
周博磊《模型可解释性年度进展概述》20200805
https://www.bilibili.com/video/BV1Tk4y1U7ts/?spm_id_from=333.788.recommend_more_video.14
热力图。
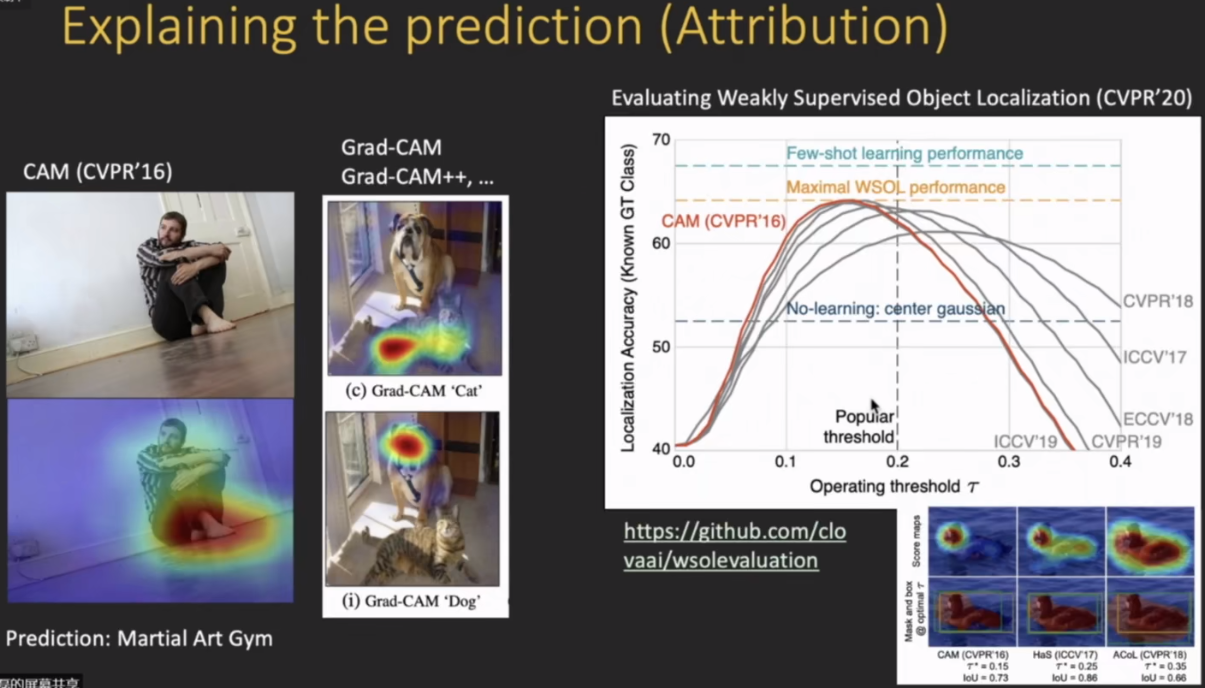
上述热力图有很大的局限,因为他只是一个causality的结果。

