时间序列预测新范式:基于迁移学习的AdaRNN方法

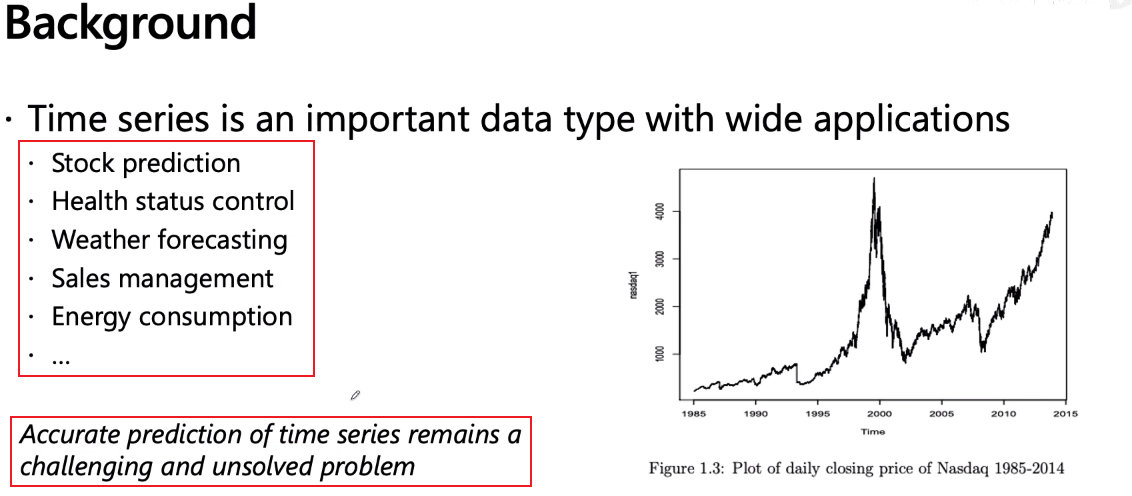
整体来看波动较大,但是分成一个一个区间段来看,则符合高斯分布。


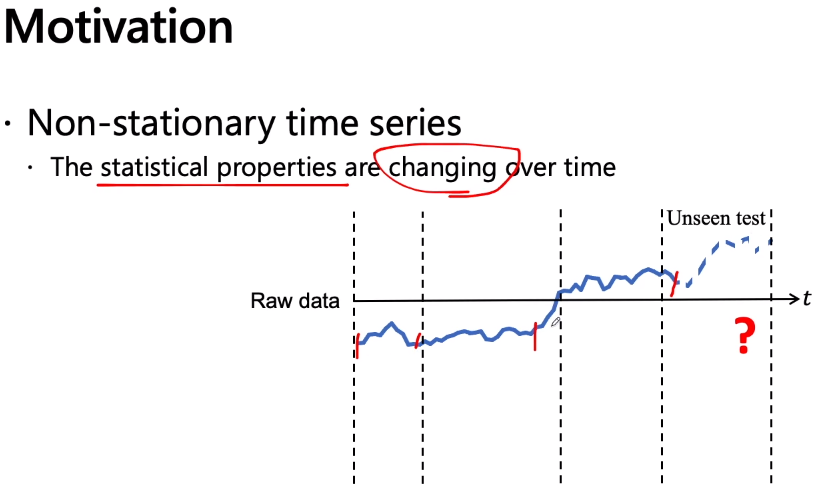
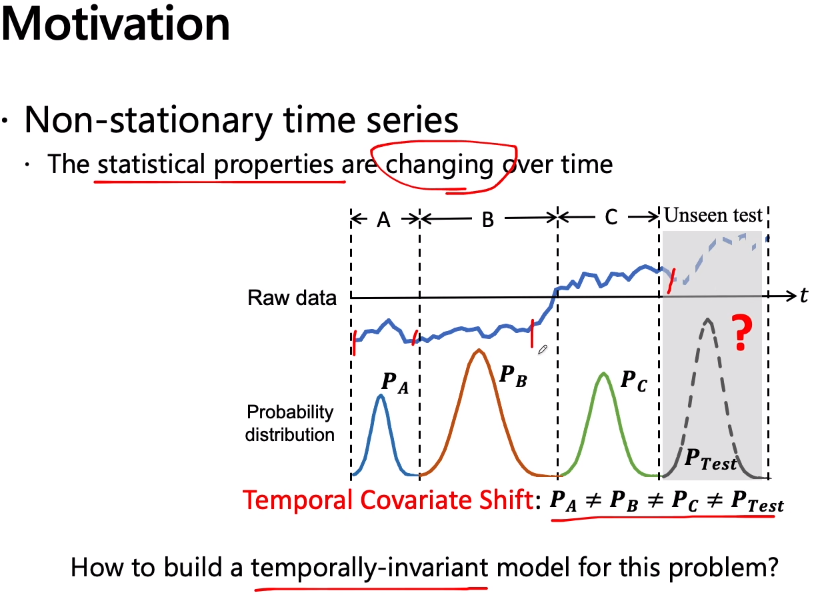
比如上图虚线隔开的区间。A,B,C可能彼此两两之间分布不一样,但是 每个肚子的区间可以看作是一个独立的分布,如果PA,PB,PC用高斯来表示的话 ,那么他们3个和test部分都是各自的分布状况。也即观察到时间序列中是存在内部的分布不一致性,但是在某一小段的区间内的分布可以认为是趋向于一致的(网友:高斯混合模型?),这个问题之前是没有被人研究过的,所以就给他定义了一下,叫做temporal covariate shift时间协变量/变量偏移;也即在一个时间序列里面可以划分成多段,每一个段内的分布可以认为是一致的,段与段之间的分布是不一样的,这就是给它的一个形象的定义。

