基于XC7Z100+OV5640(DSP接口)YOLO人脸识别模块编写思路(部分2)
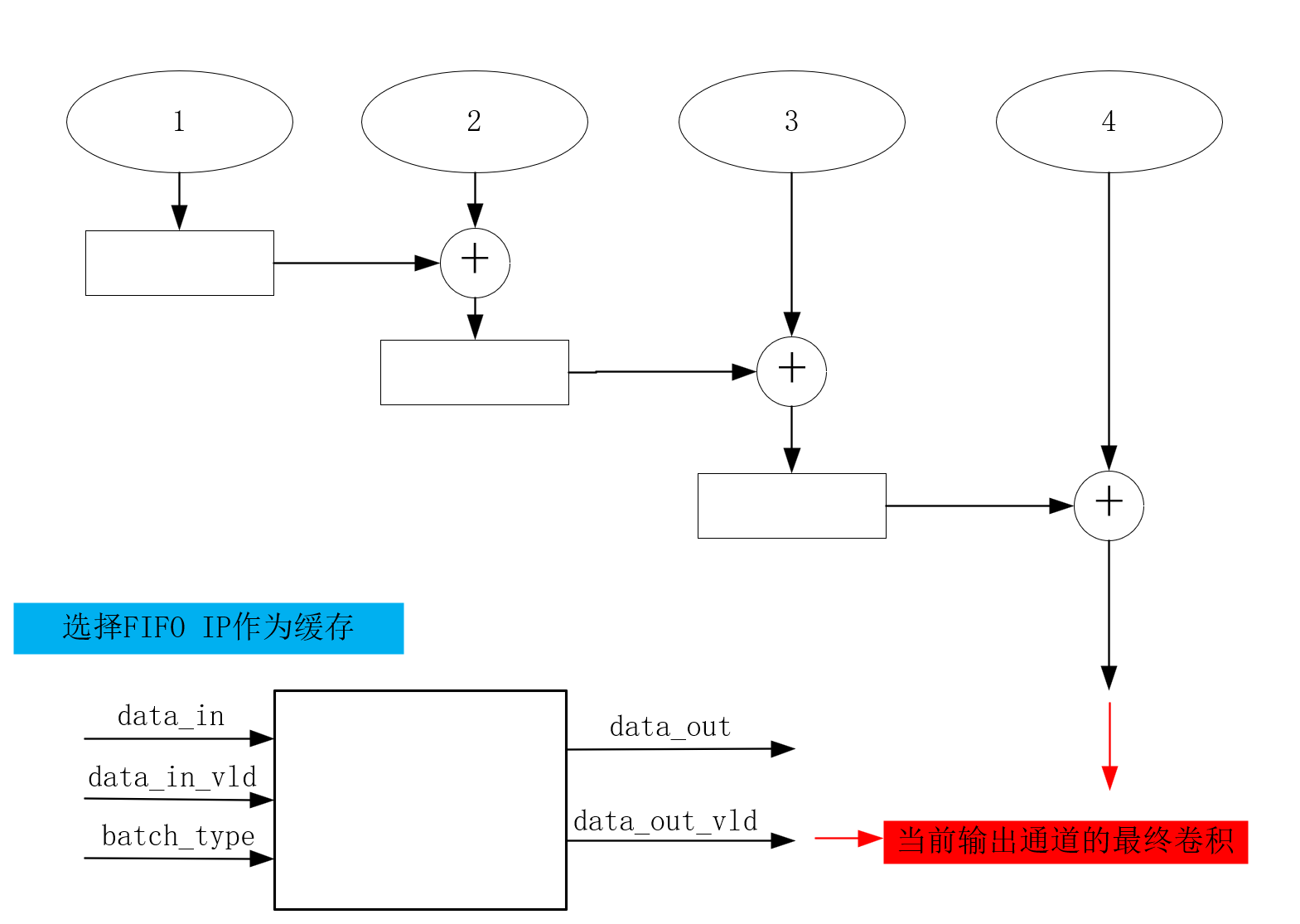
实现分批卷积计算的累加模块
- 分批卷积计算:指的是将卷积层的输入通道或输出通道分成若干个批次,每次只计算一部分通道的卷积,然后将所有批次的结果累加起来,得到最终的卷积输出。这样做的目的是为了减少计算资源的消耗,提高运算效率。
- 累加模块:指的是用于缓存和累加分批卷积计算的中间结果的模块,它主要包含一个 FIFO(先进先出)存储器和一个加法器。根据不同的批次类型(第一批、中间批或最后一批),累加模块会对 FIFO 进行不同的读写操作,并将最终的累加结果输出。
包含两个模块:conv_kernel_acc 和 conv_kernel_acc_8ch。
功能是实现分批卷积计算的累加模块,即对输入的数据进行分批累加,并输出最终结果。其中,conv_kernel_acc 是一个单通道的累加模块,conv_kernel_acc_8ch 是一个八通道的累加模块,它由八个 conv_kernel_acc 组成。
-
conv_kernel_acc模块 (单通道累加模块)
- 输入:data_in(24位有符号数),data_in_vld(数据有效信号),batch_type(批次类型信号)
- 输出:data_out(32位有符号数)
- 设计思路(累加逻辑):
- 使用一个FIFO缓存上一个批次的卷积结果,根据batch_type信号决定是否进行累加操作
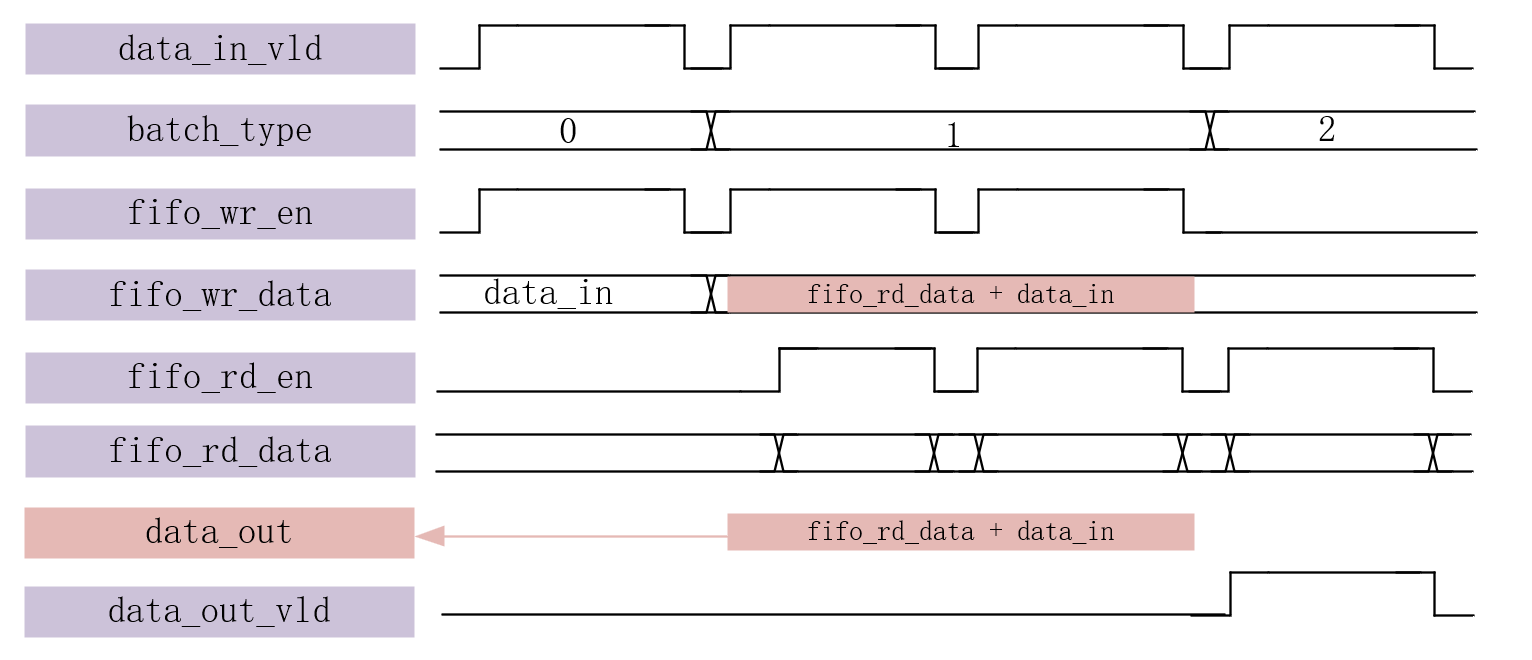
- batch_type == 0:(第一批数据)表示输入数据是第一批次的第一个元素,此时 fifo_wr_en = data_in_vld,fifo_wr_data = data_in,即将输入数据直接写入 FIFO。
- batch_type == 1:(中间批次数据)表示输入数据是第一批次的非第一个元素,此时 fifo_wr_en = data_in_vld,fifo_wr_data = data_in + fifo_rd_data,即将输入数据与 FIFO 中的数据相加后写入 FIFO。
- batch_type == 2:(最后一批数据)表示输入数据是第二批次的第一个元素,此时 fifo_wr_en = 0,data_out = data_in + fifo_rd_data,即将输入数据与 FIFO 中的数据相加后输出。
- 当batch_type为其他值时,不进行任何操作。
- FIFO 的读使能 fifo_rd_en 由 batch_type 和 data_in_vld 共同决定,当 batch_type > 0 且 data_in_vld = 1 时为高电平,否则为低电平。这样可以保证 FIFO 只在需要累加或输出时才读出数据。
- data_out 是一个寄存器型信号,在时钟上升沿或复位信号下降沿更新。当复位信号为低电平时,data_out 清零;当 batch_type == 2 时,data_out 赋值为 data_in + fifo_rd_data。
-
conv_kernel_acc_8ch模块 (8通道累加模块)
-
输入:ch0_data_in到ch7_data_in(8个24位有符号数),data_in_vld(数据有效信号),batch_type(批次类型信号)
-
输出:ch0_data_out到ch7_data_out(8个32位有符号数),data_out_vld(输出有效信号)
-
设计思路(累加逻辑):
8通道累加模块的累加逻辑与单通道累加模块的累加逻辑相同,只是将每个通道的输入数据和输出数据分别传递给对应的单通道累加模块实例
- 内部实例化了八个 conv_kernel_acc 模块,分别对应每个通道的累加操作。每个子模块的输入输出信号与父模块相连。
- data_out_vld 是一个寄存器型信号,在时钟上升沿或复位信号下降沿更新。当复位信号为低电平时,data_out_vld 清零;当 batch_type == 2 时,data_out_vld 赋值为 data_in_vld。
问题及解决方法:
- 如何避免竞争和冒险现象?
- 解决方法:使用非阻塞赋值符号<=来实现状态信息的更新,避免在同一个always语句中对同一个变量进行多次赋值。同时使用复位信号rst_n来初始化状态信息,避免出现不确定的状态值。
- 在设计FIFO存储器时,需要考虑FIFO满和空的情况,以及写入和读出的同步问题。为了解决这些问题,可以采用以下方法:
- 使用full和empty信号来判断FIFO是否可以写入或读出数据,并在相应的控制信号上加入逻辑判断。例如,当FIFO满时,不允许写入数据;当FIFO空时,不允许读出数据
- 使用同步电路来保证写入和读出的时钟同步。例如,使用触发器或锁存器来实现数据的同步更新,或使用同步器来实现跨时钟域的数据传输³
- 在设计累加模块时,需要考虑不同批次的数据如何进行累加操作,以及如何判断输出是否有效。为了解决这些问题,可以采用以下方法:
- 使用batch_type信号来区分不同批次的数据,并在相应的逻辑表达式上加入条件判断。例如,当batch_type为0时,表示第一批数据,直接输出;当batch_type为1时,表示后续批次的数据,需要与上一批次的结果进行累加;当batch_type为2时,表示最后一批数据,需要输出一个有效信号
