【RocketMQ源码分析】深入消息存储(1)

最近在学习RocketMQ相关的东西,在学习之余沉淀几篇笔记。
RocketMQ有很多值得关注的设计点,消息发送、消息消费、路由中心NameServer、消息过滤、消息存储、主从同步、事务消息等等。
本篇不需要你有使用RocketMQ的前置条件,完全从消息存储的直接实现上来分析RocketMQ的Store包。
0.队列文件存储思考
在开始之前,先来做一个简单思考。
MQ既然要接收大量的消息,这些消息如果全部存在内存,是否可行呢?

在机器内存的限制下当然不行,那么就要考虑非内存的存储方式。
数据库?
听上去很奇葩,但真有这么实现的,ActiveMQ。
本地磁盘?
这个太慢了,如果我存储的消息也支持我顺序读,那还好,如果涉及到各种消息特性,速度一定会慢很多。
本地磁盘虽然慢,但是它的容量很大。
内存容量虽然小,但是它的速度很快。
所以,能不能有一种折中的方法,即用到内存又用到本地磁盘。
我想出了一种填充和交换算法,根据需要将固定大小(例如128M)的页面文件映射到内存中,并在固定的生存时间(TTL)时间内未访问该文件时取消映射。 通过这种设计,我不仅可以更安全,更有效地使用内存,而且可以在需要时删除一些用过的页面文件以节省磁盘空间。
MQ顾名思义是消息队列。
队列是一种前置读、后置追加的结构,那么只需要将队列的前部分和后部分放入内存,中间部分在磁盘操作,就能保证高效、大容量操作。
读取和追加操作总是可以发生在内存中,这意味着入队和出队操作总是接近O(1)访问速度。
但如果想要读取在磁盘上的数据,速度还是会降下来,为此,我们可以再维护一份索引,记录目标消息在磁盘文件上的偏移量,以随机读接口去访问。
至此,一个很实用的队列文件存储系统就有眉目了。
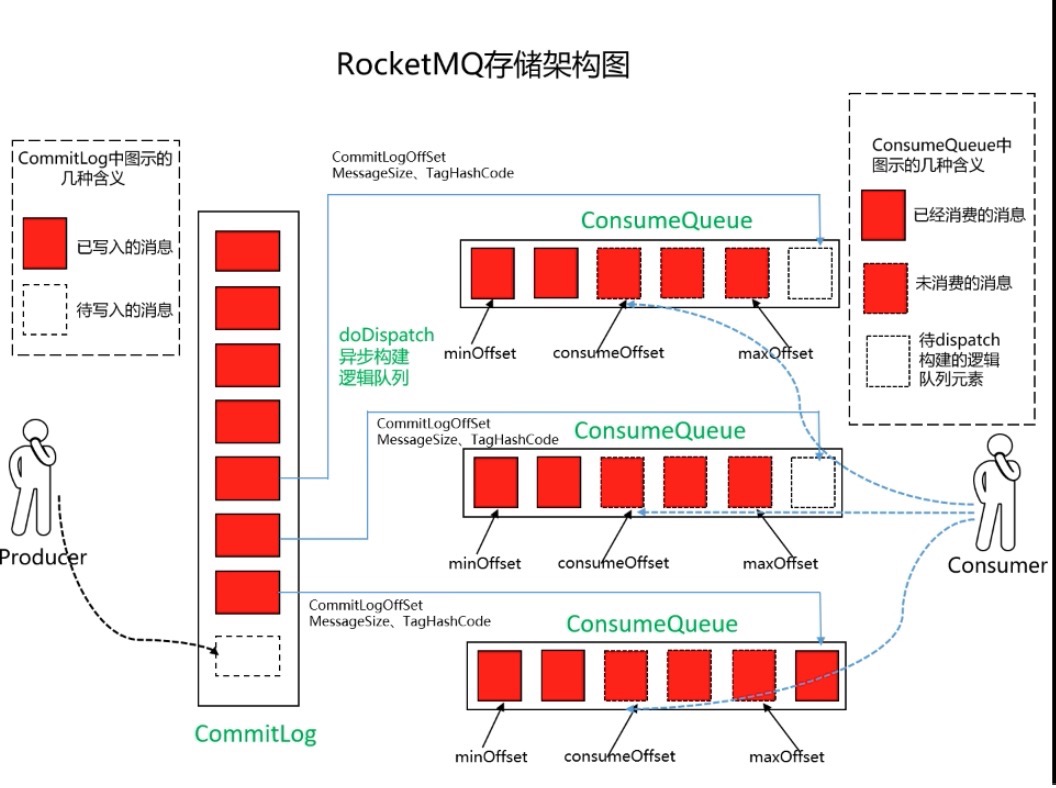
1.RocketMQ文件存储架构
RocketMQ会将消息存储到本地文件,这样我们的消息都可以保证可查,也可以在系统故障时恢复。
不同于Kafka那种分区的存储方式,RocketMQ是将消息都存储到CommitLog中,不会区分消息的Topic、Group等信息。
默认路径在C盘用户空间下的store目录。

每个CommitLog都有固定的大小。
所有生产者的消息都会写道CommitLog文件中,因为在磁盘上,读取起来并不是很快,所以还需要一个类似于索引的文件。
这就是ConsumeQueue,也就是逻辑上的队列。

ConsumeQueue中存放的CommitLog Offset是消息在CommitLog中的偏移位置,也就是坐标,保证能使用随机读来快速定位。
此外还有消息的大小Size,也就是CommitLog指定位置我需要读取多少个字节。
最后是消息Tag的哈希值,Message Tag Hashcode,用来过滤消息。
CommitLog是MQ接收到消息后直接写入本地文件的,而ConsumeQueue这个类似CommitLog索引的结构,是异步构建的,它是一种逻辑上的队列结构。
去看本地的存储文件,可以发现ConsumeQueue的目录结构很有意思。

