
第2期 分布迁移下的深度学习时间序列异常检测方法探究 2021-09-22
2021-09-22



Gartner曲线:https://baijiahao.baidu.com/s?id=1741660322658337733&wfr=spider&for=pc
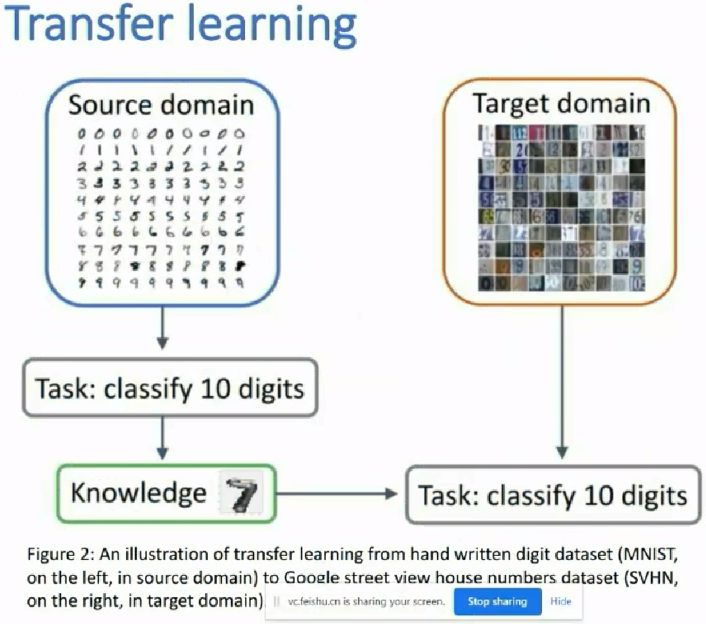
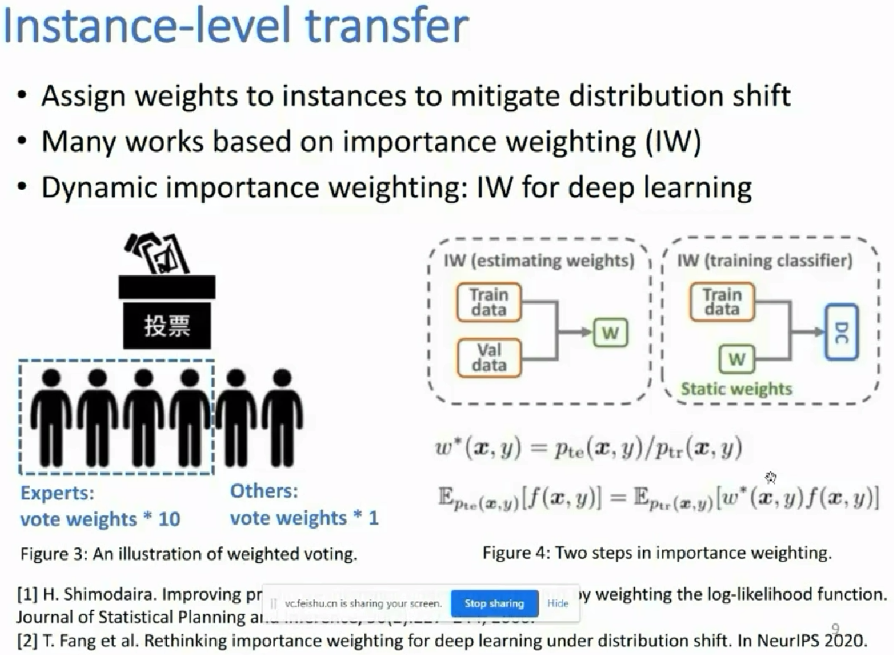
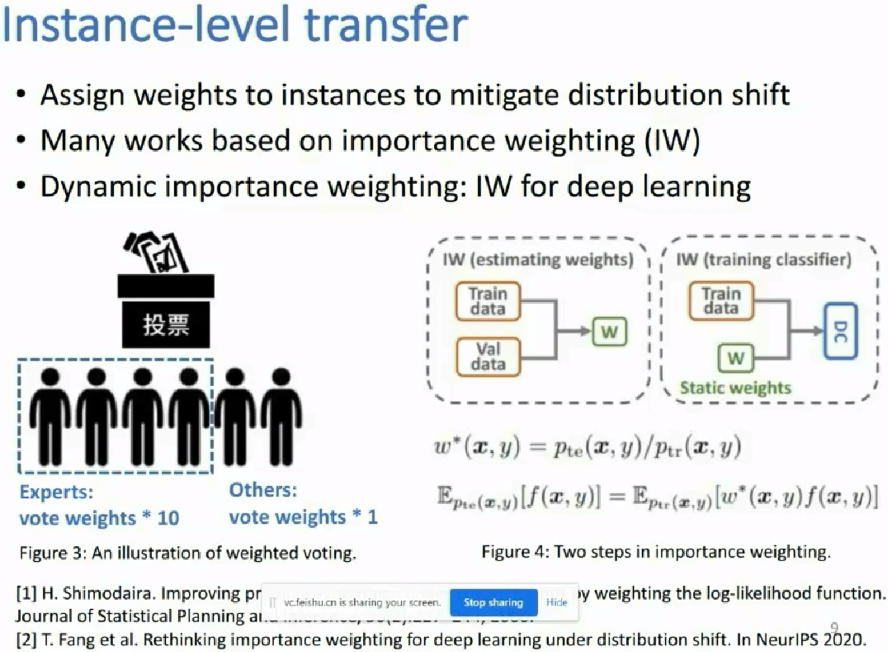
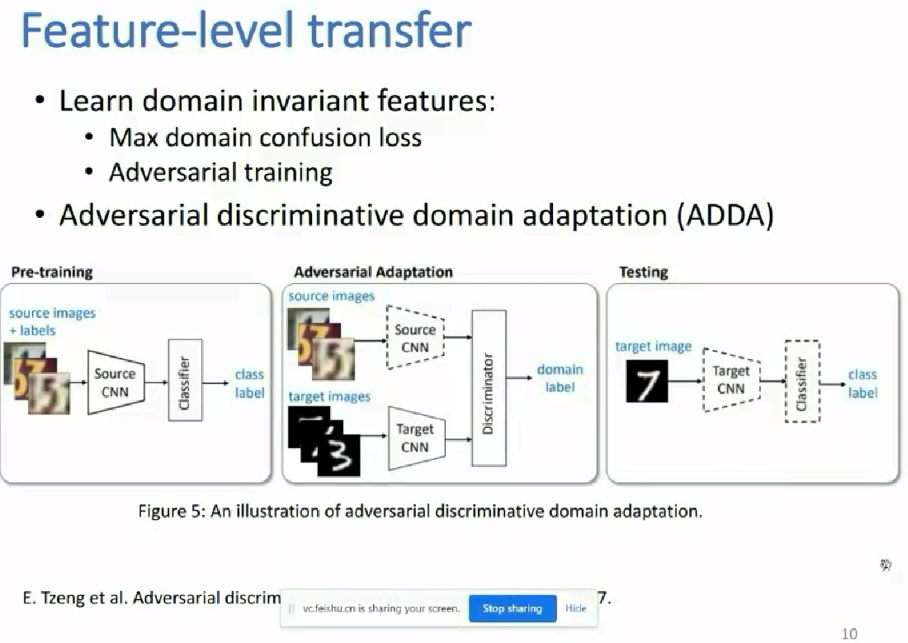
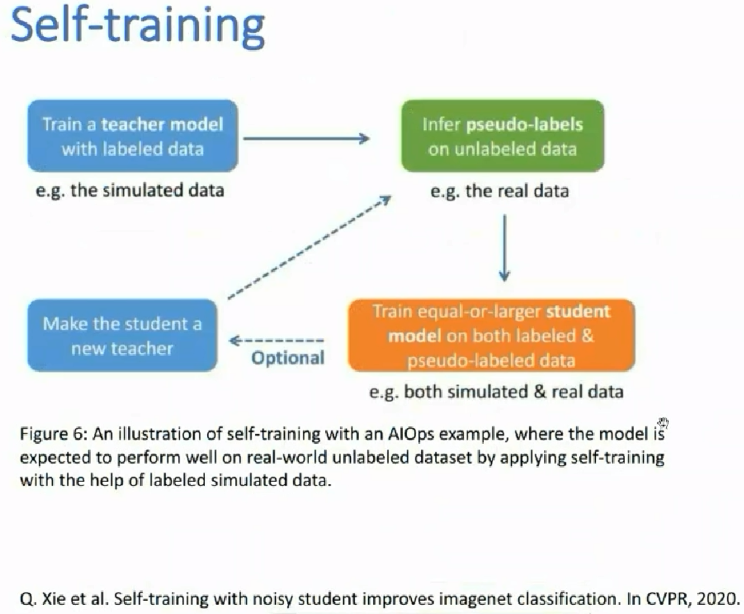
source domain A中是有标签的数据;而target domain B中是没标签的数据,那么如何用好?某作者这样用:先在A中训练好一个模型M1,再在B中应用模型,使得B中的数据有伪标签;让后再把A和有伪标签的B数据集放一块后,再训练一个模型M2;


