MapReduce编程之Map Join多种应用场景与使用
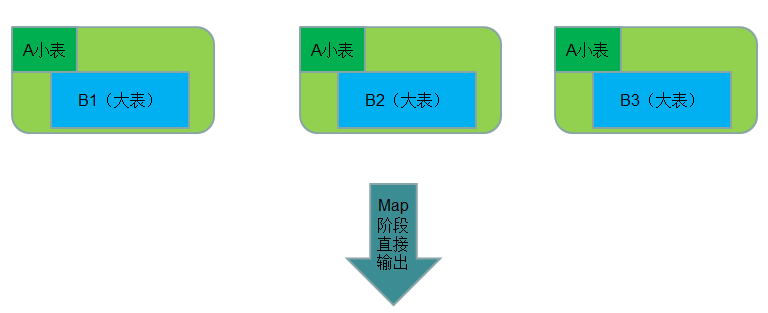
Map Join 实现方式一:分布式缓存
● 使用场景:一张表十分小、一张表很大。
● 用法:
在提交作业的时候先将小表文件放到该作业的DistributedCache中,然后从DistributeCache中取出该小表进行join (比如放到Hash Map等等容器中)。然后扫描大表,看大表中的每条记录的join key /value值是否能够在内存中找到相同join key的记录,如果有则直接输出结果。
DistributedCache是分布式缓存的一种实现,它在整个MapReduce框架中起着相当重要的作用,他可以支撑我们写一些相当复杂高效的分布式程序。说回到这里,JobTracker在作业启动之前会获取到DistributedCache的资源uri列表,并将对应的文件分发到各个涉及到该作业的任务的TaskTracker上。另外,关于DistributedCache和作业的关系,比如权限、存储路径区分、public和private等属性。
代码实现


package com.hadoop.reducejoin.test; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStreamReader; import java.net.URI; import java.util.Hashtable; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.Reducer.Context; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /* * 通过分布式缓存实现 map join * 适用场景:一个小表,一个大表 */ public class MapJoinByDistributedCache extends Configured implements Tool { /* * 直接在map 端进行join合并 */ public static class MapJoinMapper extends Mapper<LongWritable, Text, Text, Text> { private Hashtable<String, String> table = new Hashtable<String, String>();// 定义Hashtable存放缓存数据 /** * 获取分布式缓存文件 */ @SuppressWarnings("deprecation") protected void setup(Context context) throws IOException, InterruptedException { Path[] localPaths = (Path[]) context.getLocalCacheFiles();// 返回本地文件路径 if (localPaths.length == 0) { throw new FileNotFoundException( "Distributed cache file not found."); } FileSystem fs = FileSystem.getLocal(context.getConfiguration());// 获取本地 // FileSystem // 实例 FSDataInputStream in = null; in = fs.open(new Path(localPaths[0].toString()));// 打开输入流 BufferedReader br = new BufferedReader(new InputStreamReader(in));// 创建BufferedReader读取器 String infoAddr = null; while (null != (infoAddr = br.readLine())) {// 按行读取并解析气象站数据 String[] records = infoAddr.split("\t"); table.put(records[0], records[1]);// key为stationID,value为stationName } } public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] valueItems = line.split("\\s+"); // 使用下面一行将没有数据, StringUtils不能接正则,只能接分隔符 // String[] valueItems = StringUtils.split(value.toString(), "\\s+"); String stationName = table.get(valueItems[0]);// 天气记录根据stationId // 获取stationName if (null != stationName) context.write(new Text(stationName), value); } } public int run(String[] args) throws Exception { // TODO Auto-generated method stub Configuration conf = new Configuration(); Path out = new Path(args[2]); FileSystem hdfs = out.getFileSystem(conf);// 创建输出路径 if (hdfs.isDirectory(out)) { hdfs.delete(out, true); } Job job = Job.getInstance();// 获取一个job实例 job.setJarByClass(MapJoinByDistributedCache.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[2])); // 添加分布式缓存文件 station.txt job.addCacheFile(new URI(args[1])); job.setMapperClass(MapJoinMapper.class); job.setOutputKeyClass(Text.class);// 输出key类型 job.setOutputValueClass(Text.class);// 输出value类型 return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args0) throws Exception { String[] args = { "hdfs://sparks:9000/middle/reduceJoin/records.txt", "hdfs://sparks:9000/middle/reduceJoin/station.txt", "hdfs://sparks:9000/middle/reduceJoin/MapJoinByDistributedCache-out" }; int ec = ToolRunner.run(new Configuration(), new MapJoinByDistributedCache(), args); System.exit(ec); } }
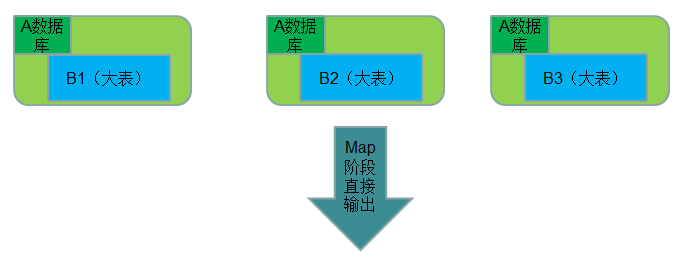
Map Join 实现方式二:数据库 join
● 使用场景:一张表在数据库、一张表很大。
另外还有一种比较变态的Map Join方式,就是结合HBase来做Map Join操作。这种方式完全可以突破内存的控制,使你毫无忌惮的使用Map Join,而且效率也非常不错。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号