它是以Topic为主目录,队列id为次目录的层级存储的。
而ConsumeQueue的存储单元根据我们上面那副图的计算,可以得到每个消息在ConsumeQueue中的大小是20Byte。
CommitLog Offset : 8 Byte
Size : 4 Byte
Message Tag Hashcode : 8 Byte
ConsumeQueue上还有一些其他的数据,是消费者消费消息的位置。
综上,我们可以得到一张RocketMQ的存储架构图。
2.源码分析
有了CommitLog和ConsumeQueue的概念,我们可以简单过一边消息存储流程的代码了。
RocketMQ的文件存储部分代码不需要启动NameServer、Broker等节点就可以单机运行,具体可以参考RocketMQ源码Store包下的Test用例。
第一步需要先实例化Store的配置。
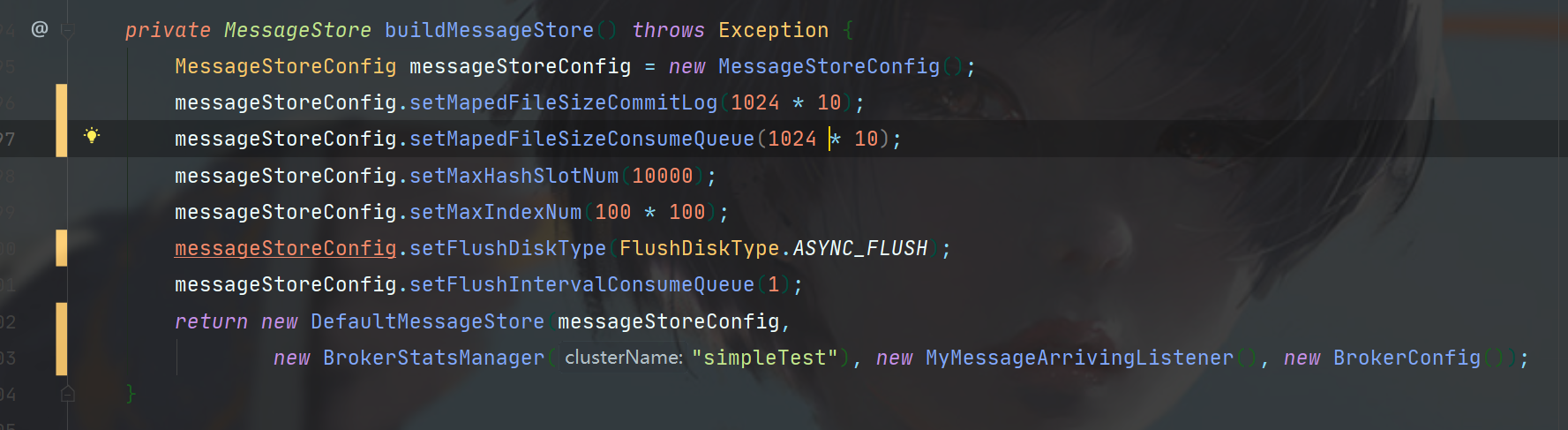
指定CommitLog、ConsumeQueue文件的大小,以及刷盘机制是同步还是异步,ConsumeQueue的异步构建时间间隔。
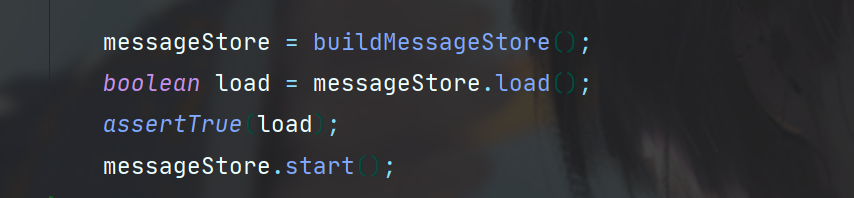
之后load、start即可,此处MessageStore实例是RocketMQ消息存储系统的核心类,DefaultMessageStore,其putMessage方法就是消息写入磁盘文件的入口方法。
实例化DefaultMessageStore后,就可以构建一个简单的消息,使用putMessage方法写入了。

