机器学习的可解释性:因果推理和稳定学习--况琨 浙江大学
分享嘉宾:况琨 浙江大学 助理教授 编辑整理:有感情的打字机、闫建飞
导读:机器学习方法已经在许多领域取得了巨大的成功,但是其中大多数都缺乏可解释性和稳定性。其主要原因是目前机器学习方法是关联驱动的,且没有区分数据中的因果关联和虚假关联。
因果推理是用于解释分析的强大建模工具,可以帮助恢复数据中的因果关联,用于指导机器学习,实现可解释的稳定预测。在本次分享中,主要介绍了大数据背景下如何进行因果推理,以及如何利用因果技术来指导机器学习,实现可解释稳定学习。
▌目前AI算法的风险:不可解释性与不稳定性
1. 不可解释性与不稳定性说明
目前的AI算法大多数都是一个black box,存在不可解释性的问题,并且算法的预测特别不稳定。以一个简单的图片识别问题为例:识别一张图片中是否有狗。在很多预测问题中,我们拿到的数据集往往都是有偏的,比如我们拿到的数据中有80%的图片中狗都在草地上,这样就导致在训练集中草地这一特征会和图片中是否有狗这个label十分相关。基于这样的有偏数据集学习一个预测模型,无论是LR,还是Deep Model,都很有可能会将草地这一特征学习成很重要的预测特征。
这样的预测模型,首先是不可解释的,其次,对于未来的测试数据集,如果和训练集一样也是狗在草地上,则模型可以得到正确的预测结果,当然测试数据集也可能是狗在沙滩上,但是背景中有一些树木或者绿植,这时模型也许能识别出来。但是对于狗在水里的图片,基于我们的训练集学习出来的模型肯定会识别不准。这样就导致了对于所有未知的测试数据集,模型的预测特别不稳定。

再举一个比较实际的例子,我们如果要帮助医院预测一个癌症患者的生存率,我们很难拿到所有医院的数据,假设我们现在拿到了某一个城市某一个医院的数据,如果我们利用这个数据集做建模,我们可能会发现在这个医院中病人的收入越高,病人的幸存率也会越高,这是有道理的,收入高的病人得到的治疗和能支付起的药物可能更好。基于这样的模型做预测时,如果未来的要预测的病人同样是来自该医院的患者,我们可能会得到很准确的预测结果。但是如果未来要预测的数据集来自大学校医院 ( 比如美国的校医院,对患者给予的救治不由收入决定 ),此时的预测效果很可能不好。

以上的例子均揭示了现有机器学习算法存在着不可解释性与不稳定性两个风险。
2. 不可解释性与不稳定性产生的原因
不稳定性的产生首先可能是数据的问题。现有的大部分机器学习方法都需要IID假设,训练数据和测试数据应当是独立同分布的。然而在现实中,这一假设很难满足,这样就会产生distribution shift的问题,这在小样本学习任务中的问题更严重。在大数据条件下,比如ImageNet的分类任务的训练数据非常大,许多模型的效果都非常好,因为训练数据足够大可能已经涵盖了未来会出现的测试数据类型。但是在现实问题中,我们无法控制测试数据的产生,也就无法保证这一假设的成立。

换个角度,我们认为这是模型的问题。现有大部分机器学习模型主要是关联(Correlation)驱动的。关联主要有三个来源:Causation,Confounding,Selection Bias。
其中Causation是不会随着环境的变化而变化的(比如下雨会导致地面湿,这在任何城市和国家都是成立的),是稳定且可解释的。而Selection Bias描述的就如上述草地和狗的相关性现象,我们通过样本选择,使得草地和狗十分相关;同样也可以使得沙滩等其它背景与狗十分相关。这种关联会随着数据集和环境变化而变化。Confounding 描述的是由于忽略某些混淆变量导致的关联。
通过Confounding和Selection Bias产生的相关性是不稳定且不可解释的,我们称这两种相关性为SpuriousCorrelation即虚假相关。传统方法预测不稳定且不可解释的主要原因就在于其没有区分因果关联与虚假关联,笼统地将所有关联都用于指导模型学习和预测。