- 使用data_out_vld信号来表示输出是否有效,并在相应的时序逻辑上加入条件判断。例如,当batch_type为2时,表示最后一批数据,需要输出一个data_out_vld信号,表示输出有效;否则,不输出data_out_vld信号
-
assign fifo_rd_en = (batch_type > 'd0) ? data_in_vld : 1'b0;
always @(posedge sclk or negedge s_rst_n) begin
if(s_rst_n == 1'b0) begin
fifo_wr_en <= 1'b0;
fifo_wr_data <= 'd0;
end
else case(batch_type)
0: begin
fifo_wr_en <= data_in_vld;
fifo_wr_data <= data_in;
end
1: begin
fifo_wr_en <= data_in_vld;
fifo_wr_data <= data_in + fifo_rd_data;
end
default: begin
fifo_wr_en <= 1'b0;
fifo_wr_data <= 'd0;
end
endcase
end
always @(posedge sclk or negedge s_rst_n) begin
if(s_rst_n == 1'b0) begin
data_out <= 'd0;
end
else if(batch_type == 'd2) begin
data_out <= data_in + fifo_rd_data;
end
end
acc_fifo_ip acc_fifo_ip_inst (
.clk (sclk ), // input wire clk
.srst (~s_rst_n ), // input wire srst
.din (fifo_wr_data ), // input wire [31 : 0] din
.wr_en (fifo_wr_en ), // input wire wr_en
.rd_en (fifo_rd_en ), // input wire rd_en
.dout (fifo_rd_data ), // output wire [31 : 0] dout
.full ( ), // output wire full
.empty ( ), // output wire empty
.data_count ( ) // output wire [12 : 0] data_count
);
conv_kernel_acc ch0_conv_kernel_acc_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch0_data_in ),
.data_in_vld (data_in_vld ),
.batch_type (batch_type ),
//
.data_out (ch0_data_out )
);
conv_kernel_acc ch1_conv_kernel_acc_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch1_data_in ),
.data_in_vld (data_in_vld ),
.batch_type (batch_type ),
//
.data_out (ch1_data_out )
);
conv_kernel_acc ch2_conv_kernel_acc_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch2_data_in ),
.data_in_vld (data_in_vld ),
.batch_type (batch_type ),
//
.data_out (ch2_data_out )
);
conv_kernel_acc ch3_conv_kernel_acc_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch3_data_in ),
.data_in_vld (data_in_vld ),
.batch_type (batch_type ),
//
.data_out (ch3_data_out )
);
conv_kernel_acc ch4_conv_kernel_acc_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch4_data_in ),
.data_in_vld (data_in_vld ),
.batch_type (batch_type ),
//
.data_out (ch4_data_out )
);
conv_kernel_acc ch5_conv_kernel_acc_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch5_data_in ),
.data_in_vld (data_in_vld ),
.batch_type (batch_type ),
//
.data_out (ch5_data_out )