使用putMessage。

此时就进入了org.apache.rocketmq.store.DefaultMessageStore#putMessage。
在这里有六个前置校验。

- 校验DefaultMessageStore实例初始化状态,在上一步messageStore进行start时,会完成CommitLog文件channel的初始化等操作,所以此处需要校验是否准备完毕。
- 当前节点是否是从节点,只有主节点才对消息进行存储。
- 是否可写
- Topic长度是否过长
- 配置属性是否过多
- 操作系统分页缓存是否忙碌状态
通过了上述六步校验,就可以进行文件存储了。
下面是DefaultMessageStore#putMessage剩余的过程,看上去很简单。
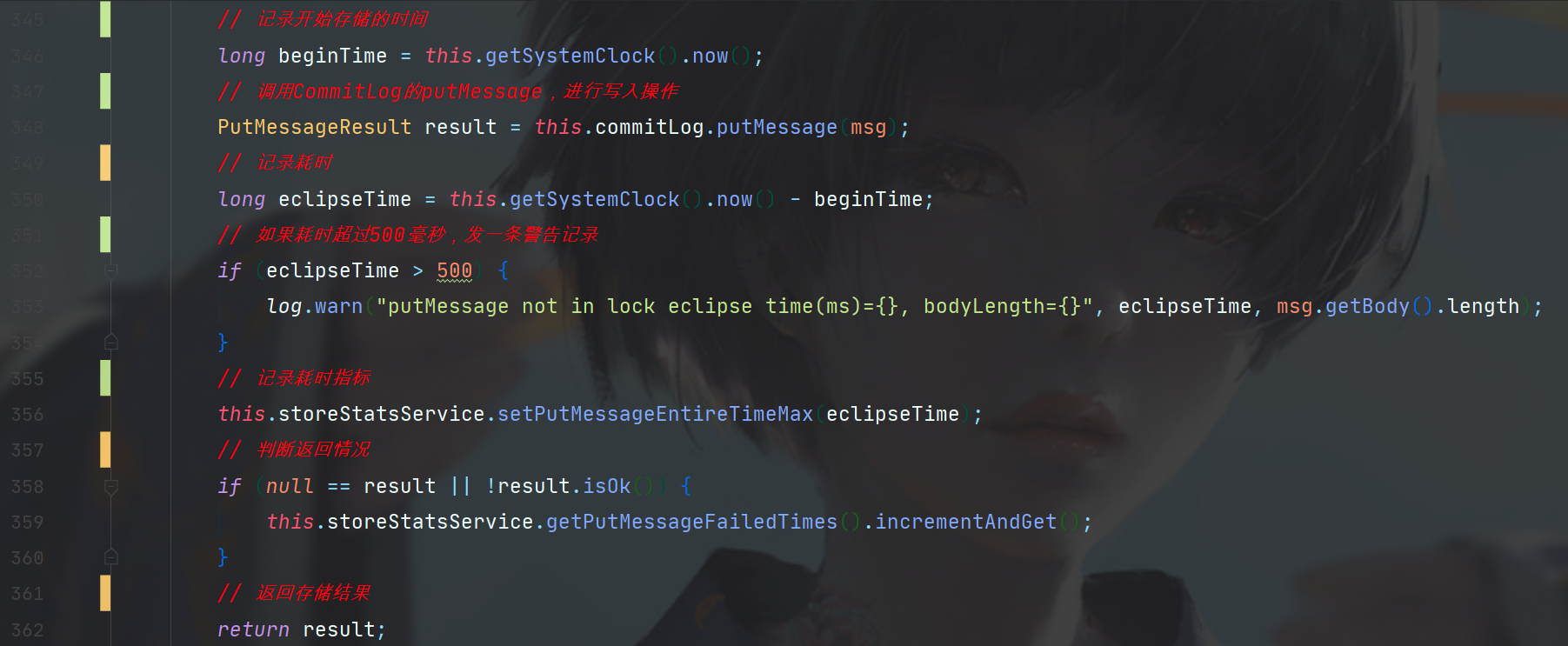
这里主要是在调用CommitLog的putMessage前后记录了耗时,并且如果耗时超过500毫秒就发出一次告警日志,然后是StoreStatusService进行的一系列指标监控,StoreStatusService会记录下Store一切操作的指标记录,用于一些RocketMQ控制台应用去展示节点状态等信息。
然后我们进入org.apache.rocketmq.store.CommitLog#putMessage。
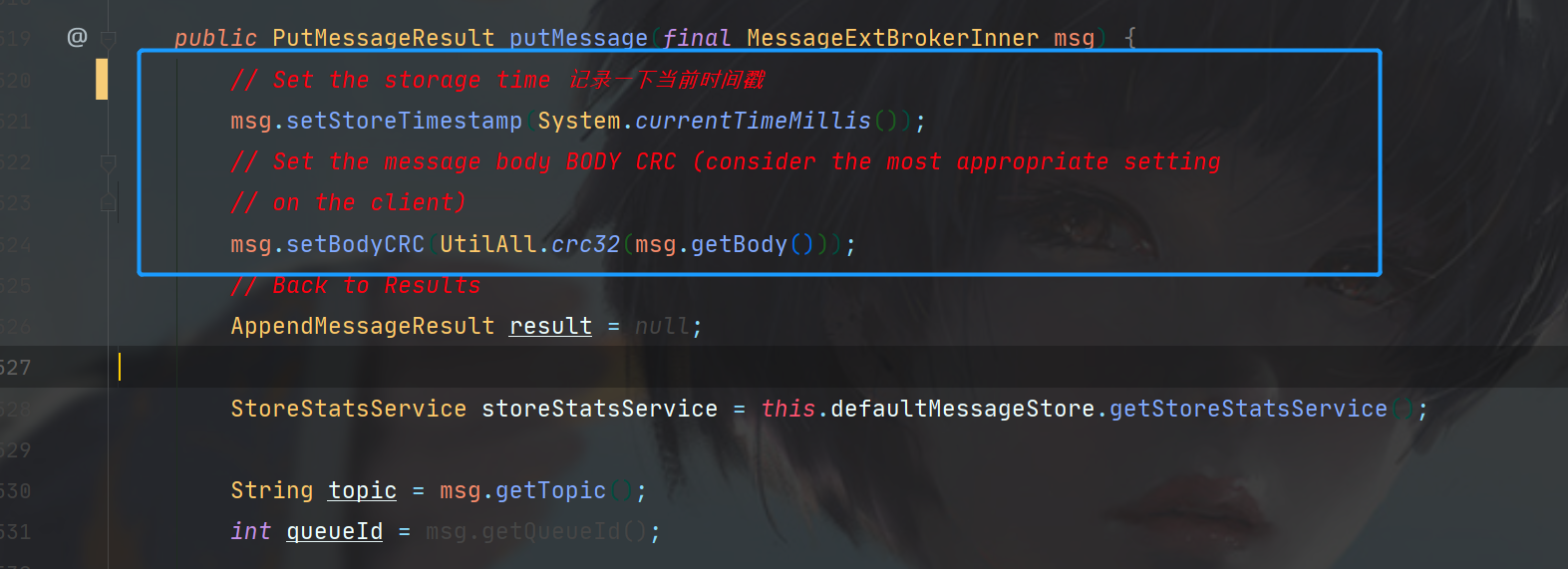
在开始,先是在消息中写入了时间戳,然后根据消息内容计算了校验码,防止消息被篡改。

