QCon笔记~《天下武功,唯快不破——面向云原生应用的Java冷启动加速技术》
上周去听了QCon全球开发大会,其中有几场印象比较深刻的分享,除去几个比较概念化的话题,在Java技术演进这个Topic里的几个分享都是比较有干货的(但感觉工作中用不到)
首先是关于林子熠老师分享的冷启动加速技术,听完后这几天也在思考分享中所说敢叫日月换新天的创建型技术与现有静态编译语言的对比。
演讲:天下武功,唯快不破:面向云原生应用的冷启动加速技术
分享人: 林子熠(层风) 博士 阿里巴巴 /技术专家
Java从诞生到现在已经经过了26年,在这段时间由于Java语言功能强,峰值性能高,生态支持好的特点,在市场上取得了具有引导性的地位,在这26年,Java应用在不断的发展演进,从最开始的单机版到web应用再到现在的service云原生应用,在发展的过程中也不断遇到了各种各样新的挑战,也带来了机遇促进Java向前发展,在云原生时代的应用都带来了新的特点,比如说云原生的应用程序短小、启动频繁,这都是对Java现在比较耗时的冷启动方面比较突出的挑战,那我们就要考虑Java应用启动时间会这么长,我们有什么办法可以解决这个问题?
先来看看Java启动慢的原因,参考下图。
https://shipilev.net/talks/j1-Oct2011-21682-benchmarking.pdf
