
PyTorch DataLoader NumberWorkers Deep Learning Speed Limit Increase
![]()
![]()
这意味着训练过程将按顺序在主流程中工作。
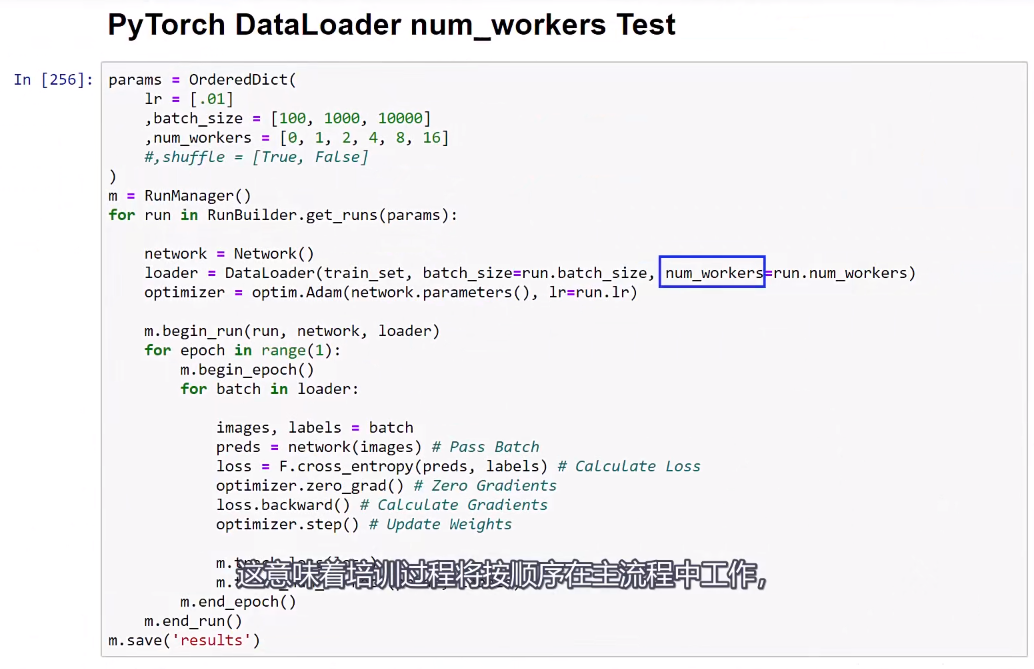