如上图示,去预测未来的t个步骤,总体来说和分类类似,给了i个时间序列,只不过x可能是某些时段的观测点,y也是有可能有较多的label,e.g. 长度n,维度p,以及d个label,要做的就是预测未来的变化情况,这个定义看起来比较复杂,其实是比较简单的。

更重要的是定义的这个问题TCS,我们是想先从问题的本质covariate shift出发,这也是十几年前大家提出来的定义比较良好的一个问题,(做迁移学习和做机器学习的研究人员应该都不会陌生),也就是说Ptrain和Ptest两个分布的marginal probability distributions(边缘分布)是不一样的,但是conditional distribution条件分布是一样的。这是非常经典的一个定义。那我们扩展了定义如上如图下部所示的temporal covariate shift,也就是给定了一个数据集D,让后把D分成D1到Dk共k段,每一段都是x,y对;其中每一段Di的分布两两之间的分布都是不一样的,也即pDi(x)和pDj(x)的分布是不一样的,但是他们的条件分布是一样的。可以通过对比原来的covarite shift和现在的temporal covariate shift的定义,后者的是扩展了前者,扩展到了时间序列上,并根据时间序列自身的特点丰富了covarite shift其在时间序列里面的定义。这就是指出来的TCS的问题。
那如何在这个定义的问题存在的前提下去建立一个随着时间变化不那么大的temporally-invariant model,就是说随着时间的波动model依然很有效,也就是泛化能力很强的model。但是注意到这个问题是普遍存在的,并不是说这个问题有,几乎你找任何一个时间序列它几乎都会存在这样的问题,所以这个问题是具有普适性的。

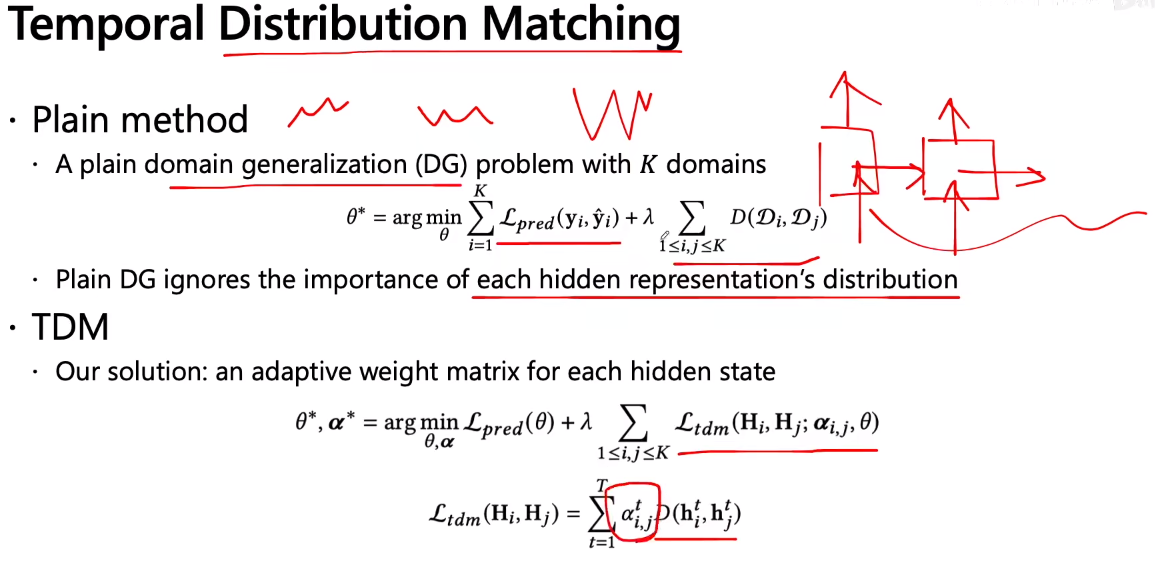
有了上述的TCS问题后,如何解决这个问题呢?上图给出了一个通用的框架,首先要确定所给完整时间序列数据的划分方式,我们把这个问题归结为构建一个worst-case的分布的问题,因为给一段时间序列,你可以划分为任意段,每一小段都有自己的分布状况,那么到底怎么样的划分才是对于解决这个问题是最好的;那么问题就是在给定数据集的情况下,怎么更巧妙的划分段,或者说划分成最多的段,使得分布情况是最坏的情况也就是使得分布特别不一样,如果能够在这种分布特别不一样的分布状况下,也能够建立非常好的模型,那么就可以对于未来的那些预测数据有很好的表现,所以第一步就是去找worst-case的分布情况,紧