);
conv_kernel_acc ch6_conv_kernel_acc_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch6_data_in ),
.data_in_vld (data_in_vld ),
.batch_type (batch_type ),
//
.data_out (ch6_data_out )
);
conv_kernel_acc ch7_conv_kernel_acc_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch7_data_in ),
.data_in_vld (data_in_vld ),
.batch_type (batch_type ),
//
.data_out (ch7_data_out )
);
实现多通道卷积运算
代码功能
实现了多通道卷积运算,即对多个输入通道的数据矩阵和多个卷积核矩阵进行乘加运算,得到多个输出通道的结果矩阵。卷积运算是一种常用的图像处理和深度学习的算法,可以提取特征和降低维度。
代码结构
- conv_kernel_1x2: 实现一个输入通道和两个输出通道的卷积运算,即对一个3x3的数据矩阵和两个3x3的卷积核矩阵进行乘加运算,得到两个1x2的结果矩阵。该模块使用了conv_mult_dsp子模块来实现数据和权重的乘法运算,以及conv_kernel_1x2_add子模块来实现结果矩阵的加法运算。
- conv_kernel_2ch: 实现两个输入通道和两个输出通道的卷积运算,即对两个3x3的数据矩阵和四个3x3的卷积核矩阵进行乘加运算,得到两个1x2的结果矩阵。该模块使用了conv_kernel_1x2子模块来实现每个输入通道和每个输出通道的卷积运算,以及conv_kernel_2ch_add子模块来实现结果矩阵的加法运算和偏置项的加法运算。
- conv_kernel_8ch: 实现八个输入通道和八个输出通道的卷积运算,即对八个3x3的数据矩阵和六十四个3x3的卷积核矩阵进行乘加运算,得到八个1x2的结果矩阵。该模块使用了conv_kernel_2ch子模块来实现每两个输入通道和每两个输出通道的卷积运算。
- conv_mult_dsp: 实现数据和权重的乘法运算,即对一个8位有符号数和一个8位有符号数进行乘法运算,得到一个16位有符号数。该模块使用了DSP48E1原语来实现乘法器。
- conv_kernel_1x2_add: 实现结果矩阵的加法运算,即对九个16位有符号数进行加法运算,得到一个20位有符号数。该模块使用了三级加法器来实现加法逻辑。
- conv_kernel_2ch_add: 实现结果矩阵的加法运算和偏置项的加法运算,即对八个20位有符号数进行加法运算,并根据偏置使能信号决定是否加上一个32位有符号数,得到一个24位有符号数。该模块使用了三级加法器来实现加法逻辑。
代码时序
代码的时序是同步时序,以sclk为时钟信号,以s_rst_n为复位信号。当s_rst_n为低电平时,所有寄存器清零;当s_rst_n为高电平时,所有寄存器根据时钟上升沿更新值。
代码设计思路
- 将多通道卷积运算分解为多个单通道或双通道卷积运算,以便复用相同的模块和减少资源消耗。
- 将单通道或双通道卷积运算分解为多个乘法运算和加法运算,以便利用DSP48E1原语和加法器来实现。
- 将数据矩阵和卷积核矩阵分别用72位的向量来表示,以便将每个元素用8位有符号数来表示。
- 将结果矩阵用24位有符号数来表示,以便保证足够的精度和范围。
- 使用偏置使能信号来控制是否加上偏置项,以便提供更多的灵活性和功能。
- 为了实现多通道卷积运算,首先需要实现一个基本的卷积核,即conv_kernel_1x2模块。该模块使用了九个conv_mult_dsp模块来实现乘法运算,并且使用了两个conv_kernel_1x2_add模块来实现加法运算。最终输出两个20位有符号数作为卷积结果。
- 为了实现多通道卷积运算,需要将多个基本的卷积核组合起来,即conv_kernel_2ch和conv_kernel_8ch模块。这两个模块都使用了多个conv_kernel_1x2模块来实现多通道卷积运算,并且可以选择是否加上偏置值。最终输出多个24位有符号数作为卷积结果。
代码遇到问题及解决方法
- 由于卷积运算涉及大量的乘法运算和加法运算,因此可能会消耗大量的DSP48E1资源和逻辑资源,导致资源不足或时序不满足的问题。解决方法是根据目标平台的资源情况,合理分配数据位宽和结果位宽,以及优化乘法运算和加法运算的结构和顺序,以减少资源消耗和延迟。
- 由于卷积运算涉及大量的数据传输,因此可能会造成数据拥塞或数据丢失的问题。解决方法是根据目标平台的接口情况,合理设计数据格式和数据流控制,以保证数据完整性和有效性。
- 由于卷积运算涉及大量的参数配置,因此可能会造成参数错误或参数不匹配的问题。解决方法是根据目标应用的需求,合理设计参数接口和参数校验,以保证参数正确性和一致性。
主要代码清单:
conv_kernel_1x2
assign data_00 = data_in[7:0];
assign data_10 = data_in[15:8];
assign data_20 = data_in[23:16];
assign data_01 = data_in[31:24];
