深入理解计算机系统 CSAPP (二)
1.不要抽象的学“操作系统"理论,而学具体的操作系统Linux。从熟悉各种常见的Linux命令开始。
(CentOS, RedHat, Ubuntu,..)
2.各种Linux API及背后原理
3.4大资源角度理解操作系统和应用程序:CPU、内存、磁盘、网络(性能优化...)
基础-Linux命令常用操作0.远程登录,远程文件传输#ssh,scp
1.文本编辑与查看
- vi, head, tail, cat, grep,..
2.文件、目录操作
- ls, mkdir , cd, cp, rm, chmod
3.软件安装/卸载
- yum install/uninstall4.管道、重定向>, >>,l
..
建议:
不需要死记硬背每个命令和参数,找本常见的Linux操作命令书,或者
baidulgoogle,用的时候不会的再翻阅。工作一段时间,常用的也就会了。
CPU
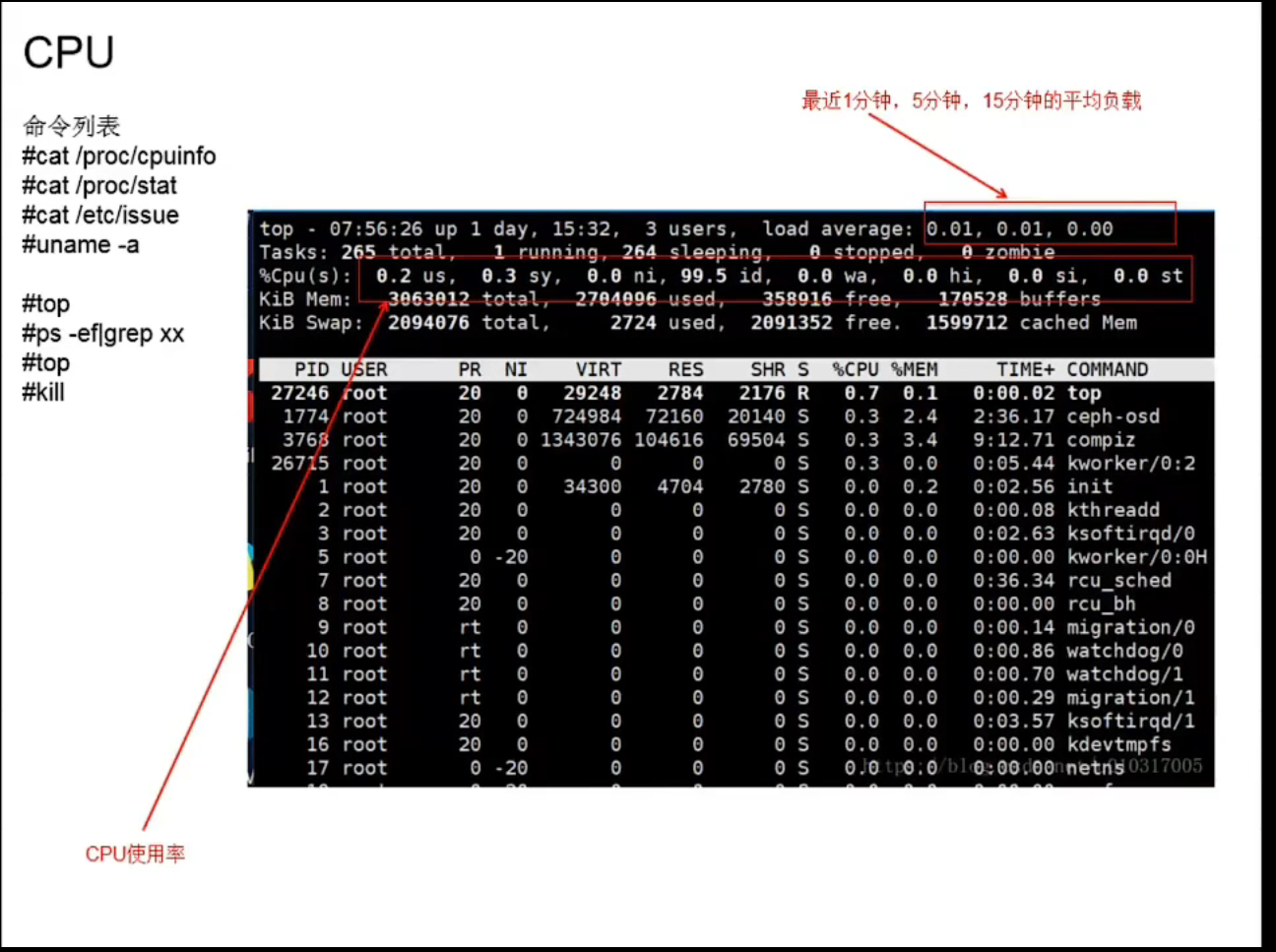
cat /proc/stat
每个cpu,都有8个数字,这8个数字,表示从电脑开机到当前的累计时间(单位是jffies,时钟中断次数)
use: cpu在用户态的运行时间
system: cpu在内核态的运行时间
nice: ???
idle: cpu空闲时间
iowait: cpu空闲,并且在等待IO的时间
irq:硬中断时间
softirq:软中断时间
steal:???
total1 = use + system + nice + idle + iowait + irq + softirq + steal
used1 = use + system + nice + irq + softirq + steal
过15秒,再采集一次
total2= use + system + nice + idle +iowait + irq + softirq + steal
used2 = use + system + nice + irq + softirq + steal
这15秒内,cpu的使用率=(used2 - used1)/(total2 - total1)备注:使用率的计算,与采样间隔有关
- 在线系统:
低峰期,CPU使用率往往只有15-30%,大量资源浪费。->为什么要上云?
高峰期,达到70%,就算CPU资源利用充分
- 离线大数据系统:
没有明显的波峰波谷,平均使用率可以到80%
- 流式大数据计算系统:
要看消息的到达是否有明显的波峰波谷
背景知识1.区分“系统调用”与“库函数调用”
系统调用(System Call) :操作系统对外提供的API,C语言函数形式提供
库函数调用(LibraryFunction):C语言提供的函数库
因为2者都是C语言开发的,使得c/c++程序在调用库函数的时候,往往
区分不出来到底是-一个“系统调用”,还是“库函数调用”
1.Linux官网提供的有系统调用的API列表,这个列表以外的,都不是‘系统调用”。
2.库函数可能是对”系统调用“的封装,也可能没有使用系统调用
3.“系统调用”是-一个进程从“用户态”进入“内核态”的切换点
用户态: cpu执行用户程序自己的代码
内核态: cpu执行操作系统内核代码
背景知识2:硬中断与软中断
1.什么是“中断”?
你正在家“看电视”,突然有个快递员打电话,你“中断"看电视的行为,去取快递,这就是“中断”。
中断包括2个部分:
中断触发(中断信号):快递员打电话中断响应(中断处理程序):你去取快递
2.为什么有硬中断、软中断?–中断嵌套问题
想象以下场景:快递员找不到你家地址,打电话沟通了很久,这个时候另外一个快递员打电话通知你另外一个快递,电话一直占线,最后通知不到你,就走了。
中断无法被中断,即中断无法被嵌套。
解决办法:
第1步:快递员打电话,你告知放快递柜,立即挂断电话(硬中断)
第2步:你事后去快递柜取(软中断)
硬中断:硬件触发的,需要操作系统立即执行,执行时间要短,以免这个期间,有新的中断信号响应不了,比如时钟中断、IO完成事件...