接着第二步就是去match这个最坏情况下的分布,就是把分布的gap去填平,这样如果能在worst-case的情况下表现得比较好,那么在一般情况下就更没有问题了。就可以得到一个good model了。注意到这种思想其实是和一类优化的思想(distributional robust orgnization)比较像的,但是他那个问题是给了一个理想的定义,我们这边是把他用到了时序数据上。因为这个时间序列天然就存在这样的问题,所以就解决的比较好。

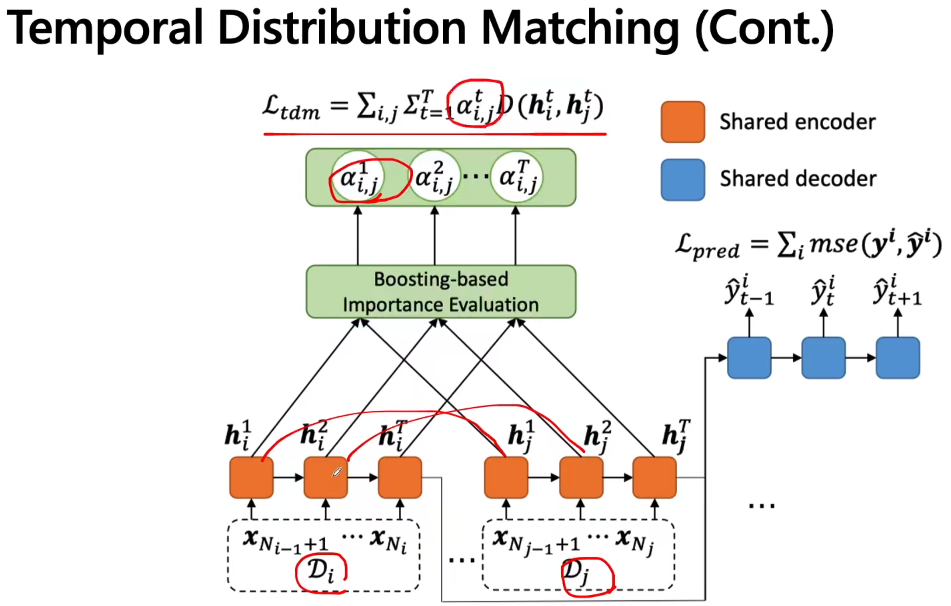
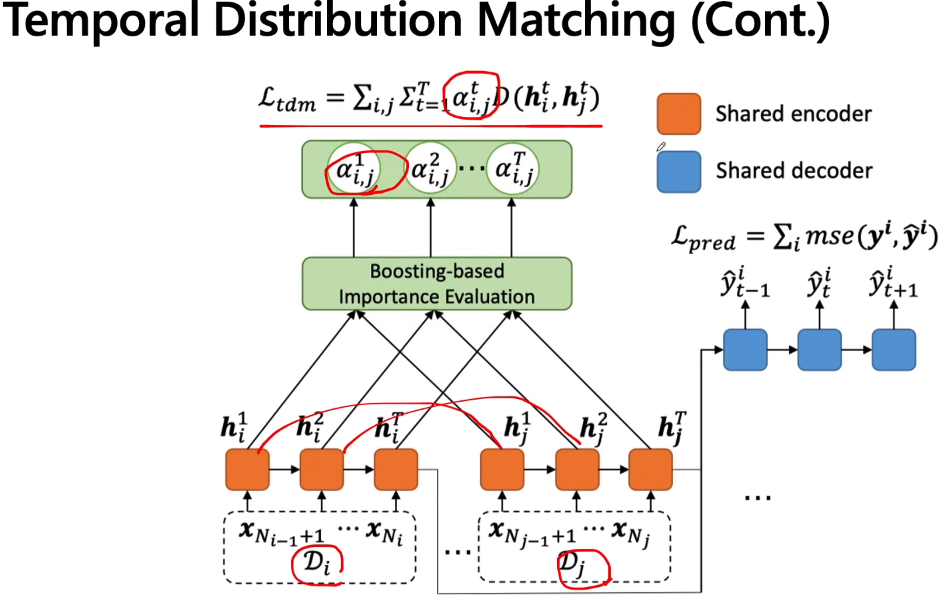
那么为了解决这个问题,就给它取了个名字叫做AdaRNN(Adaptive RNN),从字面上的意思来看是基于RNN的,但是这个东西是不局限于RNN的,因为他是跟框架的关系不是特别的大;我们现在先来看一下上图右边这个整体的框架,主要分为绿色和黄色的两块。黄色对应的部分是找到最坏情况下的分布,然后插入一个预训练的东西,再然后在做一个temporal distribution matching的工作,这两大块就构成了方法的核心。其中黄色块对应的分解开如下图所示,
