《机器学习》第一次作业——第一至三章学习记录和心得
机器学习学习笔记与心得记录
第一章 模式识别基本概念
1.1 什么是模式识别
- 应用
- 计算机视觉领域(字体识别,交通标识识别,动作识别...)
- 人机交互(语音识别)
- 医学领域
- 网络领域
- 金融领域
- ...
-
基本定义:
-
分类与回归:
- 分类:输出量是离散的类别表达,即输出待识别模式所属的类别
- 输出量是连续的信号表达(回归值)
- 回归是分类的基础:离散的类别值是由回归值做判别决策得到的。
-
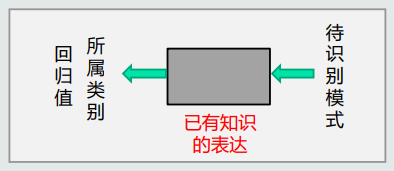
模式识别:
- 根据已有知识的表达,针对待识别模式,判别决策其 所属的类别或者预测其对应的回归值。
- 本质上是一中推理过程。
-
1.2 模式识别的数学表达
-
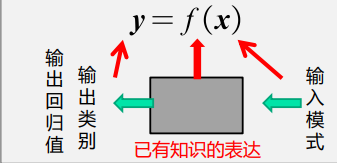
数学解释:模式识别可以看做一种函数映射f(x),将待识别模式x从输入空间映射到输出空间。函数f(x)是关于已有知识的表达。
- 函数f (x)的形式:可解析表达的、难以解析表达的
- 函数f (x)的输出:确定值、概率值。
-
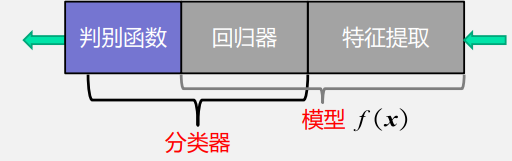
模型:
- 关于已有知识的一种表达 y = f(x);
- (回归模型)组成:
-
- 特征提取(feature extraction):从原始输入数据提取更有效的信息。
- 回归器(regressor):将特征映射到回归值。传统意义上的模型)

- (分类模型)组成:
- 模型(广义):特征提取+回归器+判别函数。
- 模型(狭义):特征提取+回归器
- 分类器(classifier):回归器+判别函数。
-
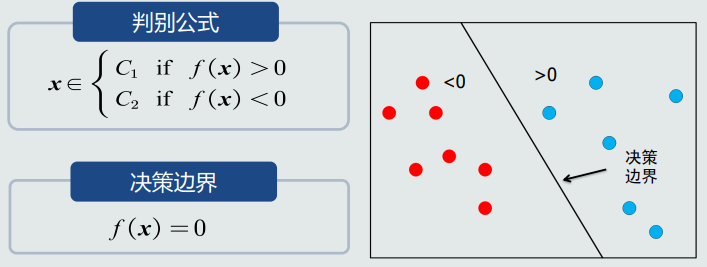
判别函数(决策边界)
- 二类分类: 使用sign函数:判断回归值大于0还是小于0。
- 多类分类:使用max函数:取最大的回归值所在维度对应的类别。
- 由于判别函数通常固定已知,所以不把它当做模型的一部分。
- 决策边界:
-
特征:
- 可以用于区分不同类别模式的、可测量的量。
- 特征向量: 多个特征构成的向量。
- 长度、方向等
- 特征空间:
- 每个坐标轴代表一维特征
- 空间中的每个点代表一个模式(样本)
- 从坐标原点到任意一点(模式)之间的向量即为该模式的特征 向量。
1.3 特征向量相关性
- 线性代数相关知识:
- 点积
- 投影(向量x分解到向量y方向上的程度。能够分解的越多,说明两个向量方向上越相似。)
- 残差向量
- 向量间的欧氏距离
1.4 机器学习基本概念
-
如何得到模型? -- 机器学习技术
-
训练样本
- iid : 独立同分布
- 覆盖所有可能空间
-
模型参数和结构:
-