上图:随着数据量的增加,传统的机器学习算法的性能/效果就到了一个瓶颈,其效果就涨不起来了。而深度学习仍旧可以持续提升性能。
不仅数据量大,数据的形式、结构都变得比较复杂。深度学习就在当下的环境中迅速崛起,取得了非常好的效果。
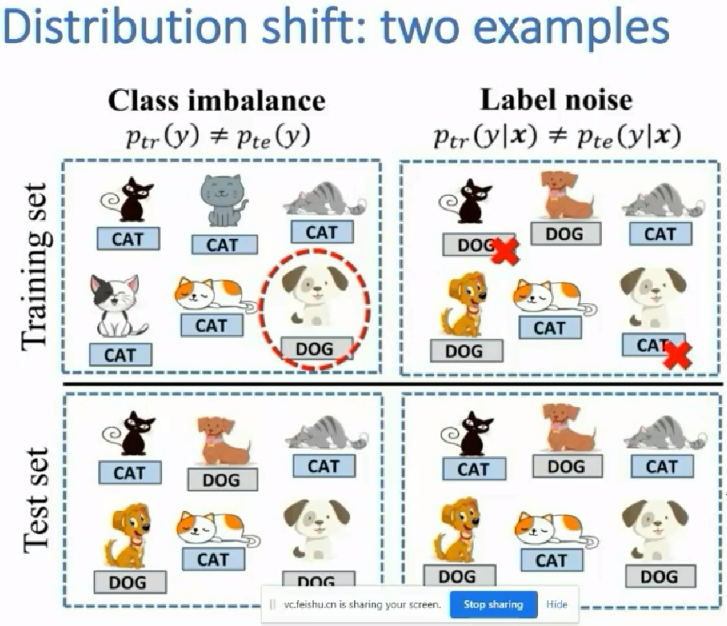
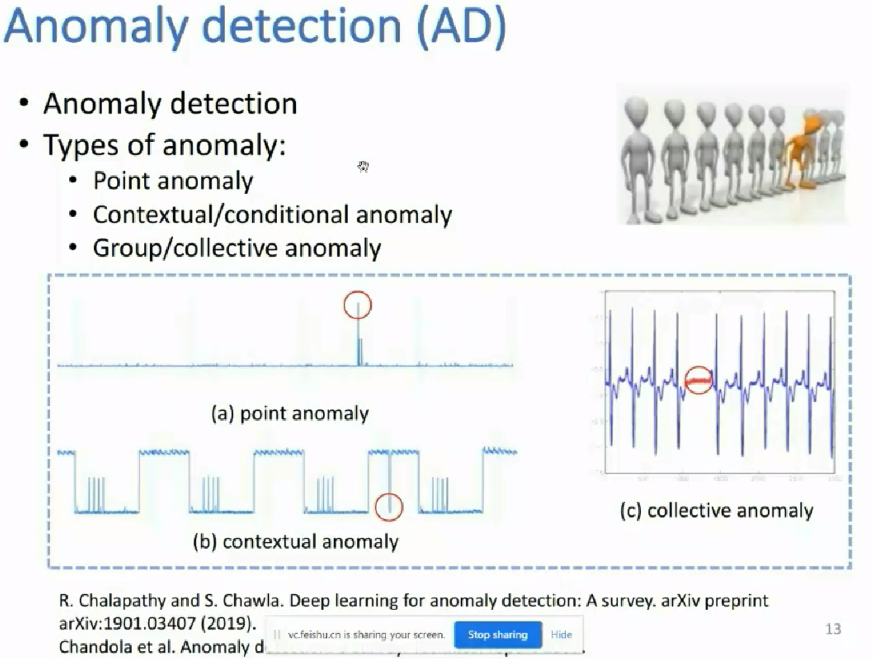
此外学术上认为异常发生的概率非常小,小到近似于没有异常。所以学术上的很多研究都是假设在训练集总没有异常,测试集中可能有异常,且测试集中的异常数据可能用到也可能用不到我们的算法设计里面。
学术上的类别不平滑问题可能更符合我们的应用实际;也即我们的训练和测试数据集中同时包含着正常和异常的数据,或者说训练和测试数据集的分布是一样的。
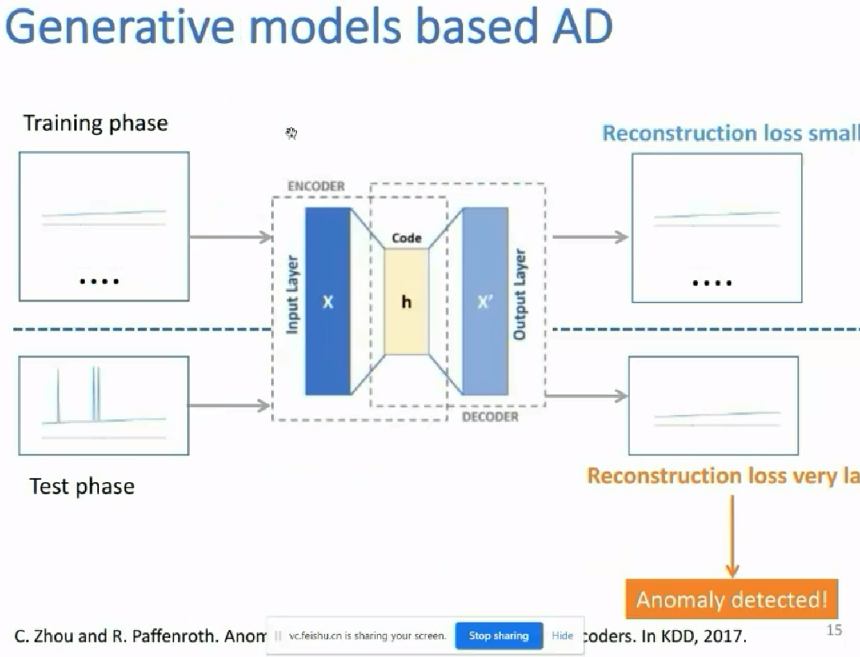