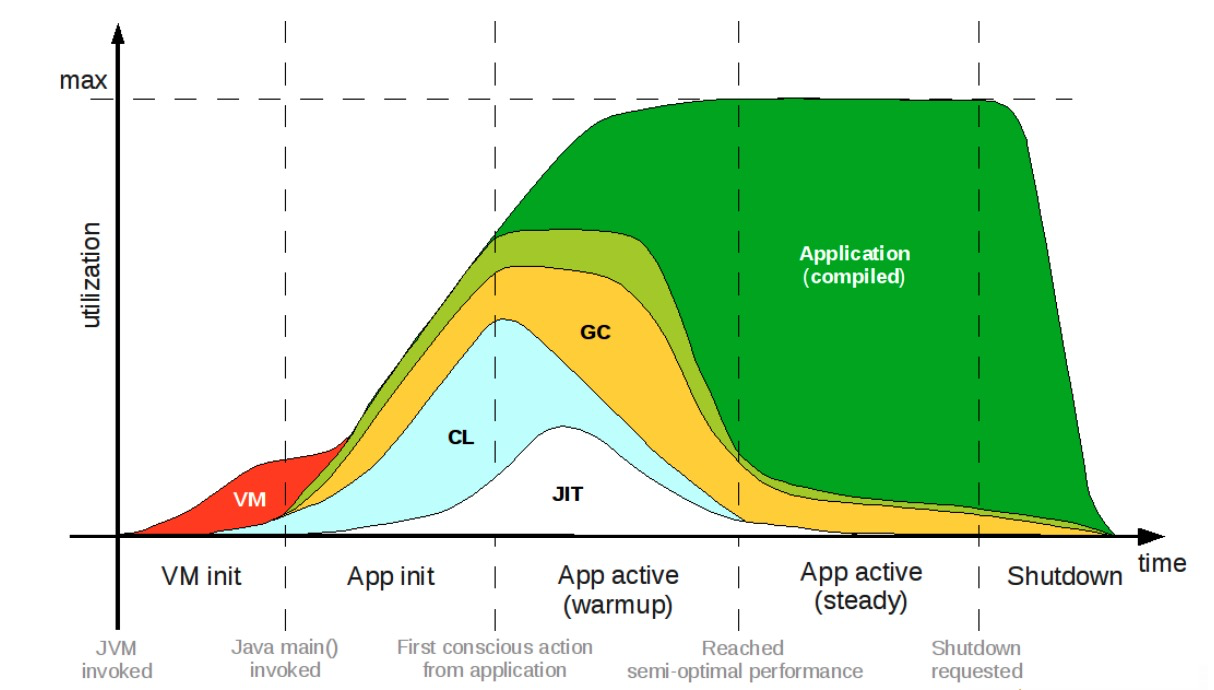
这个图代表了Java运行时各个阶段的生命周期,可以看到它要经过五个阶段,首先是VM init虚拟机的初始化阶段,然后是App init应用的初始化阶段,再经过App active(warmup)的应用预热时期,在预热一段时间后进入App active(steady)达到性能巅峰期,最后应用结束完成整个生命周期。
图中VM init与App init就是所谓的冷启动,红色部分的VM虚拟机初始化,这是逃不掉的,蓝色的CL(ClassLoad),这两个已经占用很多时间了,接下来才慢慢的预热再发展。
那么我们如何针对冷启动的根因做一些东西。
比如说我们有一种改良性的技术,在现有的Java的框架和运行模型的里面做一些调整优化,例如App CDS技术,降低冷启动阶段的类加载开销,去削减CL的时间达到整体时间的压缩。
还有一种革新性的技术,静态编译,启动即巅峰。
改良型——EagerAppCDS
积跬步,至千里
CDS(Class Data Sharing)是一个Java已有的技术,允许将一组类预处理为共享归档文件,以便在运行时能够进行内存映射以减少 Java 程序的启动时间,当多个 Java 虚拟机(JVM)共享相同的归档文件时,还可以减少动态内存的占用量,同时减少多个虚拟机在同一个物理或虚拟的机器上运行时的资源占用。