软中断:硬中断处理完成之后,操作系统触发,由操作系统的后台线程去异步执行,对时间要求宽松
背景知识3:进程的nice值
1.进程的nice值(缩写ni)
范围-20到19,默认是0,值越大,优先级越低
2.cpu使用率中的nice含义:
低优先级用户态cpu时间,也就是进程的nice值被调整为1-19的cpu时间
(use里面,不包含nice时间)
背景知识4: iowait 与 steal
iowait高,不是指cpu正在“忙于IO操作”,而是指此时CPU为空闲,并恰好有未处理完的lO操作(IO的读写不需要CPU参与)。
steal:系统运行在虚拟机里面,被其它虚拟机占用的cpu时间
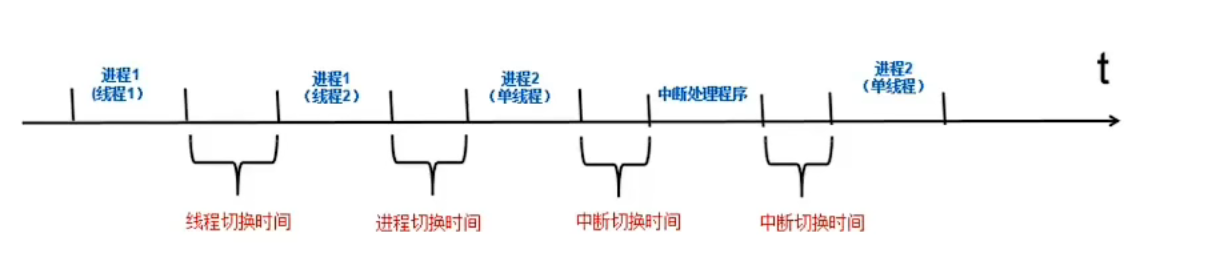
背景知识5:经常说的“上下文切换时间",反映在上面哪个数字里面?
- 用户态/内核态切换(同一个进程,从用户态切换到内核态)use, system这2个指标
- 进程上下文切换(1个进程,切换到另一个进程)
- 线程上下文切换(同1个进程,1个线程切换到另1个线程)
- 中断上下文切换(进程,切换到“中断处理程序”)
切换都是在内核态进行的,所以最终都反映在了system这个指标上
“平均负载"怎么计算的?进程的状态
R:Running/Runnable (Ready),正在跑的;正准备跑的(就绪,等待被调度)
s: Sleep,可中断的睡眠状态,等待lO、线程锁...
D: Disk Sleep,不可中断的睡眠状态,通常是在进行IO的时候,会短暂的进入到该状态
Z: Zombie,僵尸进程,等待被父进程回收
1.“平均负载”:单位时间内,处于R和D状态的进程的个数
单位时间,可能是1分钟、5分钟、15分钟
2.为什么只统计R和D状态的进程?
因为只有这2类进程正占用着CPU(或者即将占用),也就是“活跃进程数"。
3.当平均负载>CPU核数,说明CPU繁忙!
cpu使用率是一个百分比,而这里的平均负载是一个数字。
平均负载越高,使用率越高吗?? ?
CPU密集型应用
(比如:排序、加/解密、音视频编/解码、压缩/解压、序列化/反序列化、大对象的新建/拷贝)
使用率高,平均负载也高,2者是正相关
IO密集型应用
(比如DB读写、KV查询、http/rpc外部接口调用)
平均负载可能很高,但CPU使用率不一定高。
负载高,可能是CPU问题,也可能是lO问题。
进一步,再看iowait是否高,就大概知道是CPU,还是lO问题。
内存
磁盘与文件系统
缓冲lO
对应API接口——C语言的库函数:fopen,fclose,fseek,fflush,fread,fwrite,fprintf,fscanf…
无缓冲lO
Linux系统API:open,close,lseek,fsync,read, write,pread, pwrite
直接IO,就是直接读写磁盘,不经过操作系统的Pagecache。
直接IO和无缓冲IO所用的API是一样的,只是在open文件时加了O_DIRECT参数。
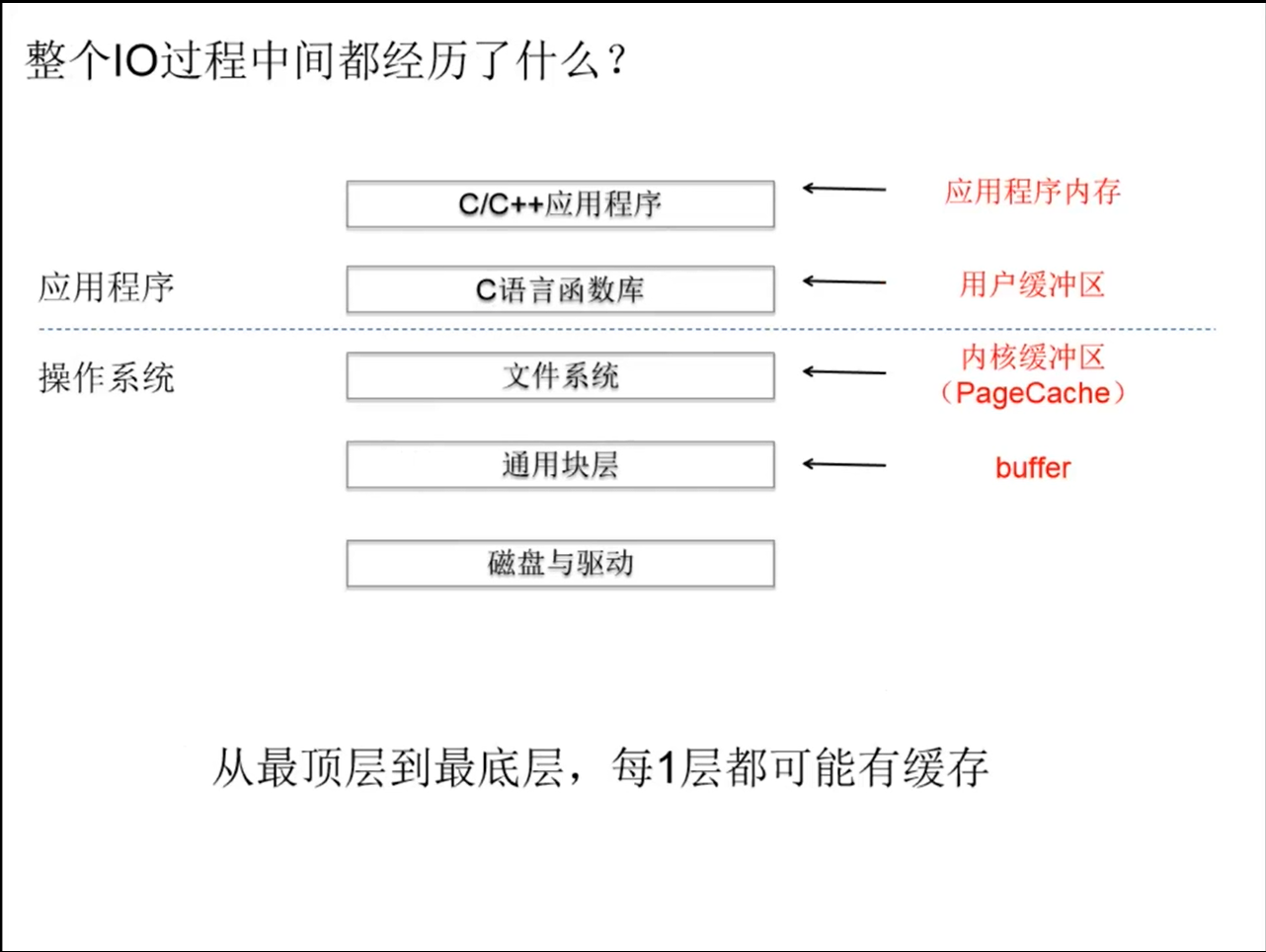