接着判断了一下当前消息是不是事务消息,如果是事务消息,则判断是不是延迟消息,这里不做深入。
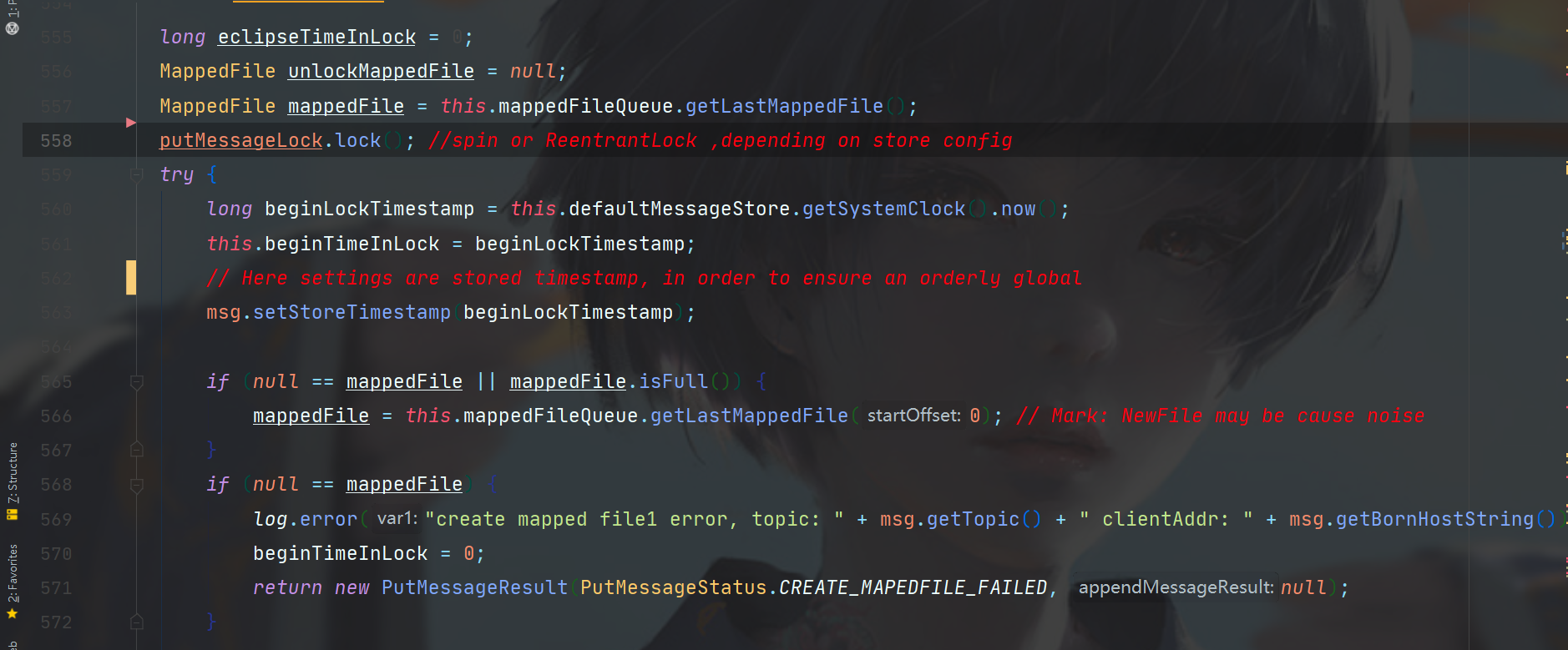
接下来就到了RocketMQ消息存储的一个核心类了,MappedFile。
MappedFile就是我们最开始思考中的实现随机读的关键,它将内存和文件创建了映射关系,每一个MappedFile都指向一个CommitLog,我只要知道消息的位置(ConsumeQueue中存储的有),就可以快速利用MappedFile去设置偏移位置读取到该消息,当我们需要写入时,MappedFile中也存储的有CommitLog当前以及写到哪里的记录,只需要在把偏移位置设置到那里,进行写入即可。
总的来说,就是结合了顺序写,随机读,保证读写都是高效的O(1)。
当然我们不止一个CommitLog,那么也不止一个MappedFile实例,为此,有一个MappedFileQueue来存储它,下图是我本地Debug时MappedFileQueue实例的内容。
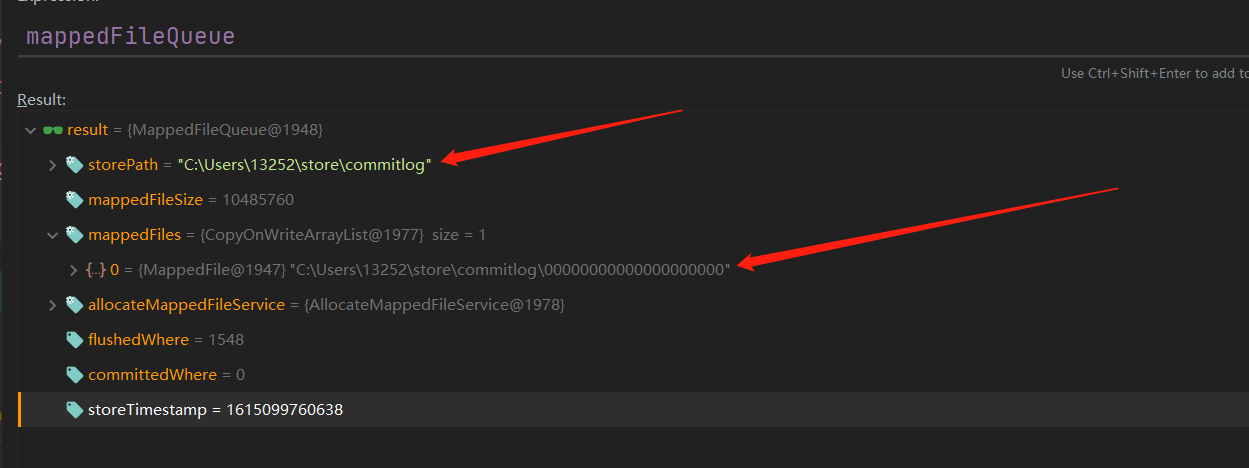
因为我本地消息写入较少,完全还没有用到第二个CommitLog,所以Queue中只有一个MappedFile,而这个MappedFile也指向一个CommitLog。
我们在将消息写入CommitLog时,需要拿到最靠后的那个CommitLog,因为写入操作只会在最后面添加消息。
所以此处我们需要调用this.mappedFileQueue.getLastMappedFile()来获取最后一个MappedFile。

有了MappedFile,我们就要开始真正对磁盘文件进行操作,此时需要上锁,官方给的注释说此处是自旋锁or可重入锁都可以,当然需要看场景,如果你的机器CPU强大,当然推荐自旋锁了。
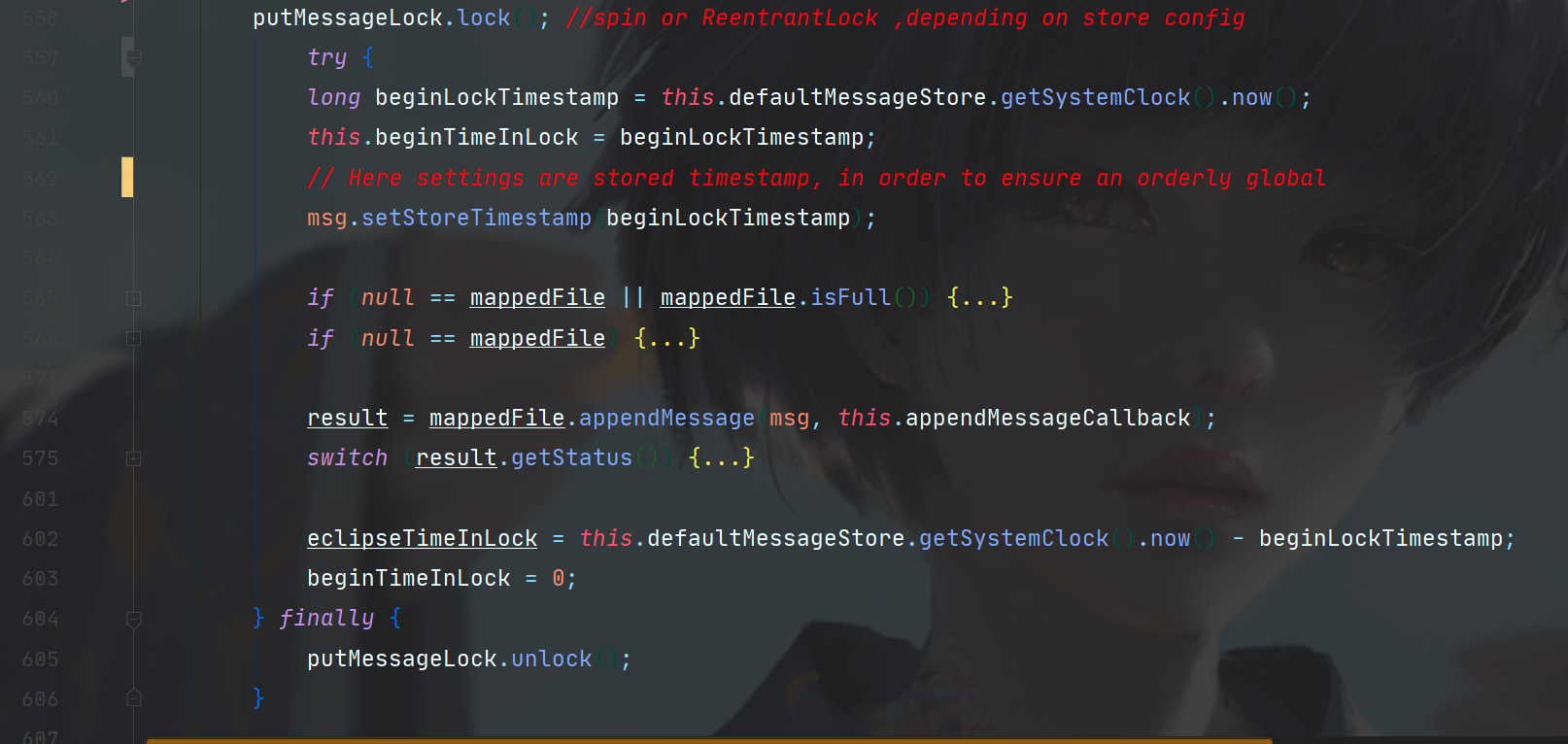
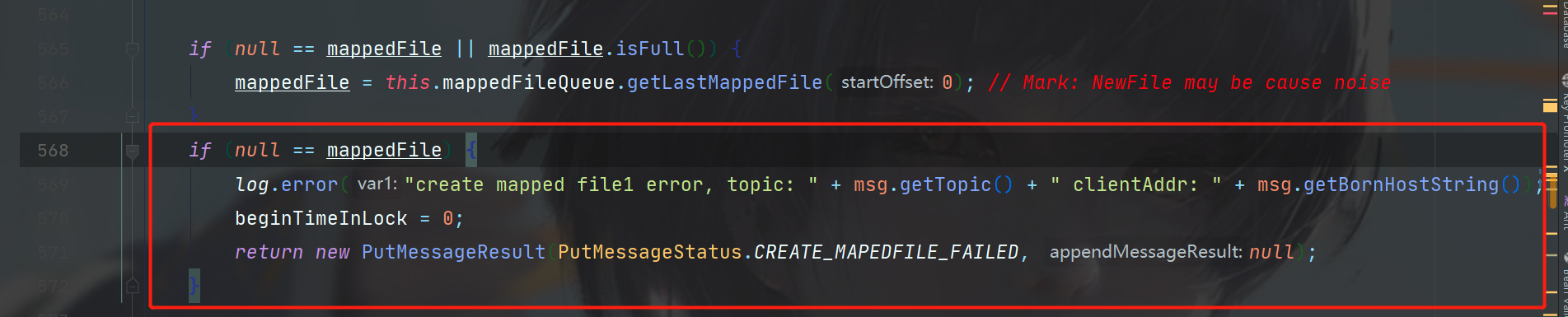
在try-catch中,再次对消息的存储时间戳进行了设置(还记得前面已经设置过一次了吗),然后判断你拿到的mappedFile是不是null,或者mappedFile是不是已经满了,如果是这样,如下图,就需要重新创建一个CommitLog了。

