
青源Talk第8期|苗旺:因果推断,观察性研究和2021年诺贝尔经济学奖
biobank 英国的基金数据
因果推断和不同的研究互相论证,而非一个研究得到的接了就行。
数据融合,data fusion,同一个因果问题不同数据不同结论,以及历史上的数据,来共同得到更稳健、更高效的推断。敏感性分析(评价假定的方法)。多方验证。统计中的meta analysis荟萃分析。讨论这个做法背后的模型、假定是如何解释这个结果。
敏感性分析(评价假定的方法)。
1.实现你的方法,论证你的方法;
2.论证你的模型、假定,以及解释你的结果。三者缺一不可。单单的方法是不行的。
大规模数据处理面对比较高维的数据时,skrining 作为标准预处理的一个步骤。与其配套的是敏感性分析,敏感性分析就是看你的假定,如果说错了,错到什么程度会影响结论,会得到不一样的结论;二者是配套的,也即你有一个抢的假定,同时也要有一个,评价假定的方法--敏感性分析。
相关的主要目的是为了做预测,只要预测好就行。因果关系母的不一样,因果关系要特别在意解释型;要直到到底哪些因素导致了明天的股票上涨。相关的主要目的是为了做预测,只要预测好就行。因果关系母的不一样,因果关系要特别在意解释型;要直到到底哪些因素导致了明天的股票上涨。
时空数据相关的发展到了什么程度?最近的一些进展?也即时序数据上有一套不太一样的因果推断方法,如果把这样的方法放到时空数据里面,是否也有一套比较特定的好方法来解决它?时空数据、相关性数据的因果推断。
confounding,selective bias为第一梯队要研究的,inference,midiation,ide,以及异质化为第二梯队要研究的。真正的拿因果关系的因素去预测,不一定比用相关关系的预测效果更好。
二者的目标不太一致;ML:主要关注的是预测、分类等类似的问题;而因果推断天生的就是关注模型的解释性,参数的识别性,定义,因果参数,因果的意义是什么;二者目标不太一致。对于预测来讲,你拿真正的因果关系去预测,不一定比拿相关关系去预测更好。反之,相关关系不能代表因果关系。当然现在大家正在把可解释性和可预测性,预测能力结合在一起;这可能是因果推断和深度学习能够深入融合的地方,而不仅仅是换汤不换药的模式。如何把预测、可解释性、参数的推断把目标给融合到一起,可能是一个方向。需要找到一条线,使得预测的目标和因果推理的目标能够对齐。之前做预测可能相对来讲大家再用一个比较简单的数据集(e.g. i.i.d,随机分割等这样的交叉验证的数据集来做,),正是由于此导致今天很多的方法,在不符合这个假定条件下的真实的场景下边就会出现各种问题 。因果推理和ML里面都有很多的假定。假如把这个假定换一下,换的更实用些、更realistic,可能就需要用一些更本质的统计的逻辑或结构可能才能够做到这种事情;这种情况下可能更需要去借鉴一些更严格的统计的手段和方法来解决这样的问题。让ML或预测更加的stable。
除了读书教书方面,学术研究有几个方面让其收益很大;1.写作交流表达能力一定要重视起来,记录单词,积累句子等。2.拓宽自己的视野;不一定只是盯着前沿的东西,一定要对自己所在的领域有一个全局的认识。3.扩展一些兴趣,应用方面的以及交叉领域相关领域的一些事情,来拓宽自己的视野;不同的问题、方法交汇融合。4.加强阅读,多读多写。

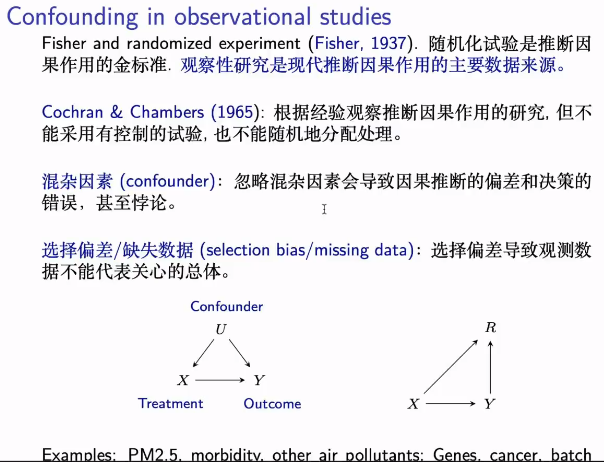






上述结果在潜在结果模型或do caculates下都可以建立,这些模型是等价的。关键的是你背后因果的假定,以及推断识别的方法是什么,在给定这些假定和方法的情况下,不论用结构方程模型,do caculates或其它的模型,都可以得到相同的因果推断的结果。
回归树等都可以去估计。logistic回归是个最简单的方法。




缺失依赖于缺失值本身则称为非随机缺失;缺失只依赖于完全观测的变量则成为随机缺失;
https://www.bilibili.com/video/BV1fY4y1q7Ks/?spm_id_from=333.788.recommend_more_video.1&vd_source=3ad05e655a5ea14063a9fd1c0dcdee3e
随机缺失是比较容易解决的,但是非随机缺失则有比较大的挑战性,因为其可识别性不能保证;给了观测数据的分布,可能存在完全不同的联合分布或不同的参数,让你得到相同的数据分布,这样你就没办法推断背后未知的参数。
其中一个重要的工作就是heckma's selection model 1979年提出来的,并于2000年获得诺贝尔经济学奖







 浙公网安备 33010602011771号
浙公网安备 33010602011771号