:
- 降低计算复杂度。由于1x1卷积只涉及一个像素点和一个权重的乘法,所以它比3x3卷积更节省计算资源和时间。
- 增加非线性。由于每个网格单元需要预测多个边界框和类别概率,所以YOLO网络需要有足够的表达能力来捕捉不同目标的特征。在3x3卷积层之间插入1x1卷积层可以增加网络的非线性,即增加网络的拟合能力。
- 实现特征融合。由于YOLO网络需要同时处理不同尺度和形状的目标,所以YOLO网络需要融合不同层次和通道的特征。在不同深度的3x3卷积层之间插入1x1卷积层可以实现特征融合,即将不同通道的特征进行加权组合。
例如,Yolo网络中的第13层使用了1x1卷积,它的输入尺寸是13x13x1024,输出尺寸是13x13x512,它相当于对每个13x13的特征图进行了一个降维操作,同时增加了激活函数
-
-
1x1卷积的缺点
- 不能捕捉空间信息,只能在通道维度上进行变换
- 不能实现下采样,需要配合其他卷积或池化层使用
- 会造成一些DSP资源的浪费,因为每个权重数据只占用8位,而RAM位宽为72位
-
为什么要完善1x1卷积方案
- 3x3卷积的加速方案,即让8个卷积通道同时并行计算
- 对于1x1卷积,如果也使用8个卷积通道并行计算,那么就会导致一些DSP资源浪费,因为每个卷积通道只需要一个乘法操作,而不是9个
- 如果能够利用所有的DSP资源,那么就可以计算更多的卷积通道,提高计算效率和吞吐量
- 但是,如果要改变输入通道的数量,那么就需要重新设计整体的方案和代码结构,这样很复杂和麻烦
- 所以,在这里,为了简化设计和保持一致性,还是采用8个卷积通道并行计算的方案,不管有没有DSP资源浪费
- 这样,无论是3x3卷积还是1x1卷积,都可以使用同样的方案
-
1x1卷积的加速方案
- Yolo加速方案里让8个卷积通道同时并行计算
- 对于1x1的卷积也让8个卷积通道同时并行计算
- 这样会导致一些DSP闲置,因为只用到一个乘法器
- 如果能利用所有的DSP,就能计算更多的卷积通道,意味着输入数据通道数也要变多
- 但是这样就需要重新设计整体方案和代码结构,很复杂很麻烦
- 所以还是让8个卷积通道并行计算,不管有没有DSP闲置
- 结论:不管是3x3还是1x1的卷积,都是让8个卷积通道并行计算
-
与3x3卷积一样,使用8个卷积通道并行计算,不考虑DSP资源的优化(即使有些DSP闲置)
仍然让8个卷积通道并行计算,即使有些DSP闲置,避免改变整体方案和代码结构
-
修改权重缓存模块,不进行3x3拼接,直接将8位权重写入RAM,剩余64位补零
-
新建一个读数据控制模块,根据卷积类型和输入尺寸,从FIFO中读取整个通道的数据,并发送到卷积核计算模块
-
修改卷积核计算模块,根据卷积类型,选择不同的数据和有效标志输入,并输出结果
-
修改顶层模块,根据是否需要池化,选择将激活后或池化后的数据写入buffer
-
如何完善1x1卷积方案
-
完善1x1卷积方案主要涉及到两个方面:权重缓存和数据缓存
-
对于权重缓存,因为不需要构造3x3的矩阵,所以可以省去拼接的操作,直接将8位的权重数据写入到72位的RAM中,每个权重数据占用一个RAM地址,剩余的64位可以补零。根据卷积类型信号来判断是否进行拼接或直接写入
为了实现权重缓存,需要在FPGA内部定义8个通道的权重buffer,每个通道的buffer又包含8个RAM,每个RAM的位宽为72位,与输入数据通道相对应。
![image]()
-