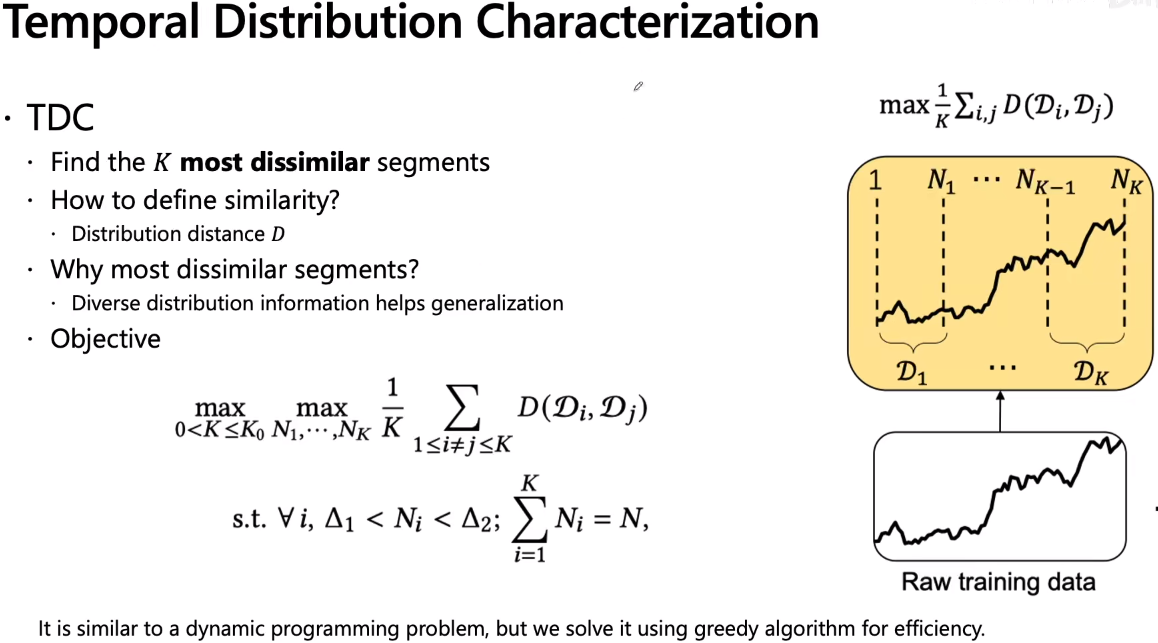
如上图右下角所示,要把完整的raw training data分成K段,K段里面要把其distribution的信息找出来,让它max,也就是让它的disance特别大,这样也就是worst-case。核心就是找K个most dissimilar segments,k是自己定义的。也就是找K个最不相关,最不相似,分布最不相同的segments,那如何定义similarity呢?因为这里不挑距离,所以任意分布的distance都是可以用的,我们后面的实验会看到。因为为了是分布尽可能的diverse,所以是挑最不相似的而不是挑最相似的。多样性大的话,会帮助泛化能力。有了这些后可以锁类似于聚类的操作,但是注意这不是聚类,而是以点对点的距离来度量的,这里是对分布做聚类来度量的,聚类的目标就是使得上图中的D(Di,Dj)均值最大化,。。。


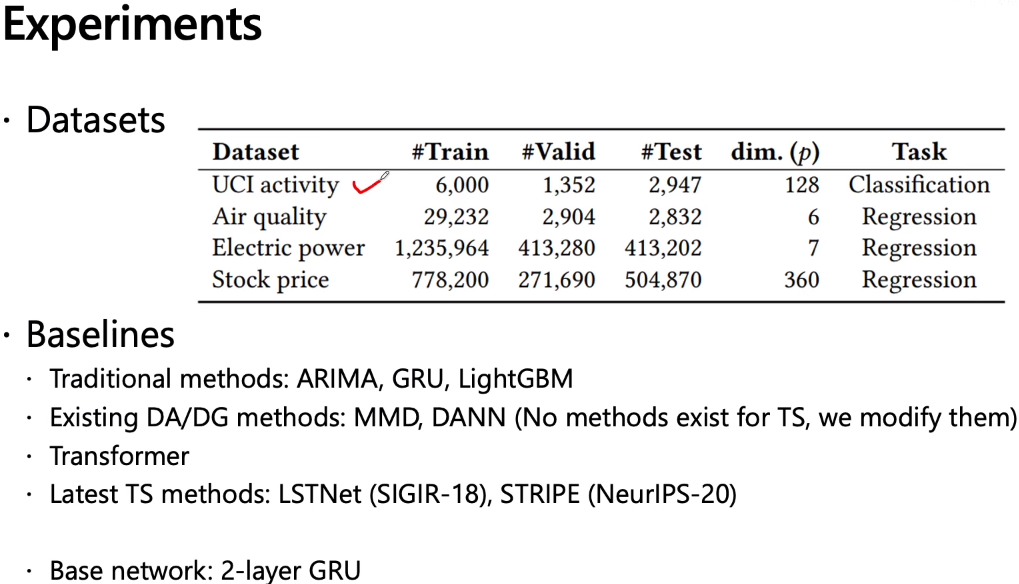
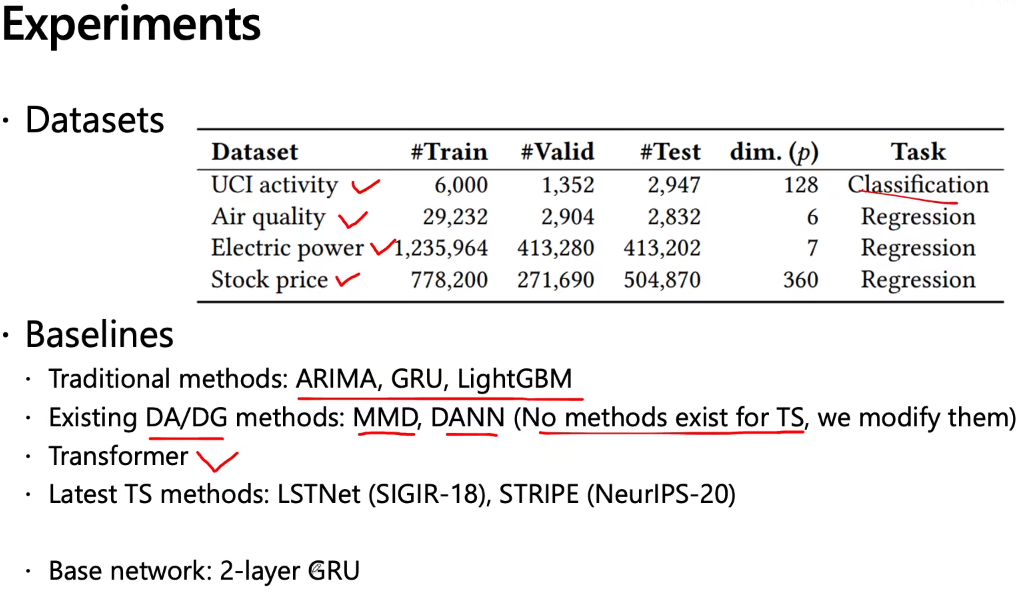
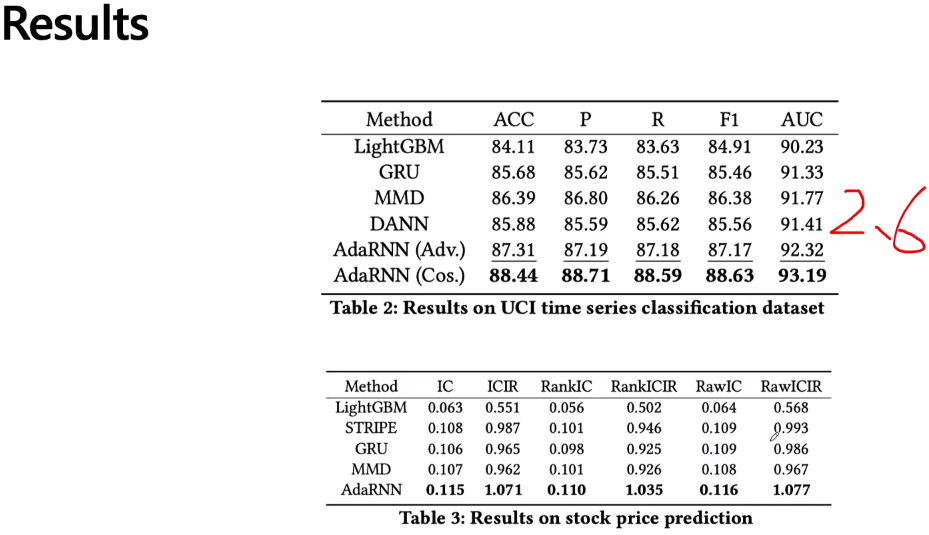
