

(数据挖掘方法论)
2020/12/18
数据挖掘方法论
数据挖掘活动主要分为无监督和有监督两大类。
在无监督数据挖掘中,我们对各个变量不区别对待,而是考察它们之间的关系。这类方法有描述和可视化、关联规则分析、聚类分析、主成分分析等。
在有监督数据挖掘中,我们希望建立根据一些变量来预测另一些变量的模型,前者被称为自变量,后者被称为因变量。有监督数据挖掘能从数据中获取深度细致的信息,应用非常广泛(如针对贷款企业违约率的预测、针对信用卡客户对营销活动的响应情况的预测、零售商店的销售预测等)。
我们将要介绍的两种数据挖掘方法论主要针对的是有监督数据挖掘,它们为数据挖掘项目提供了设计和实施的大框架。CRISP-DM(CRoss-Industry Standard Process for Data Mining,数据挖掘的跨行业标准过程)是由Daimler Chrysler、SPSS和NCR三家机构共同发展起来的数据挖掘方法论(http://www.crisp-dm.org)。CRISP-DM参考模型如图1.3所示,它将数据挖掘分为以下六个阶段:
1.业务理解从业务的角度理解项目实施的目的和要求,将这种理解转化为一个数据挖掘问题,并设计能达成目标的初步方案。
2.数据理解收集原始数据,熟悉它们,考察数据的质量问题,对数据形成初步的洞见。
3.数据准备从原始数据中构造用于建模的最终数据集,构造过程中包含观测选择和变量选择、数据转换和清理等多种活动。
4.建模选择并应用多种建模方法,优化各种模型。
5.模型评估全面评估模型,回顾建立模型的各个步骤,确保模型与业务目标一致,并决定如何使用模型的结果。
6.模型发布以客户友好的方式组织并呈现从数据挖掘中所获取的知识。这一阶段经常会在组织的决策过程中灵活地应用模型。例如,在建立了预测贷款企业违约率的模型后,模型发布形式可以如下:信贷员在前台输入一个贷款企业的各种信息,后台使用模型预测违约概率后直接反馈给前台,帮助信贷员决定是否给该企业贷款。
从图1.3中可以看出,前五个阶段都不是线性或一蹴而就的。在数据理解阶段可能发现数据能支持的业务目标不同于业务理解阶段所设定的目标,所以需要重新回到业务理解阶段;数据准备阶段和建模阶段互为反馈,需要反复改进建模数据集的构造方法和建模的方法;模型评估阶段可能发现模型的结果与预先设定的业务目标不符,需要重新进行业务理解。图1.3中带箭头的外圈表示所有这些阶段都是循环往复、持续改进的过程。
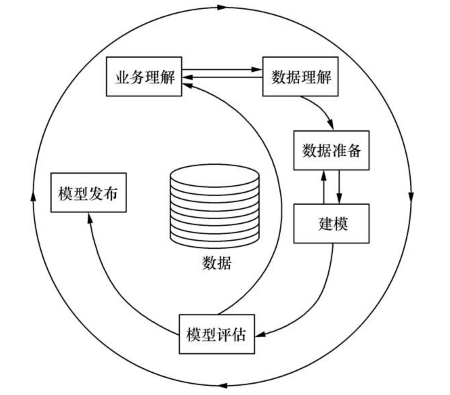
图1.3 CRISP-DM参考模型
针对数据挖掘过程中直接与数据相关的部分,SAS公司提出了SEMMA方法论,将数据挖掘的核心过程分为抽样(Sample)、探索(Explore)、修整(Modify)、建模(Model)、评估(Assess)几个阶段。
1. 抽样
从数据集中抽取具有代表性的样本,样本应该大到不丢失重要的信息,小到能够便于操作。创建三个数据子集:
(1)训练数据,用于拟合各模型;
(2)验证数据,用于评估各模型并进行模型选择,避免过度拟合;
(3)测试数据,用于对模型的普适性形成真实的评价。
我们不能根据对训练数据集的拟合效果来进行模型选择。举例来说,如果有100个训练数据点用于拟合因变量y和自变量x之间的关系,使用x的99次多项式能够完美拟合这100个点,但是这个多项式模型不仅拟合了y与x之间系统的关系,也拟合了训练数据集的噪音,我们称这种现象为过度拟合。因为不同数据的噪音是不同的,所以这样的模型无法推广到新的数据。因此,我们需要使用验证数据集来比较各模型并进行选择。类似地,因为在这种选择过程中不仅使用了验证数据集中因变量和自变量之间系统的关系,也使用了其中的噪音,所以使用验证数据集无法对被选择模型的效果进行客观评价。因此,我们需要使用第三个数据集——测试数据集来评价模型。
2.探索使用可视化方法或主成分分析、因子分析、聚类等统计方法对数据进行探索性分析,发现未曾预料的趋势和异常情况,对数据形成初步理解,寻求进一步分析的思路。
3.修整包括生成和转换变量、发现异常值、变量选择等。
4.建模搜寻能够可靠地预测因变量的数据组合,具体而言是指采用哪些观测、使用哪些自变量能够可靠地预测因变量。
5.评估评估模型的实用性、可靠性和效果。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述