如果创建之后还是null,就返回写入失败。
接着,就要调用MappedFile的appendMessage方法去向磁盘文件写入消息了。

这里返回结果也会去校验status,根据不同的status去包装不同的返回结果。
在进入MappedFile#appendMessage之前,让我们把CommitLog的putMessage方法看完,看看写入成功后干了什么。
震惊!居然是主从同步和刷盘操作!这里不进去看代码了,但是了解一下相关概念。
主从同步中该节点会把自己CommitLog的内容同步给其他节点,这里可以看到,每次有新消息都会去同步,是实时性的。
刷盘,MappedFile虽然写入了,但其实是位于Buffer中的,只有刷一次才会到本地磁盘,至于刷盘是同步还是异步刷,异步多久刷,就要看你store配置了(记得最开始实例化DefaultMessageStore时候的配置吗)
扯完这些,就可以进入MappedFile#appendMessage一探究竟了。
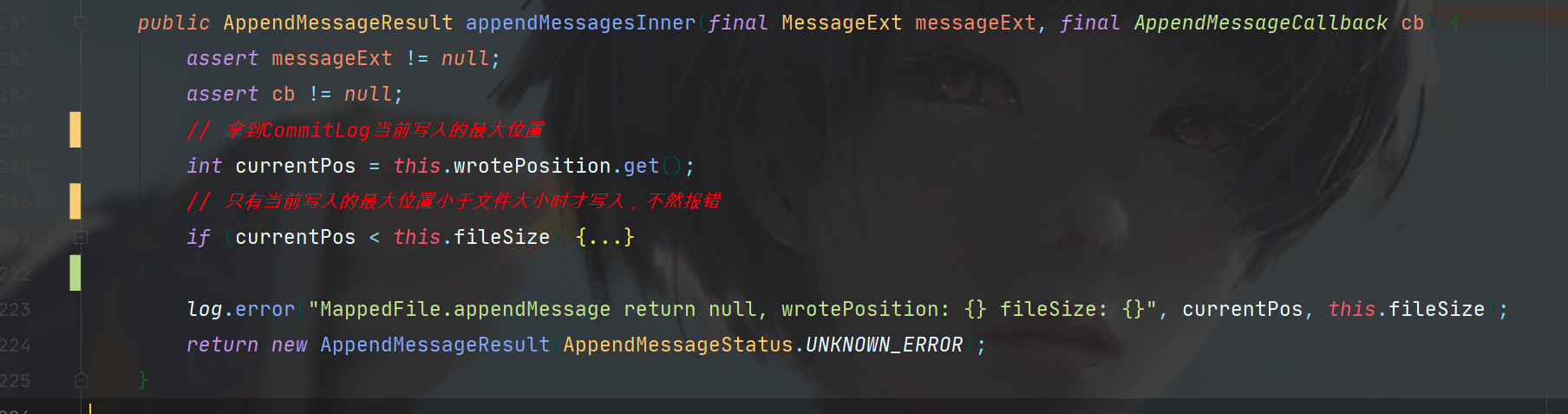
先看看概览,首先是拿到了CommitLog目前写入了多少,作为当前写入位置,然后于CommitLog文件大小比较,如果大于,那肯定有问题了,会报错,如果小于,就开始接下来的步骤。
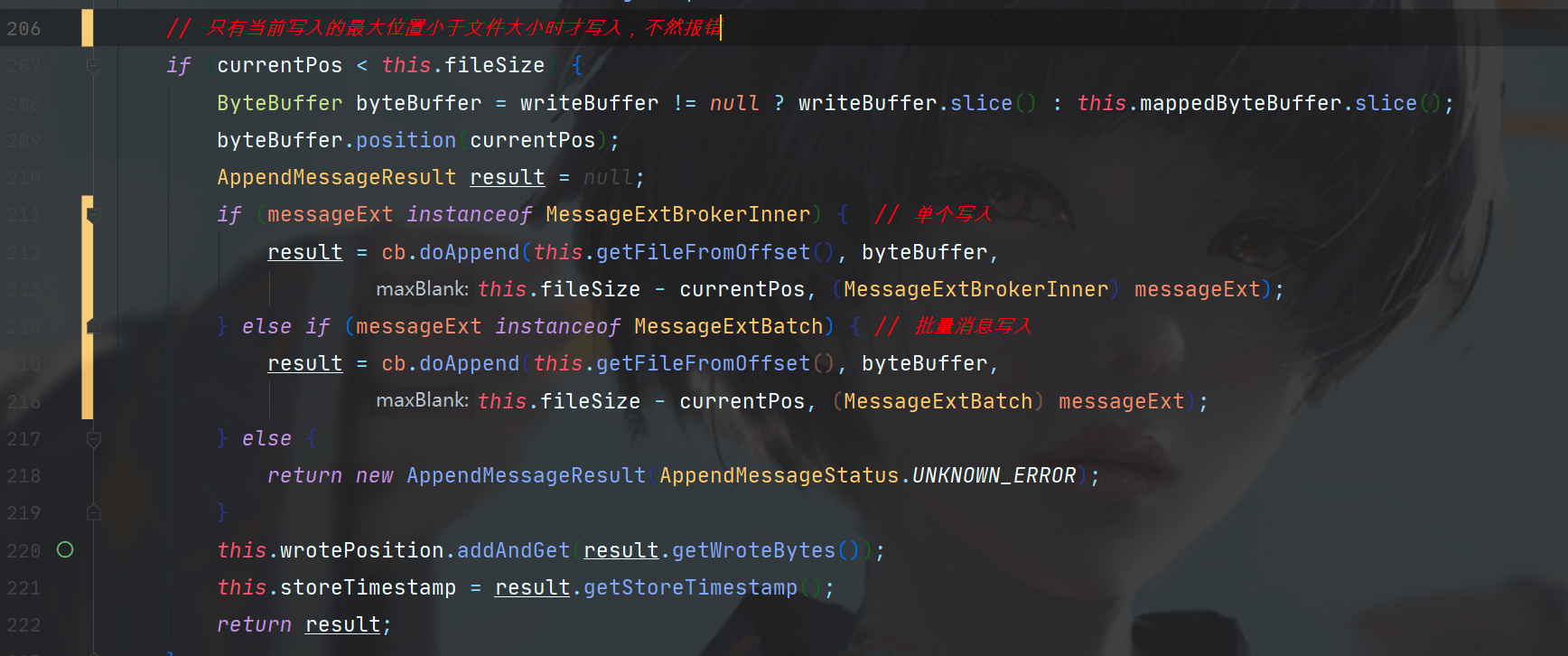
首先拿到了MappedFile对于CommitLog操作的ByteBuffer,这不就简单了,写就完事儿了。
接着设置ByteBuffer要操作的位置。
下面有两种操作方法,一个是单个消息写入,一个是批量,我们来看单个消息写入的,doAppend。
doAppend传入的参数有fileFromOffset,你可以理解它就是CommitLog的名字,因为CommitLog文件名本身就是存储的偏移,只是分成多个文件而已,ByteBuffer, 还有一个文件大小减去当前偏移位置的值,可以理解为当前CommitLog还可以写入多少,最后一个参数是消息内容。
cb.doAppend(this.getFileFromOffset(),
byteBuffer,
this.fileSize - currentPos,
(MessageExtBrokerInner) messageExt);
doAppend方法位于CommitLog中,这里是本次消息写入源码分析的最后一个函数了,在这个方法中,主要是对消息进行序列化操作,以及buffer的写入。

