


技术总结
编程语言的分类
1.编译型(c、c++、go、swift、objrct—c、pascal)
编译型是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,执行速度很快,但是开发效率慢。并且不可以跨平台。
2.解释型(java、python、ruby、php、perl、erlang)
解释型则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译型的程序运行的快的,执行效率慢,但是开发效率快,并且可以跨平台
Python的优缺点
先看优点
- Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是简单易懂,初学者学Python,不但入门容易,而且将来深入下去,可以编写那些非常非常复杂的程序。
- 开发效率非常高,Python有非常强大的第三方库,基本上你想通过计算机实现任何功能,Python官方库里都有相应的模块进行支持,直接下载调用后,在基础库的基础上再进行开发,大大降低开发周期,避免重复造轮子。
- 高级语言————当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节
- 可移植性————由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工 作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就几乎可以在市场上所有的系统平台上运行
- 可扩展性————如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
- 可嵌入性————你可以把Python嵌入你的C/C++程序,从而向你的程序用户提供脚本功能。
再看缺点:
- 速度慢,Python 的运行速度相比C语言确实慢很多,跟JAVA相比也要慢一些,因此这也是很多所谓的大牛不屑于使用Python的主要原因。(我喜欢就行,我又不是大牛)
- 代码不能加密,因为PYTHON是解释性语言,它的源码都是以名文形式存放的,不过我不认为这算是一个缺点,如果你的项目要求源代码必须是加密的,那你一开始就不应该用Python来去实现。(加密也没个啥用。)
- 线程不能利用多CPU问题,这是Python被人诟病最多的一个缺点。(会优化)
‘‘’密码本(编码库)’’’
首先编码是什么?(面试会考)
简单来说就是我们所认知的语言,和计算机能识别的语言,他们之间存在这这种一一对应的关系。而计算机能识别的语言,叫编码。(为什么称之为密码本,像电视剧中的抗战片,电报摩斯码,01010101什么的,这个就是编码,通过密码本我们可以知道传递过来的信息是什么意思。)
ASCII码:
最初的编码库,八位表示一个字符,也就是一字节一个字符
只能表示字母,字符
Unicode码:
统一码、万国码、单一码,
最少由 16 位来表示一个字符,就是2字节一个字符。
中文用32位来表示,就是4个字节一个字符。
(老师说这厮浪费资源)
Utf-8码:
Unicode码的升级版,最少8位一个字符,欧洲字符用16位,亚洲字符24位。中文(3个字节一个字符)
Gbk码:
Gbk是各国有各国的,在utf-8出来之前,代替用的,中文用两2个字节表示1个字符
Python中注释的符号
# 嘤嘤嘤(快捷键 Ctrl+/)
’’’嘤嘤嘤’’’
”””嘤嘤嘤””””
这三种。
变量 *****(重要)
变量是什么? 变量:把程序运行的中间结果临时的存在内存里,以便后续的代码调用。
在pycharm中输入(注意:从今以后输入程序中的“()”要用英文版本,要不然会报错)
name = (’L公子’) # name变量被设定成L公子
print(name) #打印出这个name;
print就是打印的意思。
这两句话的相当于在内存中创建了一个name的变量,这name这个变量,现在是背设定成了L公子。
上面那两个程序敲入pycharm中按回车得到了L公子
变量的设定的规律
- 变量只能是字母,数字,下划线(“_”)的任意排列组合
- 变量第一个字符不能是数字。例:1aaa = (‘L公子’)
- 不能是关键词['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
- 变量不可以是中文
- 变量要具有可描述性,例如:name = (‘L公子’);age = 18
- 变量不宜过长。
- 变量推荐驼峰体和下划线体
例:AgeOfLGongZi(驼峰体)
age_of_l_gong_zi(下划线)(推荐)
变量之所以称之为变量因为它是可变的
name = (‘L公子’) #name变量被设定成L公子
name = (‘Lgongzi’) #name变量被设定成Lgongzi
print(name)
则输出
Lgongzi
因为python是一条一条从上到下编译,第一句name变量被设定成L公子,但是第二句name变量被设定成了Lgongzi,因此打印出来的结果就是Lgongzi。
常量
常量即指不变的量,如圆周率π = 3.141592653..., 或在程序运行过程中不会改变的量
在Python中没有一个专门的语法代表常量,程序员约定俗成用变量名全部大写代表常量
基础数据类型
我们人类可以很容易的分清数字与字符的区别,但是计算机并不能呀,计算机虽然很强大,但从某种角度上看又很傻,除非你明确的告诉它,1是数字,“汉”是文字,否则它是分不清1和‘汉’的区别的,因此,在每个编程语言里都会有一个叫数据类型的东东,其实就是对常用的各种数据类型进行了明确的划分,你想让计算机进行数值运算,你就传数字给它,你想让他处理文字,就传字符串类型给他。Python中常用的数据类型有多种,先暂只讲3种, 数字、字符串、布尔类型
Type()这个码是用来查看数据类型的
Pycharm中敲入:
a = 666
b = ('L公子')
c = (1<2)
print(a,type(a))
print(b,type(b))
print(c,type(c))
输出结果为:
666 <class 'int'>
L公子<class 'str'>
True <class 'bool'>
整数类型(int)。
1. 数字型字符类型int
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
2. 字符串类型(str)
在Python中,加了引号的字符都被认为是字符串!
