VGG及其变种
一、背景介绍
VGG全称是Visual Geometry Group,因为是由Oxford的Visual Geometry Group提出的。AlexNet问世之后,很多学者通过改进AlexNet的网络结构来提高自己的准确率,主要有两个方向:小卷积核和多尺度。而VGG的作者们则选择了另外一个方向,即加深网络深度。
二、网络架构
卷积网络的输入是224 * 224的RGB图像,整个网络的组成是非常格式化的,基本上都用的是3 * 3的卷积核以及 2 * 2的max pooling,少部分网络加入了1 * 1的卷积核。因为想要体现出“上下左右中”的概念,3*3的卷积核已经是最小的尺寸了。
解释两个关键问题:
1. 作者用的是多个3 * 3卷积叠加,而不是例如7 * 7、11 * 11的单个卷积,原因如下:
3个3 * 3卷积叠加得到的理论感受野和一个7 * 7卷积的理论感受野是相同的。详细解释可以参考 深度学习面试题-感受野
因为每个卷积层后面都会跟着一个ReLU,3个3 * 3卷积就会有3个ReLU,但是一个7 * 7卷积只有一个,所以这么做可以使得模型的非线性拟合能力更强。
减少了参数数量。假设3个3*3卷积的输入和输出都是C个通道,那么参数数量为3 ( 3 ∗ 3 ∗ C ∗ C ) = 27 C 2,而7 * 7卷积的参数数量为7 ∗ 7 ∗ C ∗ C = 49 C 2 。
1 * 1卷积的作用是什么?
为了在不影响卷积层感受野的前提下,增加模型的非线性。融合各通道的信息。
1*1卷积也即你的卷积核的高和宽都等于1,也即它不会识别你的空间信息,因为它每一次只看一个像素,而不会看这个像素的周围,所以它不会给你识别出你这个通道里面它的空间的模式是什么样的;它的作用就是给你融合你的不同通道的信息;不做空间的匹配,只做在(输入层)输入的通道和输出的通道之间做融合;
调整网络维度,如mobilenet使用1 * 1卷积核来扩维,resnet用其降维。不过这一条不是vgg提出的。
下图是VGG16的网络架构:
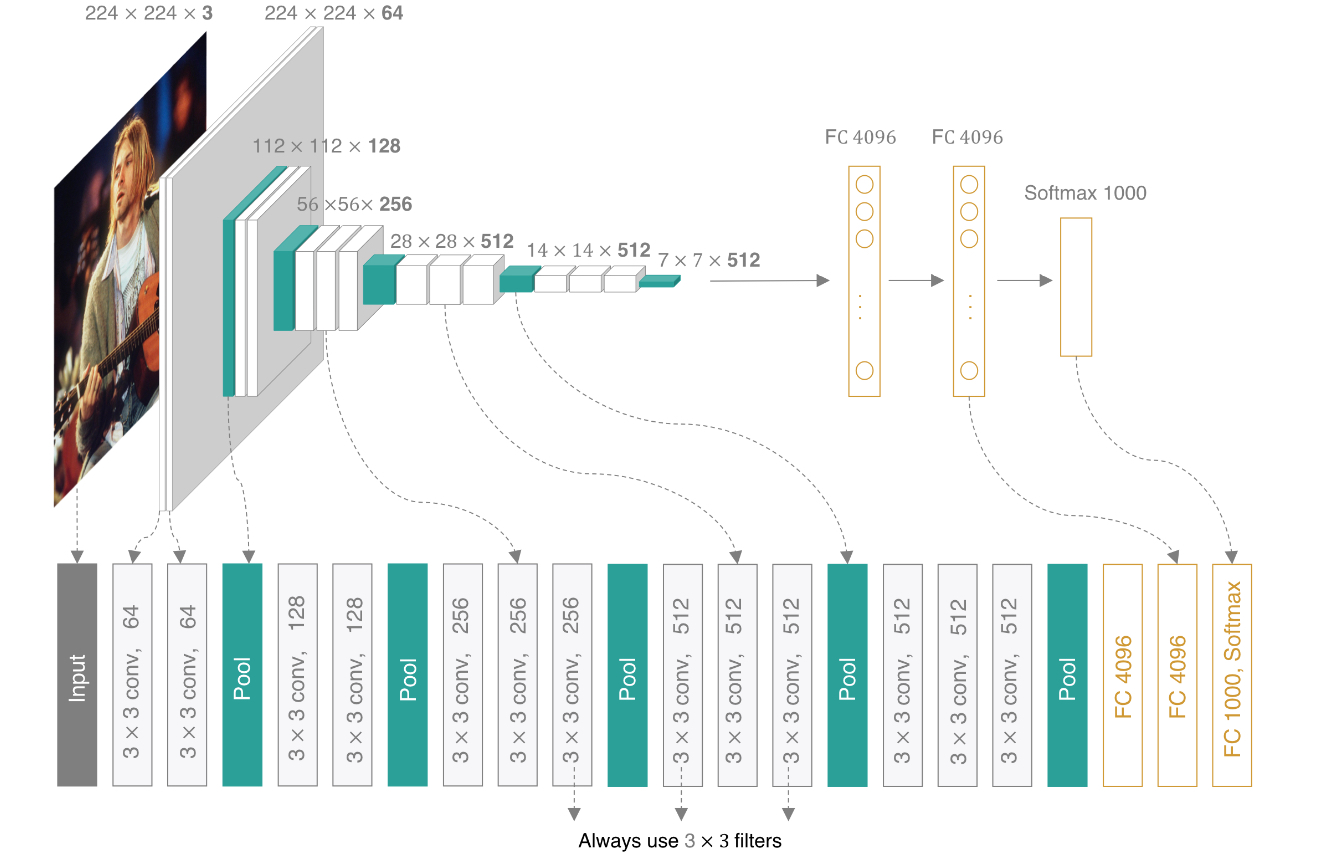
三、对比实验
首先放上作者用来做对比实验的六组网络。
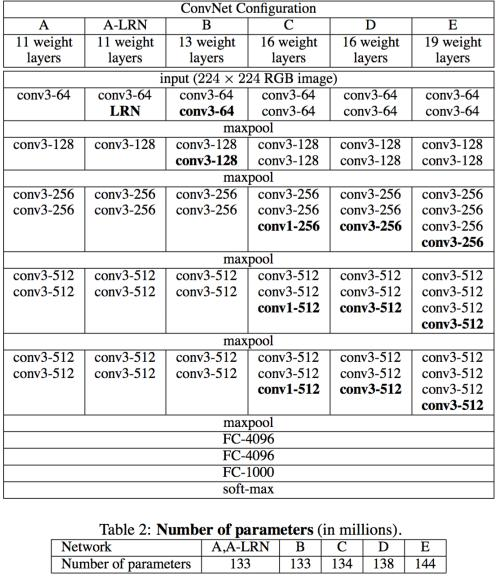
简单介绍一下各组的区别:
A:没啥特别的。
A-LRN:加了LRN,这是AlexNet里提出来的,不需要怎么了解,基本很少使用了。