首先,根据buffer的偏移和CommitLog文件的偏移,计算出这个消息真正的下表位置,这个值只会出现在ConsumeQueue,因为ConsumeQueue存储的是相对于所有CommitLog的偏移,而不是在单个CommitLog文件中的偏移,因此需要加上CommitLog本身的偏移位置。
接着是消息id,根据MessageDecoder创建即可,这个id会存储在内存,是一个Topic和Topic下的队列id组成的Table。
具体实现。
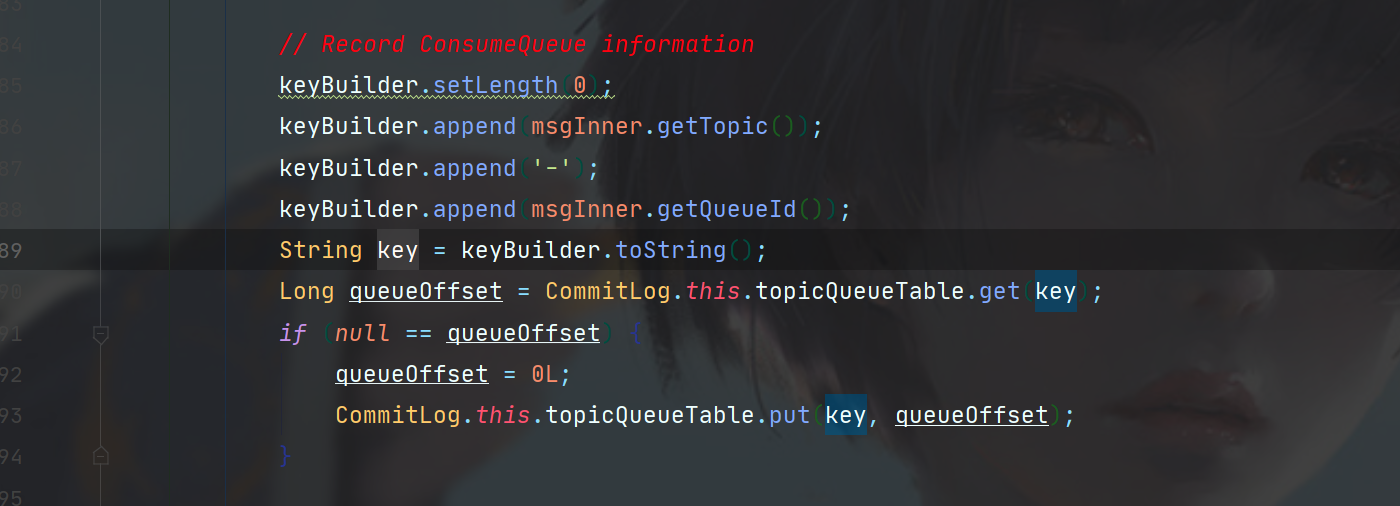
再接着是一大段对消息配置序列化的操作。
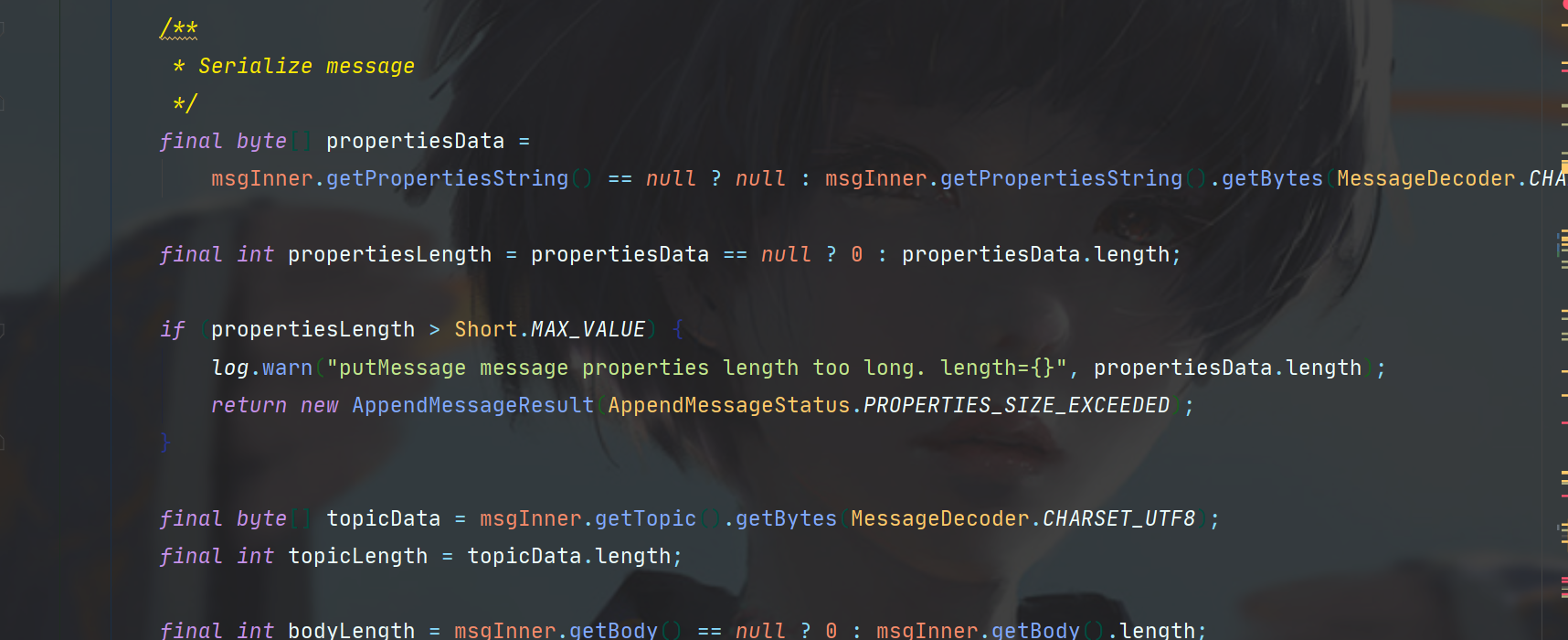
序列化完成后,我们有消息的长度,就知道这条消息在CommitLog中占有的空间大小了,因此需要判断一下够不够塞。