上图所示把unit以及channel的语义打上标签,这样就能利用神经元的激活(也即给一张图片,看那些神经元被激活了),然后用这些被激活的神经元,来提供一个解释。用神经元内部的激活以及语义特性提供了conversational。



上述的可解释性都是训练一个模型,然后对其进行分析,但是后续的一个方向是如何构建自身具有可解释性的模型。
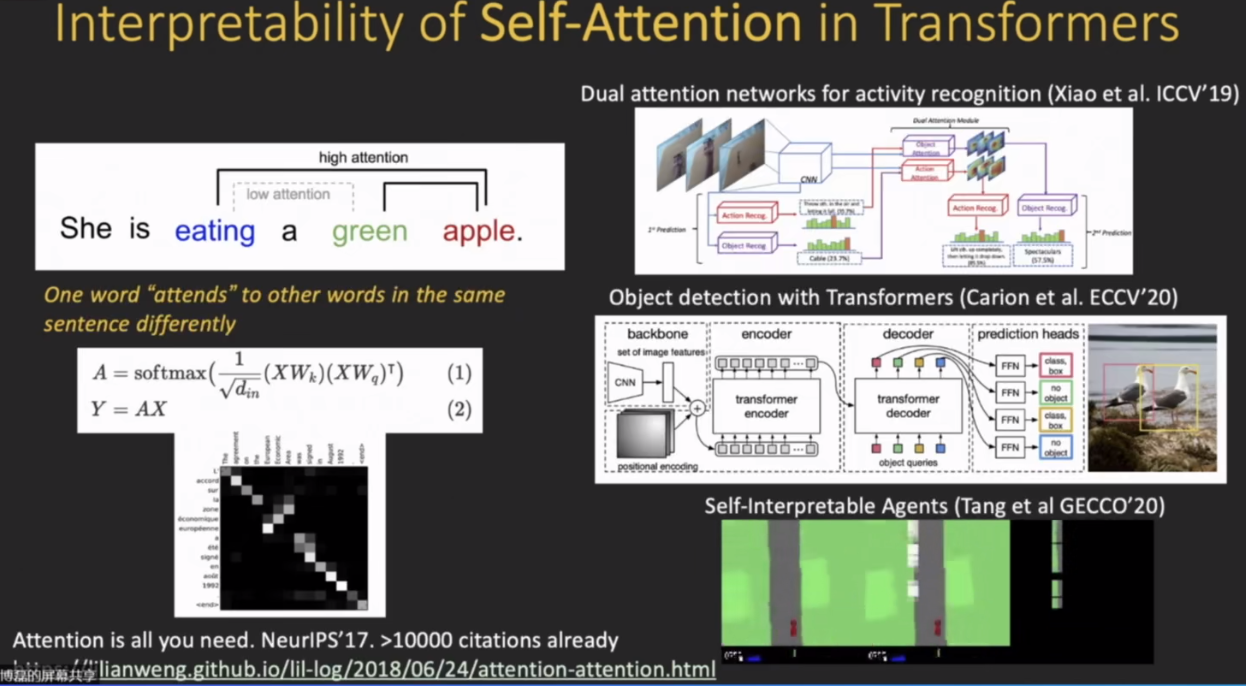