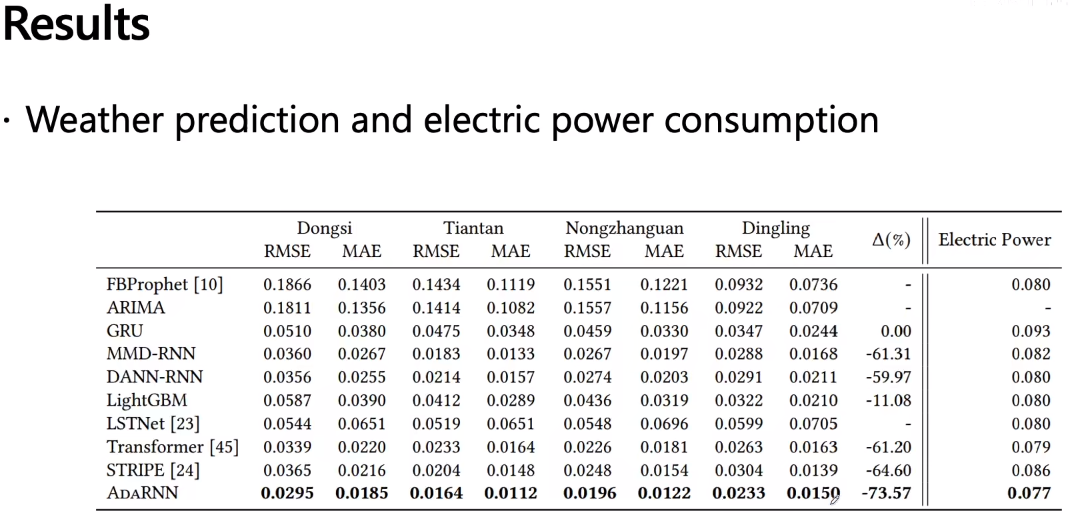

最近想做一个时序信号分类的实验,看了您的AdaRNN: Adaptive Learning and Forecasting for Time Series这篇文章有很大启发,但是我的代码能力不太好,虽然您分享了源码,但是不知道怎么把预测任务改成分类任务。我看您实验部分也做了时序信号的分类任务,希望您能够分享一下;答:分类很简单的,只要改数据的label和训练loss就可以的。
王博士您好,感谢您们团队的研究成果供借鉴参考!我是做工程领域研究的,初学深度学习,想请教些问题:
①该方法是基于迁移学习思想而提出的一种像LSTM能够预测时间序列数据的性能更佳的新思路新范式,那么有没有能够用于源域(数值模拟)和目标域(现场实景)的时间序列预测模型的迁移学习方法呢(或循环神经网络迁移学习)?
②源域和目标域的采样时间步长不一致时,还能否迁移?
③想实现多输入单输出的时间序列分类预测,源域中的其中一个纬度指标可以人为设定且可以始终保持为恒定值,但目标域中的这个指标是不确定的,是动态变化的。这种情况下,剔除这一纬度是否是其唯一办法?
