
make_classification函数
sklearn.datasets.make_classification
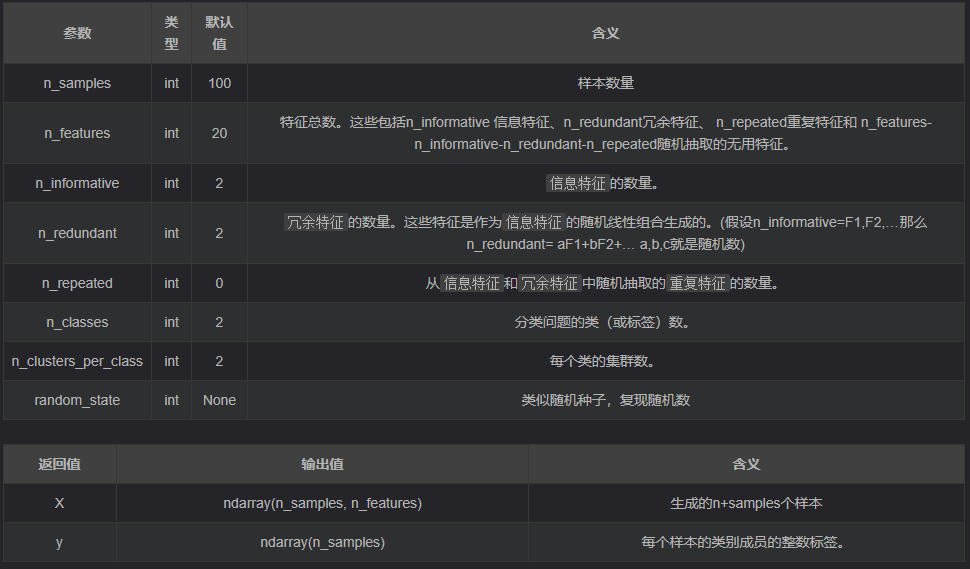
sklearn.datasets.make_classification(n_samples=100, n_features=20, *, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None)
生成一个随机的 n nn 类分类问题。
在不打乱的情况下,X按以下顺序水平堆叠特征:主要n_informative特征,然后n_redundant 是信息特征的线性组合,然后是n_repeated 重复,随机抽取信息和冗余特征的替换。其余特征充满随机噪声。因此,无需改组,所有有用的特征都包含在列中 。X[:, :n_informative + n_redundant + n_repeated]
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=6, n_classes=2, n_features=5, n_informative=5,n_redundant=0,n_clusters_per_class=1)
display(X,y)
"""
n_samples=6 - 6行6个数据
n_classes=2 - 结果分为2类即二分类
n_features=5 - 5个特征
n_informative=5 - 5个全部有效的特征
n_redundant=0 - 冗余特征为0
n_clusters_per_class=1 - 每一个类别聚为一个簇
array([[ 1.10885456, -1.97464085, 2.14372944, -0.08241471, -2.60173628],
[ 0.98456921, -4.67257395, -0.10161149, 0.52329866, 2.0178222 ],
[-2.92441307, -2.20249011, 0.12827954, 1.90711152, 0.24340137],
[ 0.14524134, -1.42685331, 1.92731161, -0.72915701, 1.3529692 ],
[-0.09694719, -0.28604481, -2.62609999, -0.46131174, 0.72515074],
[ 0.25540393, -2.64589841, -2.05721611, 0.53203936, 0.34273113]])
array([0, 1, 1, 0, 1, 0])
"""
同时参考这链接中的不平衡数据部分,以及代码部分的crossvalidate()
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_validate
classifier = RandomForestClassifier()
scores = cross_validate(
classifier, X, y, cv=10,
scoring=['accuracy', 'precision', 'recall', 'f1','r2', 'neg_mean_squared_error']
)
scores = pd.DataFrame(scores)
scores.mean()
#output
fit_time 0.296672
score_time 0.011580
test_accuracy 0.911000
test_precision 0.920261
test_recall 0.904000
test_f1 0.910236
test_r2 0.644000
test_neg_mean_squared_error -0.089000
dtype: float64


 浙公网安备 33010602011771号
浙公网安备 33010602011771号