


(九)groupByKey,reduceByKey,sortByKey算子-Java&Python版Spark
groupByKey,reduceByKey,sortByKey算子
视频教程:
1、优酷
2、 YouTube
1、groupByKey
groupByKey是对每个key进行合并操作,但只生成一个sequence,groupByKey本身不能自定义操作函数。
java:
1 package com.bean.spark.trans; 2 3 import java.util.Arrays; 4 import java.util.List; 5 6 import org.apache.spark.SparkConf; 7 import org.apache.spark.api.java.JavaPairRDD; 8 import org.apache.spark.api.java.JavaSparkContext; 9 10 import scala.Tuple2; 11 12 public class TraGroupByKey { 13 public static void main(String[] args) { 14 SparkConf conf = new SparkConf(); 15 conf.setMaster("local"); 16 conf.setAppName("union"); 17 System.setProperty("hadoop.home.dir", "D:/tools/spark-2.0.0-bin-hadoop2.6"); 18 JavaSparkContext sc = new JavaSparkContext(conf); 19 List<Tuple2<String, Integer>> list = Arrays.asList(new Tuple2<String, Integer>("cl1", 90), 20 new Tuple2<String, Integer>("cl2", 91),new Tuple2<String, Integer>("cl3", 97), 21 new Tuple2<String, Integer>("cl1", 96),new Tuple2<String, Integer>("cl1", 89), 22 new Tuple2<String, Integer>("cl3", 90),new Tuple2<String, Integer>("cl2", 60)); 23 JavaPairRDD<String, Integer> listRDD = sc.parallelizePairs(list); 24 JavaPairRDD<String, Iterable<Integer>> results = listRDD.groupByKey(); 25 System.out.println(results.collect()); 26 sc.close(); 27 } 28 }
python:
1 # -*- coding:utf-8 -*- 2 3 from pyspark import SparkConf 4 from pyspark import SparkContext 5 import os 6 7 if __name__ == '__main__': 8 os.environ["SPARK_HOME"] = "D:/tools/spark-2.0.0-bin-hadoop2.6" 9 conf = SparkConf().setMaster('local').setAppName('group') 10 sc = SparkContext(conf=conf) 11 data = [('tom',90),('jerry',97),('luck',92),('tom',78),('luck',64),('jerry',50)] 12 rdd = sc.parallelize(data) 13 print rdd.groupByKey().map(lambda x: (x[0],list(x[1]))).collect()
注意:当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对都移动,这样的后果是集群节点之间的开销很大,导致传输延时。
整个过程如下:
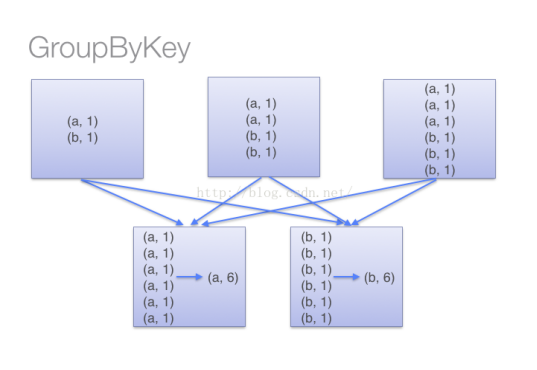
因此,在对大数据进行复杂计算时,reduceByKey优于groupByKey。
另外,如果仅仅是group处理,那么以下函数应该优先于 groupByKey :
(1)、combineByKey 组合数据,但是组合之后的数据类型与输入时值的类型不一样。
(2)、foldByKey合并每一个 key 的所有值,在级联函数和“零值”中使用。
2、reduceByKey
对数据集key相同的值,都被使用指定的reduce函数聚合到一起。
java:
1 package com.bean.spark.trans; 2 3 import java.util.Arrays; 4 import java.util.List; 5 6 import org.apache.spark.SparkConf; 7 import org.apache.spark.api.java.JavaPairRDD; 8 import org.apache.spark.api.java.JavaSparkContext; 9 import org.apache.spark.api.java.function.Function2; 10 11 import scala.Tuple2; 12 13 public class TraReduceByKey { 14 public static void main(String[] args) { 15 SparkConf conf = new SparkConf(); 16 conf.setMaster("local"); 17 conf.setAppName("reduce"); 18 System.setProperty("hadoop.home.dir", "D:/tools/spark-2.0.0-bin-hadoop2.6"); 19 JavaSparkContext sc = new