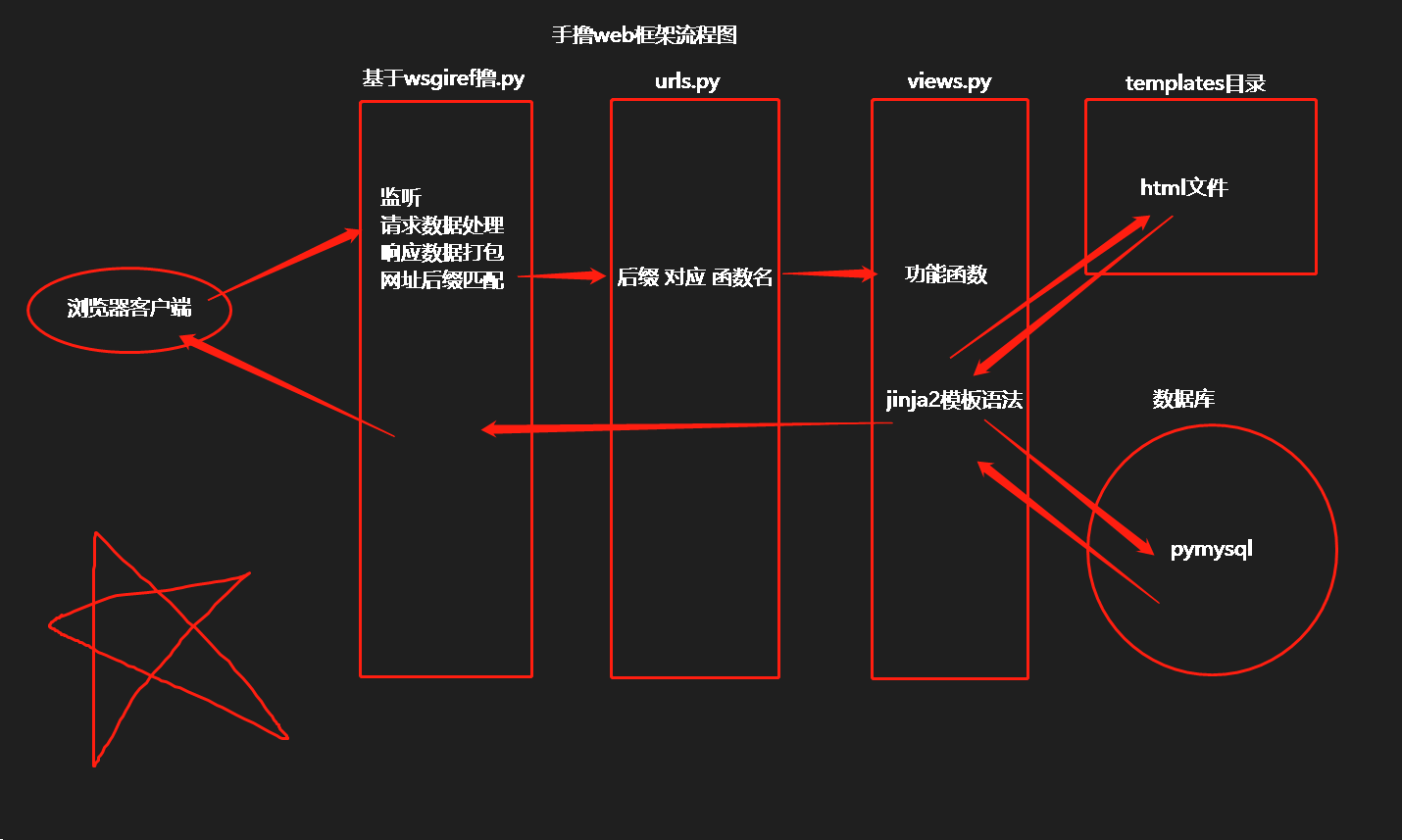
web框架 wsgiref模块优化 jinja2模块 前后端数据库联动
手写web框架
1.web框架的本质
连接前端与数据库的中间介质 就是服务端
socket服务端
2.手写的web框架
编写socket服务端代码
浏览器访问响应无效>>>: 因为数据格式不一样, HTTP协议(规定了浏览器与服务端之间数据交互的格式)
根据网址的路由不同获取不同的页面内容
获取到用户输入的路由>>>: 查看请求数据内 找到规则获取路由
"请求首行 GET /login HTTP/1.1 找到规则 处理请求数据获取网址路由"
import socket
server = socket.socket()
server.bind(('127.0.0.1',14334))
server.listen(5)
while True:
sock , address = server.accept() # 等待连接
date = sock.recv(1024) # 接收信息
sock.send(b'HTTP/1.1 200 ok\r\n\r\n')
date_str = date.decode('utf8') # 请求头 decode解码 获取字符串
target_url = date_str.split(' ')[1] # 切割获取 路由
if target_url =='/index':
with open(r'index.html','rb')as f: # 可以发送一个页面过去
sock.send(f.read())
elif target_url == '/login':
sock.send(b'hellow login')
else:
sock.send(b'hellow baby')
问题:
"""
1.sock的代码 重复太多
2. 针对请求数据的处理过于繁琐
3. 路由匹配逻辑过于 低端
"""
基于wsgiref模块
wsgiref是自带的内置模块, 很多web框架底层都使用到的模块。
功能: 1.封装了socket代码 2.处理了请求数据
from wsgiref.simple_server import make_server
def run(request,response):
"""
:param request: 请求相关数据
:param response: 响应相关数据
:return: 返回给客户端的真实数据
"""
response('200 ok', []) # 固定格式
# print(request) # (字典形式的数据)
path_info = request.get('PATH_INFO')
if path_info =='/index':
return [b'hello index']
elif path_info =='/admin':
return [b'hello admin']
return [b'hello baby!']
if __name__ == '__main__':
server = make_server('127.0.0.1',8080,run) # 实施监听127.0,0,1:8080的请求,一旦有请求自动给run加括号并调用
server.serve_forever() # 启动服务器
优点:
1.固定的代码启动服务端
2.查看处理之后的request 发现是 以 大字典的形式的数据
3.研究大字典键值对找到 含有路由的键值对>>> get 方法获取路由
4. 发现 还是要进行if判断 思考解决方法

优化后代码
-
解决 路由获取后的 判断问题
-
思考路由匹配成功后 执行代码可能会很多也可能会很少
2.1 将if分支的代码封装成多个函数 (views.py) 2.2 建立函数与路由之间的对应关系 (urls.py)
2.3 获取路由后进行循环匹配 自动执行该路由对应函数
2.4 后续 新增功能只需要添加函数再进行添加对应关系
-
为了使函数体代码中业务逻辑有更多的数据可用
3.1 把request 大字典当做实参 传给函数
"""根据不同的功能拆分成不同的py文件
views.py 存储核心业务逻辑(功能函数)