assign data_11 = data_in[39:32];
assign data_21 = data_in[47:40];
assign data_02 = data_in[55:48];
assign data_12 = data_in[63:56];
assign data_22 = data_in[71:64];
assign ch0_w_00 = ch0_weight[7:0];
assign ch0_w_01 = ch0_weight[15:8];
assign ch0_w_02 = ch0_weight[23:16];
assign ch0_w_10 = ch0_weight[31:24];
assign ch0_w_11 = ch0_weight[39:32];
assign ch0_w_12 = ch0_weight[47:40];
assign ch0_w_20 = ch0_weight[55:48];
assign ch0_w_21 = ch0_weight[63:56];
assign ch0_w_22 = ch0_weight[71:64];
assign ch1_w_00 = ch1_weight[7:0];
assign ch1_w_01 = ch1_weight[15:8];
assign ch1_w_02 = ch1_weight[23:16];
assign ch1_w_10 = ch1_weight[31:24];
assign ch1_w_11 = ch1_weight[39:32];
assign ch1_w_12 = ch1_weight[47:40];
assign ch1_w_20 = ch1_weight[55:48];
assign ch1_w_21 = ch1_weight[63:56];
assign ch1_w_22 = ch1_weight[71:64];
conv_mult_dsp U00_conv_mult_dsp_inst(
// system signals
.sclk (sclk ),
//
.data_a (ch0_w_00 ),
.data_d (ch1_w_00 ),
.data_b (data_00 ),
//
.data_ab (ch0_out_00 ),
.data_db (ch1_out_00 )
);
conv_mult_dsp U01_conv_mult_dsp_inst(
// system signals
.sclk (sclk ),
//
.data_a (ch0_w_01 ),
.data_d (ch1_w_01 ),
.data_b (data_01 ),
//
.data_ab (ch0_out_01 ),
.data_db (ch1_out_01 )
);
conv_mult_dsp U02_conv_mult_dsp_inst(
// system signals
.sclk (sclk ),
//
.data_a (ch0_w_02 ),
.data_d (ch1_w_02 ),
.data_b (data_02 ),
//
.data_ab (ch0_out_02 ),
.data_db (ch1_out_02 )
);
conv_mult_dsp U10_conv_mult_dsp_inst(
// system signals
.sclk (sclk ),
//
.data_a (ch0_w_10 ),
.data_d (ch1_w_10 ),
.data_b (data_10 ),
//
.data_ab (ch0_out_10 ),
.data_db (ch1_out_10 )
);
conv_mult_dsp U11_conv_mult_dsp_inst(
// system signals
.sclk (sclk ),
//
.data_a (ch0_w_11 ),
.data_d (ch1_w_11 ),
.data_b (data_11 ),
//
.data_ab (ch0_out_11 ),
.data_db (ch1_out_11 )
);
conv_mult_dsp U12_conv_mult_dsp_inst(
// system signals
.sclk (sclk ),
//
.data_a (ch0_w_12 ),
.data_d (ch1_w_12 ),
.data_b (data_12 ),
//
.data_ab (ch0_out_12 ),
.data_db (ch1_out_12 )
);
conv_mult_dsp U20_conv_mult_dsp_inst(
// system signals
.sclk (sclk ),
//
.data_a (ch0_w_20 ),
.data_d (ch1_w_20 ),
.data_b (data_20 ),
//
.data_ab (ch0_out_20 ),
.data_db (ch1_out_20 )
);
conv_mult_dsp U21_conv_mult_dsp_inst(
// system signals
.sclk (sclk ),
//
.data_a (ch0_w_21 ),
.data_d (ch1_w_21 ),
.data_b (data_21 ),
//