Transformer里面有一个很重要的的self attention机制。他可以把feature之间的联系显式的体现出来;这样的话feature加到约束层次还能长点(提高精度)。
如下图右边图把self attention的机制用进去后,这样就使得模型自身已经具有很强的可解释性,因为它可高亮出那些feature被强调出来了,然后直接就可以把它投影到图片上去,然后找到它真正高亮的区域,这样模型自身就具有可解释性。
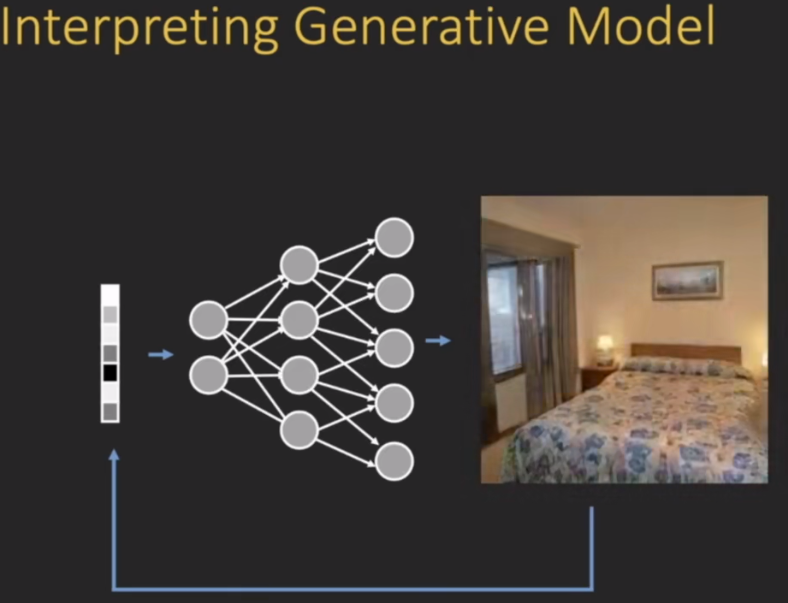
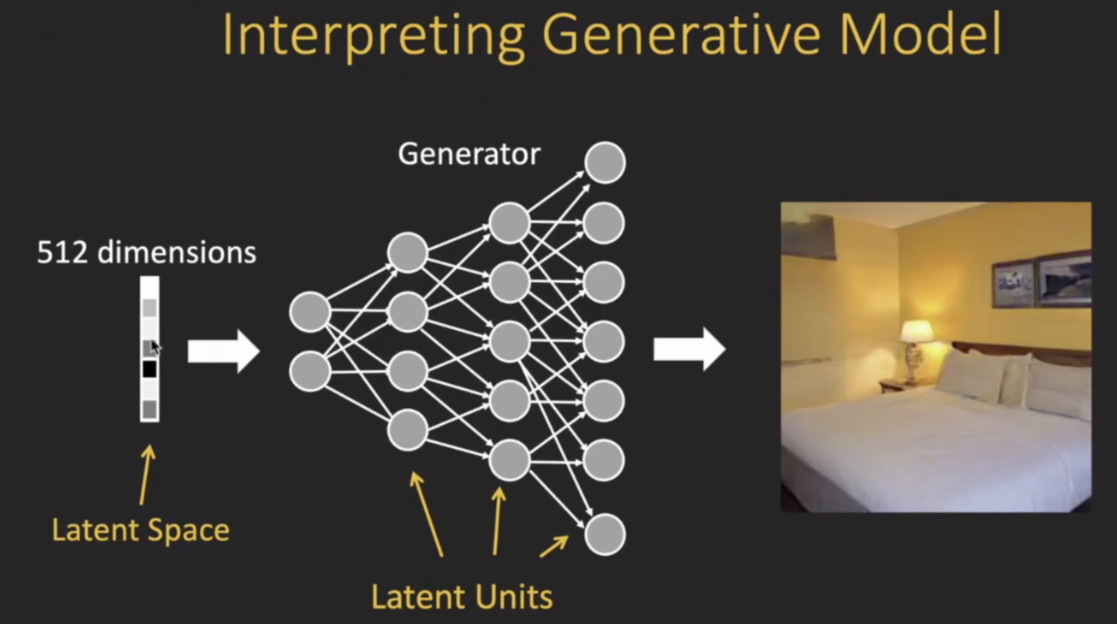
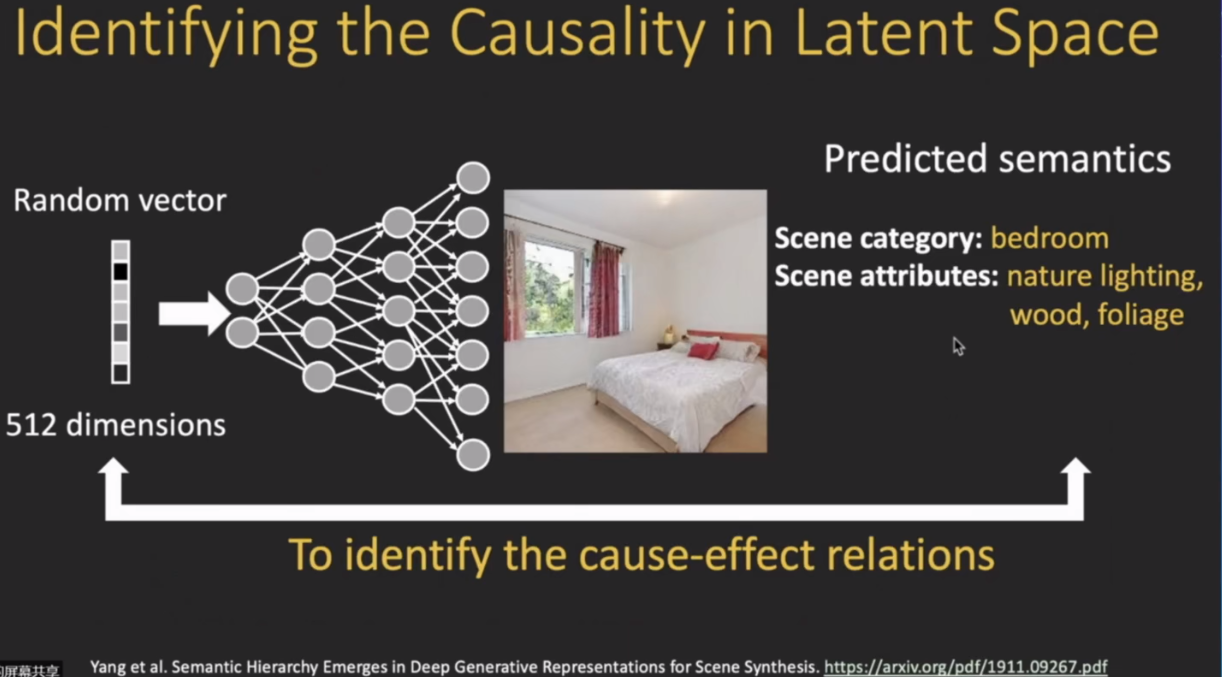
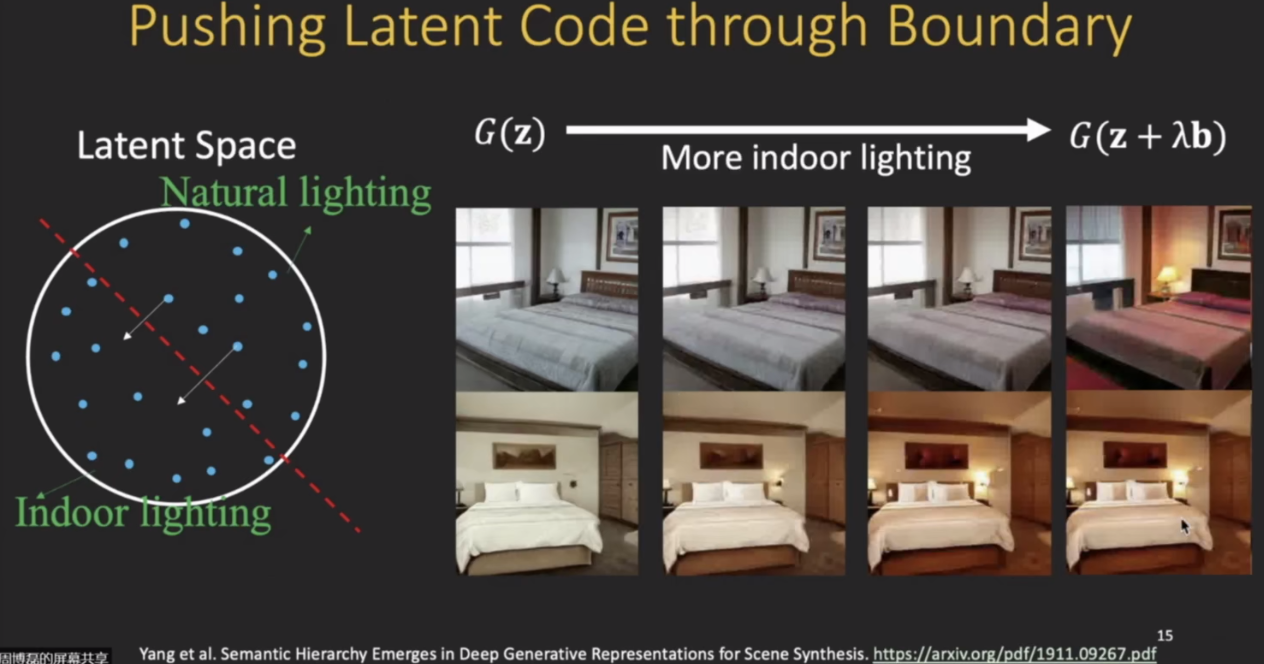

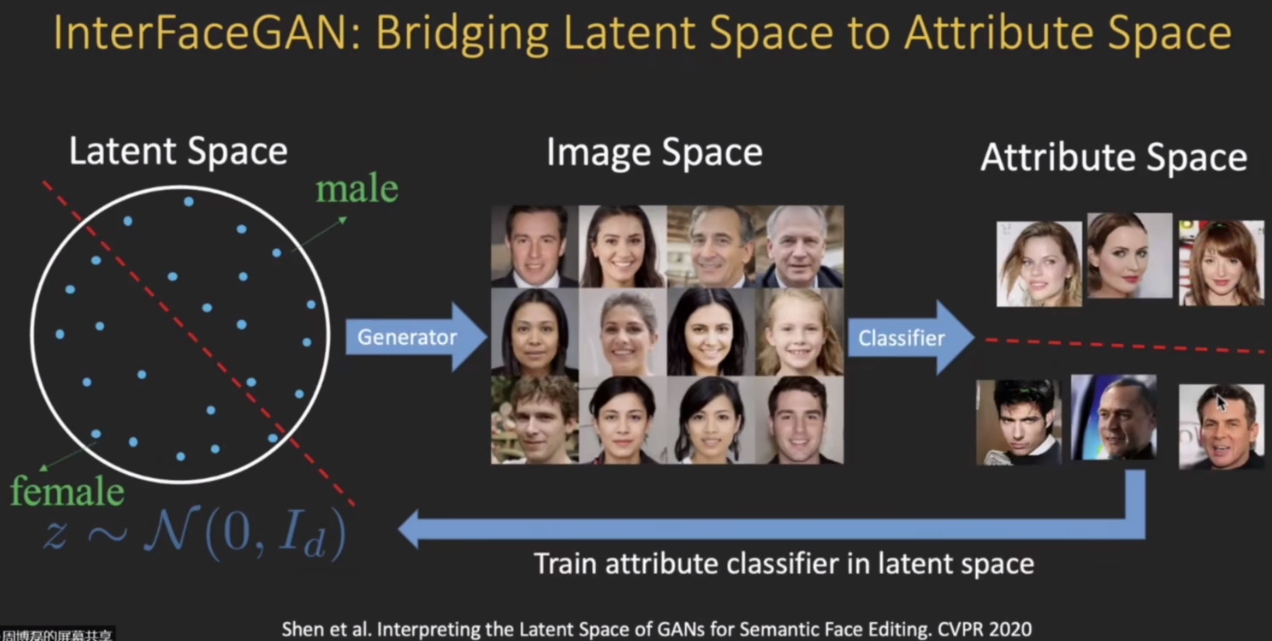