学科交叉的机器学习初学者,很多不懂,敬待指教,非常感谢!
博士我有点疑问,您说这个问题转化为dg,但是好像没说具体的dg方法。后面对比da和dg方法时,也没有一些dg的方法,和da对比的时候使用的多源da吗,不太懂。答:不和da比啊;
王博士 我在测试act这个数据集的时候始终报这个错误cannot import name 'config_info' from 'config' (D:\Anaconda3\lib\site-packages\config\__init__.py) 但config已经安装过了 却始终无法运行 希望您能解答一下 万分感谢!答:我也遇到了 不过用所给的数据集的话 用不到那个函数,直接注释掉就好了,不影响运行的;
王博士您好,我看了您的代码,但有一些疑问
get_spilt_time函数就是得到分布差异最大的划分吗?我似乎没有找到其它的像是TDC的代码?但这个函数只是按照先验信息将数据集划分了,并没有使用动态规划或贪心算法;答:TDC代码还没开源,readme里写了;
王博士,您好,我想咨询一下,近期有没有利用浅层的迁移学习方法来解决回归问题的paper呢?答:没有,现在都用深度方法;
确实,用以前的方法对比被审稿人要求更新对比方法,但是找了半天没找到比较新的浅层的方法;
博主,这个代码是不是只有paython代码,有没有MATLAB代码。发现电脑显卡安装不了CUDA;用不了cuda,那就做不了深度的。transferlearning.xyz/code/traditional 下面有非深度方法,有matlab的。。
这个dg为啥不是很好,要利用hidden state?答:看效果对比;明白了,效果说话;
王博士您好,请问您觉得这个工作用在行人轨迹预测上work吗?我没做过这个轨迹预测,你可以试试看;可以分享一下ppt吗?https://www.jianguoyun.com/p/DeQxVWMQjKnsBRjm-IoE。
您好,我想请教您处理后天气的数据集中的lable含义是什么呢,天气预报处理后数据klp文件里边有三个数组,第一个数组是特征,第二和第三个数组中代表什么含义呢?真实标签和domain标签;真实标签里边的数值是空气质量等级吗还是什么呢,真实标签归一化了吗?是pm2.5;标签感觉与PM2.5对应不上,PM2.5对应的值变化大有几百的,处理后的数据中只有0-5的数值,和任何一个指标都对不上呀;给一作发邮件要处理细节,抄送给我;
小白请教一下博士,加alpha的方式,有可能应用在XGB这类树模型中吗?可以。
王博士好,在论文里面,我看用了tdc分了几段数据出来,然后使用rnn预测,那我可以看成是rnn在预测多元时间序列吗?多元指的是特征多,不是有几段;
王博士好~有一个疑问,K段中不相等长度的小段,当取这每段的对应位置特征计算阿尔法(对分布重要性的权重)的时候,长度不相等呀,比如第一段是3,第二段是5,他俩剩下的4和5对应不上怎么办呀,短的那段特征就不计算α了吗,还是说补0对齐呀?新年快乐哦!我们的最小单位是batch,长度一样的;这个算法不好,不是端到端的。改进版请openreview.net上搜索diversify to generalize。
刚入门迁移学习,我想问一下利用迁移学习对时间序列建模的程序的文件名是什么?万分感谢!readme里面有运行方法呀;我能运行,就是不知道每个程序文件的作用,想知道哪个程序是利用迁移学习对时间序列建模的?是在train_weather.py文件中吗?是的。
王博士好,请问adarnn在新的序列任务上边,是需要重新训练吗,还是直接用第二步直接训练好的多层rnn进行预测的呢? 直接用第二步就可以。
王博,现在没有开源TDC,是不是换其他的数据集有问题?哈哈,是一作早就不在这里实习了,我跟他说了很多次了人家不听我的,也没办法,等着吧
王博士,你好,我想问一下有没有回归模型可以迁移的,比如VGG16就可以迁移过来做分类,或者这方面的文章,我在网上搜到的全是分类的;你换个loss就可以,问题不大;
这个α感觉是一个attention机制?就是加权,attention本质也是加权,我们也没不承认。
非常好的一篇时间序列迁移学习的文章,这方面文章太少了,大佬还有关于时间序列迁移学习的理论性文章推荐吗?时间序列我做的不多,这是第一个,也是盲人摸象。时间序列本身是一个非常古老的问题,做统计学的人就提出了很多的方法,比如arima系列,公式理论多到令人发指,最近nips 19 20有几篇从概率角度做的,你可以看看;好的,非常感谢。
王博您好,我是今年研一的新生,某些理解可能比较粗浅,希望您不吝赐教。想问下您,我们的这个方法是分段进行预测的吗, 是将每段分批送入rnn,最终再拼接成一个完整的序列吗?不是的哦,你去看代码。
好厉害啊,我知道时间序列可以用RNN,我也知道迁移学习,可就是想不出来时序漂移;今天也是怀疑智商的一天;
老师代码链接里面可以分享一下MMD+GRU的代码吗?想学习一下,谢谢!MMD+GRU的代码和普通的DeepDA并没有什么不同,直接把ResNet换成GRU就可以啦;
王博好,仔细阅读了您的文章,觉得是一个挺新颖的时序预测思路,如果把多条时序数据当做是TDC分割的子序列,这样去建一个模型,会有效吗?