应用程序内存:是通常写代码用malloc/free、new/delete等分配出来的内存。
用户缓冲区:C语言的FILE结构体里面的buffer。FILE结构体的定义如下,可以看到里面有定义的buffer;
内核缓冲区:Linux操作系统的Page Cache。为了加快磁盘的IO,Linux系统会把磁盘上的数据以Page为单位缓存在操作系统的内存里,这里的Page是Linux系统定义的一个逻辑概念,一个Page一般为4K。
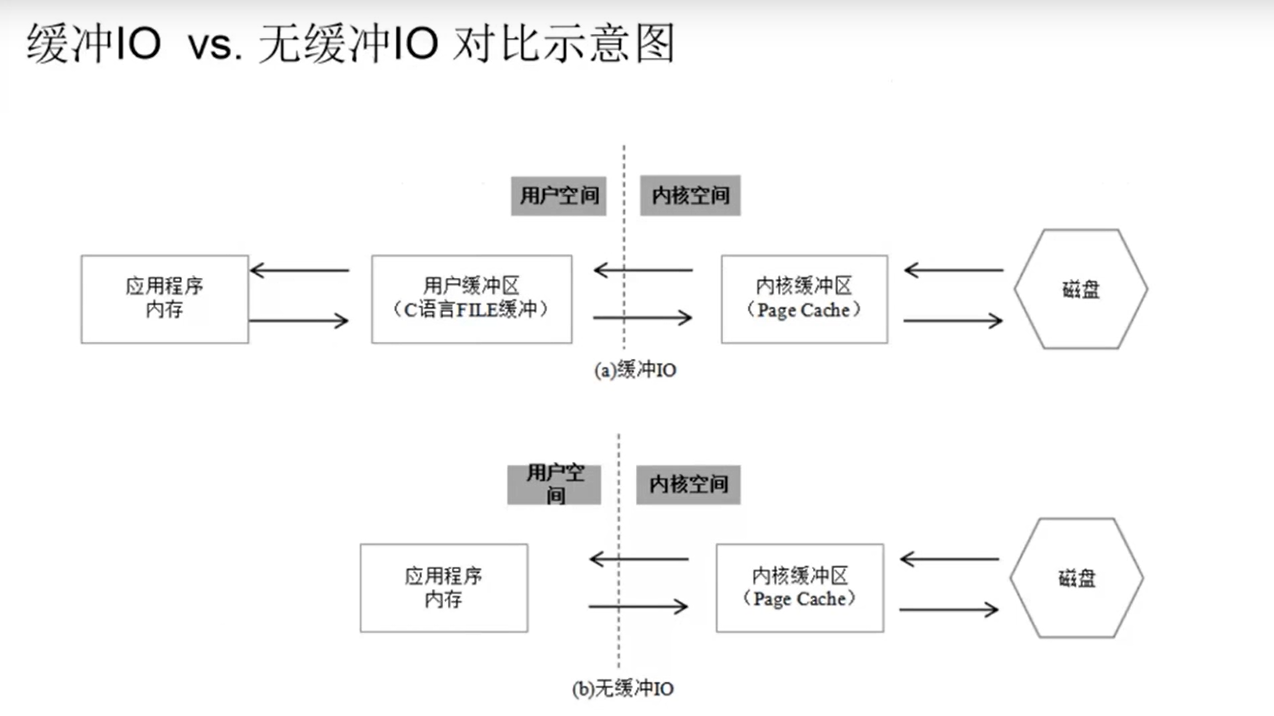
无缓冲指的是在用户层次没有缓冲区,并不是真正意义上的无缓冲。
1.什么叫“块设备”?
以“块"为最小读写单位,块大小是512字节(传统机械硬盘,一个扇区大小就是512字节)。内存呢,是"字节设备“,最小读取单位能到1个字节。
2.什么叫物理扇区/逻辑扇区?
物理扇区:就是传统机械硬盘的扇区,512字节
逻辑扇区:现代的机械硬盘扇区已到4K,同时SSD硬盘也没有扇区概念,但在操作系统里面,一个扇区512字节的概念已经根深蒂固。为了兼容,有了“逻辑扇区"概念,逻辑扇区统一了传统、现代机械硬盘、SSD硬盘,还是512字节。
3.什么叫“通用块层”?
把各种异构的磁盘设备,抽象成通用的一个个“块”,供上层文件系统调用。在这层会对IO请求进行排队、合并,尽可能提高lO性能
fflush vs. fsync
fflush:缓冲lO中的一个API,它只是把数据从用户缓冲区刷到内核缓冲区而已
fsync:则是把数据从内核缓冲区刷到磁盘里。
1.无论缓冲I/O,还是无缓冲IO,如果在写数据之后不调用fsync,此时系统断电重启,最新的部分数据会丢失。
2.每次IO调用fsync,性能数量级上的下降
性能vs.可靠性的权衡
例子1: Mysql里面双1参数
innodb_flush_log_at_trx_commit = 1 //每次事务提交,innodb redolog调用fsync刷盘
sysc_binlog = 1 //每次事务提交,binlog调用fsync刷盘
牺牲一定性能,保证数据可靠性
例子2:Kafka
log.flush.interval.messages 每多少条刷盘一次
log.flush.interval.ms 每隔多长时间,刷盘1次
log.flush.scheduler.interval.ms 周期性刷盘,默认是3s
为了高性能,异步刷盘。因为有3个副本,可以忍受1个副本丢数据。
内存映射文件
(1)Linux API
void* mmap(void* start,size_t length,int prot,int flags,int fd(文件描述符),off_t offset)
(2) Java APl
MappedByteBuffer类可以实现同样的目的。
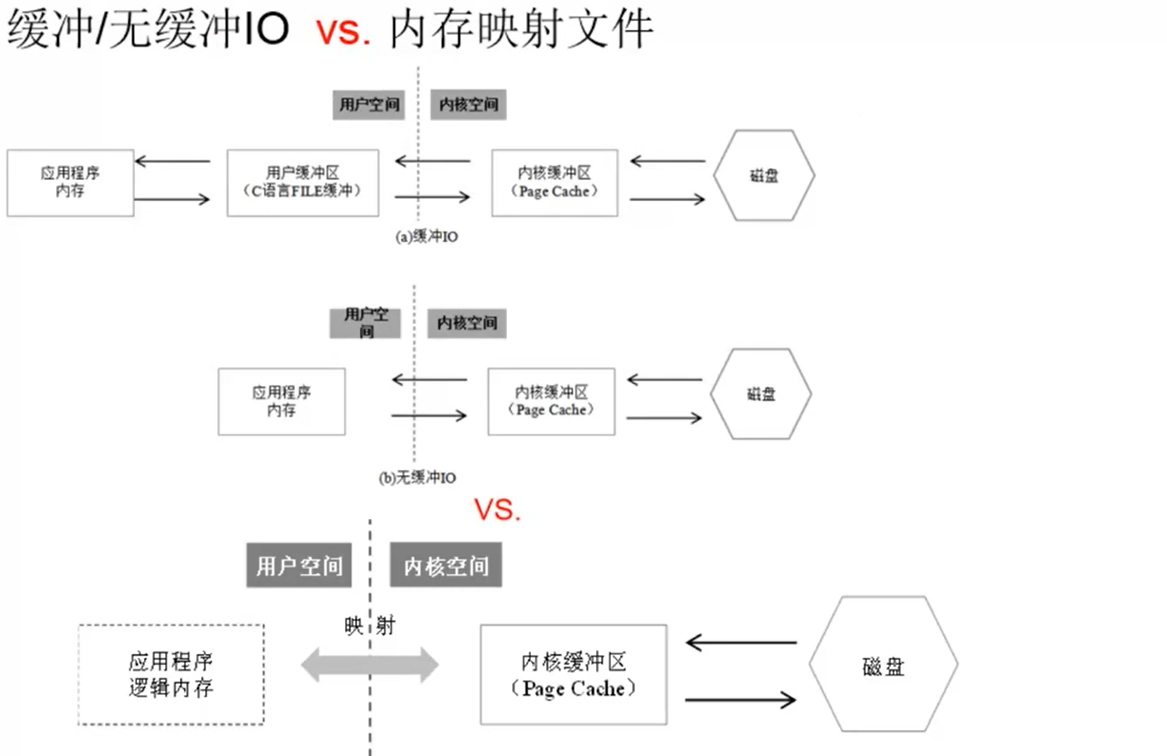
直接拿应用程序的逻辑内存地址映射到Linux操作系统的内核缓冲区,应用程序虽然读写的是自己的内存,但这个内存只是一个“逻辑地址”,实际读写的是内核缓冲区.