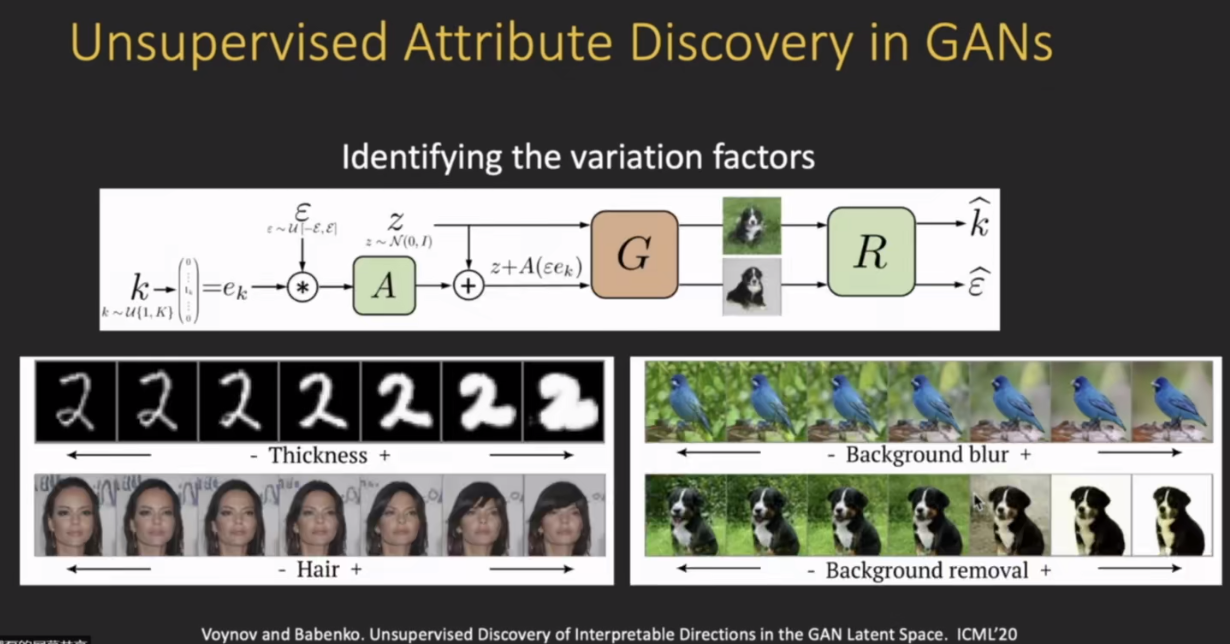



模型可解释性是一个非常大的topic,需要把这种可解释性的思想用到不同的应用之中去,比如说用来解释 模型的预测 或者对 对抗样本的稳健性进行一个可解释分析,以及对模型的偏见和公平性进行可解释性分析;此外生成模型也是一个重要的方向,。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号