为了增强机器学习模型的预测稳定性和可解释性,我们提出了用因果约束指导机器学习的方法,具体想法是去除关联中的虚假关联,恢复因果关联,使用因果关联指导模型学习。
▌因果约束的稳定学习框架
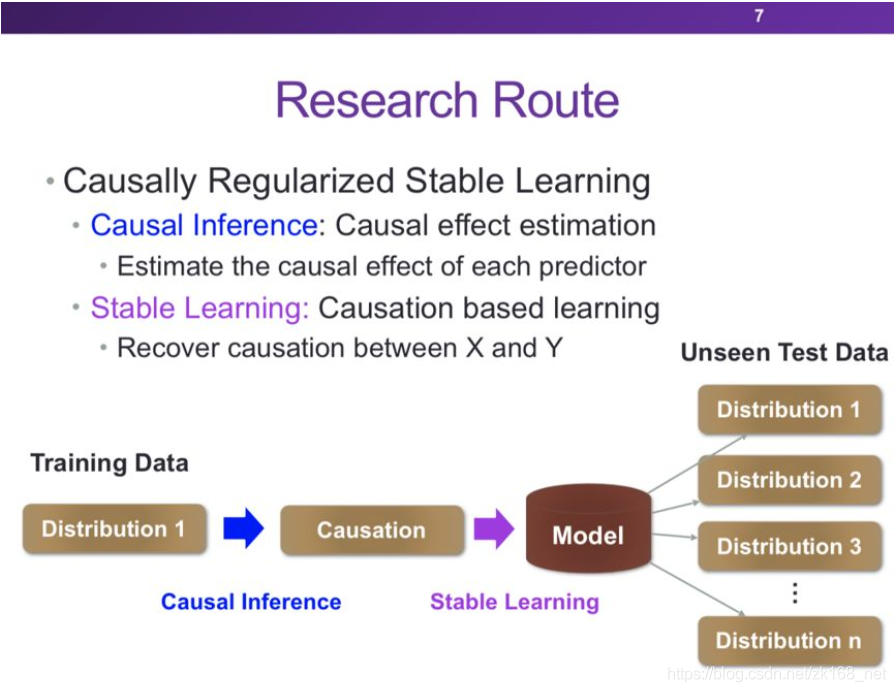
稳定学习是指利用一个训练数据分布为分布1的数据学习一个模型,使得模型在任何可能的测试数据分布1,分布2,...,分布n上面的预测精度都很高且相近的。如果我们预先知道测试数据的分布为分布1,则该问题就是理想的IID样本的学习问题,如果预先知道测试数据的分布为分布n,则可能利用transfer learning的方法来解决。但是在难以预知未来测试数据分布的实际问题中,我们想达到的效果是模型在未知分布的测试数据上有稳定的预测效果。
因此我们提出了一种因果约束的稳定学习框架,该框架主要包含因果推理与稳定学习两个部分。在因果推理部分,我们评估每个预测变量对结果的因果效应。利用之前草地与狗的例子:根据评估,草地对是否为狗的因果效应若为0,则可以将草地这一变量剔除。在稳定学习部分,主要任务是如何利用因果方法恢复所有预测变量X与Y的因果关联,基于这样的因果关联实现Causation-based Learning。
1. 因果推理
因果效应:T对Y具有因果效应当且仅当保持其他条件不变,T的改变会导致Y的改变。其因果效应的衡量可以通过单位T的变动导致的Y的变动的大小来衡量。评估因果效应的两个关键是一要保证T的变化,二要保证其他变量的不变。

因果效应估计:现实中最直接的因果效应估计方法为随机实验。但是随机实验是有成本的,并且很多情况下会影响用户体验,甚至由于伦理道德等问题是不可行的,因此下面介绍如何使用观测数据估计因果效应。在观测数据中,将Treated Group与Control Group之间特征分布不一样且会对结果造成影响的特征称为Confounders(混淆变量)。当我们在研究Treatment变量T对Outcome变量Y的因果效应时,如果存在混淆变量x,它会影响Treatment变量T,也会影响最后的结果Y。当我们直接通过数据计算T对Y的关联时,我们实际上将x对Y的效应也计算在内,因此很难区分T对Y的关联是由T对Y的因果效应导致的,还是由混淆变量x通过T对Y产生影响导致的。