urls.py 存储网址后缀与函数名对应关系
templates目录 存储html页面文件"""
views.py
def index(request):
with open(r'templates/index.html', 'r',encoding='utf8') as f:
return f.read()
"html文件存放与 templates目录"
def login(request):
return 'hello login'
def error(request):
return '404'
urls.py
from views import *
urls = [
('/index',index),
('/login',login)
]
启动文件
from wsgiref.simple_server import make_server
from urls import urls
from views import *
def run(request,response):
"""
:param request: 请求相关数据
:param response: 响应相关数据
:return: 返回给客户端的真实数据
"""
response('200 ok', []) # 固定格式
path_info = request.get('PATH_INFO')
func_name= None # 定义一个用于存储函数名的变量
for url_type in urls:
if path_info == url_type[0]:
func_name = url_type[1]
break # 匹配到了就不用接着匹配了
if func_name: # 判断如果有值+()调用
res = func_name(request) # 接收函数的返回值
else:
res = error(request)
return [res.encode('utf8')]
if __name__ == '__main__':
server = make_server('127.0.0.1',8080,run) # 实施监听127.0,0,1:8080的请求,一旦有请求自动给run加括号并调用
server.serve_forever() # 启动服务器
动静态网页
1.动态网页
页面数据来源于后端
def get_time(request):
import time
ctime = time.strftime('%Y-%m-%d %X') # 过去当前时间
with open(r'templates/gettime.html','r',encoding='utf8') as f:
date= f.read() # 获取html 里的数据 字符串格式
res = date.replace('asd',ctime) # 利用替 换把我们提前设置好需要放时间的地方的字符串替换成时间
return res
urls = [
('/index',index),
('/login',login),
('/home',get_time)
]
启动文件还是上面优化后的就不展示了
- 如果想要把字典 传给 页面 并可以通过字典的操作方式获取字典内的数据,必须要使用模板语法>>>:jinja2 模块
2.静态网页
页面数据直接在html里写死
jinja2模块
- 将字典数据传输到页面并还可以用后端的操作获取到字典的数据进行展示
def get_dict(request):
user_dict = {'name':'李阿鸡','age':28,'hobby':'花姑娘'}
with open(r'templates/get_dict.html' ,'r',encoding='utf8') as f:
data=f.read()
temp_obj = Template(data) # 把页面数据交给jinjia2模板处理
res=temp_obj.render({'d1':user_dict}) # 给页面传一个变量名是d1的字典
return res
页面内数据:
<p>数据展示</p>
<p>{{d1}}</p>
<p>{{d1.name}}</p>
