
浅谈机器学习中的数据漂移问题
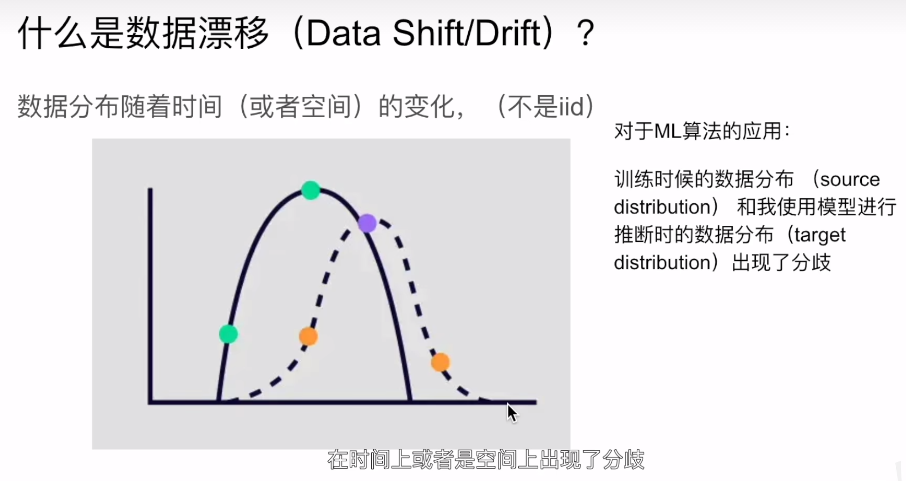
也即在训练的时候的数据和在使用模型进行推断的时候的数据分布式不一样的,二者不是同分布的。

因为很多模型都是在线下训练好的,使用的是线下的参数和损失函数,线上abtest的时候就会发现,在production traffic上的话效果就没那么好了。于是模型在被revert的同时,还会有很多工程师开始熬夜debug;
另外一个是数据变化会使得模型性能上产生变化,性能变化就意味着赚的钱更少了,一个典型表现就是话费了很多人力物力开发的模型,上线后逐渐就不好用了,适应不了新的数据。我们可以使用简单的概率公式解释为何在没有任何的系统bug的情况下,也可能会出现数据漂移的问题。
大家在训练的时候都假设每个样本都是独立同分布,但是在实际运用的时候,往往会出现样本既不独立也不同分布的情况,不独立意味着我们采样本身就有偏差,而不同分布也意味着样本本身的分布也是在不断的变化的,总结一句话就是模型在训练时看到的,Psrc (x,y) != Ptgt (x,y),
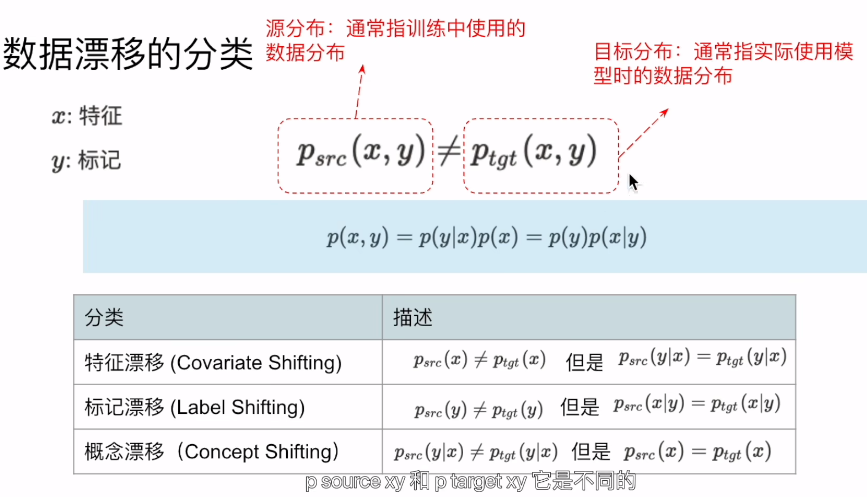
P(x,y)可以分解成P(x,y)=P(y|x)P(x)=P(y)P(x|y)
基本上所有的p(x,y)的变动都叫做data shift,但是依据不同的概率分布的变动呢,我们可以进一步的把data shift分成三种,第一种叫做特征漂移或者协变量漂移,他指的是Psrc(y|x)=Ptgt(x|y)不变的情况下,Psrc(x) != Ptgt(x)。
比如在训练模型时,主要用的是中年人的数据,但是在线上主要服务的用户却是青少年居多。那么模型很可能就没办法得到很好的结果。
而标记漂移(label shift)也经常叫做prior shift,也即y的概率进行的漂移,也即标记进行了漂移。他通常会假设Psrc(x|y)=Ptgt(x|y).


 浙公网安备 33010602011771号
浙公网安备 33010602011771号