K8S HPA在CRD Operator中的应用
K8S HPA在Trino Operator中的应用
HPA(Horizontal Pod Autoscaler)
水平扩缩意味着对增加的负载的响应是部署更多的 Pod。 这与“垂直(Vertical)”扩缩不同,对于 Kubernetes, 垂直扩缩意味着将更多资源(例如:内存或 CPU)分配给已经为工作负载运行的 Pod。
https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/
官方HPA文档里并没有说明HPA对CRD(自定义资源)的支持。仅支持K8S自带Deployment 或者 StatefulSet等资源。
https://github.com/apache/flink-kubernetes-operator/blob/main/examples/hpa/basic-hpa.yaml
后来在社区里发现,有人使用HPA来扩缩CRD
scaleTargetRef:
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
name: basic
仔细翻阅CRD的文档,里面说明了关于HPA的支持。
主要是暴露Selector、Replicas字段。
apiVersion: trino.cloud.bds.17usoft.com/v1
kind: WorkerCluster
metadata:
spec:
status:
labelSelector: app=trino-worker,cluster=dynamic-test
replicas: 5
现状
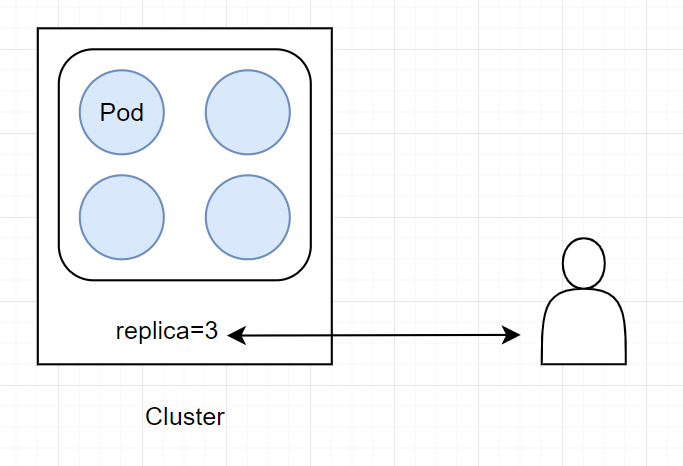
防止用户方手动调节与平台方自动调节冲突,将副本数的控制权收敛到HPA,用户可调整Min来间接控制副本数