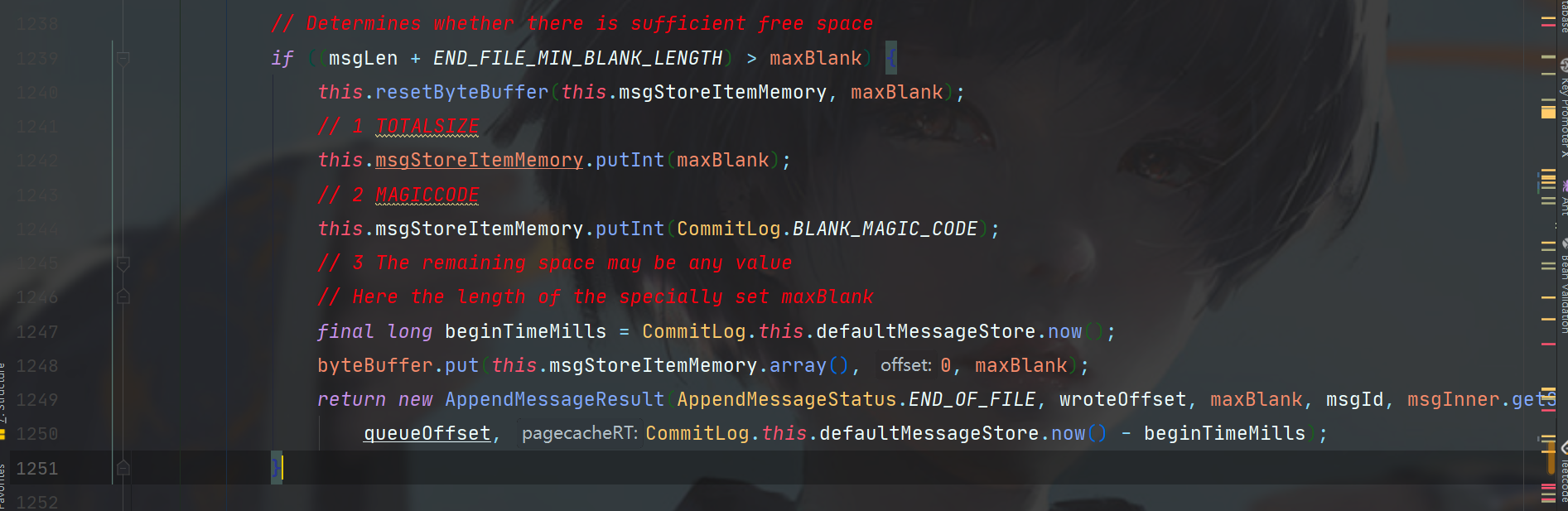
这里if的逻辑可以理解为消息的大小加上CommitLog的文件终止符需要小于CommitLog文件的剩余空间。
这个文件终止符其实就是魔数,UNIX系统文件中随处可见,操作系统启动引导中也是,可以理解为用一个特殊的数在磁盘中做空间区分的。
// File at the end of the minimum fixed length empty
private static final int END_FILE_MIN_BLANK_LENGTH = 4 + 4;
如果大小不够就返回错误。
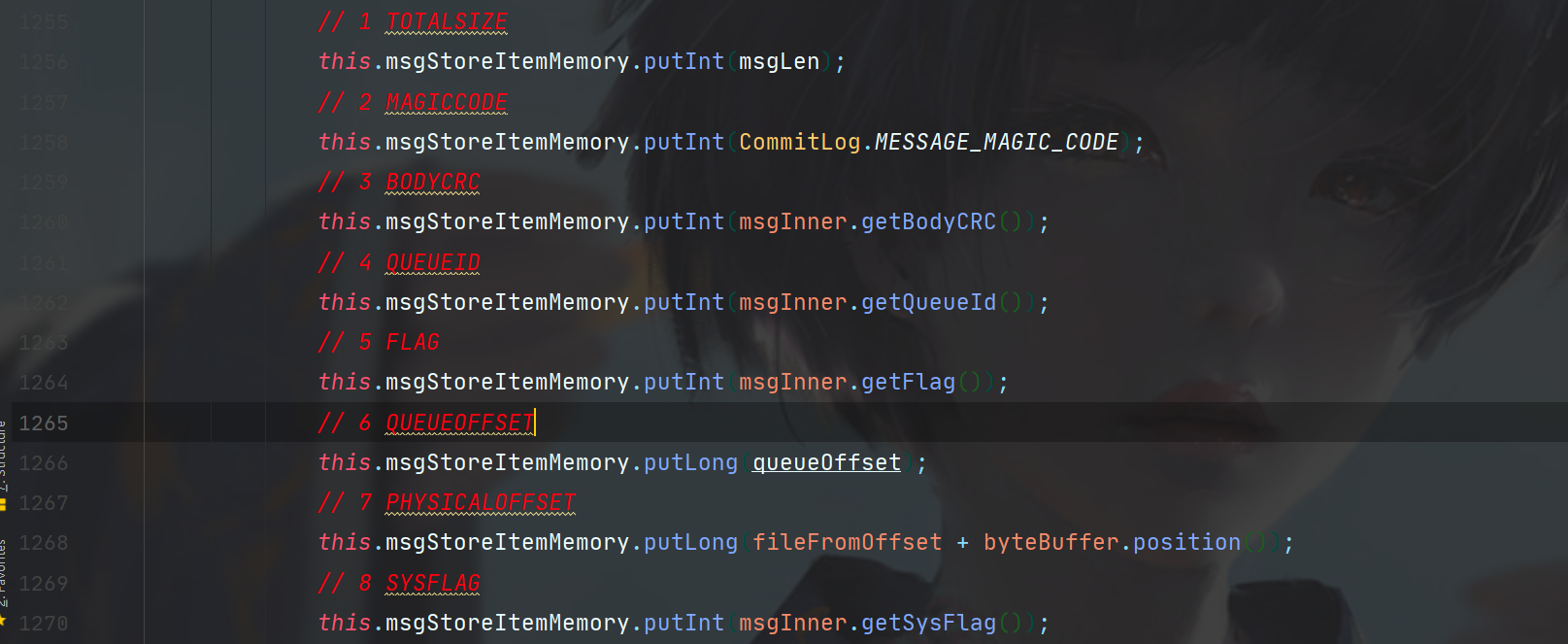
如果空间足够,就开始写入消息,写入消息的格式可以参考下图CommitLog的Message规范。