对于数据缓存,因为不需要做填充和矩阵构造,所以可以省去这两个模块,直接将从FIFO中读取的数据送到卷积核计算模块中。根据卷积类型信号来判断是否进行填充或直接读取。由于输入数据尺寸都小于buffer深度(13x13或26x26),所以可以直接读取整个通道的数据,不需要分段读取
-
在代码上,需要根据卷积类型
conv_type(0表示3x3卷积,1表示1x1卷积)来做一些判断和选择,例如:- 在权重缓存模块中,根据卷积类型来改变写使能信号和写地址信号
- 在数据缓存模块中,根据卷积类型来改变读使能信号和读地址信号
- 在转接计算模块中,根据卷积类型来改变数据输入信号和数据输出信号
-
-
1x1卷积的权重缓存和读取方法
- 权重数据从PC端过来后,先缓存到FIFO里面
- 权重数据从FIFO出来后,根据卷积类型判断是否需要拼接成72位
- 如果是3x3卷积,需要拼接9个8位权重数据,每拼接完一次产生一次写使能信号
- 如果是1x1卷积,不需要拼接,直接将8位权重数据写入RAM,每来一个数据产生一次写使能信号
- 权重数据从RAM读出来后,根据输入通道数和输出通道数进行选择和分配
-
1x1卷积的数据缓存和读取方法
- 数据缓存方法和3x3卷积相同,都是先缓存到FIFO里面
- 数据读取方法和3x3卷积不同,不需要进行填充和矩阵构造
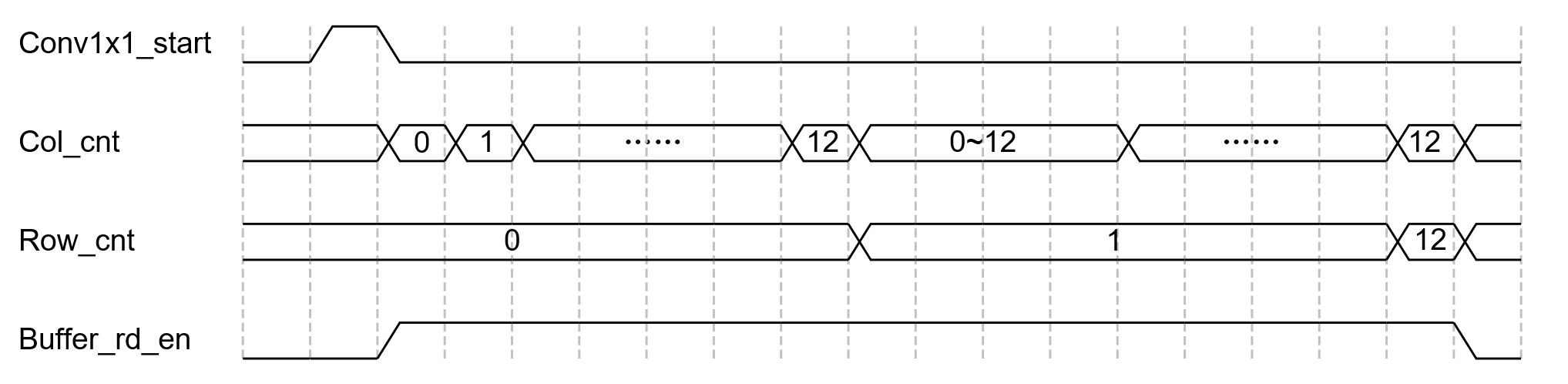
- 新建一个模块用于控制数据读取时序,根据输入尺寸(13x13或26x26)确定行数和列数
- 当收到start信号时,产生buffer读使能信号,并开始计数器计数(col_cnt和row_cnt)
- 当两个计数器都达到最大值时(12或25),拉低buffer读使能信号,并产生finish信号
- 将buffer读出来的数据直接送到卷积核计算模块里面去,只取第一个8位数据,剩下的补0
-
1x1卷积的计算方法和输出结果
- 计算方法就是将输入数据和权重数据直接相乘,然后累加得到输出结果
- 输出结果就是一个8位数据,不需要进行位宽调整或截断
-
1x1卷积的后续处理(激活、池化等)
- 根据网络结构,1x1卷积后面还有激活函数(ReLU或Leaky ReLU)和池化层(最大池化或平均池化)
- 激活函数的作用是增加非线性,提高网络的表达能力
- 池化层的作用是降低特征图的尺寸,减少计算量和参数量,防止过拟合
- 但是在Yolo网络中,1x1卷积后面没有池化层,而是直接进入下一层的3x3卷积,所以不需要进行池化操作
- 所以在输出结果时,需要根据是否需要池化来判断是将激活后的数据还是池化后的数据写入buffer里面
-
举例说明
- 假设输入数据为13x13x8的特征图(即13行13列8通道),权重数据为8位整数
- 假设要进行1x1卷积操作,输出通道数为16(即每个输入通道对应两个输出通道)
- 假设使用8个卷积通道并行计算的方案,即每个卷积通道处理一个输入通道和两个输出通道
- 那么,完善1x1卷积方案的过程如下:
- 权重缓存:从PC端接收权重数据,每次接收8个权重数据(即一个输入通道对应的两个输出通道的权重),直接写入到对应的RAM中,不需要拼接,剩余的64位补0
- 数据缓存:从FIFO中读取输入数据,每次读取8个输入数据(即8个输入通道的同一位置的像素),直接送到卷积核计算模块中,不需要填充和矩阵构造
- 卷积核计算:对每个卷积通道,将输入数据和权重数据相乘,然后累加,得到两个输出数据(即两个输出通道的同一位置的像素),然后进行激活和量化操作
- 输出结果:将卷积核计算得到的输出数据写入到输出FIFO中,等待下一层卷积操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号