B:加了两个卷积层。
C: 进一步叠加了3个卷积层,但是加的是1 * 1的kernel。
D:将C中1 * 1的卷积核替换成了3 * 3的,即VGG16。
E:在D的基础上进一步叠加了3个3*3卷积层,即VGG19。
3.1 Single-Scale Evalution
首先说明一下训练集里图像短边长度S的设置,设置方式分为两种:
固定S:针对单尺寸图片进行训练。

3.2 Multi-Scale Evalution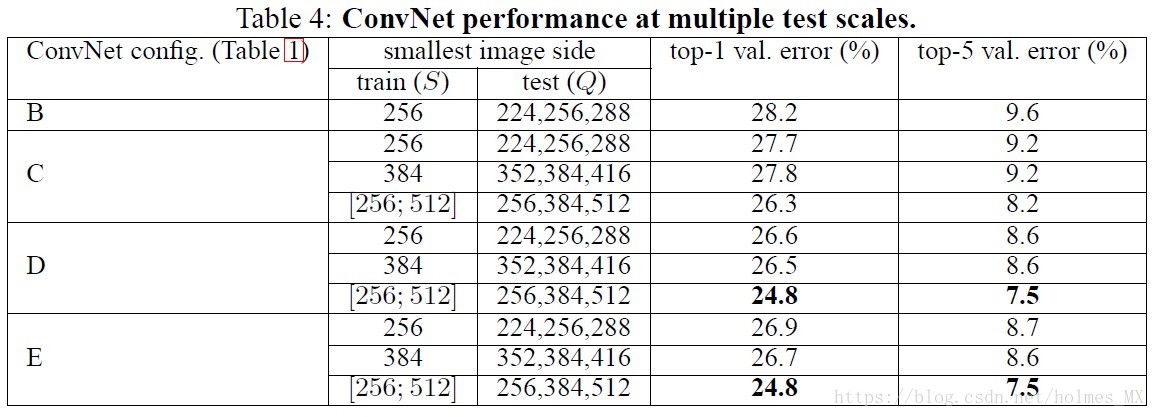
这里Multi-Scale是指采用多个尺寸的测试图像,可以把这个表格和前面Single Scale的表格进行对比,可以发现测试时对测试集的图像采用Scale jittering也可以获得更好的精度。
3.3 Mulit-Crop Evalution
首先解释一下dense evalution和multi-crop:
dense evalution:用卷积层代替全连接层,那么卷积网络就可以接受任意大小的图像作为输入。
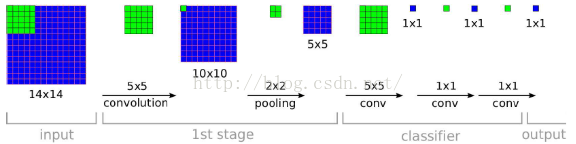
以上图为例,假设输入图片大小是14 * 14,最后输出有C个通道(等同于类别数),经过第一阶段的卷积和池化之后得到了5 * 5的特征图。如果我们用传统的CNN,那么这时候我们需要将特征图展平为一维向量,大小为(1, 25),然后加上一个全连接层(权重w的大小为(25, C)),就可以得到属于各类别的概率。但是我们可以用一个5 * 5的卷积层来代替,得到输出为(1, 1, C),然后降维得到分类概率。
如果将全卷积网络的输入换成16 * 16的图像,结果如下图所示:
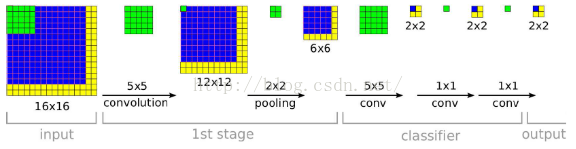
那么最后会得到2 * 2 * C的输出,把每个通道里2 * 2的特征图的每一点相加求平均(sum pooling),就是图片属于某一类别的概率。看不懂的话可以去了解一下FCN。
multi-crop:这一种方式是将测试图片的短边缩放到不同大小Q,然后在Q * Q的图像上裁剪出多个图像,将这些图像作为CNN(没有将全连接转化为卷积)的输入,经过网络计算之后得到每个裁剪图像的分类概率,相加取平均之后作为原始图像的分类概率。按我的理解,这种方式其实和上面的dense很类似,上面输入任意大小的图像,不经过裁剪直接放到卷积层里,卷积核在原图或者特征图上的滑动就好像是在Crop,只是更加密集(dense)。