-
线性模型:模型结构是线性的(直线、面、超平面)
-
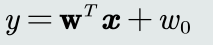
-
其中,𝐰, 𝑤0就是模型参数。
- 非线性模型:模型结构是非线性的(曲线、曲面、超曲面)
- 适用于线性不可分/线性不可表达的数据:
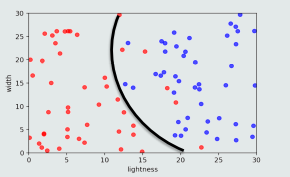
-
-
样本量 && 模型参数量
-
训练样本个数=模型参数个数(𝑁 = 𝑀):参数有唯一的解。
-
𝑁 ≫ 𝑀 ,Over-determined:没有准确的解。
-
需要额外添加一个标准,通过优化该标准 来确定一个近似解。该标准就叫目标函数,也称作代价函数或损失函数。
-
目标函数以待学习的模型参数作为自变量、以训练样本作为给定量
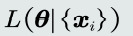
-
𝑁 ≪ 𝑀 , Under-determined :无数个解/无解。
-
需要在目标函数中加入能够体现对于参 数解的约束条件,据此从无数个解中选出最优的一个解。
-
优化算法:
-
机器学习流程示意图
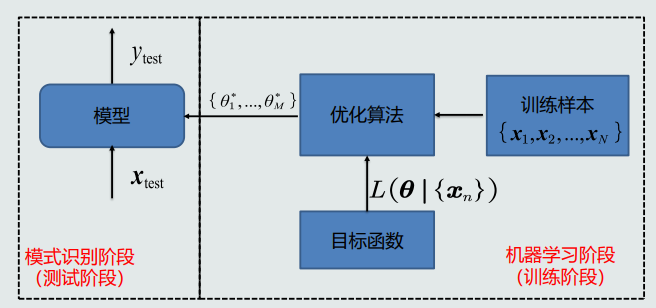
- 机器学习方式
-
监督学习:训练样本及其输出真值都给定情况下的机器学习算法
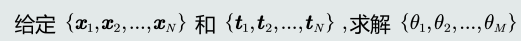
-
监督式学习是机器学习中最常见的学习方式。
-
通常使用最小化训练误差作为目标函数进行优化。
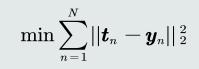
-
-
无监督学习:只给定训练样本、没有给输出真值情况下的机器学习算法。
- 根据训练样本之间的相似程度来进行决策
- 应用:
- 聚类
- 图像分割
-
半监督学习:有标注的训练样本、又有未标注的训练样本情况下的 学习算法。
-
强化学习
- 机器自行探索决策、真值滞后反馈的过程。
- 定义从输入状态到动作决策为一个策略(policy)
- 使用该策略进行决策探索时,给予每次决策一个奖励(reward)
- 累积多次奖励获得回报值(return)
- 回报的期望值作为该策略的价值函数(value function)
- 通过最大化回报的期望值,解出策略的参数。
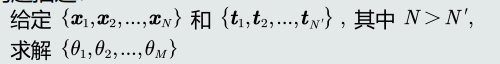
1.5 模型的泛化能力
-
训练集/ 测试集
- 测试集和训练集是互斥的,但假设是同分布的。
-
训练误差/测试误差
- 测试误差(test error):模型在测试集上的误差。它反映了模型 的泛化能力,也称作泛化误差。
- 训练误差(training error):模型在训练集上的误差。
-
泛化能力:
-
问题: 噪声、不均匀、样本稀疏
-
训练得到的模型不仅要对训练样本具有决策能力, 也要对新的(训练过程中未看见)的模式具有决策能力。
-
过拟合: 模型训练阶段表现很好,但是在测试阶段表现很差。 模型过于拟合训练数据。
-
提高泛化能力:
- 不要过度训练。(正则化、模型选择、调节超参数)
1.6 评估方法与性能度量指标
-
评估方法
-
留出法
-
随机划分:随机分为训练集和测试集。训练集训练模型,测试集评估模型的量化指标。
-
取统计值:为了克服单次随机划分带来的偏差。
-
-
K折交叉验证
-
将数据集分割成K个子集,从其中选取单个子集作为测试集,其他K - 1个子集作为训练集。
-
交叉验证重复K次,使得每个子集都被测试-次;将K次的评估值取平均,作为最终的量化评估结果。
-
K折交叉验证代码
def k_split(data,iris_type,num): import random testSet = [] testType = [] first_cur = [] second_cur = [] third_cur = [] for i in range(len(iris_type)): if iris_type[i] == 0: first_cur.append(i) elif iris_type[i] == 1: second_cur.append(i) else: third_cur.append(i) match_size = int(len(first_cur)/num) size = len(first_cur)-1 train_data = [] train_type = [] for i in range(num): k = match_size train_data = [] train_type = [] for j in range(match_size): cur = random.randint(0, size) train_data.append(data[first_cur[cur]]) train_type.append(iris_type[first_cur[cur]]) first_cur.remove(first_cur[cur]) cur = random.randint(0, size) train_data.append(data[second_cur[cur]]) train_type.append(iris_type[second_cur[cur]]) second_cur.remove(second_cur[cur]) cur = random.randint(0, size) train_data.append(data[third_cur[cur]]) train_type.append(iris_type[third_cur[cur]]) third_cur.remove(third_cur[cur]) size = size-1 testSet.append(train_data) testType.append(train_type) return np.asarray(testSet),np.asarray(testType)
-
-
留一验证
- 每次只取数据集中的一个样本做测试集,剩余的做训练集。
-
-
性能度量指标
-
准确度:将阳性和阴性综合起来度量识别正确的程度。