.data_ab (ch0_out_21 ),
.data_db (ch1_out_21 )
);
conv_mult_dsp U22_conv_mult_dsp_inst(
// system signals
.sclk (sclk ),
//
.data_a (ch0_w_22 ),
.data_d (ch1_w_22 ),
.data_b (data_22 ),
//
.data_ab (ch0_out_22 ),
.data_db (ch1_out_22 )
);
conv_kernel_1x2_add ch0_conv_kernel_1x2_add_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data00 (ch0_out_00 ),
.data01 (ch0_out_01 ),
.data02 (ch0_out_02 ),
.data10 (ch0_out_10 ),
.data11 (ch0_out_11 ),
.data12 (ch0_out_12 ),
.data20 (ch0_out_20 ),
.data21 (ch0_out_21 ),
.data22 (ch0_out_22 ),
//
.add_result (ch0_out )
);
conv_kernel_1x2_add ch0_conv_kernel_1x2_add_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data00 (ch1_out_00 ),
.data01 (ch1_out_01 ),
.data02 (ch1_out_02 ),
.data10 (ch1_out_10 ),
.data11 (ch1_out_11 ),
.data12 (ch1_out_12 ),
.data20 (ch1_out_20 ),
.data21 (ch1_out_21 ),
.data22 (ch1_out_22 ),
//
.add_result (ch1_out )
);
conv_kernel_1x2_add
reg signed [19:0] temp0 ;
reg signed [19:0] temp1 ;
reg signed [19:0] temp2 ;
//=============================================================================
//************** Main Code **************
//=============================================================================
always @(posedge sclk or negedge s_rst_n) begin
if(s_rst_n == 1'b0) begin
temp0 <= 'd0;
temp1 <= 'd0;
temp2 <= 'd0;
add_result <= 'd0;
end
else begin
temp0 <= data00 + data01 + data02;
temp1 <= data10 + data11 + data12;
temp2 <= data20 + data21 + data22;
add_result <= temp0 + temp1 + temp2;
end
end
conv_kernel_2ch
wire signed [19:0] ch0_out_0 ;
wire signed [19:0] ch0_out_1 ;
wire signed [19:0] ch0_out_2 ;
wire signed [19:0] ch0_out_3 ;
wire signed [19:0] ch0_out_4 ;
wire signed [19:0] ch0_out_5 ;
wire signed [19:0] ch0_out_6 ;
wire signed [19:0] ch0_out_7 ;
wire signed [19:0] ch1_out_0 ;
wire signed [19:0] ch1_out_1 ;
wire signed [19:0] ch1_out_2 ;
wire signed [19:0] ch1_out_3 ;
wire signed [19:0] ch1_out_4 ;
wire signed [19:0] ch1_out_5 ;
wire signed [19:0] ch1_out_6 ;
wire signed [19:0] ch1_out_7 ;
//=============================================================================
//************** Main Code **************
//=============================================================================
conv_kernel_1x2 U0_conv_kernel_1x2_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch0_data_in ),