那单引号、双引号、多引号有什么区别呢? 让我大声告诉你,单双引号木有任何区别,只有下面这种情况 你需要考虑单双的配合
msg = "My name is L , I 'm 18 years old!"(因为i‘m所以使用单引号会报错,所以使用双引号)
多引号什么作用呢?作用就是多行字符串必须用多引号
在pycharm中敲入:
msg = '''
今天我想写首小诗,
歌颂我的同桌,
你看他那乌黑的短发,
好像一只炸毛鸡。'''
print(msg)
回车则会显示这首诗。(这种情况推荐使用三引号)
字符串拼接
数字可以进行加减乘除等运算,字符串呢?让我大声告诉你,也能?what ?是的,但只能进行"相加"和"相乘"运算,并且只能与数字想乘。
相加例子:
name1 = (‘Lgongzi’)
name2 = (‘L公子’)
print(name1 + name2)
则会显示:
LgongziL公子
相乘例子:
如敲入
name1 = (‘L公子’)
print(name1 *3)
则会显示
L公子L公子L公子
3.布尔值(True,False)。
布尔类型很简单,就两个值 ,一个True(真),一个False(假), 主要用记逻辑判断
但其实你们并不明白对么? let me explain, 我现在有2个值 , a=3, b=5 , 我说a>b你说成立么? 我们当然知道不成立,但问题是计算机怎么去描述这成不成立呢?或者说a< b是成立,计算机怎么描述这是成立呢?
没错,答案就是,用布尔类型
布尔类型只会表示True,False!
敲入:
a = 1
b = 3
print( a < b )
输出
True
格式化输出
现有一练习需求,问用户的姓名、年龄、工作、爱好 ,然后打印成以下格式
------------ info of L公子 -----------
Name : L公子
Age : 18
job : studen
Hobbie: girl
------------- end -----------------
你怎么实现呢?你会发现,用字符拼接的方式还难实现这种格式的输出,所以一起来学一下新姿势
只需要把要打印的格式先准备好, 由于里面的 一些信息是需要用户输入的,你没办法预设知道,因此可以先放置个占位符,再把字符串里的占位符与外部的变量做个映射关系就好啦
name = input("Name:")
age = input("Age:")
job = input("Job:")
hobbie = input("Hobbie:")
info = '''
------------ info of %s ----------- #这里的每个%s就是一个占位符,本行的代表 后面拓号里的 name
Name : %s #代表 name
Age : %s #代表 age
job : %s #代表 job
Hobbie: %s #代表 hobbie
------------- end -----------------''' %(name,name,age,job,hobbie) # 这行的 % 号就是 把前面的字符串 与拓号 后面的 变量 关联起来
print(info)
%s就是代表字符串占位符,除此之外,还有%d,是数字占位符, 如果把上面的age后面的换成%d,就代表你必须只能输入数字啦
age : %d
我们运行一下,但是发现出错了。。。
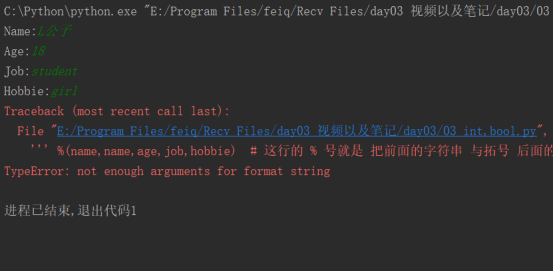
说%d需要一个数字,而不是str, what? 我们明明输入的是数字呀,18呀。
不用担心 ,不要相信你的眼睛我们调试一下,看看输入的到底是不是数字呢?怎么看呢?查看数据类型的方法是什么来着?type()
name = input("Name:")
age = input("Age:")
print(type(age))
执行输出是
Name:L公子
Age:18
<class 'str'> #怎么会是str
Job:student
让我大声告诉你,input接收的所有输入默认都是字符串格式!
要想程序不出错,那怎么办呢?简单,你可以把str转成int
age = int( input("Age:") )
print(type(age))
肯定没问题了。相反,能不能把字符串转成数字呢?必然可以,str( yourStr )
问题:现在有这么行代码
msg = "我是%s,年龄%d,目前学习进度为80%"%('L',18)print(msg)
这样会报错的,因为在格式化输出里,你出现%默认为就是占位符的%,但是我想在上面一条语句中最后的80%就是表示80%而不是占位符,怎么办?
msg = "我是%s,年龄%d,目前学习进度为80%%"%('L',18)
print(msg)
这样就可以了,第一个%是对第二个%的转译,告诉Python解释器这只是一个单纯的%,而不是占位符。

