python MLPRegressor神经网络回归预测
参数说明:
-
batch参数用来指定mini-batch sgd优化器的样本批量大小,默认值为200(如样本数低于200,则为样本数)。
-
max_iter用来指定神经网络的最大迭代次数,默认值为200。
-
random_state用来指定随机种子,用来控制模型初始权重的随机性。如果给定特定值,重新跑模型的时候,可以得出同样的结果。
-
tol参数用于指定优化器的忍耐度。当损失函数的值的变化小于了忍耐度,便认为训练结束,从而停止训练。默认值为1e-4。
-
momentum参数用于指定随机梯度下降优化器的动量,其值介于0到1之间。该参数仅在优化器为sgd的情形下有效。
-
activation用来指定激活函数。
- activation = identity,使用f(x) = x的激活函数
- activation = logistic,使用f(x) = 1 / (1 + exp(-x))的激活函数,又名sigmoid激活函数。
- activation = tanh,使用双曲正切激活函数。
- activation = relu,使用整流线性单元激活函数。(默认值)
-
solver用来指定优化器。
- solver = lbfgs,使用拟牛顿法作为优化器。
- solver = sgd,使用随机梯度下降优化器。
- solver = adam,使用adam优化器。(默认值)
-
learning_rate参数用来指定学习率的模式。
- learning_rate = constant,即使用常数作为学习率。用learning_rate_init参数来设置其值。(默认值)
- learning_rate = invscaling,使用一种逐渐自动下降的学习率。在训练的第t步,学习率会变为learning_rate_init / pow(t, power_t)。其中power_t可以手动设定,其默认值为0.5。
- learning_rate = adaptive,使用自适应的学习率,当误差函数变化很小时,就会降低学习率。
-
learning_rate_init 用来指定学习率,默认值为0.001。
-
hidden_layer_sizes用于指定网络架构,输入形式为元组,元组长度表示架构的层数,元组第i个数表示第i层的神经元个数。例如hidden_layer_sizes = “512-512-64”表示该多层感知机会用三个隐藏层,神经元数量分别为512,512,64。
默认值为100,表示只用一个100个神经元的隐藏层。 -
power_t。该参数仅当learning_rate = invscaling时有效,其作用见learning_rate参数下invscaling取值时的说明。默认值为0.5。
'''载入数据'''
from sklearn import datasets
import sklearn
boston = datasets.load_boston()
x,y = boston.data,boston.target
'''引入标准化函数'''
from sklearn import preprocessing
x_MinMax = preprocessing.MinMaxScaler()
y_MinMax = preprocessing.MinMaxScaler()
''' 将 y 转换成 列 '''
import numpy as np
y = np.array(y).reshape(len(y),1)
'''标准化'''
x = x_MinMax.fit_transform(x)
y = y_MinMax.fit_transform(y)
''' 按二八原则划分训练集和测试集 '''
from sklearn.model_selection import train_test_split
np.random.seed(2019)
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size = 0.2)
'''模型构建'''
from sklearn.neural_network import MLPRegressor
fit1 = MLPRegressor(
hidden_layer_sizes=(100,50), activation='relu',solver='adam',# 第一个隐藏层有100个节点,第二层有50个,激活函数用relu,梯度下降方法用adam
alpha=0.01,max_iter=200)
# 惩罚系数为0.01,最大迭代次数为200
print ("fitting model right now")
fit1.fit(x_train,y_train)
pred1_train = fit1.predict(x_train)
'''计算训练集 MSE'''
from sklearn.metrics import mean_squared_error
mse_1 = mean_squared_error(pred1_train,y_train)
print ("Train ERROR = ", mse_1)
'''计算测试集mse'''
pred1_test = fit1.predict(x_test)
mse_2 = mean_squared_error(pred1_test,y_test)
print ("Test ERROR = ", mse_2)
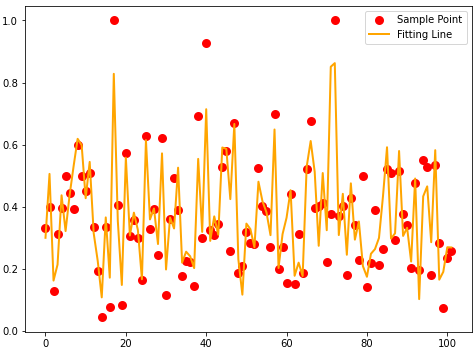
'''结果可视化'''
import matplotlib.pyplot as plt
xx=range(0,len(y_test))
plt.figure(figsize=(8,6))
plt.scatter(xx,y_test,color="red",label="Sample Point",linewidth=3)
plt.plot(xx,pred1_test,color="orange",label="Fitting Line",linewidth=2)
plt.legend()
plt.show()
fitting model right now Train ERROR = 0.00733273144550684 Test ERROR = 0.009604936442639026


 浙公网安备 33010602011771号
浙公网安备 33010602011771号