对比上图,消息写入规范完全符合。
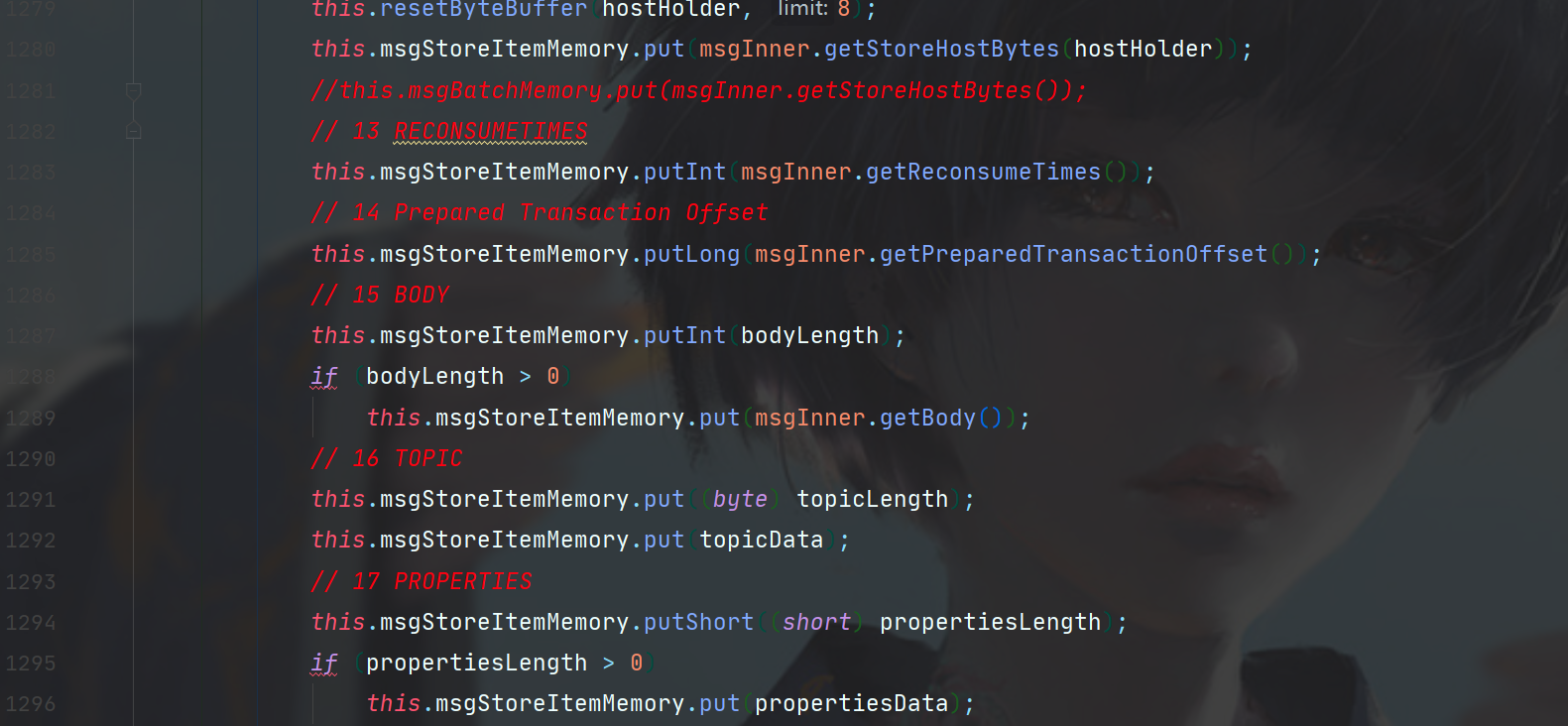
最后,将消息放入buffer中,返回成功

综上,消息写入就完成了,不过此时消息只是写入了Buffer,还需要等后续刷盘才会持久化到磁盘。
作者: AntzUhl
首发地址博客园:http://www.cnblogs.com/LexMoon/
代码均可在Github上找到(求Star) : Github
个人博客 : http://antzuhl.cn/
公众号 |
 |
赞助
支付宝 |
微信 |
 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号