有一个问题想和您探讨下,TDC本质上就是把一个时间序列分解成n小段,怎么确定n的具体数值呢???我看代码里面num_domain直接给的2.答:是超参数呀,文章里实验部分说过了。
老师您好,请问一下使用自己的数据集能直接使用吗,还是说得对程序进行修改,我查了您的数据集的结构和我的不一样。谢谢老师!答:主要程序不改,数据加载要改。核心算法肯定不改的。谢谢老师,意思是用我的数据集就能直接跑了吗?你要改输入输出啊,算法核心不改;
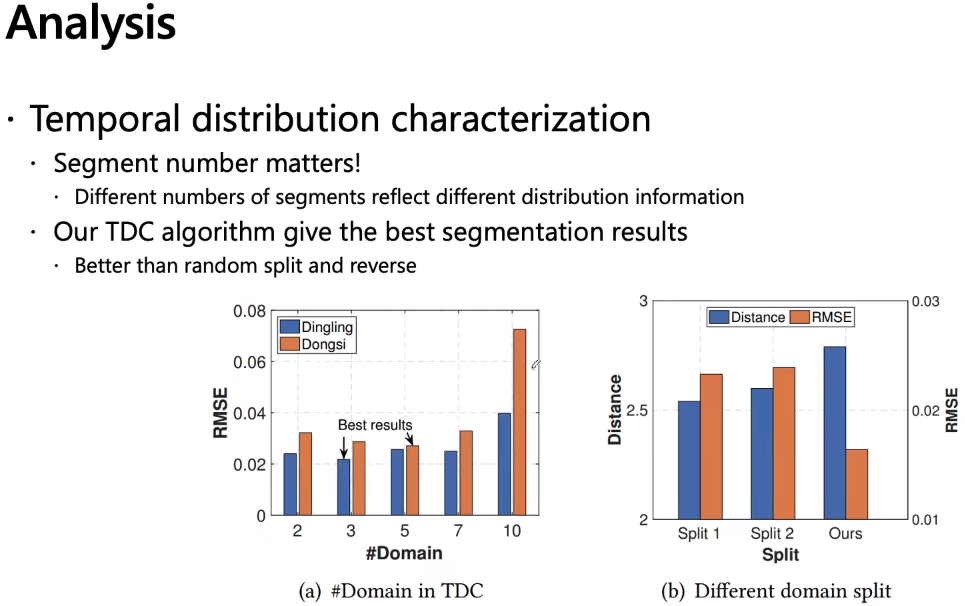
最后实验分析,split划分,第一个是随机分的,第二个是反着划分,第三个是我们的TDC,第二种反着分是什么意思;就是最好的情况,跟我们的反着来。
请问一下各位大佬,我最近想把DANN用到回归上(时间序列预测),我看了一些论文有这样的,但是这样有个问题,好像只把源域和目标域的特征对齐了,标签并没有对齐呀,这样会有问题吗?DANN解决什么问题,你考虑了吗?和你的问题场景相符吗?就是我在做负荷预测,特征是温度、历史负荷,输出是未来负荷。然后源域和目标域特征可能存回归问题,不存在标签问题啊。DANN在对齐源域和目标域的同时,还要最小化预测值和真实值之间的误差在分布差异,输出也存在。但是我看有一篇论文直接只对齐了输入特征,用DANN;DANN不是解决分类问题吗?也有用在回归里了。你是做负荷预测吗?有一篇A hybrid deep transfer learning strategy for cross building energy prediction;但是对齐的时候只考虑了对齐特征,是不是比较局限呢。输出需不需要也要考虑对齐呢。可能我研究的还不够深,不知道考虑的这个问题存不存在;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号