.ch0_weight (ch0_weight_0 ),
.ch1_weight (ch1_weight_0 ),
//
.ch0_out (ch0_out_0 ),
.ch1_out (ch1_out_0 )
);
conv_kernel_1x2 U1_conv_kernel_1x2_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch1_data_in ),
.ch0_weight (ch0_weight_1 ),
.ch1_weight (ch1_weight_1 ),
//
.ch0_out (ch0_out_1 ),
.ch1_out (ch1_out_1 )
);
conv_kernel_1x2 U2_conv_kernel_1x2_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch2_data_in ),
.ch0_weight (ch0_weight_2 ),
.ch1_weight (ch1_weight_2 ),
//
.ch0_out (ch0_out_2 ),
.ch1_out (ch1_out_2 )
);
conv_kernel_1x2 U3_conv_kernel_1x2_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch3_data_in ),
.ch0_weight (ch0_weight_3 ),
.ch1_weight (ch1_weight_3 ),
//
.ch0_out (ch0_out_3 ),
.ch1_out (ch1_out_3 )
);
conv_kernel_1x2 U4_conv_kernel_1x2_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch4_data_in ),
.ch0_weight (ch0_weight_4 ),
.ch1_weight (ch1_weight_4 ),
//
.ch0_out (ch0_out_4 ),
.ch1_out (ch1_out_4 )
);
conv_kernel_1x2 U5_conv_kernel_1x2_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch5_data_in ),
.ch0_weight (ch0_weight_5 ),
.ch1_weight (ch1_weight_5 ),
//
.ch0_out (ch0_out_5 ),
.ch1_out (ch1_out_5 )
);
conv_kernel_1x2 U6_conv_kernel_1x2_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch6_data_in ),
.ch0_weight (ch0_weight_6 ),
.ch1_weight (ch1_weight_6 ),
//
.ch0_out (ch0_out_6 ),
.ch1_out (ch1_out_6 )
);
conv_kernel_1x2 U7_conv_kernel_1x2_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data_in (ch7_data_in ),
.ch0_weight (ch0_weight_7 ),
.ch1_weight (ch1_weight_7 ),
//
.ch0_out (ch0_out_7 ),
.ch1_out (ch1_out_7 )
);
conv_kernel_2ch_add ch0_conv_kernel_2ch_add(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data0 (ch0_out_0 ),
.data1 (ch0_out_1 ),
.data2 (ch0_out_2 ),
.data3 (ch0_out_3 ),
.data4 (ch0_out_4 ),
.data5 (ch0_out_5 ),
.data6 (ch0_out_6 ),
.data7 (ch0_out_7 ),
.bias (ch0_bias ),
.bias_enable (bias_enable ),
//
.data_out (ch0_conv_out )
);
conv_kernel_2ch_add ch1_conv_kernel_2ch_add(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.data0 (ch1_out_0 ),
.data1 (ch1_out_1 ),
.data2 (ch1_out_2 ),
.data3 (ch1_out_3 ),
.data4 (ch1_out_4 ),
.data5 (ch1_out_5 ),
.data6 (ch1_out_6 ),
.data7 (ch1_out_7 ),
.bias (ch1_bias ),
.bias_enable (bias_enable ),
//
.data_out (ch1_conv_out )
);