按照作者的观点,这两种方法的差别在于convolution boundary condition不同:dense由于不限制图片大小,可以利用像素点及其周围像素的信息(来自于卷积和池化),包含了一些上下文信息,增大了感受野,因此提高分类的准确度;而multi-crop由于从图片上裁剪再输网络,需要对图像进行零填充,因此增加了噪声。
实验表明,两种方式结合在一起更好。然而我也不懂怎么把它们结合在一起。
3.4 ConvNet Fushion
这个融合貌似意思是分别跑了各个网络之后,得到各自每张图片的softmax分类概率,然后取平均作为最后的结果,作者说因为不同网络的互补性,所以分类效果有提升。不太清楚这种测试思路在后面提出的网络中应用得怎么样了。
四、补充
4.1 各向同性缩放和各向异性缩放

各向同性缩放:也称为“等比缩放”,图像长边和短边缩放比例相同,这样就不会破坏原图的比例,便于对物体精准定位,对应图中上边的路线。Smin被设置为256,假设短边缩放了2倍到Smin,那么长边也对应缩放两倍。
各向异性缩放:不考虑物体是否会发生形变,直接对图片进行暴力resize,使得图像变为我们想要的尺寸,对应图中下边的路线。如图所示,直接将图片先放缩到256 * 256,发生了肉眼可见的形变。
————————————————
转自:https://blog.csdn.net/disguise666/article/details/105271503
https://blog.csdn.net/weixin_44957722/article/details/119089221
https://zhuanlan.zhihu.com/p/116900199
https://zhuanlan.zhihu.com/p/343747851
https://blog.csdn.net/DreamBro/article/details/121068023
https://zhuanlan.zhihu.com/p/41423739
https://blog.csdn.net/zzq060143/article/details/99442334


 浙公网安备 33010602011771号
浙公网安备 33010602011771号