<p>{{d1['age']}}</p>
<p>{{d1.get('hobby')}}</p>
前端,后端,数据库
前端浏览器访问/table 后端连接数据库查询userinfo表中所有的数据 传递到get_table页面 设置好标签样式 再发送给浏览器展示
前端
<div class="container">
<div class="row">
<h1 class="text-center">数据展示</h1>
<div class="col-md-8 col-md-offset-2">
<table class="table table-hover table-striped">
<thead>
<tr>
<th>ID</th>
<th>Name</th>
<th>Age</th>
</tr>
</thead>
<tbody>
{%for user_dict in user_list %} 、
<tr>
<td>{{user_dict.id}}</td>
<td>{{user_dict.name}}</td>
<td>{{user_dict.age}}</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
</div>
</div>
后端
from jinja2 import Template
import pymysql
def get_table(request):
conn=pymysql.connect(
user='root',
password='321',
host='127.0.0.1',
port=3306,
database='djiango01',
charset='utf8',
autocommit=True
)
curses = conn.cursor(cursor=pymysql.cursors.DictCursor) # 以字典形式传
sql = 'select * from userinfo;' # 编写sql语句
curses.execute(sql) # 发送语句
user_data = curses.fetchall() # 接收查询后所有数据[{},{}]
print(user_data)
with open(r'templates/get_table.html','r',encoding='utf8') as f:
data= f.read()
temp_obj= Template(data) # 把页面数据交给jinjia2模板处理
res = temp_obj.render({'user_list':user_data}) # 给页面传一个变量名是user_list的字典
return res
关系层:
from views import *
urls = [
('/index',index),
('/login',login),
('/home',get_time),
('/dict',get_dict),
('/table',get_table)
]
数据库
创建一个库,接着创建一个userinfo表存储用户数据,录入用户数据,先把数据准备好
create database day01;
create table userinfo(id int primary key auto_increment,name varchar(32),age int);
insert into userinfo(name,age) values('李阿鸡',18),('jason',27),('牛小妹',16),('tank',22);
===============================
+----+-----------+------+
| id | name | age |
+----+-----------+------+
| 1 | 李阿鸡 | 18 |
| 2 | jason | 27 |
| 3 | 牛小妹 | 16 |
| 4 | tank | 22 |
+----+-----------+------+
===============================
delete from userinfo where id=2;