因此在基于观测数据进行因果效应评估时,关键是如果保证混淆变量在评估数据的Treated Group与Control Group的分布是一致。最直接的方法是基于Matching的方法,为Treated Group匹配Control Group中特征分布一致的人群,通过匹配后的人群计算因果效应。但是在高维情况很难找到两个特征分布一样的样本,因此该方法很难应用到高维情况中。
为了解决这一问题,出现了基于Propensity Score的方法,该方法通过计算样本在Treated Group的概率来实现Matching。将在Treated Group概率相同的样本进行匹配,理论上也能保证匹配后的样本混淆变量的分布是一致的。基于Propensity Score的方法主要有Propensity Matching,Propensity Weighting,Doubly Robust等。但是基于Propensity Score的方法也存在一些问题:
A. 将所有观测到的变量都笼统地当作混淆变量去评估Propensity Score。
B. 使用PropensityScore方法需要模型假设,常用的模型假设是logistic regression。
为了解决以上两个问题,一些学者提出了一些无参的方法如Entropy Balancing,Approximate ResidualBalancing等。这些方法的主要思想是通过某些数学方法衡量和刻画Confounders的分布是否已经平衡,例如变量的矩能够唯一决定变量的分布,因此可以通过控制变量的矩使得变量的分布一致,一般控制变量的一阶矩就能达到比较好的效果。

这类方法有两个缺点,一是将所有变量都当作confounders来做平衡;二是将所有的confounders都同等对待。在大数据背景下,我们面临着两个新的问题,一是如何自动化地区分哪些变量是confounders,二是对于不同的混淆变量,如何区分他们对因果效应评估带来的作用。为此我们提出了两种算法:数据驱动的变量分离算法及混淆变量区分性平衡算法。
数据驱动的变量分离算法:
下图展示了一个之前常用的因果推断框架,所有的观测变量U都被当作混淆变量X,然后计算PropensityScore,基于得到的Propensity Score对结果变量做re-weighting,最后评估因果效应。

但是我们认为并非所有的观测变量都是混淆变量,基于这样的想法我们提出了一个新的因果推理框架(见下图),我们将所有的观测变量分解为三部分:混淆变量X(会同时影响T和Y),调整变量Z(独立于T,只与Y相关),无关变量I(独立于T和Y,在框架中被省略)。若能准确地将观测变量分解为以上三部分,就能只通过混淆变量X评估Propensity Score,之后用Z回归Y,减掉Y上的一些噪声,达到降低方差的目的,利用经过调整的结果变量来评估因果效应。
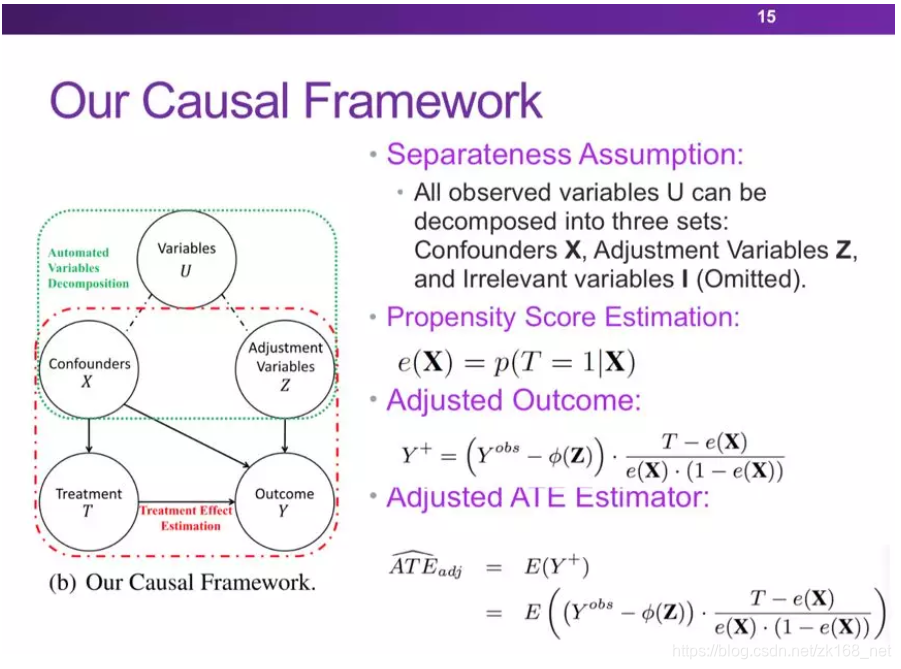
算法的目标函数和求解约束如下:

该算法在假设成立下,可以无偏地评估因果效应,并且相对于传统的Propensity Score方法可以降低评估的方差,经过仿真数据和真实数据验证确实能够分离混淆变量和调整变量。
我们的方法通过与下面四种方法进行比较:

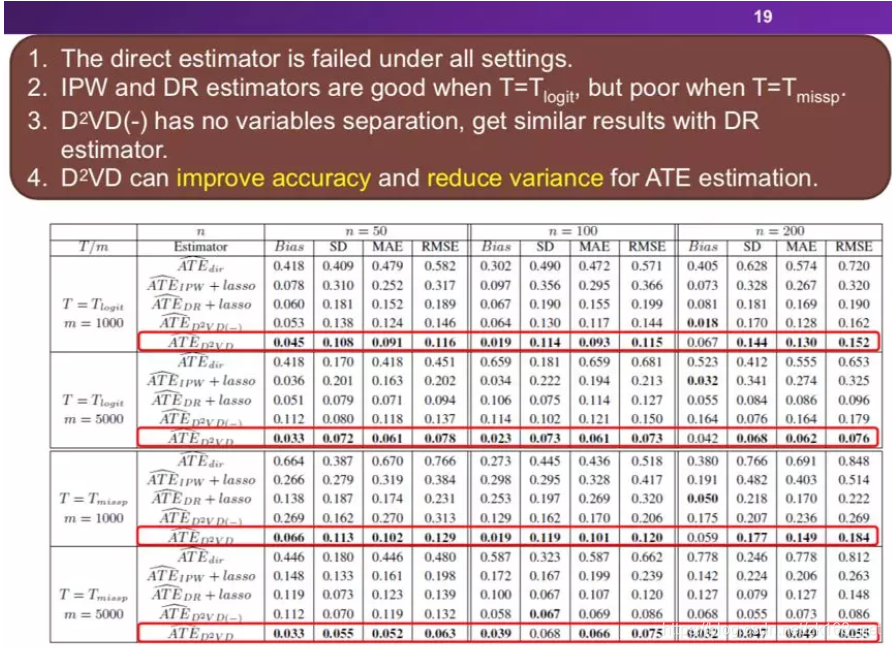
通过上述的实验我们可以得出,我们提出的数据驱动的算法DVD是最优的,因为该算法成功的将变量分为了混淆变量与调整变量,可以提高准确率,同时可以降低ATE预估的方差。
微信LONGCHAMP数据实验结果:

数据集来自于微信的LONGCHAMP,用户对于包包这个广告点击还是不点击作为结果Y,另外搜集了用户的56个特征作为变量,通过这个数据集验证我们的方法。
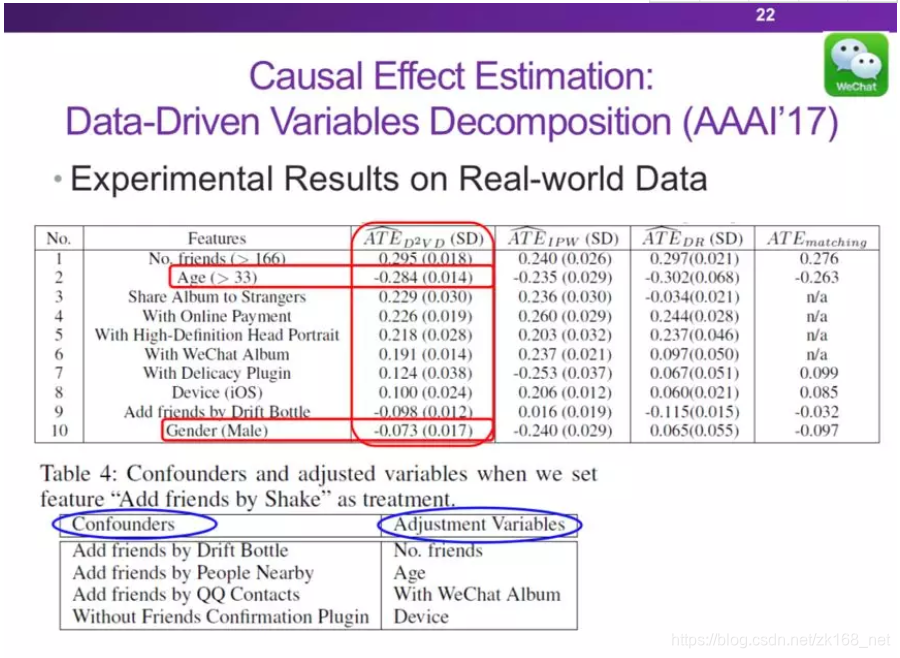
上图对排名前十的特征进行了因果效应评估,再一次验证了我们方法的准确率与方差都是优于其他方法的。此外还发现了一个有趣的现象,上图中年龄大于33岁与男性这两个特征的因果效应是负的,也就是说年轻的女性更加喜欢包包,这与实际是相符合的。
混淆变量区分性平衡算法:
为了解决之前的算法中将不同的混淆变量同等对待的问题,我们提出了混淆变量区分性平衡算法,具体推导如下图:

直接估计的ATT hat实际上是由真实的ATT(averagetreatment effect on the treated)加上一部分误差组成,而这个误差又由confoundingbias和confounding weights两部分决定,不同confounder的confounding weights不一样,并且该confounding weights是M对f(x)的回归系数。所以在我们提出的混淆变量区分性平衡算法中我们通过学习两个参数beta(区分哪些变量是混淆变量及对应的weight)和W(样本权重)来达到区分不同的混淆变量的目的。

下面是算法在仿真数据和真实数据上的部分实验结果:

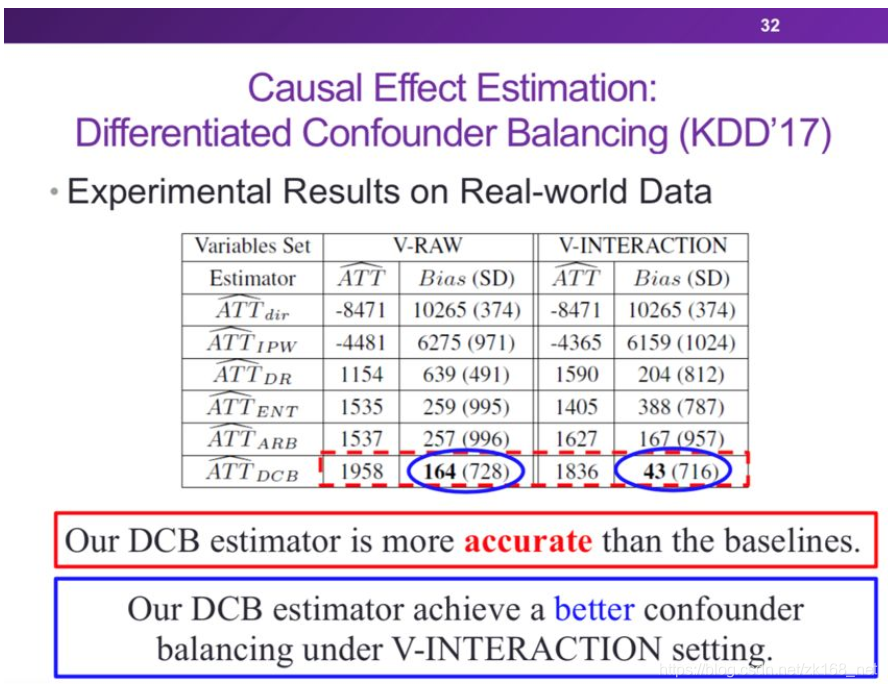
2. 稳定学习
有了之前因果推理的技术,下面探讨能否恢复所有X与Y的因果关系,实现稳定学习。在对Y进行预测时,Causal features对Y的预测是稳定的,不稳定性主要来自non-causal features对Y预测的不稳定性,这种不稳定性源自non-causal features与Y的虚假关联关系。因此如果能实现non-causal features与Y独立,便可以消除这样的虚假关联。