零拷贝
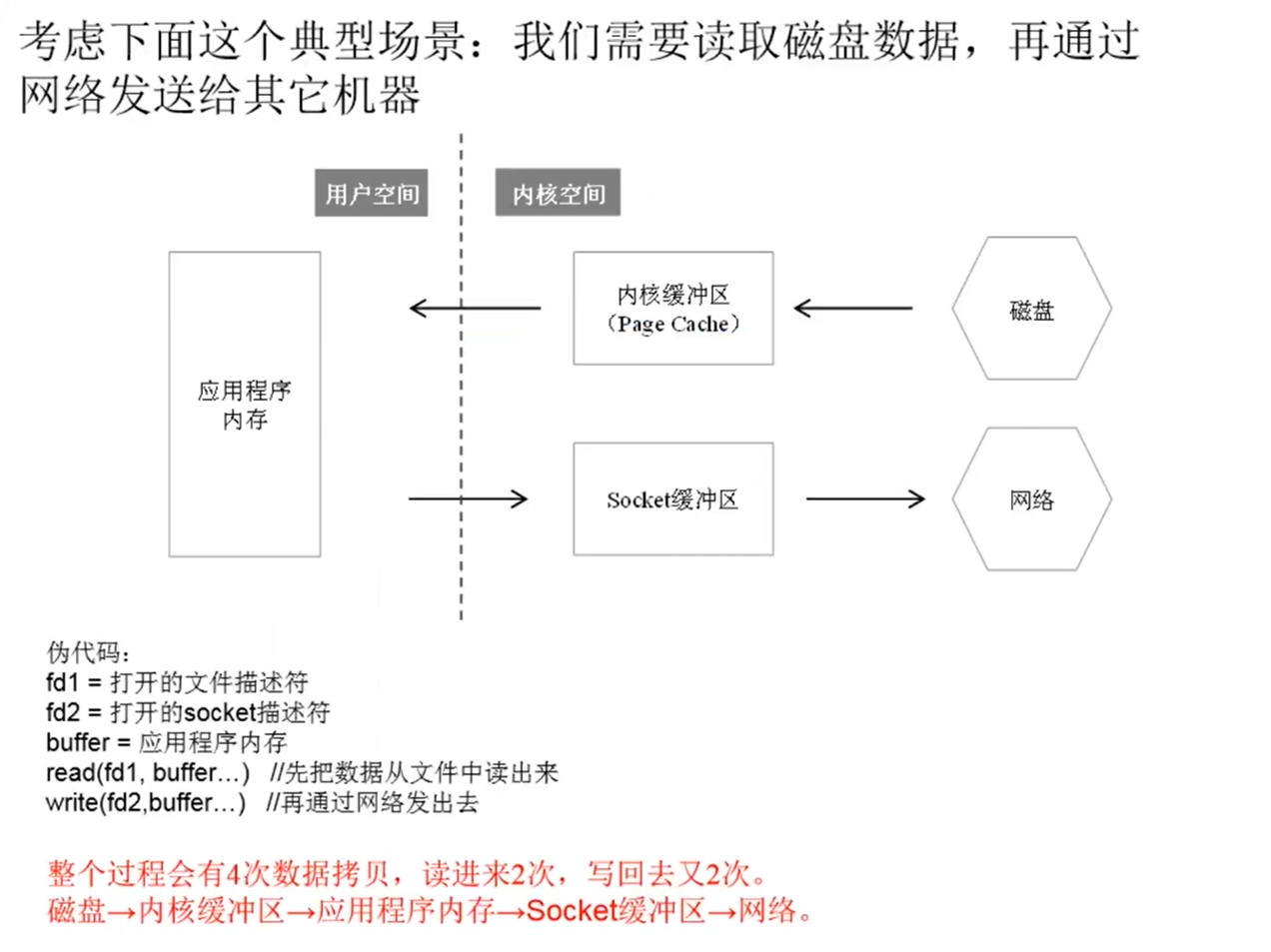
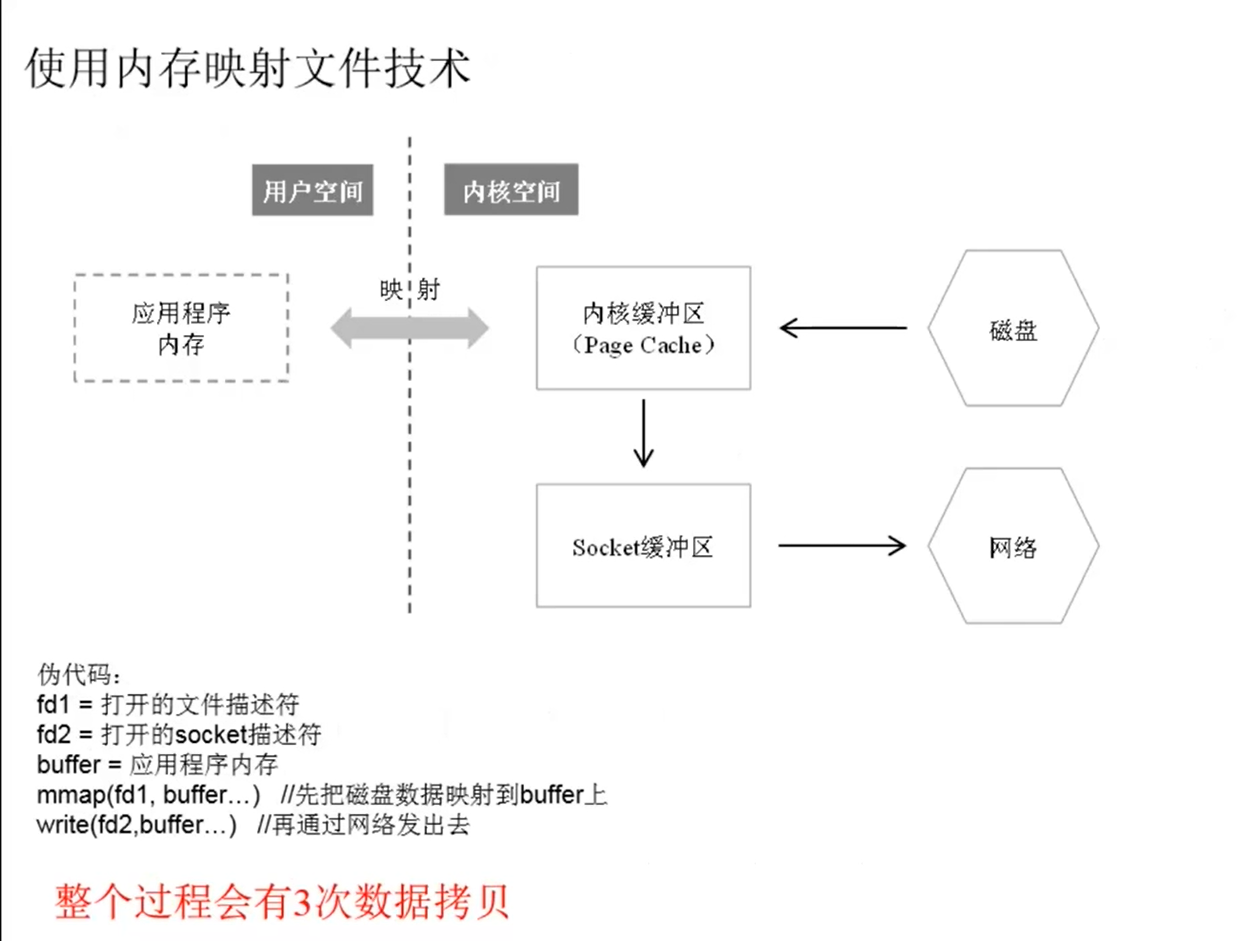
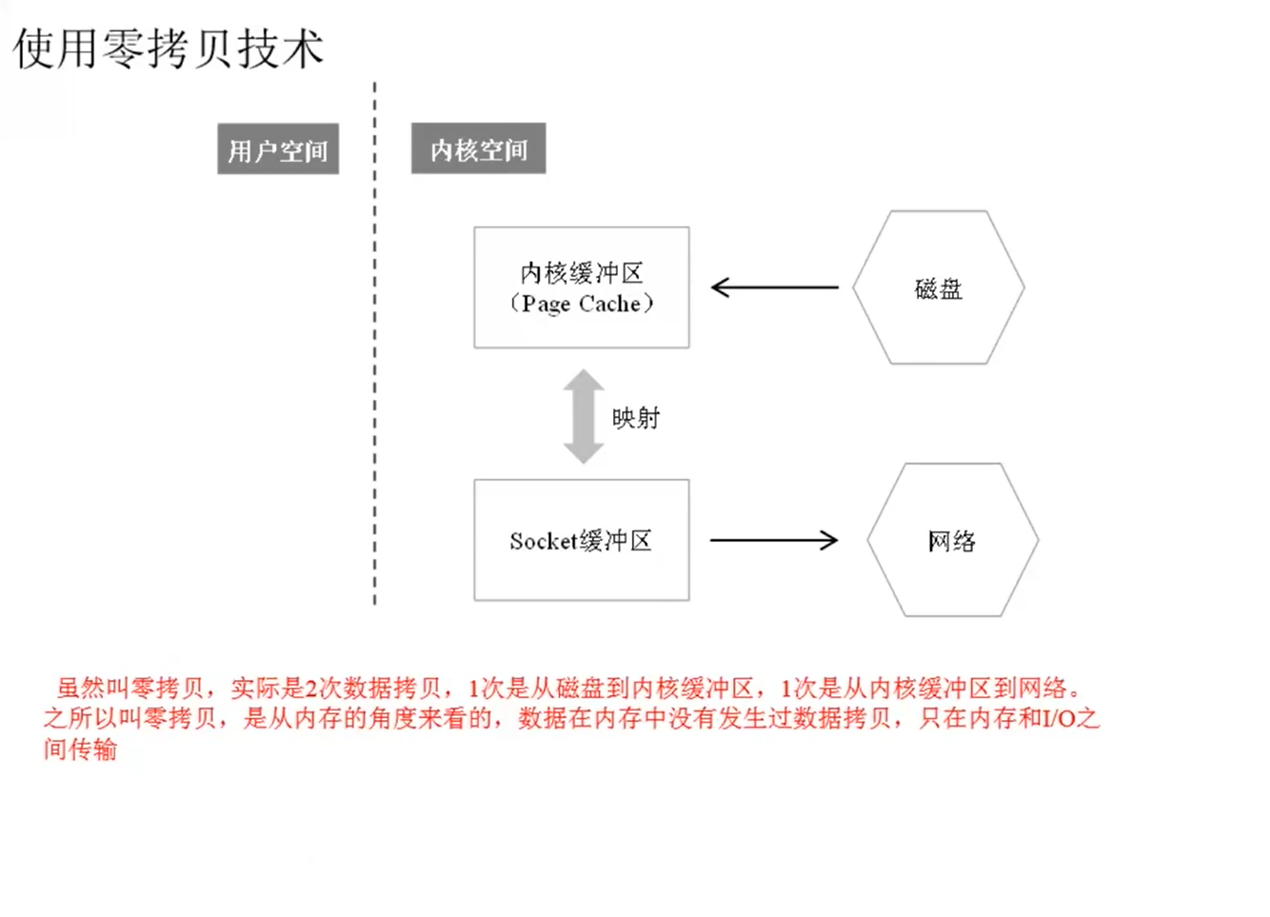
对应API
(1) Linux API
sendfile(int out_fd, int in_fd, off_t *offset, size_t count)
其中,out_fd是socket描述符,in_fd文件描述符。
(2)Java API
FileChannel.transferTo(long position, long count,WritableByteChanneltarget)
零拷贝的一个应用:
Kafka Consumer
Kafka Consumer消费消息的时候,Broker通过零拷贝技术把磁盘上的消息读出来,然后通过网络发送给Consumer.