当把一个异常的数据放入自编码器(编码解码器)中的时候,因为自编码器(编码解码器)学的是之前的正常的东西的特征表征,所以很可能编码解码器,会把这个异常的数据给表征成正常的;相当于把异常的数据重建为了一个正常的数据;所以重建的loss比较大,当某个loss超过某个阈值时,我们就认为其是异常的数据;阈值是设定的;

上图是根据one-class classification做的一个样例,这里同样假设在训练数据中的数据都是正常的,异常数据只可能出现在test数据集中。其基本思想是学得一个最小超球面,使得这个最小超球面能包含住所有的正常的训练数据。
其中上图中,最左边的是原始数据,最右边是特征空间;上图中间是用神经网络做的一个非线性变换,使得能把左边的原始数据映射成右边的特征空间超球面;以使得能在特征空间中学到一个比较好的最小超球面;能包括所有的训练数据(正常数据)。
建立超球面后,当在测试阶段时,可以对新来的数据计算其到超球面球心的距离,当距离大于超球面的半径或某个设定的阈值时,就认为这个新来的数据是个异常数据。
上图上述的这个思路大致类似于上上图中的生成模型的思路,大致都是先学得正常数据的某些特征等,当测试阶段有异常数据进来时,异常数据会在某个维度或指标上变得不在正常范围内(很大或很小,此处的例子指很大),进而认为这个数据是异常。

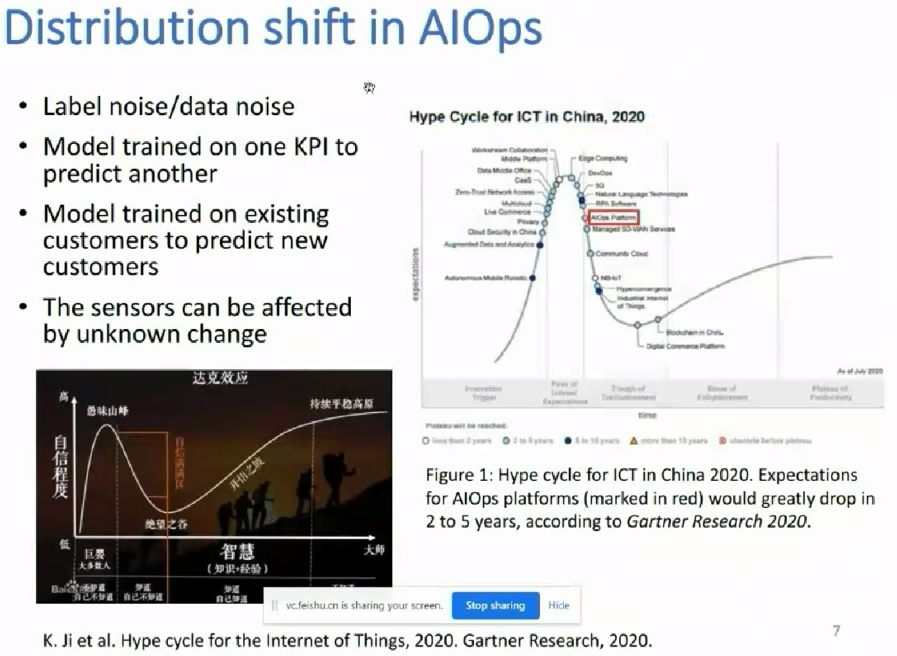
基于深度学习的异常检测遇到一个分布迁移的问题的时候,可能的一些研究的思路。

比如说对source domain中的时间序列数据,先进行一些预处理,同时对于target domain (其是没有标签的)中的数据也进行一些处理;在对source 数据预处理后,要对其进行深度学习异常检测的算法进行检测,当在source数据的结果比较好的情况下,载使用domain adaptation领域自适应方法,把源域的知识迁移到目标域中。这是个基本的而思路。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号