Java 10 在现有的 CDS 功能基础上再次拓展,以允许应用类放置在共享存档中。CDS 特性在原来的 bootstrap 类基础之上,扩展加入了应用类的 CDS (Application Class-Data Sharing) 支持。其原理为:在启动时记录加载类的过程,写入到文本文件中,再次启动时直接读取此启动文本并加载。设想如果应用环境没有大的变化,启动速度就会得到提升。
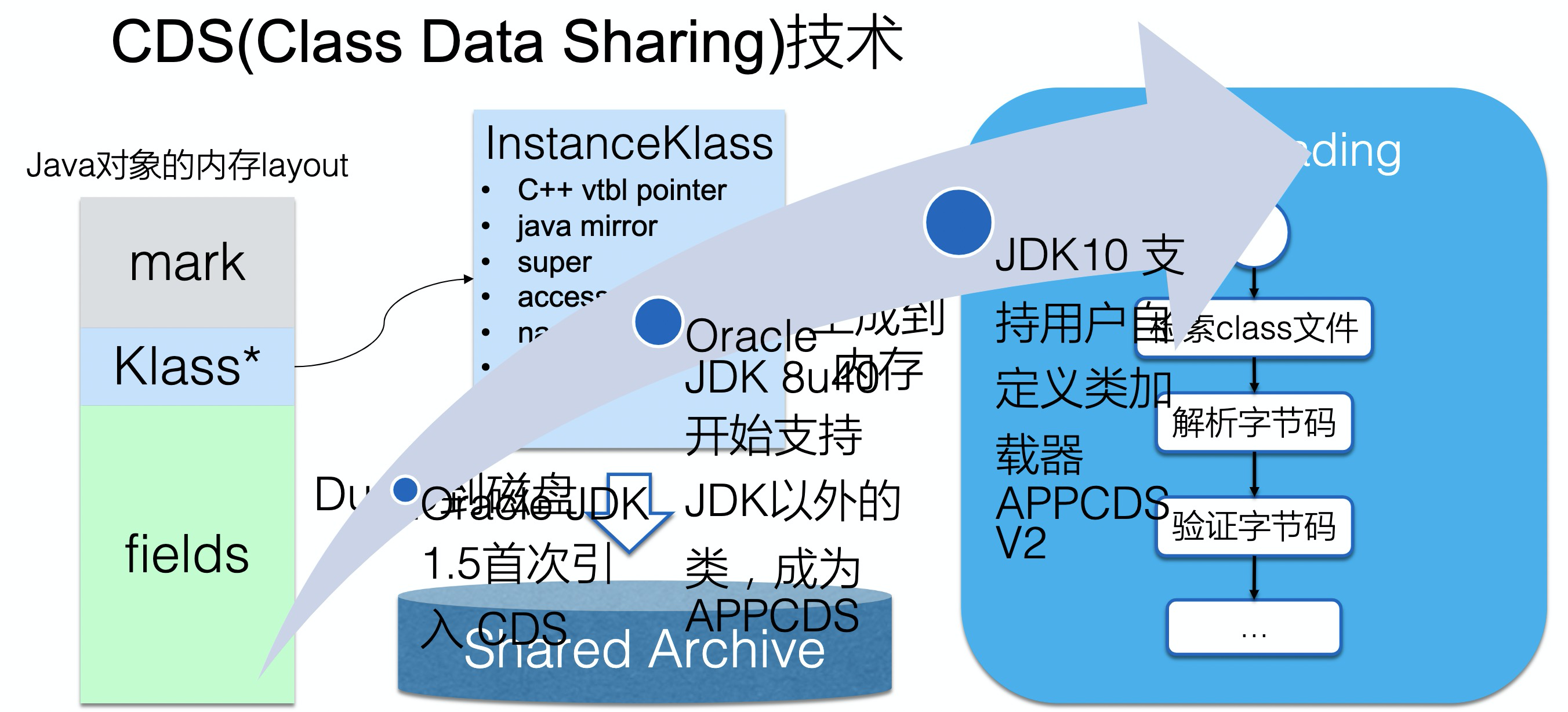
上图中,Klass是一块内存对象指针,指向被ClassLoader加载到类实例,传统的CDS将这部分内容持久化到磁盘,在下次加载时直接从磁盘读取,但起初这只能支持System Class,不能支持Custom Class,在JDK 8u40后才开始陆续支持。
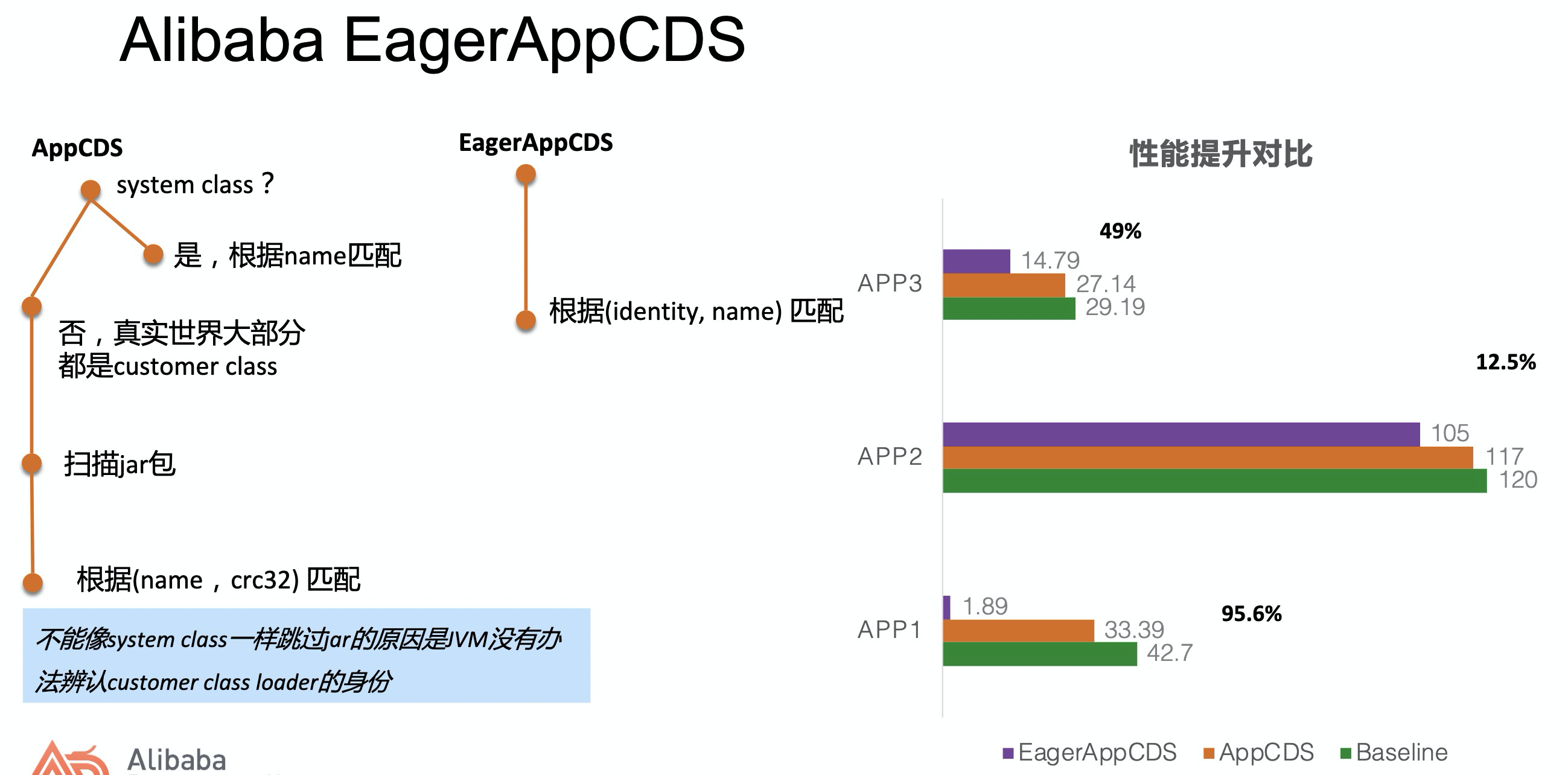
为此阿里有一套自研的Alibaba CDS,如下图,传统AppCDS中,如果是system class直接根据name匹配,如果是Custom Class就需要扫描Jar包,Jar包本质是一个Zip包,这就需要大量IO操作去加载,性能当然不会好。