网络
Linux操作系统的4种网络IO模型
排列组合,理论上有4种模型·
同步阻塞模型
同步非阻塞模型
异步阻塞模型(史籍并不存在)
异步非阻塞模型
3个误解:
认为非阻塞IO (Non-Blocking IO)和异步IO ( asynchronous IO)是同一个概念。
认为Linux系统下的select、poll、epoll这类1/O多路复用是“异步I/O”。
存在一种I/O模型,叫“异步阻塞IO”,实际没有这种模型
第一种模型:同步阻塞l/O
Linux系统的read和write函数,在调用的时候会被阻塞,直到数据读取完成,或者写入成功。
第二种模型:同步非阻塞l/O
和同步阻塞I/O的API是一样的,只是打开fd的时候带有O_NONBLOCK参数。于是,当调用read和write函数的时候,如果没有准备好数据,会立即返回,不会阻塞,然后让应用程序不断地去轮询。
第三种模型:O多路复用(IO Multiplexing)
前面两种I/O都只能用于简单的客户端开发。但对于服务器程序来说,需要处理很多的fd(连接数可以达几十万甚至百万)。如果使用同步阻塞IIO,要处理这么多的fd需要开非常多的线程,每个线程处理一个fd;如果用同步非阻塞IO,要应用程序轮询这么大规模的fd。这两种办法都不行,所以就有了O多路复用。
在Linux系统中,有三种I/O多路复用的办法: select、poll、epoll
第四种模型:异步IO
Windows系统的lOCP,这是一种真正意义上的异步I/O。
所谓异步VO,是指读写都是由操作系统完成的,然后通过回调函数或者某种其他通信机制通知应用程序
阻塞/非阻塞: read/write函数调用是否立即返回
同步/异步lO: read/write操作是应用程序完成,还是操作系统完成,再通知应用程序
在上述4种模型中,最常用的是第3种:IO多路复用,尤其是epoll
select
int select (int maxfdp1, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
关于此函数,有几点说明:
1)因为fd是一个int值,所以fd_set其实是一个bit数组,每1位表示一个fd是否有读事件或者写事件发生。
2)第一个参数是readfds或者writefds的下标的最大值+1。因为fd从0开始,+1才表示个数。
3)返回结果还在readfds和writefds里面,操作系统会重置所有的bit位,告知应用程序到底哪个fd上面有事件,应用程序需要自己从0到maxfds-1遍历所有的fd,然后执行相应的read/write操作。
4)每次当select调用返回后,在下一次调用之前,要重新维护readfds和writefds。
poll
通过看上面的函数会发现,select、 poll每次调用都需要应用程序把fd的数组传进去,这个fd的数组每次都要在用户态和内核态之间传递,影响效率。
epoll
创建一个epoll的句柄,size用来告诉内核监听的数目一共有多少。其中的size并不要求是准确数字,只是告诉内核,计划监听多少个fd。实际通过epoll_ctl添加的fd数目可能大于这个值。
- int epoll_create(int size);
//将一个fd增/删/改到epfd里,对应的事件也即读/写
- int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
其中的maxevents也是可以自定义的。假如有100个fd,而maxevents只设置为64,则其他fd上面的事件会在下次调用epoll_wait时返回
- int epoll_wait(int epfd,struct epoll_event * events, int maxevents, int timeout);
IO多路复用伪代码
整个epoll的过程分成三个步骤:
(1)事件注册。通过函数epoll_ctl实现。
对于服务器而言,是accept、 read、 write三种事件;