 即:run.num_workers。
即:run.num_workers。




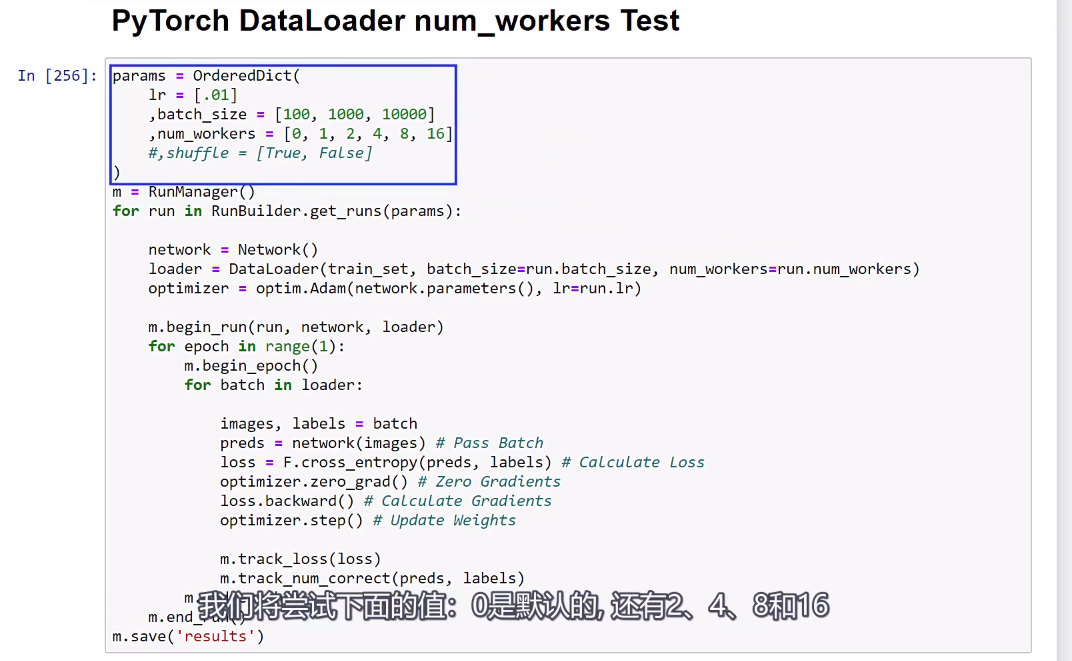





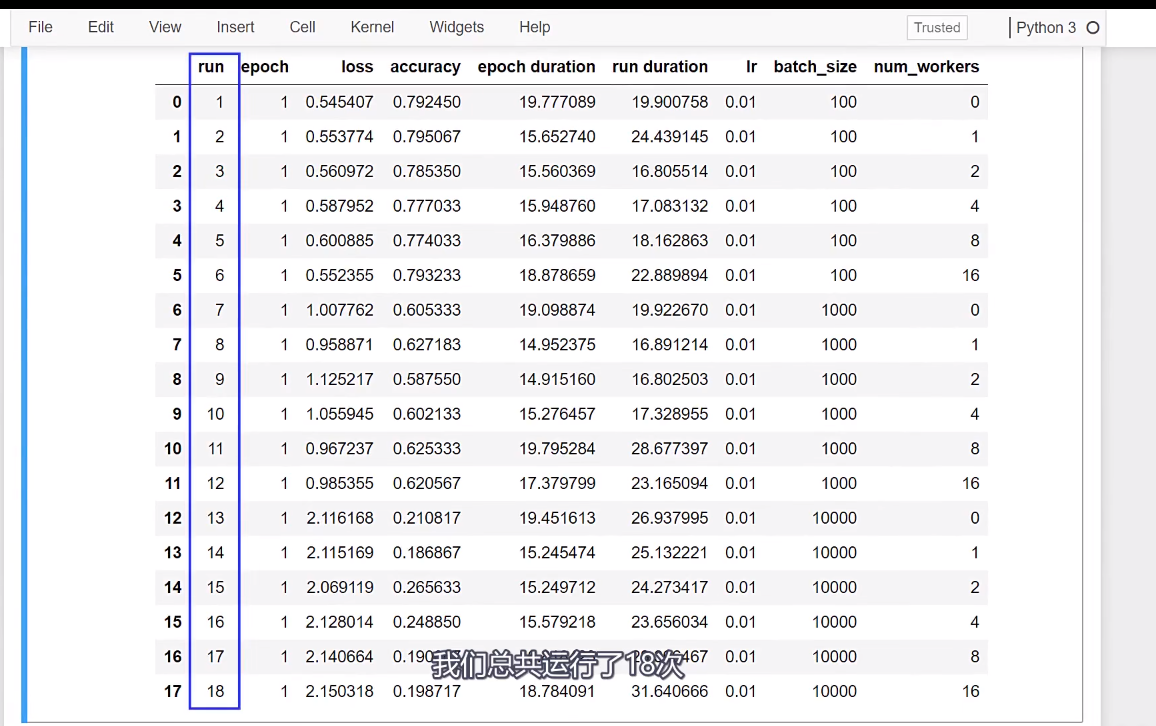
![]()
 ,此外,
,此外,