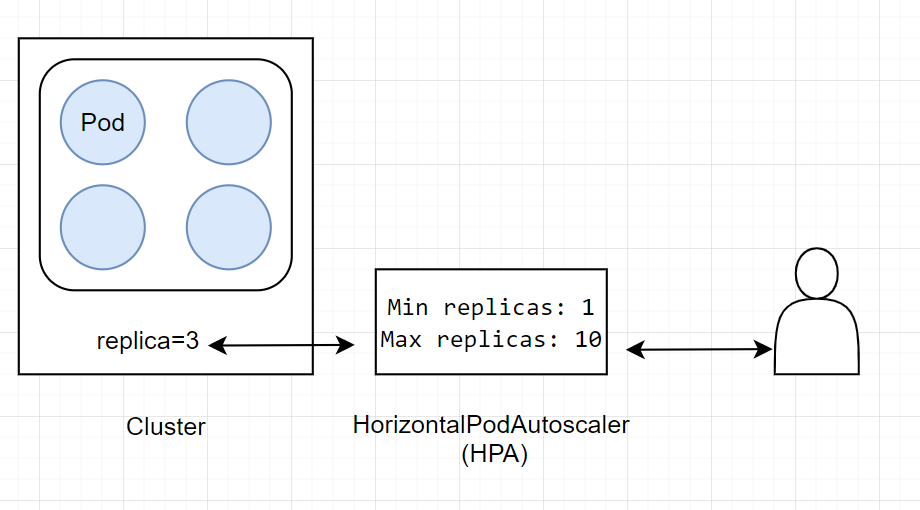
应用形式
"hpa": {
"cpuAverageUtilization": 55,
"memoryAverageUtilization": 55,
"behavior": {
"scaleDown": {
"stabilizationWindowSeconds": 300,
"podsScalingPolicy": {
"value": 2,
"periodSeconds": 50
},
"percentsScalingPolicy": {
"value": 10,
"periodSeconds": 50
}
},
"scaleUp": {
"stabilizationWindowSeconds": 300,
"podsScalingPolicy": {
"value": 2,
"periodSeconds": 30
},
"percentsScalingPolicy": {
"value": 10,
"periodSeconds": 300
}
}
}
},
指标
目前版本支持CPU、Memory的利用率
"cpuAverageUtilization": 55,
"memoryAverageUtilization": 55,
扩缩容行为
"behavior": {
"scaleDown": {
"stabilizationWindowSeconds": 300,
"podsScalingPolicy": {
"value": 2,
"periodSeconds": 50
},
"percentsScalingPolicy": {
"value": 10,
"periodSeconds": 50
}
}
可根据个数或者百分比进行缩放,会计算其速率,取最大的。
例如:
当节点副本数为10,按个数会扩2个,按百分比会扩1个,HPA会选择扩2个。