对于客户端而言,是connect、read. write三种事件。
(2)轮询这三个事件是否就绪。通过函数epoll_wait实现。有事件发生,该函数返回。
(3)事件就绪,执行实际的IO操作。通过函数accept/read/write实现。
这里要特别解释一下什么是“事件就绪”:
- read事件就绪:这个很好理解,是远程有新数据来了,socket读取缓存区里有数据,需要调用read函数处理。
- write事件就绪:是指本地的socket写缓冲区是否可写。如果写缓冲区没有满,则一直是可写的,write事件一直是就绪的,可以调用write函数。只有当遇到发送大文件的场景,socket写缓冲区被占满时,write事件才不是就绪状态。
- accept事件就绪:有新的连接进入,需要调用accept函数处理。
更进一步: epoll分为LT和ET模式
epoll里面有两种模式:LT(水平触发)和ET(边缘触发)。水平触发又称条件触发,边缘触发又称状态触发。
水平触发:读缓冲区只要不为空,就会一直触发读事件;写缓冲区只要不满,就会一直触发写事件。
边缘触发:读缓冲区的状态,从空转为非空的时候触发一次(可读)写缓冲区的状态,从满转为非满的时候触发一次(可写)
比如用户发送一个大文件,把写缓存区塞满了,之后缓存区可以写了,就会发生一次从满到不满的切换。
关于LT和ET,有两个要注意的问题:
1)对于LT模式,要避免“写的死循环”问题:写缓冲区为满的概率很小,所以当用户注册了写事件却没有数据要写时,它会一直触发,因此在LT模式下写完数据一定要取消写事件。
2)对于ET模式,要避免“short read”问题:例如用户收到100个字节,它触发1次,但用户只读到了50个字节,剩下的50个字节不读,它也不会再次触发。因此在ET模式下,一定要把“读缓冲区”的数据一次性读完。
在实际开发中,大家一般都倾向于用LT,这也是默认的模式,Java NIO用的也是epoll的LT模式。因为ET容易漏事件,一次触发如果没有处理好,就没有第二次机会了。虽然LT重复触发可能有少许的性能损耗,但代码写起来更安全。
上层网络框架封装的网络lO模型
c++的 asio
aiso的”异步",是”真异步”,还是“假异步”?
Linux系统上封装的是epoll,不算真异步,只是IO多路复用
在Windows系统上封装的是IOCP,是真异步。
| Java NIO | epoll | |
|---|---|---|
| 注册 | channel.register(selector,xxx) selectorKey.interOps=xxx | epoll_ctr(...) |
| 轮询 | selector.poll() | epoll_wait(...) |
| 实际IO操作 | channel.accept channel.read channel.write | accept read write |
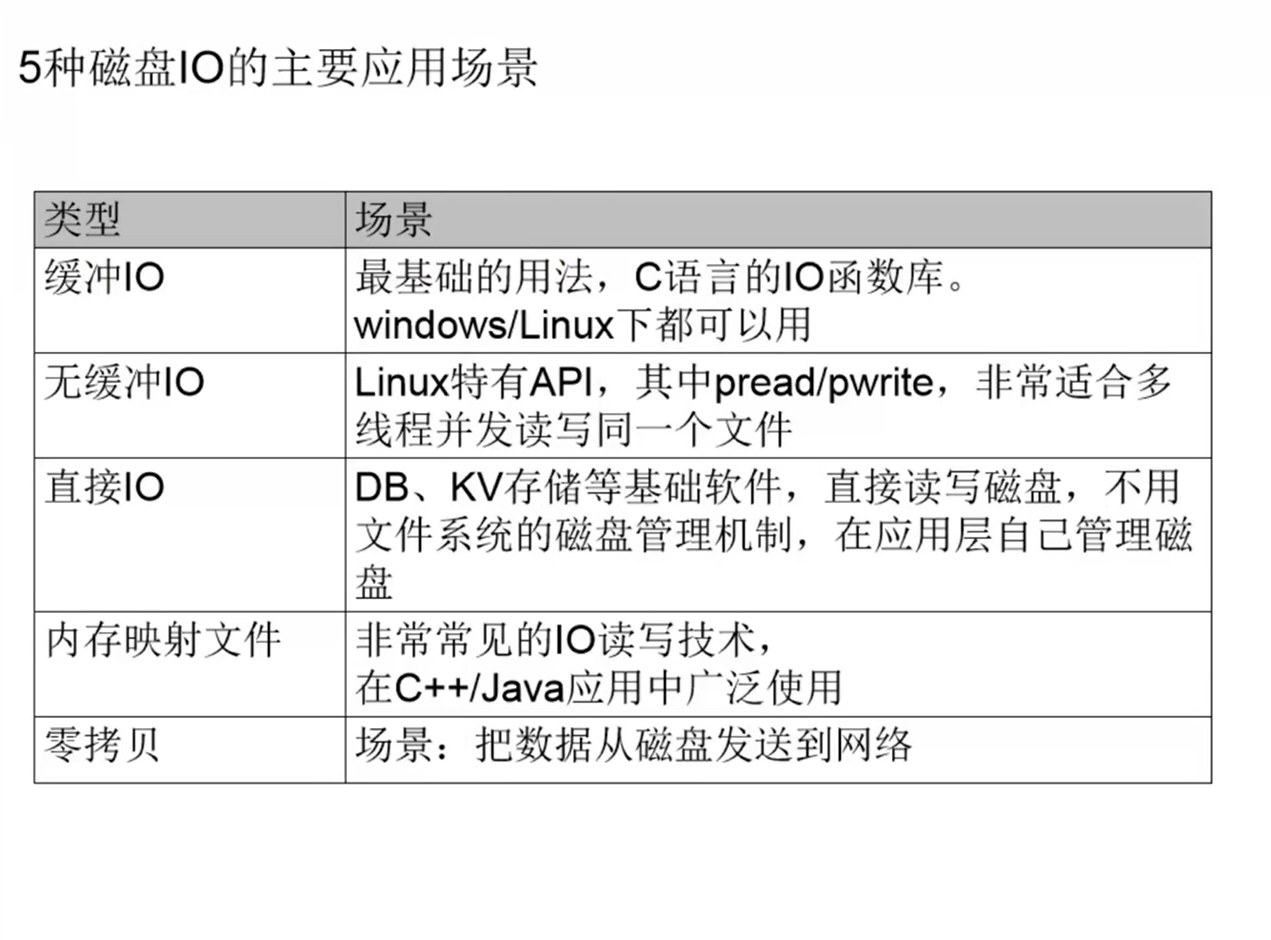
2个网络IO的设计模式
无论操作系统的网络IO模型的设计,还是上层网络框架的网络IO模型的设计,用的都是这两种设计模式之一。
(1)Reactor模式。主动模式,是指应用程序不断地轮询,询问操作系统或者网络框架、IO是否就绪。
Linux系统下的select/poll/epoll,Java中的NIO都属于这种模式。在这种模式下,实际的I/O操作还是应用程序执行的。
(2) Proactor模式。被动模式。应用程序把read和write函数操作全部交给操作系统或者网络框架,实际的I/O操作由操作系统或网络框架完成,之后再回调应用程序。asio库就是典型的Proactor模式。
应用程序的网络lO与线程模型
理解了操作系统、网络框架之后,应用程序(服务器端)怎么编写?
2个方面:
1.网络IO模型
2.线程模型
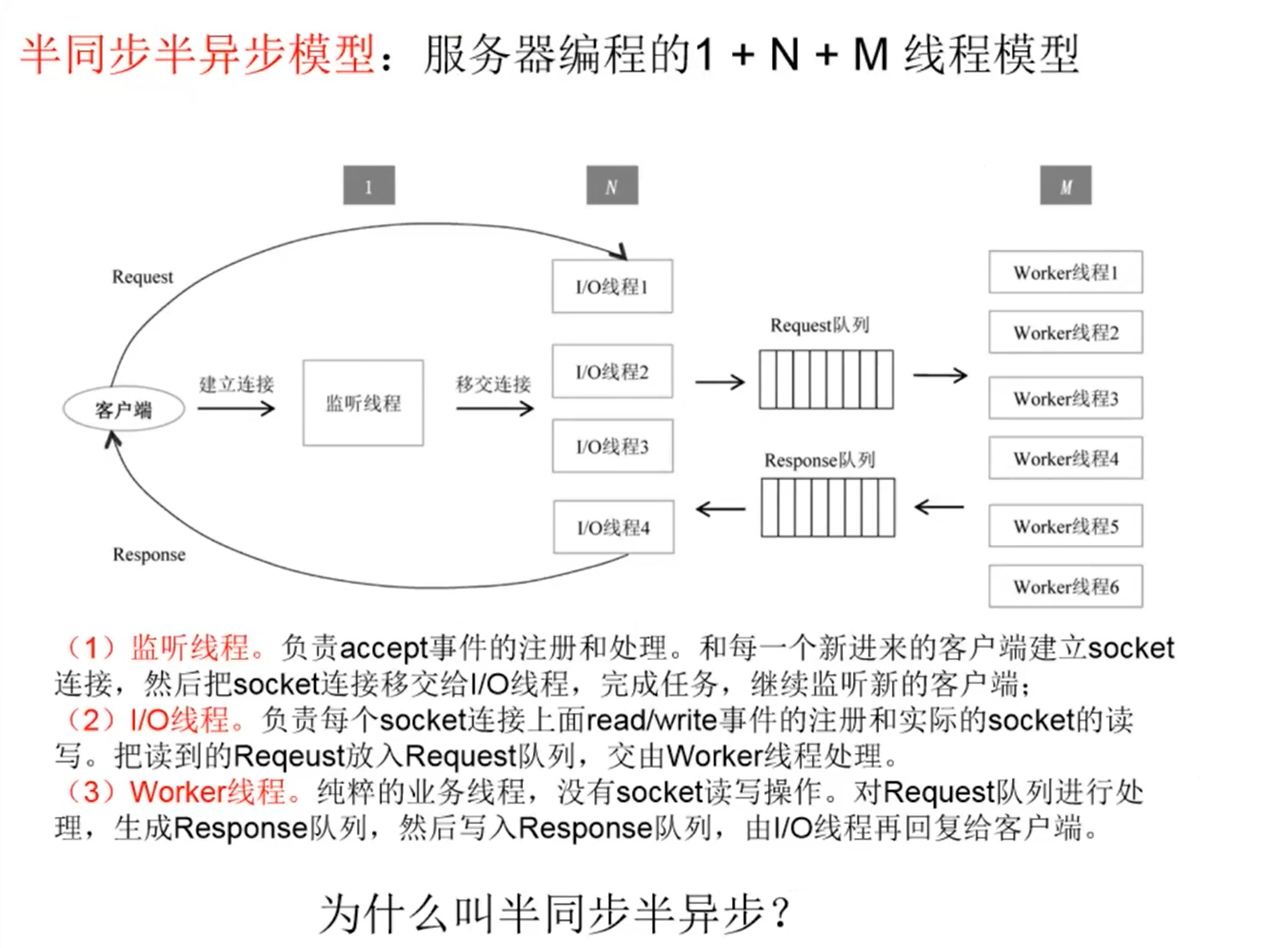
上述模型的N、M取值分别多大合适?
N:CPU核数
M: IO密集型 vs.CPU密集型?