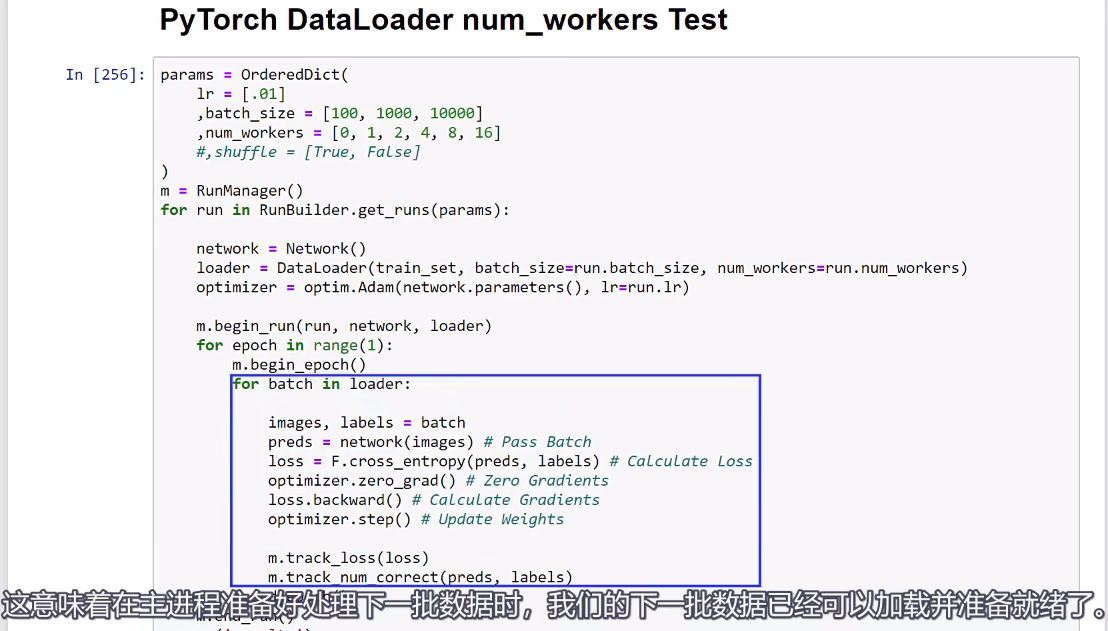
 ,因此,主进程不需要从磁盘读取数据;相反,这些数据已经在内存中准备好了。
,因此,主进程不需要从磁盘读取数据;相反,这些数据已经在内存中准备好了。
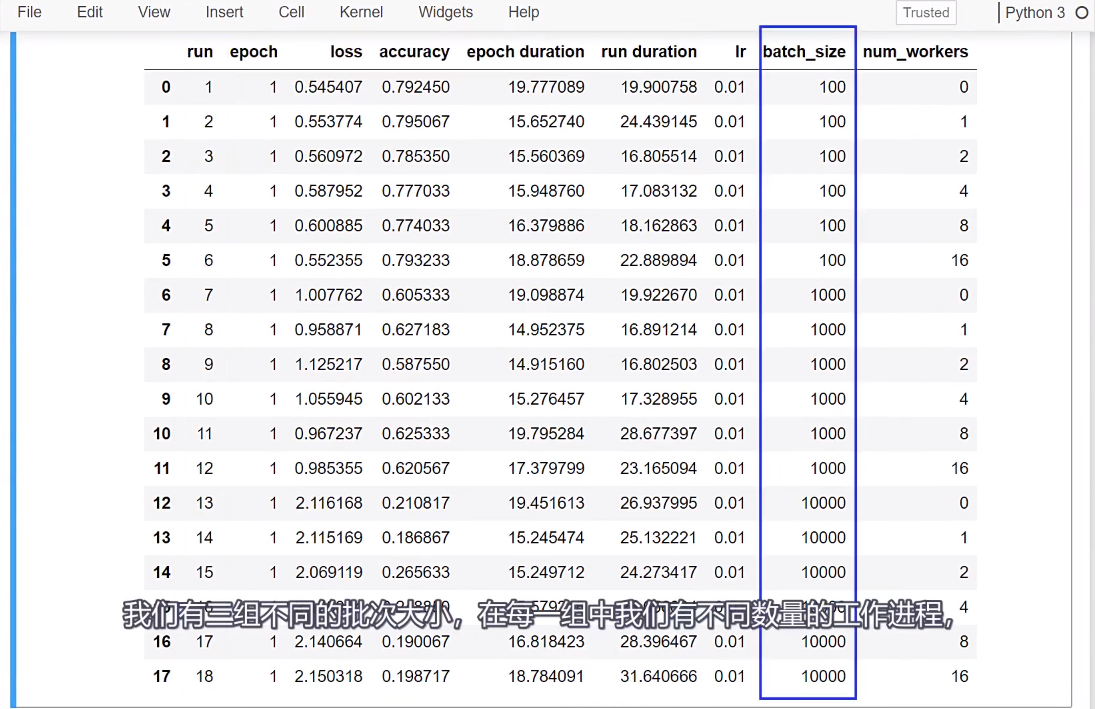
这个例子中,我们看到了20%的加速效果,那么你可能会想, 