- 如果阳性和阴性样本数量比例失衡,该指标很难度量识别性能。
- 例子:阳性/阴性=5/95,模型把所有样本都判断为阴性。
-
精度
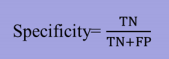
-
召回率
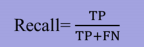
-
F-Scor: 加权平均,综合precision和recall:
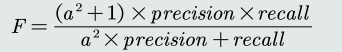
-
混淆矩阵:矩阵的列代表预测值,行代表真值。
- 对角线元素的值越大,表示模型性 能越好。
-
PR曲线
- 横轴:召回率(recall)
- 纵轴:精度(precision) 理想性能:右上角(1,1)处。
- PR曲线越往右上凸,说明模型 的性能越好
-
ROC曲线
- 横轴:False positive rate (FPR)
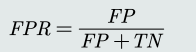
- 纵轴:True positive rate (TPR),即recall。度量所有阳性样本 被识别为阳性的比例。
- 横轴:False positive rate (FPR)
-
AUC
-
第二章 基于距离的分类器
2.1 MED分类器
-
基于距离分类:把测试样本到每个类之间 的距离作为决策模型,将测试样 本判定为与其距离最近的类。
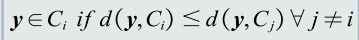
-
类的原型: 用来代表这个类的一个模式或者 一组量,便于计算该类和测试样 本之间的距离。
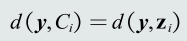
- 均值
- 最近邻
-
常见的几种距离度量
- 欧氏距离
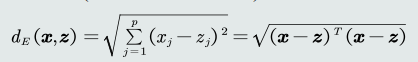
- 曼哈顿距离
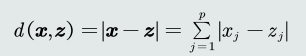
- 加权欧式距离
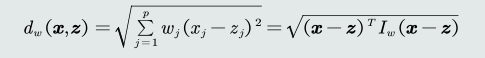
- 欧氏距离
-
MED分类器
-
最小欧式距离分类器(Minimum Euclidean Distance Classifier)
-
距离衡量:欧式距离
-
类的原型:均值
-
决策边界:
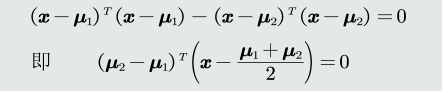
-
问题: MED分类器采用欧氏距离作为距离度量,没有考虑 特征变化的不同及特征之间的相关性。
-
解决方法:去除特征变化的不同及特征之间的相关性。
-
代码实现
def MED_classification(data,iris_type,t,f,flag): data_linear,iris_type_linear=getIrisLinear(data,iris_type,flag) train_data,train_type,test_data,test_type = hold_out_way(data_linear,iris_type_linear) c1 = [] c2 = [] n1=0 n2=0 for i in range(len(train_data)): #均值 if train_type[i] == 1: n1+=1 c1.append(train_data[i]) else: n2+=1 c2.append(train_data[i]) c1 = np.asarray(c1) c2 = np.asarray(c2) z1 = c1.sum(axis=0)/n1 z2 = c2.sum(axis=0)/n2 test_result = [] for i in range(len(test_data)): result = np.dot(z2-z1,test_data[i]-(z1+z2)/2) test_result.append(np.sign(result)) test_result = np.array(test_result) TP = 0 FN = 0 TN = 0 FP = 0 for i in range(len(test_result)): if(test_result[i]>=0 and test_type[i]==t): TP+=1 elif(test_result[i]>=0 and test_type[i]==f): FN+=1 elif(test_result[i]<0 and test_type[i]==t): FP+=1 elif(test_result[i]<0 and test_type[i]==f): TN+=1 Recall = TP/(TP+FN) Precision = TP/(TP+FP) print("Recall= %f"% Recall) print("Specify= %f"% (TN/(TN+FP))) print("Precision= %f"% Precision) print("F1 Score= %f"% (2*Recall*Precision/(Recall+Precision))) #绘图 xx = [[0, 1, 2], [1, 2, 3], [0, 2, 3], [0, 1, 3]] iris_name =['setosa','vesicolor','virginica'] iris_color = ['r','g','b'] iris_icon = ['o','x','^'] fig = plt.figure(figsize=(20, 20)) feature = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] for i in range(4): ax = fig.add_subplot(221 + i, projection="3d") X = np.arange(test_data.min(axis=0)[xx[i][0]],test_data.max(axis=0)[xx[i][0]],1) Y = np.arange(test_data.min(axis=0)[xx[i][1]],test_data.max(axis=0)[xx[i][1]],1) X,Y = np.meshgrid(X,Y) m1 = [z1[xx[i][0]],z1[xx[i][1]],z1[xx[i][2]]] m2 = [z2[xx[i][0]], z2[xx[i][1]], z2[xx[i][2]]] m1 = np.array(m1) m2 = np.array(m2) m = m2-m1 #将公式进行化简 Z = (np.dot(m,(m1+m2)/2)-m[0]*X-m[1]*Y)/m[2] ax.scatter(test_data[test_result >= 0, xx[i][0]], test_data[test_result>=0, xx[i][1]], test_data[test_result >= 0, xx[i][2]], c=iris_color[t], marker=iris_icon[t], label=iris_name[t]) ax.scatter(test_data[test_result < 0, xx[i][0]], test_data[test_result < 0, xx[i][1]], test_data[test_result < 0, xx[i][2]], c=iris_color[f], marker=iris_icon[f], label=iris_name[f]) ax.set_zlabel(feature[xx[i][2]]) ax.set_xlabel(feature[xx[i][0]]) ax.set_ylabel(feature[xx[i][1]]) ax.plot_surface(X,Y,Z,alpha=0.4) plt.legend(loc=0) plt.show()
-
2.2 特征白化
-
目的:将原始特征映射到一个新的特征空间,使得在新空间 中特征的协方差矩阵为单位矩阵,从而去除特征变化 的不同及特征之间的相关性。
-
目标:
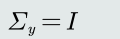
-
将特征转换分为两步:
-
解耦: 通过W1实现协方差矩阵对角化,去除特征之间的相关性。


-
白化: 通过W2对上一步变换后的特征再进行尺度变换,实现所有特征具有相同方差。
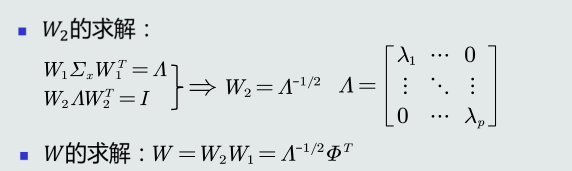