M= CPU核数l[(CPU时间)/ (CPU时间+IO时间)]
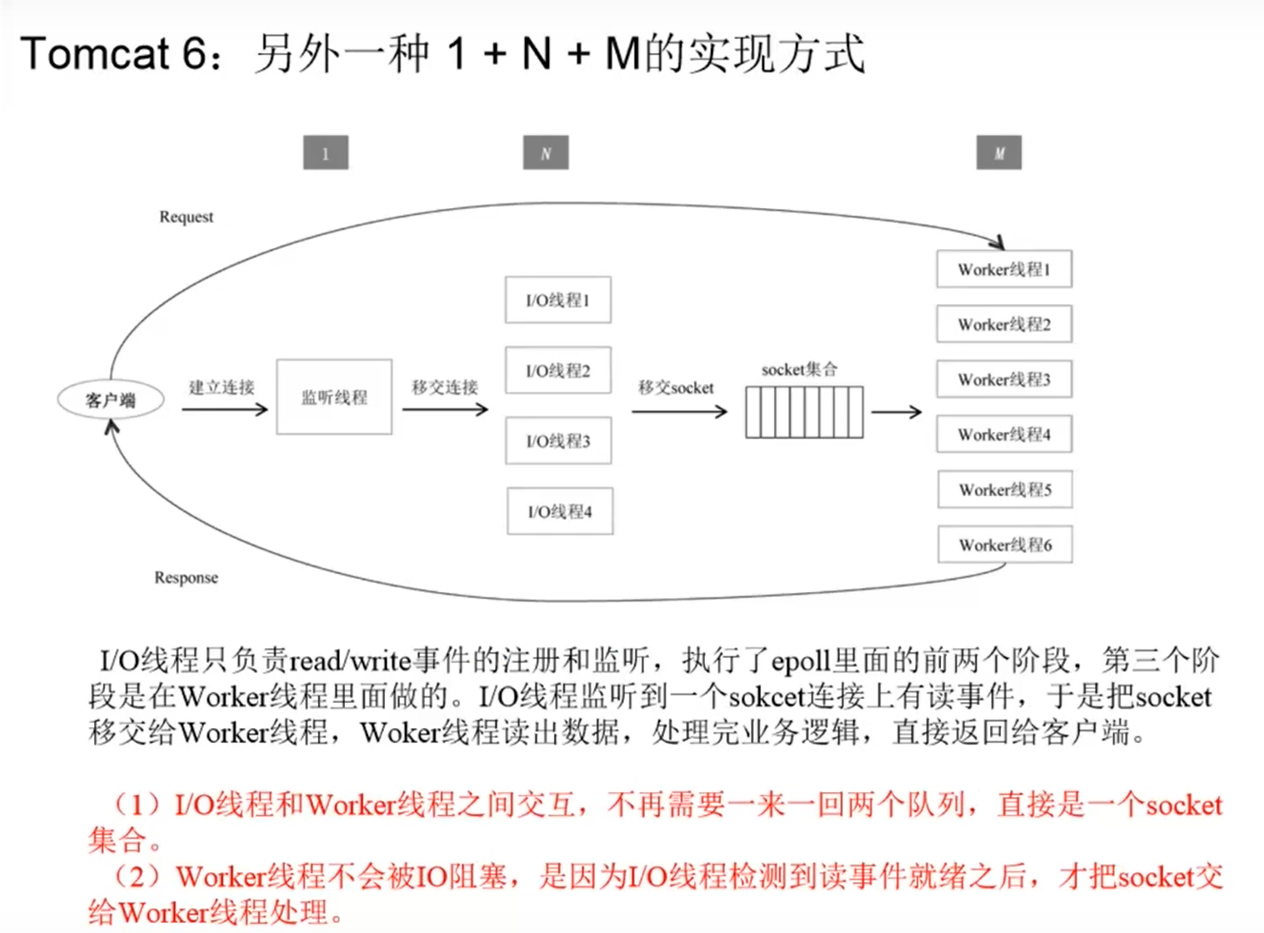
Java Netty框架
不需要应用程序自己开线程池了,Netty框架内部已经把1,N,M 3个对应的线程池准备好了。
C++/Java/Go中的进程、线程、协程支持
多线程对应的API
c/c++:
语言本身没有多线程机制,需要利用操作系统API实现多线程pthread库: pthread_create, pthread_mutex_init,...
Java:
语言本身有多线程支持: synchronized,Thread/Runnable,Java Concurrent Util库
为什么要多线程
之所以要开多线程,是因为服务器的程序往往是I/O密集型的应用。举个极端的例子,假设程序没有任何IO(磁盘IO或网络IO),纯粹的CPU计算,如同一个最简单的、空的死循环,只需要一个线程就可以把一个CPU的核占满。
所以,多线程主要是为了应对IO密集型的应用。多线程能带来两方面的好处:(1)提高CPU利用率。通俗地讲,不能让CPU空闲着。当一个线程发生IO时,
会把该线程
从CPU上调度下来,并把其他的线程调度上去,继续计算。
(2)提高I/O吞吐。典型的场景是,应用程序连接的Redis或者MySQL,它们提供的都是同步接口,一次只能处理一个请求。要想并发,办法是通过连接池和多线程,实现每个线程使用一个连接。好比在客户端和服务器之间开了多条通道,并行传输数据。
为什么要多进程
1.多进程主要用在C/C++开发中,利用Linux原生的多进程通信机制
lPC
(Interprocess Communication)来实现,比如共享内存、管道...
在Java中全是单进程-多线程程序。
备注:开多个进程,通过本地socket通信,这个不算是"多进程“程序,而是相当于多台机器(多个进程)的分布式系统。
2.随着云原生的兴起,“多进程程序"越来越少,除非特别必要的场景,比如Agent,ServiceMesh
通过共享内存通信的多进程程序,需要多个容器之间共享内存通信,部署麻烦
能用多进程解决的问题,往往都可以多线程解决
3.那为什么以前做C/C++开发,经常用多进程?
为了简单,把1个机器的多个核当成多台机器,每个核上一个进程,
彼此之间
独立不通信,省去了多线程之间复杂的通信、同步机制
协程比较新,并不是所有语言都有
1.C/C++
原生没有协程支持,需要上层应用自己实现,
以前在C/C++里面用协程的非常少,现在逐渐增多。·微信开源的协程库libco (需要用到汇编语言)
百度开源的brpc里面的bthread
boost::fiber
2.Java
以前原生的JDK也不支持,目前在逐步支持,并不完全成熟. Quasar
.Loom
备注:Java里面已经有一套非常早、完善的多线程的库JUC,用协程动力不足
3.Go
原生支持多协程,这也是Go越来越火的原因之一:很容易写出高并发的服务器程序
为什么大家都热衷用协程?
1.并发度更高
一台机器,多线程通常开几百个,因为线程切换的开销大而如果是协程,能开几千/几万个
2.代码可读性–用同步代码写出异步程序
用多线程就涉及到异步编程,异步编程的典型模式: callback
callback很容易产生callback hell(回调地狱),回调里面嵌套回调代码可读性、程序调试,都很麻烦
为了让异步编程更简便,Java里面有了Future,但还是不够直观。
协程区别于线程/进程的核心特征
1.线程/进程的调度都是由操作系统决定的,应用程序干预不了。
操作系统决定:某个进程/线程调入某个CPU执行,某个进程/线程从某个CPU调出的时间点:时间片用完,IO等待,线程锁,sleep函数..
协程的调度由应用程序自己控制,应用程序决定某个协程放弃cpu,某个协程占用cpu
2.协程因为是应用程序层面的概念,操作系统并不感知。所以协程的底层,还是依赖多个线程来执行。
M:N模型:M个协程,跑在N个固定的线程上面。
__EOF__

本文链接:https://www.cnblogs.com/LiPengFeiii/p/15946788.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)