JavaSparkContext(conf); 20 List<Tuple2<String, Integer>> list = Arrays.asList(new Tuple2<String, Integer>("cl1", 90), 21 new Tuple2<String, Integer>("cl2", 91),new Tuple2<String, Integer>("cl3", 97), 22 new Tuple2<String, Integer>("cl1", 96),new Tuple2<String, Integer>("cl1", 89), 23 new Tuple2<String, Integer>("cl3", 90),new Tuple2<String, Integer>("cl2", 60)); 24 JavaPairRDD<String, Integer> listRDD = sc.parallelizePairs(list); 25 JavaPairRDD<String, Integer> results = listRDD.reduceByKey(new Function2<Integer, Integer, Integer>() { 26 @Override 27 public Integer call(Integer s1, Integer s2) throws Exception { 28 // TODO Auto-generated method stub 29 return s1 + s2; 30 } 31 }); 32 System.out.println(results.collect()); 33 sc.close(); 34 } 35 }
python:
1 # -*- coding:utf-8 -*- 2 3 from pyspark import SparkConf 4 from pyspark import SparkContext 5 import os 6 from operator import add 7 if __name__ == '__main__': 8 os.environ["SPARK_HOME"] = "D:/tools/spark-2.0.0-bin-hadoop2.6" 9 conf = SparkConf().setMaster('local').setAppName('reduce') 10 sc = SparkContext(conf=conf) 11 data = [('tom',90),('jerry',97),('luck',92),('tom',78),('luck',64),('jerry',50)] 12 rdd = sc.parallelize(data) 13 print rdd.reduceByKey(add).collect() 14 sc.close()
当采用reduceByKey时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合。 注意在数据对被搬移前同一机器上同样的key是怎样被组合的。
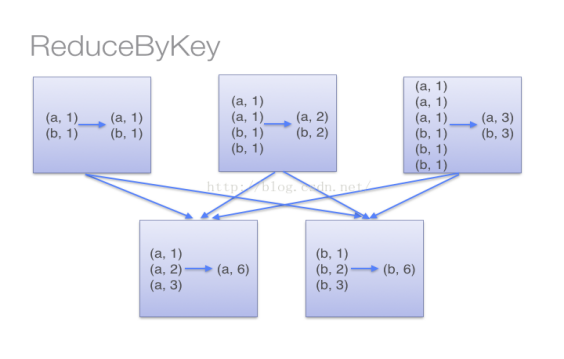
3、sortByKey
通过key进行排序。
java:
1 package com.bean.spark.trans; 2 3 import java.util.Arrays; 4 import java.util.List; 5 6 import org.apache.spark.SparkConf; 7 import org.apache.spark.api.java.JavaPairRDD; 8 import org.apache.spark.api.java.JavaSparkContext; 9 10 import scala.Tuple2; 11 12 public class TraSortByKey { 13 public static void main(String[] args) { 14 SparkConf conf = new SparkConf(); 15 conf.setMaster("local"); 16 conf.setAppName("sort"); 17 System.setProperty("hadoop.home.dir", "D:/tools/spark-2.0.0-bin-hadoop2.6"); 18 JavaSparkContext sc = new JavaSparkContext(conf); 19 List<Tuple2<Integer, String>> list = Arrays.asList(new Tuple2<Integer,String>(3,"Tom"), 20 new Tuple2<Integer,String>(2,"Jerry"),new Tuple2<Integer,String>(5,"Luck") 21 ,new Tuple2<Integer,String>(1,"Spark"),new Tuple2<Integer,String>(4,"Storm")); 22 JavaPairRDD<Integer,String> rdd = sc.parallelizePairs(list); 23 JavaPairRDD<Integer, String> results = rdd.sortByKey(false); 24 System.out.println(results.collect()); 25 sc.close() 26 } 27 }
python:
1 #-*- coding:utf-8 -*- 2 if __name__ == '__main__': 3 os.environ["SPARK_HOME"] = "D:/tools/spark-2.0.0-bin-hadoop2.6" 4 conf = SparkConf().setMaster('local').setAppName('reduce') 5 sc = SparkContext(conf=conf) 6 data = [(5,90),(1,92),(3,50)] 7 rdd = sc.parallelize(data) 8 print rdd.sortByKey(False).collect() 9 sc.close()