conv_kernel_2ch_add
reg signed [23:0] temp0 ;
reg signed [23:0] temp1 ;
reg signed [23:0] temp2 ;
wire signed [31:0] bias_data ;
//=============================================================================
//************** Main Code **************
//=============================================================================
assign bias_data = (bias_enable == 1'b1) ? bias : 32'h0;
always @(posedge sclk or negedge s_rst_n) begin
if(s_rst_n == 1'b0) begin
temp0 <= 'd0;
temp1 <= 'd0;
temp2 <= 'd0;
data_out <= 'd0;
end
else begin
temp0 <= data0 + data1 + data2;
temp1 <= data3 + data4 + data5;
temp2 <= data6 + data7 + bias_data;
data_out <= temp0 + temp1 + temp2;
end
end
conv_kernel_8ch
conv_kernel_2ch U0_conv_kernel_2ch_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.ch0_data_in (ch0_data_in ),
.ch1_data_in (ch1_data_in ),
.ch2_data_in (ch2_data_in ),
.ch3_data_in (ch3_data_in ),
.ch4_data_in (ch4_data_in ),
.ch5_data_in (ch5_data_in ),
.ch6_data_in (ch6_data_in ),
.ch7_data_in (ch7_data_in ),
.ch0_weight_0 (ch0_weight_0 ),
.ch0_weight_1 (ch0_weight_1 ),
.ch0_weight_2 (ch0_weight_2 ),
.ch0_weight_3 (ch0_weight_3 ),
.ch0_weight_4 (ch0_weight_4 ),
.ch0_weight_5 (ch0_weight_5 ),
.ch0_weight_6 (ch0_weight_6 ),
.ch0_weight_7 (ch0_weight_7 ),
.ch1_weight_0 (ch1_weight_0 ),
.ch1_weight_1 (ch1_weight_1 ),
.ch1_weight_2 (ch1_weight_2 ),
.ch1_weight_3 (ch1_weight_3 ),
.ch1_weight_4 (ch1_weight_4 ),
.ch1_weight_5 (ch1_weight_5 ),
.ch1_weight_6 (ch1_weight_6 ),
.ch1_weight_7 (ch1_weight_7 ),
//
.ch0_bias (ch0_bias ),
.ch1_bias (ch1_bias ),
.bias_enable (bias_enable ),
//
.ch0_conv_out (ch0_conv_out ),
.ch1_conv_out (ch1_conv_out )
);
conv_kernel_2ch U1_conv_kernel_2ch_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.ch0_data_in (ch0_data_in ),
.ch1_data_in (ch1_data_in ),
.ch2_data_in (ch2_data_in ),
.ch3_data_in (ch3_data_in ),
.ch4_data_in (ch4_data_in ),
.ch5_data_in (ch5_data_in ),
.ch6_data_in (ch6_data_in ),
.ch7_data_in (ch7_data_in ),
.ch0_weight_0 (ch2_weight_0 ),
.ch0_weight_1 (ch2_weight_1 ),
.ch0_weight_2 (ch2_weight_2 ),
.ch0_weight_3 (ch2_weight_3 ),
.ch0_weight_4 (ch2_weight_4 ),
.ch0_weight_5 (ch2_weight_5 ),
.ch0_weight_6 (ch2_weight_6 ),
.ch0_weight_7 (ch2_weight_7 ),
.ch1_weight_0 (ch3_weight_0 ),
.ch1_weight_1 (ch3_weight_1 ),