因此我们提出了causal regularizer,其主要思想是学习一个样本权重,用它对样本做re-weighting,使得re-weighting之后的变量之间相互独立,以此帮助我们评估单个变量对结果变量的因果关系,并且在理论上可以证明这样的样本权重是存在的。

例如基于causal regularizer和logistic regression学习一个加权的logistic regression,得到的系数从某种意义上可以被称为因果系数,基于这样的系数给出的预测结果具备可解释性和稳定性。

当然可以将此处的LR换成深度模型:
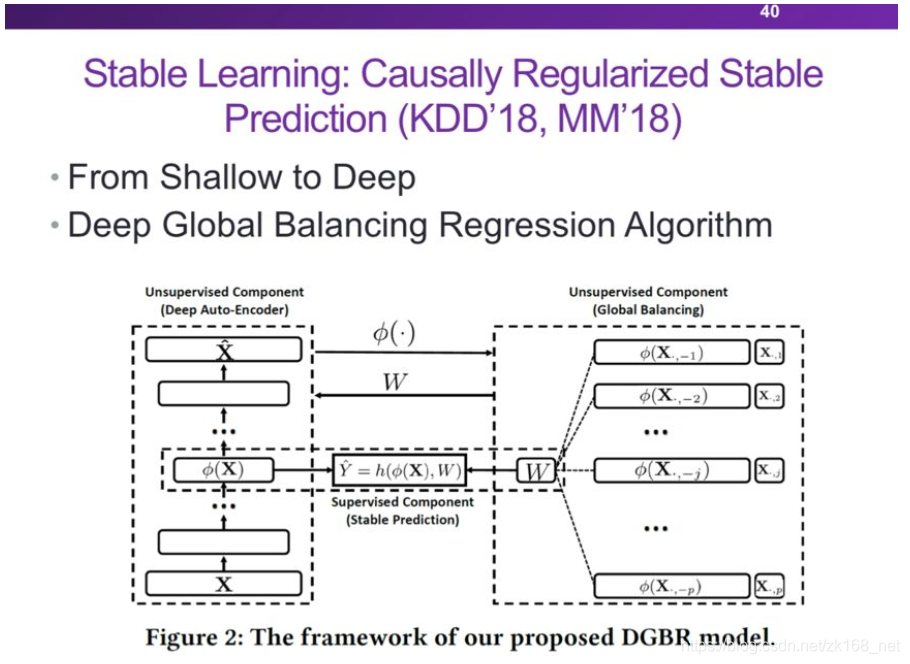
实验结果如下图,可以看到无论测试数据的分布如何变化,我们提出的方法的RMSE都是比较稳定的。


随着测试数据集与训练数据集的差异越来越大,我们的方法的提升也更加明显。并且将特征进行可视化(绿色圈为未调整的LR用到的特征,红色圈标出了调整后的方法使用的特征),可以发现我们的方法或许更加具有可解释性(绿色圈大部分落在背景物体上,红色圈更加集中在物体本身上)。

▌总结
我们认为现有的机器学习方法是correlation-based的,其中correlation有三个来源,一是因果,二是混淆变量,三是选择偏差。其中只有因果导致的关联是稳定的,可解释的,另外两个来源的correlation是不稳定的不可解释的。未区分这三个来源的算法有不可解释和预测不稳定的问题,为了解决这两个问题,我们提出了基于因果推理的稳定学习框架,利用因果推理的技术指导机器学习实现可解释性和稳定预测。现有的深度学习算法面临的一个很大的问题也是不可解释的问题,因此未来若能将因果与深度学习相结合,使特征表征更具有语义信息,就能使得预测更加稳定和可解释。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号