-
-
代码实现
def to_whiten(data): Ex = np.cov(data,rowvar=False)#这个一定要加……因为我们计算的是特征的协方差 a,w1 = np.linalg.eig(Ex) w1 = np.real(w1) module = [] for i in range(w1.shape[1]): sum = 0 for j in range(w1.shape[0]): sum += w1[i][j]**2 module.append(sum**0.5) module = np.asarray(module,dtype="float64") w1 = w1/module a = np.real(a) a=a**(-0.5) w2 = np.diag(a) w = np.dot(w2,w1.transpose()) for i in range(w.shape[0]): for j in range(w.shape[1]): if np.isnan(w[i][j]): w[i][j]=0 #print(w) return np.dot(data,w) def show_whiten(data,iris_type): whiten_array = to_whiten(data) show_out_3D(whiten_array,iris_type) def show_out_3D(data,iris_type): xx = [[0, 1, 2], [1, 2, 3], [0, 2, 3], [0, 1, 3]] fig = plt.figure(figsize=(20, 20)) feature = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] for i in range(4): ax = fig.add_subplot(221 + i, projection="3d") ax.scatter(data[iris_type == 0, xx[i][0]], data[iris_type == 0, xx[i][1]], data[iris_type == 0, xx[i][2]], c='r', marker='o', label='setosa') ax.scatter(data[iris_type == 1, xx[i][0]], data[iris_type == 1, xx[i][1]], data[iris_type == 1, xx[i][2]], c='g', marker='x', label='vesicolor') ax.scatter(data[iris_type == 2, xx[i][0]], data[iris_type == 2, xx[i][1]], data[iris_type == 2, xx[i][2]], c='b', marker='^', label='virginica') yy = [feature[xx[i][2]],feature[xx[i][0]],feature[xx[i][1]]] ax.set_zlabel(yy[0]) ax.set_xlabel(yy[1]) ax.set_ylabel(yy[2]) plt.legend(loc=0) plt.show()
2.3 MCID分类器
1. 最小类内距离分类器(Minimum Intra-class Distance Classifier),基于马氏距离的分类器。
* 距离度量:马氏距离
* 类的原型:均值
* 判别公式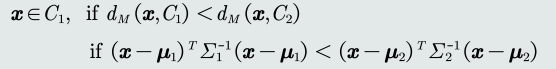
-
马氏距离属性:
1. -
对角矩阵时: 超椭圆面
-
任意值:有方向的超椭圆面
-
MCID决策边界
-
-
-

-
-
-
问题: MICD分类器的缺陷是 会选择方差较大的类
-
复现MCID分类器源码
import numpy as np from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split # distance传入'mahalanobis'代表马氏距离,其他代表欧式距离 class MED(object): def __init__(self, distance='mahalanobis', prototype='mean'): # 实际上可以自己实现不同的distance和prototype函数以实现不同的分类器,目前就实现了一两种,所以这里的赋值作了简化 # 设置距离度量 if distance == 'mahalanobis': self.__distance = self.__distance_mahalanobis else: self.__distance = self.__distance_euclidean # 设置类的原型 if True: self.__prototype = self.__prototype_mean # 是否训练完成 self.__has_fit = False # 存储类的标签 self.__tag = None # 训练集 self.__train_data = [] # 协方差矩阵的逆矩阵 self.__cov_inv = [] # 类的中心 self.__center = [] # 马氏距离 # X_train是 n*m 的矩阵,代表n个元素,m个特征, index代表第几类 def __distance_mahalanobis(self, X, index): return np.dot(np.dot((X - self.__center[index]).T, self.__cov_inv[index]), X - self.__center[index]) # 欧式距离 # X_train是 n*m 的矩阵,代表n个元素,m个特征, index代表第几类 def __distance_euclidean(self, X, index): return np.dot((X - self.__center[index]).T, X - self.__center[index]) # 均值 def __prototype_mean(self, X): return np.mean(X, axis=0) # 训练, X_train是 n*m 的矩阵,代表n个元素,m个特征,Y_train为1维列向量,代表标签 def fit(self, X_train, Y_train): self.__tag = np.unique(Y_train) for i in range(len(self.__tag)): # 划分当前数据 cur_data = X_train[np.where(Y_train == self.__tag[i])] self.__train_data.append(cur_data) # 计算中心 cur_center = self.__prototype(self.__train_data[i]) self.__center.append(cur_center) # 如果距离度量为马氏距离,计算协方差矩阵 if self.__distance == self.__distance_mahalanobis: cur_cov = np.linalg.pinv(np.cov(self.__train_data[i].T)) self.__cov_inv.append(cur_cov) self.__has_fit = True # 预测单个数据 x为n维列向量 def predict(self, x): if not self.__has_fit: print("模型还未训练") return dis = [self.__distance(x, i) for i in range(len(self.__tag))] return self.__tag[np.argmin(dis)] # 评估一组数据 X_test是 n*m 的矩阵,代表n个元素,m个特征,Y_test为1维列向量,代表标签 def score(self, X_test, Y_test): if not self.__has_fit: print("模型还未训练") return if X_test.shape[0] == 0 or X_test.shape[0] != Y_test.shape[0]: print("参数不正确") return # pass correct = 0 total = X_test.shape[0] for i in range(X_test.shape[0]): cur_tag = self.predict(X_test[i]) if cur_tag == Y_test[i]: correct += 1 # print(cur_tag) return correct / total # 使用乳腺癌数据集进行测试 def main(): cancer = load_breast_cancer() X = cancer.data Y = cancer.target X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=100) # 欧式距离 euclidean; 马氏距离 mahalanobis med = MED(distance="mahalanobis") med.fit(X_train, Y_train) print(med.score(X_train, Y_train)) print(med.score(X_test, Y_test)) main()
第三章 贝叶斯决策与学习
3.1 贝叶斯决策与MAP分类器
- 先验概率和后验概率
- 先验概率:根据以往的经验和分析得到的概率,不依靠观测数据。
- 表示方式有:
- 常数表达:例如,𝑝 𝐶𝑖 = 0.2
- 参数化解析表达:高斯分布……
- 非参数化表达:直方图、核密度、蒙特卡洛…
- 表示方式有:
- 后验概率:
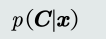
- 先验概率:根据以往的经验和分析得到的概率,不依靠观测数据。
- 如何决策呢?找找到后验概率最大的那个类。
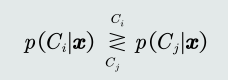
- 贝叶斯规则
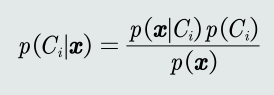
- MAP分类器
- 最大后验概率(Maximum posterior probability,MAP)分类器:将测试样本 决策分类给后验概率最大的那个类。
- 判别公式
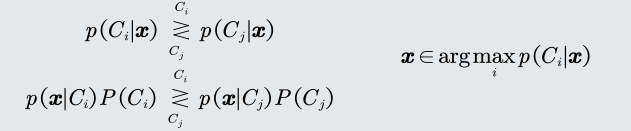
- 决策边界
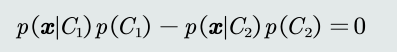
- 决策目标:最小化概率误差,即分类误差最小化。
- MAP分类器决策误差
- 给定一个测试样本𝑥,概率误差等于未选择的类所对应的后验概率。
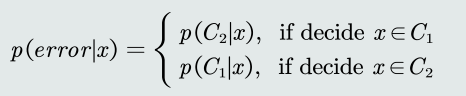
- 给定所有测试样本(𝑁为样本个数),分类决策产生的平均概率误差为: 样本的概率误差的均值
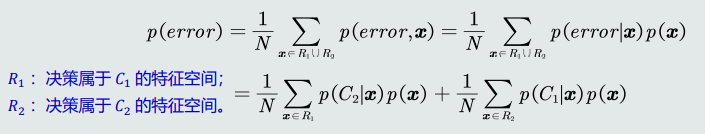
- 给定一个测试样本𝑥,概率误差等于未选择的类所对应的后验概率。
3.2 MAP分类器:高斯观测概率
-
观测概率:单维高斯分布
-
高斯分布
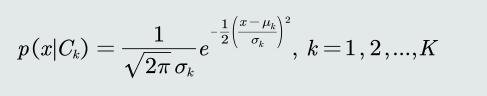
-
将高斯分布函数带入MAP分类器的判别公式,得到决策边界:
-
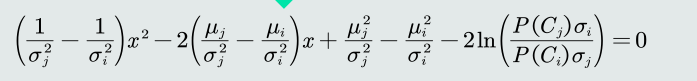
-