.ch1_weight_2 (ch3_weight_2 ),
.ch1_weight_3 (ch3_weight_3 ),
.ch1_weight_4 (ch3_weight_4 ),
.ch1_weight_5 (ch3_weight_5 ),
.ch1_weight_6 (ch3_weight_6 ),
.ch1_weight_7 (ch3_weight_7 ),
//
.ch0_bias (ch2_bias ),
.ch1_bias (ch3_bias ),
.bias_enable (bias_enable ),
//
.ch0_conv_out (ch2_conv_out ),
.ch1_conv_out (ch3_conv_out )
);
conv_kernel_2ch U2_conv_kernel_2ch_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.ch0_data_in (ch0_data_in ),
.ch1_data_in (ch1_data_in ),
.ch2_data_in (ch2_data_in ),
.ch3_data_in (ch3_data_in ),
.ch4_data_in (ch4_data_in ),
.ch5_data_in (ch5_data_in ),
.ch6_data_in (ch6_data_in ),
.ch7_data_in (ch7_data_in ),
.ch0_weight_0 (ch4_weight_0 ),
.ch0_weight_1 (ch4_weight_1 ),
.ch0_weight_2 (ch4_weight_2 ),
.ch0_weight_3 (ch4_weight_3 ),
.ch0_weight_4 (ch4_weight_4 ),
.ch0_weight_5 (ch4_weight_5 ),
.ch0_weight_6 (ch4_weight_6 ),
.ch0_weight_7 (ch4_weight_7 ),
.ch1_weight_0 (ch5_weight_0 ),
.ch1_weight_1 (ch5_weight_1 ),
.ch1_weight_2 (ch5_weight_2 ),
.ch1_weight_3 (ch5_weight_3 ),
.ch1_weight_4 (ch5_weight_4 ),
.ch1_weight_5 (ch5_weight_5 ),
.ch1_weight_6 (ch5_weight_6 ),
.ch1_weight_7 (ch5_weight_7 ),
//
.ch0_bias (ch4_bias ),
.ch1_bias (ch5_bias ),
.bias_enable (bias_enable ),
//
.ch0_conv_out (ch4_conv_out ),
.ch1_conv_out (ch5_conv_out )
);
conv_kernel_2ch U3_conv_kernel_2ch_inst(
// system signals
.sclk (sclk ),
.s_rst_n (s_rst_n ),
//
.ch0_data_in (ch0_data_in ),
.ch1_data_in (ch1_data_in ),
.ch2_data_in (ch2_data_in ),
.ch3_data_in (ch3_data_in ),
.ch4_data_in (ch4_data_in ),
.ch5_data_in (ch5_data_in ),
.ch6_data_in (ch6_data_in ),
.ch7_data_in (ch7_data_in ),
.ch0_weight_0 (ch6_weight_0 ),
.ch0_weight_1 (ch6_weight_1 ),
.ch0_weight_2 (ch6_weight_2 ),
.ch0_weight_3 (ch6_weight_3 ),
.ch0_weight_4 (ch6_weight_4 ),
.ch0_weight_5 (ch6_weight_5 ),
.ch0_weight_6 (ch6_weight_6 ),
.ch0_weight_7 (ch6_weight_7 ),
.ch1_weight_0 (ch7_weight_0 ),
.ch1_weight_1 (ch7_weight_1 ),
.ch1_weight_2 (ch7_weight_2 ),
.ch1_weight_3 (ch7_weight_3 ),
.ch1_weight_4 (ch7_weight_4 ),
.ch1_weight_5 (ch7_weight_5 ),
.ch1_weight_6 (ch7_weight_6 ),
.ch1_weight_7 (ch7_weight_7 ),
//
.ch0_bias (ch6_bias ),
.ch1_bias (ch7_bias ),
.bias_enable (bias_enable ),
//
.ch0_conv_out (ch6_conv_out ),
.ch1_conv_out (ch7_conv_out )
);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号