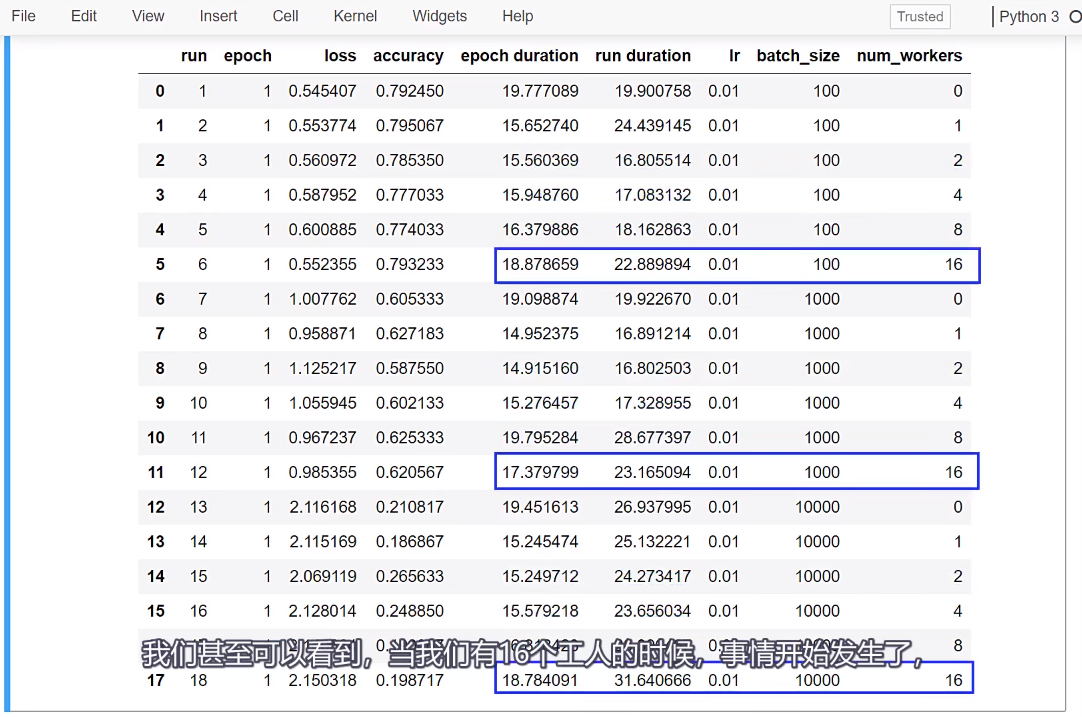
我们考虑一个工人可能足够让队列中充满了主进程的数据,然后将更多的数据添加到队列中,不会在速度上做任何事情。我们在这里看到的就是这些,
只是我们在队列中添加了更多的批次,是否意味着这些批次的加工速度更快?因此,我们受到前向和后向传播所花费的时间的限制,




保存模型,用torch.save()










 浙公网安备 33010602011771号
浙公网安备 33010602011771号