-
为了方便和MED分类器比较,决策边界可以写为
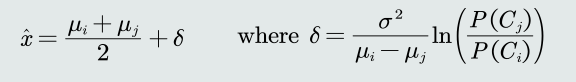
-
-
分类器倾向选择𝐶𝑗类,即 方差较小(紧致)的类。MAP分类器可以解决MICD分类器存在的问题
-
比较MAP和MICD、MED分类器:
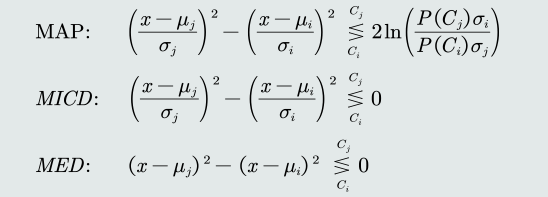
-
-
观测概率:高维高斯分布
- 判别函数:
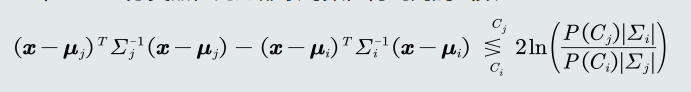
- 判别函数:
3.3 决策风险与贝叶斯分类器
- 决策风险: 贝叶斯决策不能排除出现错误判断的情况,由此会带来决策风险。 更重要的是,不同的错误决策会产生程度完全不一样的风险。
- 给定一个测试样本𝒙 ,分类器决策其属于𝐶𝑖类的动作α𝑖对应的 决策风险可以定义为相对于所有候选类别的期望损失
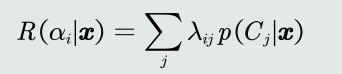
-
损失:
-
要定义一个惩罚量,用来表征当前决策动作相 对于其他候选类别的风险程度,即损失(loss)
-
假设该测试样本𝒙 的真值是属于𝐶𝑗类,决策动作𝛼𝑖对应的 损失可以表达为:𝜆(𝛼𝑖 |𝐶𝑗),简写为𝜆𝑖𝑗。
-
-
贝叶斯分类器:在MAP分类器基础上,加入决策风险因素,贝叶斯分类器选择决策风险最小的类(决策目标)。
- 判别公式:

