

蓝图,g对象,数据库链接池
flask蓝图使用
blueprint 翻译后称之为蓝图。
作用是: 用来划分目录
之前写项目的时候全在一个py文件内写flask项目。 需要使用蓝图来划分目录。小型项目与大型目录都可以
蓝图使用
1 导入蓝图类 业务视图里
from flask import Blueprint
2 实例化得到蓝图对象 业务视图里
us = blueprint('user',__name__)
3.在app的__init__注册蓝图 包 __init__ 中实例化得到Flask对象
导入视图类的蓝图
from .views.user import user_bp
app.register_blueprint(user_bp)
4在不同的app里 使用蓝图注册路由 业务视图里
@us.route('/login')
def login():
pass
小型项目就按上述操作
目录
little_blueprint # 项目名
-src # 核心代码
-static # 静态文件
-1.jpg # 图片
-templates # 模板文件
-user.html # 模板
-views # 视图函数存放位置
-order.py # 订单相关视图
-user.py # 用户相关视图
-__init__.py # 包
-models.py # 表模型
-manage.py # 启动文件
补充:
5 多个app目录可以 在 蓝图设置前缀
app.register_blueprint(user_bp,url_prefix='/user')
6 多个app目录自己的template与static 不与别的app目录起冲突可以按下面这样设置
user_bp = Blueprint('user', __name__, template_folder='templates', static_folder='static')
大型项目需每个功能弄一个文件夹,在文件夹类有 static,templates,__init__,views,models ,其他一样操作。
目录
big_blueprint # 项目名
-src # 核心文件
-admin # admin的app
-static # 静态文件
-1.jpg # 图片
-templates # 模板文件目录
-admin_home.html # 模板文件
-__init__.py # 包
-models.py # 表模型
-views.py # 视图函数
-home # home app
-order # orderapp
-__init__.py # 包
-settings.py # 配置文件
-manage.py # 启动文件
g对象
为什么用单字母来命名:
g是global的缩写,global在python中是一个关键字,不能以关键字作为变量名。
在整个请求的全局,可以对它进行放值,也可以取值当次请求生效
与我们之前写的路飞商城项目 中的 context 功能一样。
g对象是全局的在任意位置导入就可使用
from flask import Flask, g
app = Flask(__name__)
app.debug = True
def add(a, b):
print(g.name) # 并没有传name过来,可以发现g是全局的
return a + b
@app.route('/')
def home():
g.name = 'zhangsan' # 也可以从request中获取name g.name = request.args.get('name')
res = add(1, 2)
print(res)
return 'Hello World!'
if __name__ == '__main__':
app.run()
数据库的连接池
flask操作mysql 也是使用pymysql
from flask import Flask,jsonify
import pymysql
app = Flask(__name__)
app.debug = True
@app.route('/article')
def article():
# 从mysql中的article表中获取数据
# 1.连接数据库
conn = pymysql.connect(user='root',
password="",
host='127.0.0.1',
database='cnblogs',
port=3306, )
# 2.创建游标
cursor = conn.cursor() #设置游标的类型为字典类型 cursor = conn.cursor(pymysql.cursors.DictCursor)
# 3.执行sql语句
cursor.execute('select id,title from article limit 2')
# 4.获取数据
res = cursor.fetchall()
#关闭链接
cursor.close()
conn.close()
print(res) # 数据是元组套元组的形式
return jsonify(res) # 将数据转换成json格式的数据返给前端
if __name__ == '__main__':
app.run()
"""
有问题
一个请求就会创建一个链接,请求结束,链接关闭。
在全局设置链接会有问题,用的都是一个请求。
如果用并发操作查询数据,2个请求都查询了,但都没取,过一会取了会出现数据错乱
"""
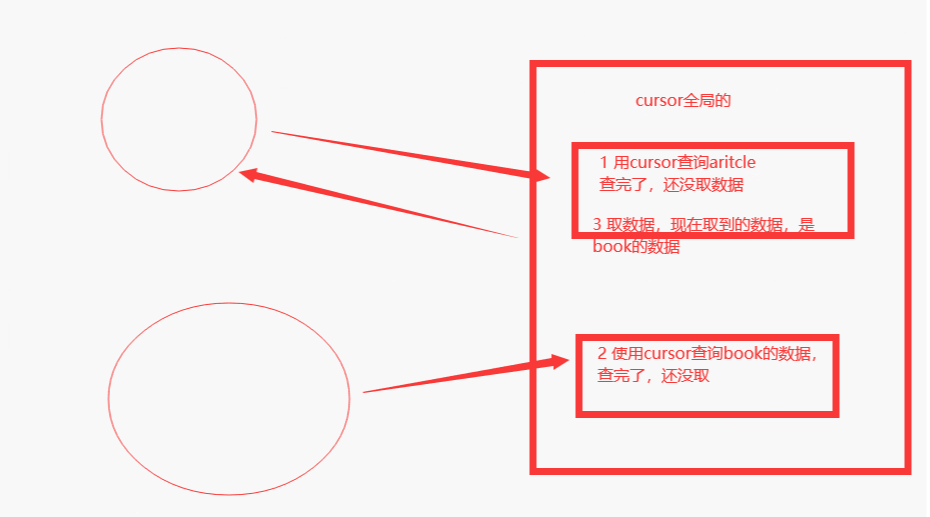
解决上述两个问题
使用数据库的链接池
每次进入视图从池里取一个链接使用,使用完放回去。控制池的大小就能控制mysql的链接数
需要借助于第三方模块
pip install dbutils
使用
实例化得到池对象
from dbutils.pooled_db import PooledDB
import pymysql
POOL= PooledDB(
creator=pymysql, #使用链接数据库的模块
maxconnections=6, #连接池允许的最大连接数,0和None表示没有限制
mincached=2, #初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=5, #链接池中最多闲置的链接,0和None不限制
maxshared=3,
#链接池中最多共享的链接数量,0和None表示全部共享。PS:无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking=True, #达到最大数量时是否阻塞等待,True表示等待,False表示不等待然后报错
maxusage=None, #一个链接最多被重复使用的次数,None表示无限制
setsession=[], #开始会话前执行的命令列表。
ping=0, #ping MySQL服务端,检查是否服务可用。
host='',
user='',
password='',
database='',
port=3306,
charset='utf8',
)
在视图中使用池
from flask import Flask,jsonify
import pymysql
from POOL import pool
app = Flask(__name__)
app.debug = True
@app.route('/article')
def article():
# 从池中获取一个连接
conn= pool.connection()
# 产生游标
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 执行sql
cursor.execute('select * from article')
# 获取数据
res = cursor.fetchall()
#关闭链接
cursor.close()
conn.close()
print(res) # 数据是元组套元组的形式
return jsonify(res) # 将数据转换成json格式的数据返给前端
if __name__ == '__main__':
app.run()
数据库查询链接数量命令
show status like 'Threads%'
压力测试代码
from threading import Thread
import requests
def task():
res = requests.get('http://127.0.0.1:5000/article_pool')
print(len(res.text))
if __name__ == '__main__':
for i in range(500):
t = Thread(target=task)
t.start()
实测效果:
使用池的连接数明显小
不使用池连接数明显很大


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现