当节点副本数为40,按个数会扩2个,按百分比会扩4个,HPA会选择扩4个。
应用
原有的HPA基于Request(下限)来计算利用率。而目前云平台的浮动配置普遍,上下限四倍配比。

Request、Limit本身是优化资源利用率。而HPA自身基于Request(下限)的与我们的理念冲突,
目前平台层会在中间做一层转化,使其基于limit进行扩缩容,例如:
request {"cpu":"1","memory":"4Gi"}
limit {"cpu":"10","memory":"40Gi"}
用户侧以limit为指标,设置 60%
平台侧会放大同样的比例以request为指标,用户侧会以limit为指标,设置 为600%
这样即利用的Request、Limit对资源的利用率提升,也充分利用了HPA的资源利用率的提升。
注意事项
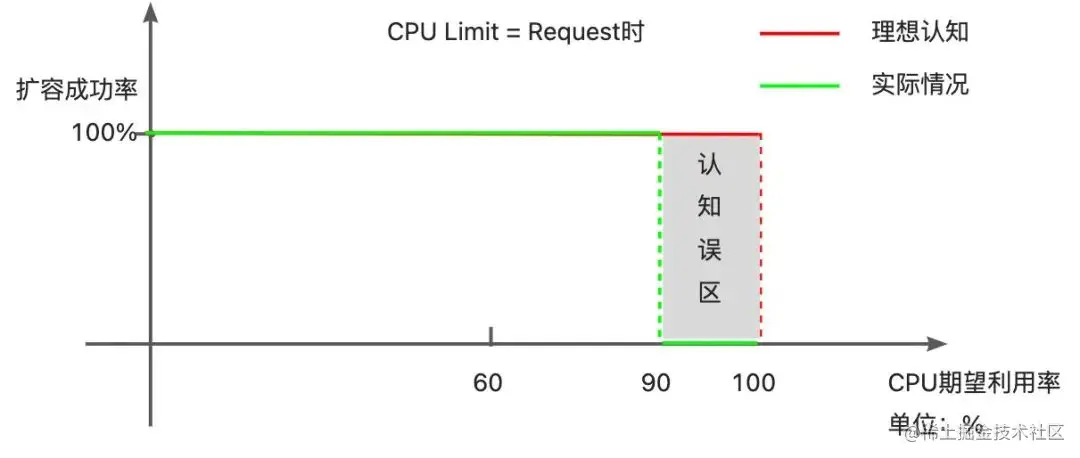
因容忍度的存在,HPA 存在扩容死区
现象:当 Request(下限)=Limit (上限)时,期望利用率超过 90%时,无法正常扩容。
原因剖析:HPA 中存在容忍度(默认为 10%),指标变化幅度小于容忍度时,HPA 会忽略本次扩/缩动作。若当期望利用率为 90%时,则实际利用率在 81%-99%之间,都会被 HPA 忽略。
避坑指南:当 Request(下限)=Limit (上限)时,避免设置过高的期望利用率,一来避免扩容死区;二来被动扩容有一定的迟滞时间,留下更多的缓冲余量以应对突增流量。
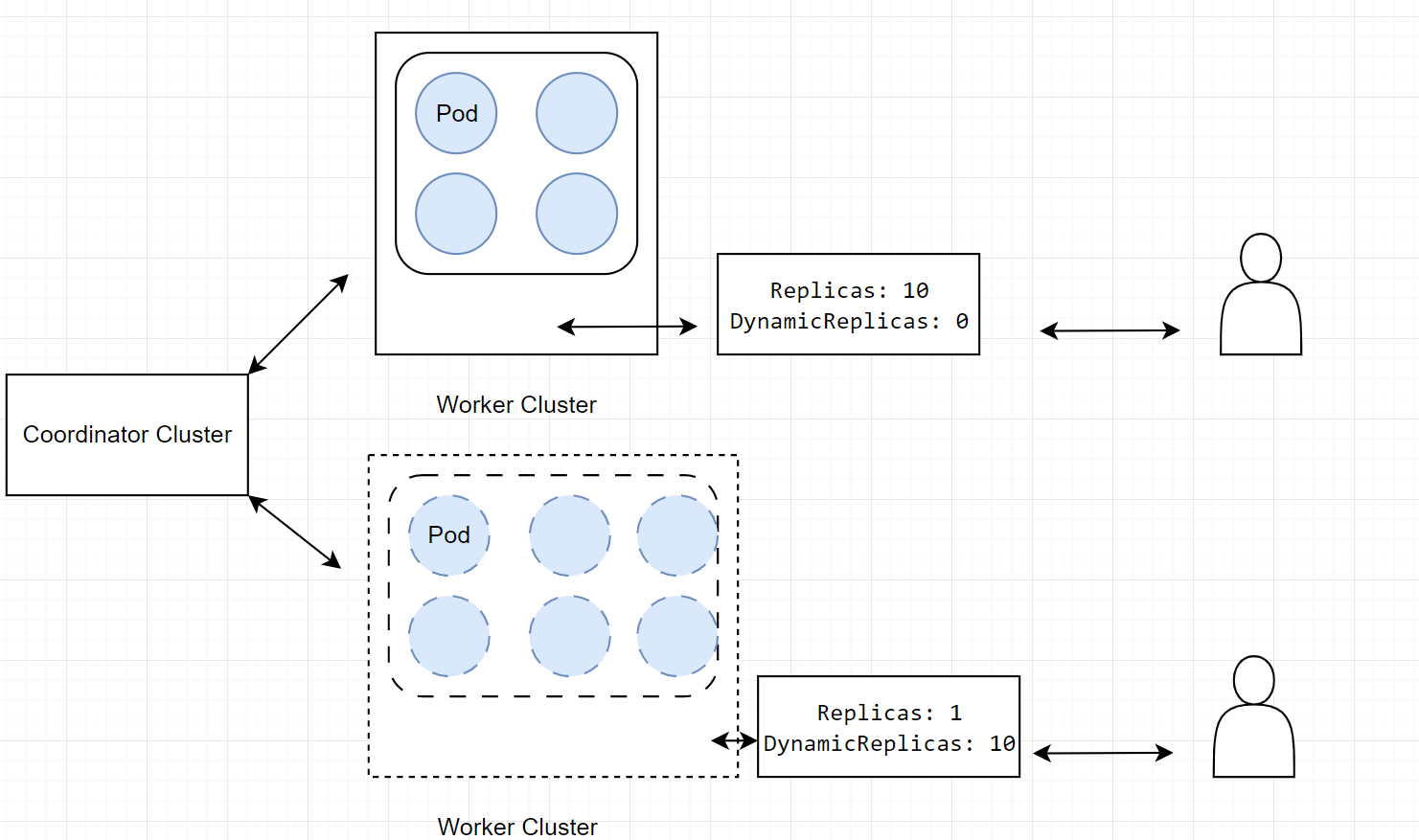
HPA的应用有可能导致更多不可控性
精彩分享 | 欢乐游戏 Istio 云原生服务网格三年实践思考
部署形式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号