- 贝叶斯分类器决策损失有多大?
- 给定单个测试样本,贝叶斯决策损失就是决策风险𝑅(𝛼𝑖 |𝒙)。
- 给定所有测试样本(N为样本个数),贝叶斯决策的期望损失: 所有样本的决策损失之和。
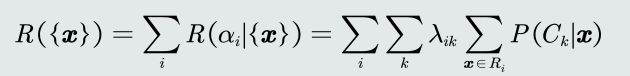
- 如何实现期望损失最小化?对每个测试样本选择风险最小的类。
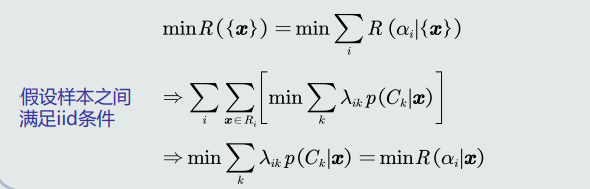
- 判别公式:
-
朴素贝叶斯分类器: 特征之间是相互独立的
-
在决策边界附近怎么处理?
- 拒绝选项(引入阈值τ :)
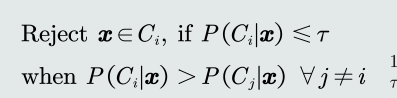
- 当τ = 1,所有样本的任何决策 都会被拒绝。
- 当τ < 1/𝐾,所有样本的决策都 不会被拒绝,K是类别的个数。
- 拒绝选项(引入阈值τ :)
3.4 最大似然估计
-
引言: 在贝叶斯决策中,求取后验概率需要事先知道每个类的先验概率和观测似然概率。 这两类概率分布需要通过机器学习算法得到
-
监督式学习方法
- 如果给定标签的训练样本,采用监督式学习。
- 监督式学习方法有以下两种:
- 参数化方法:给定概率分布的解析表达,学习这些解析表 达函数中的参数。该类方法也称为参数估计。
- 常用的参数估计方法
- 最大似然估计(Maximum Likelihood Estimation)
- 贝叶斯估计(Bayesian Estimation)
- 常用的参数估计方法
- 非参数化方法:概率密度函数形式未知,基于概率密度估 计技术,估计非参数化的概率密度表达
- 参数化方法:给定概率分布的解析表达,学习这些解析表 达函数中的参数。该类方法也称为参数估计。
-
最大似然估计
-
先验概率估计

-
目标函数:给定所有类的𝑁个训练样本,假设随机抽取其中一个样本属于𝐶1类 的概率为𝑃,则选取到𝑁1个属于𝐶1类样本的概率为先验概率的似然函数(即目标函数)。

-
为了最大化似然函数,求其关于参数𝑃的偏导,令偏导为0
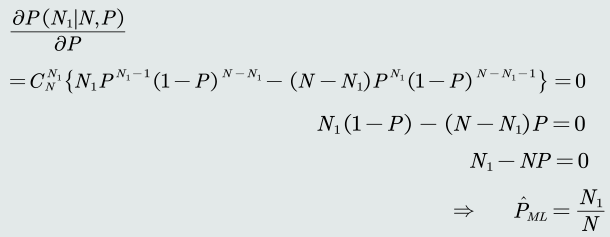
-
先验概率的最大似然估计就是该类训练样本出现的频率
- 观测概率估计:高斯分布
-
目标函数:给定𝐶𝑖 类的𝑁𝑖 个训练样本 𝒙1, … , 𝒙𝑁𝒊 ,观测似然概率的似然函数为:
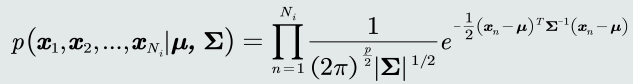
-
均值估计
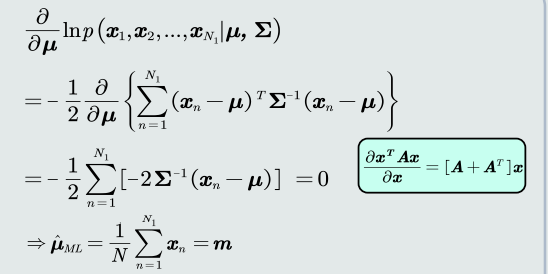
高斯分布均值的最大似然估计等于样本的均值。
-
协方差估计

高斯分布协方差的最大似然估计等于所有训练模式的协方差。
3.5 最大似然的估计偏差
-
无偏估计:如果一个参数的估计量的数学期望是该参数的真值,则该 估计量称作无偏估计(unbiased estimates)。
-
高斯分布均值的最大似然估计是无偏估计!
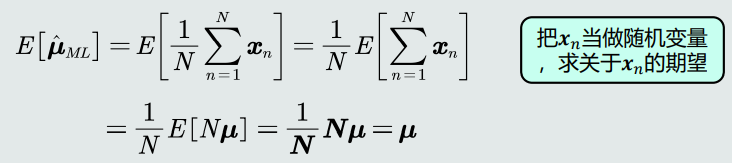
-
高斯分布协方差的最大似然估计是有偏估计!
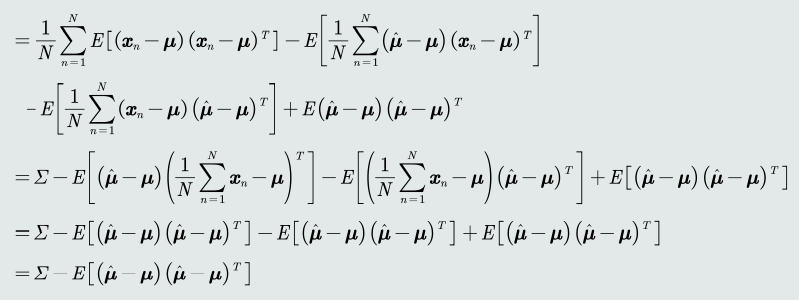
-
协方差的最大似然估计偏差多少?

-
协方差估计的修正:在实际计算中,可以通过将训练样本的协方差乘以𝑁/(𝑁 − 1)来 修正协方差的估计值
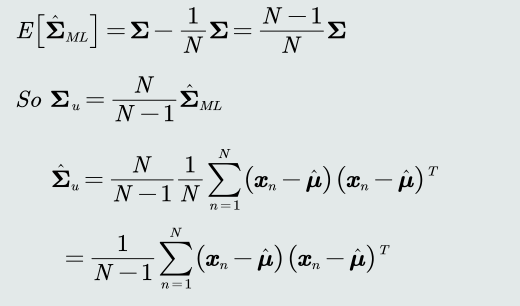
-
3.6 贝叶斯估计
-
贝叶斯估计:给定参数𝜃分布的先验概率以及训练样本,估计参数θ分布的后验概率。
-
参数的后验概率
-
给定单个𝐶𝑖类的训练样本集合𝐷𝑖,针对𝜃应用贝叶斯理论,得到 其后验概率:

-
由于样本之间相互独立(iid条件),可以得到:
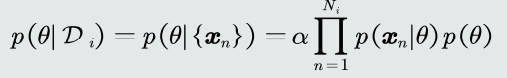
-
-
高斯观测似然
- 假设𝐶𝑖类的观测似然概率是单维高斯分布,且高斯分布的方差 𝜎 2已知,则待估计参数𝜃就只是高斯分布的均值𝜇。
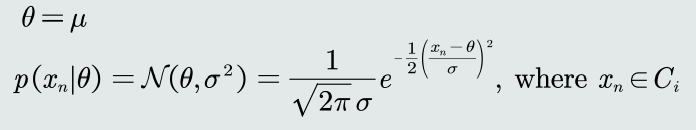
- 假设𝐶𝑖类的观测似然概率是单维高斯分布,且高斯分布的方差 𝜎 2已知,则待估计参数𝜃就只是高斯分布的均值𝜇。
-
参数(高斯均值)先验概率:
- 假设θ的先验概率分布也服从单维高斯分布,该分布的均值𝜇0 和方差𝜎0 已知:
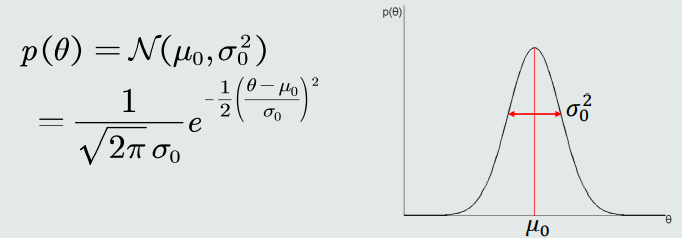
- 假设θ的先验概率分布也服从单维高斯分布,该分布的均值𝜇0 和方差𝜎0 已知:
-
参数(高斯均值)的后验概率
-
分析
- 给定𝐶𝑖类的𝑁𝑖个训练样本,参数θ概率分布的均值等于训练样 本均值和该参数先验概率均值的加权和。
- 给定𝐶𝑖类的𝑁𝑖个训练样本,参数θ概率分布的方差是由𝐶𝑖类观 测似然分布的方差、该参数的先验概率方差、 𝐶𝑖类的样本个 数共同决定。
- 当𝑁𝑖足够大时,样本均值m就是参数θ的无偏估计。
- 如果参数的先验方差𝜎0 = 0,则𝜇𝜃 → 𝜇0,意味先验的确定性较 大,先验均值的影响也更大,使得后续训练样本的不断进入对 参数估计没有太多改变。
- 如果参数的先验方差𝜎0 ≫ 𝜎,则𝜇𝜃 → 𝑚,意味着先验的确定 性非常小。刚开始由于样本较少,导致参数估计不准。随着样 本的不断增加,后验均值会逼近样本均值。
-
观测似然概率的估计
-
观测似然概率可以看做是关于𝑥的高斯分布
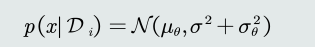
-
贝叶斯估计vs最大似然估计
-
贝叶斯:
- 把参数看做参数空间的一个概率分布。
- 依赖训练样本来估计参数的后验概率,从而得到观测似然关于参数的边缘概率:
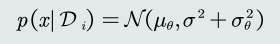
- 随着训练样本个数的逐渐增大,𝜇𝜃趋近真实均值;
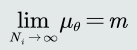
- 在已知的方差𝜎上加入𝜎𝜃 ,代表对于未知均值𝜇的不确定性。 样本个数逐渐增大时,贝叶斯估计越来越能代表真实的观测似然分布:
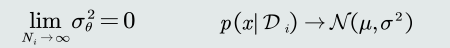
-
最大似然估计
-
把观测似然的参数𝜃看做是确定值,即参数空间的一个固定的点。
-
由于参数𝜃只有一个取值𝜃𝑀𝐿,所以估算观测似然概率的时候,不需要估 算关于𝜃的边缘概率。
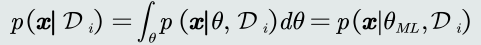
-
-
-
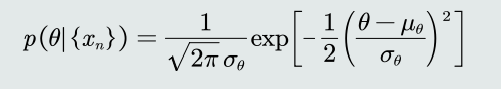

3.7 KNN估计
-
无参数(non-parametric) 技术来实现概率密度估计
- K近邻法(K-nearest neighbors)
- 直方图技术(Histogram technique)
- 核密度估计(Kernel density estimation)
-
概率密度估计基本理论
-
一个模式𝒙 落入区域𝑅的概率
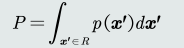
-
𝑘个样本落在区域𝑅
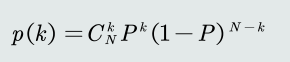
均值:
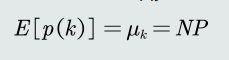
-
𝑝(𝒙)的近似估计
- 当𝑁非常大时,我们可以用二项分布的均值来近似表达 𝑘的分布:
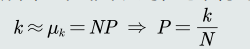
- 重新找回𝑃的定义,并假设在极小的区域𝑅内概率密度𝑝(𝒙)相同。 给定区域𝑅的体积记作𝑉。可以得到𝑝(𝒙)的近似估计:
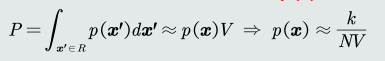
- 当𝑁非常大时,我们可以用二项分布的均值来近似表达 𝑘的分布:
-
-
KNN估计:
- K近邻(k-nearest neighbor, KNN)估计:给定𝒙,找到其对应 的区域𝑅使其包含𝑘个训练样本,以此计算𝑝 𝒙 。
- 第𝑘个样本与𝒙的距离记作𝑑𝑘 𝒙 ,则体积𝑉 = 2𝑑𝑘 𝒙
- 概率密度估计表达为:
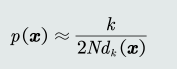
- 优点:可以自适应的确定𝒙相关的区域𝑅的范围。
- 缺点: KNN概率密度估计不是连续函数。 不是真正的概率密度表达,概率密度函数积分是 ∞ 而不是1。例如,在k=1时。
3.8 直方图与核密度估计
-
KNN估计的问题:
- 在推理测试阶段,仍然需要存储所有训练样本
- 由于区域R是由第k个近邻点确定的,易受噪声影响。
-
直方图估计
- 原理:
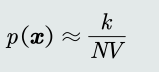
- 区域𝑅的确定:
- 直接将特征空间分为m个格子(bins),每个 格子即为一个区域𝑅,即区域的位置固定。
- 平均分格子大小,所以每个格子的体积 (带宽)设为𝑉 = ℎ,即区域的大小固定。
- 相邻格子不重叠。
- 落到每个格子里的训练样本个数不固定, 即𝑘值不需要给定。
- 统计学习
- 概率密度估计:给定任意模式𝒙,先判断它属于哪 个格子,其概率密度即为该格子的统计值/带宽:
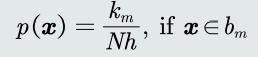
- 优缺点
- 优点
- 固定区域𝑅:减少由于噪声污染造成的估计误差。
- 不需要存储训练样本。
- 缺点
- 固定区域𝑅的位置:如果模式𝒙落在相邻格子的交界区域,意味 着当前格子不是以模式𝒙为中心,导致统计和概率估计不准确。
- 固定区域𝑅的大小:缺乏概率估计的自适应能力,导致过于尖锐 或平滑。
- 优点
- 带宽选择
- 带宽ℎ过小,概率密度函数过于尖锐。
- 带宽ℎ过大,概率密度函数过于平滑。
- 原理:
-
核密度估计
-
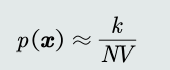
-
区域𝑅的确定:以任意待估计模式𝒙为中心、固定带宽ℎ,以此确定一个区域𝑅。
-
原理
- 统计学习
- 定义一个窗口函数:以𝒖为中心的单位超立方体(unit hypercube)
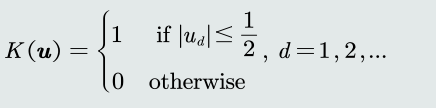
- 统计落入区域𝑅(带宽为h )内的训练样本个数

- 定义一个窗口函数:以𝒖为中心的单位超立方体(unit hypercube)
- 概率密度估计:
- 给定任意模式𝒙,其概率密度可以表达如下:
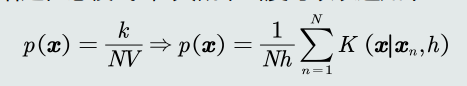
- 核函数要满足如下两个条件,使得估计的概率密度符合概率的定义。
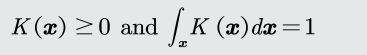
- 所以,通常会放宽核函数输出的0/1约束,使其满足概率的定义,输 出变为0~1之间的值。
- 给定任意模式𝒙,其概率密度可以表达如下:
- 统计学习
-
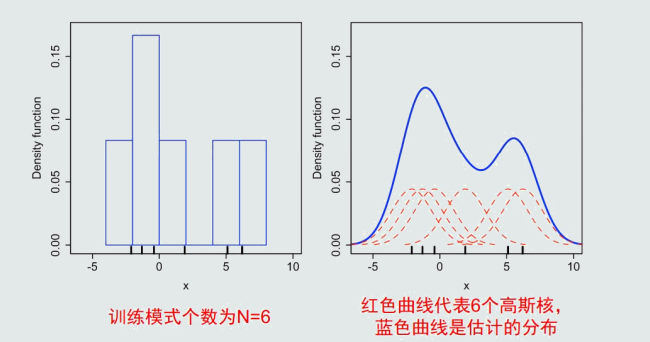
核函数:核函数可以是高斯分布、均匀分布、三角分布等。
-
优缺点
- 优点:
- 以待估计模式𝒙为中心、自适应确定区域𝑅的位置(类似KNN)。
- 使用所有训练样本,而不是基于第 𝑘 个近邻点来估计概率密度, 从而克服KNN估计存在的噪声影响。
- 如果核函数是连续,则估计的概率密度函数也是连续的。
- 缺点
- 与直方图估计相比,核密度估计不提前根据训练样本估计每个 格子的统计值,所以它必须要存储所有训练样本。
- 优点:
-
带宽选取原则:泛化能力
- 带宽ℎ决定了估计概率的平滑程度。
- 因为给定的训练样本数量是有限的,所以要求根据这些训练样本估计出 来的概率分布既能够符合这些训练样本,同时也要有一定预测能力,即 也能估计未看见的模式。
-
核密度估计比直方图估计更加平滑。
-