这种方案在Custom Class越多的情况下肯定会对性能提升有更好的支持。
os: 在当日美团万亿级别微服务治理的挑战与实践中,曹继光提到了美团在序列化反序列化上做的优化,通过分析,发现部分序列化和反序列化占据整个调用时长的9%左右,提到了在这方面做的一些优化,最后提了一句在多实例间共享内存,来避免序列化与反序列化操作,虽然听起来有点难,但是联想到本次冷启动加速的方向中CDS的操作,能不能直接把对象内存抠出来,进行类似主从同步的操作(误)。
现状
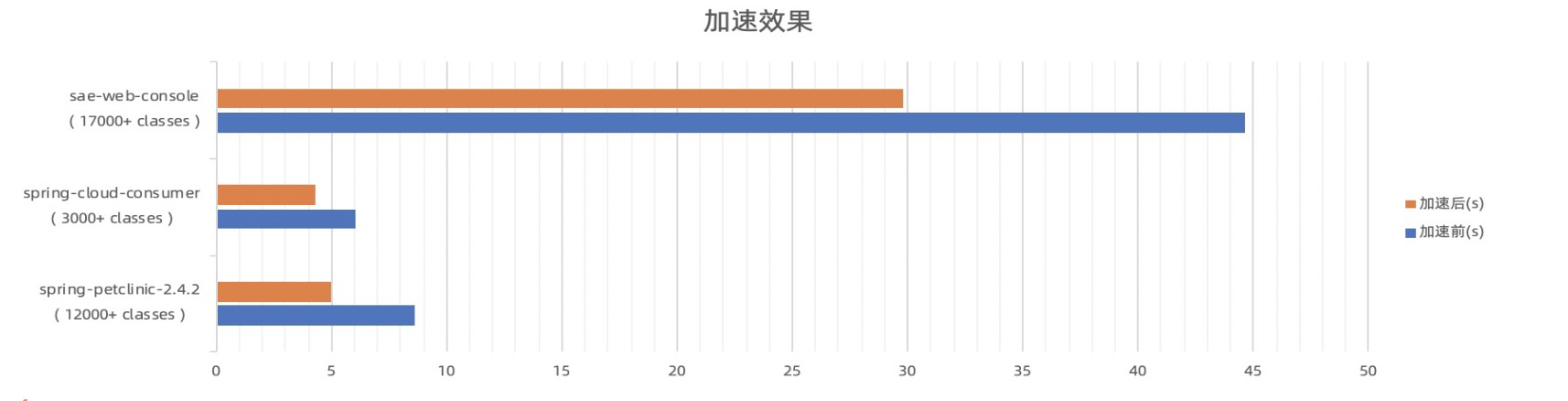
已在阿里云SAE(serverless微服务PaaS)平台应用。
应用启动耗时降低5~45%,提升效果与启动时类加载数量成正比。
其他改进型技术
JWarmup:共享预热后的code cache,减小JIT开销
PGO AOT:增强的AOT技术,改进AOT的代码质量
Class Preinit:类预先初始化,降低运行时初始化类的开销
创新型——Graal VM静态编译技术
Graal VM是基于Java的开源高性能多语言运行平台,拥有高性能低内存占用的优点。
下图是Java编译技术的演进历史,蓝色部分运行在JVM中。
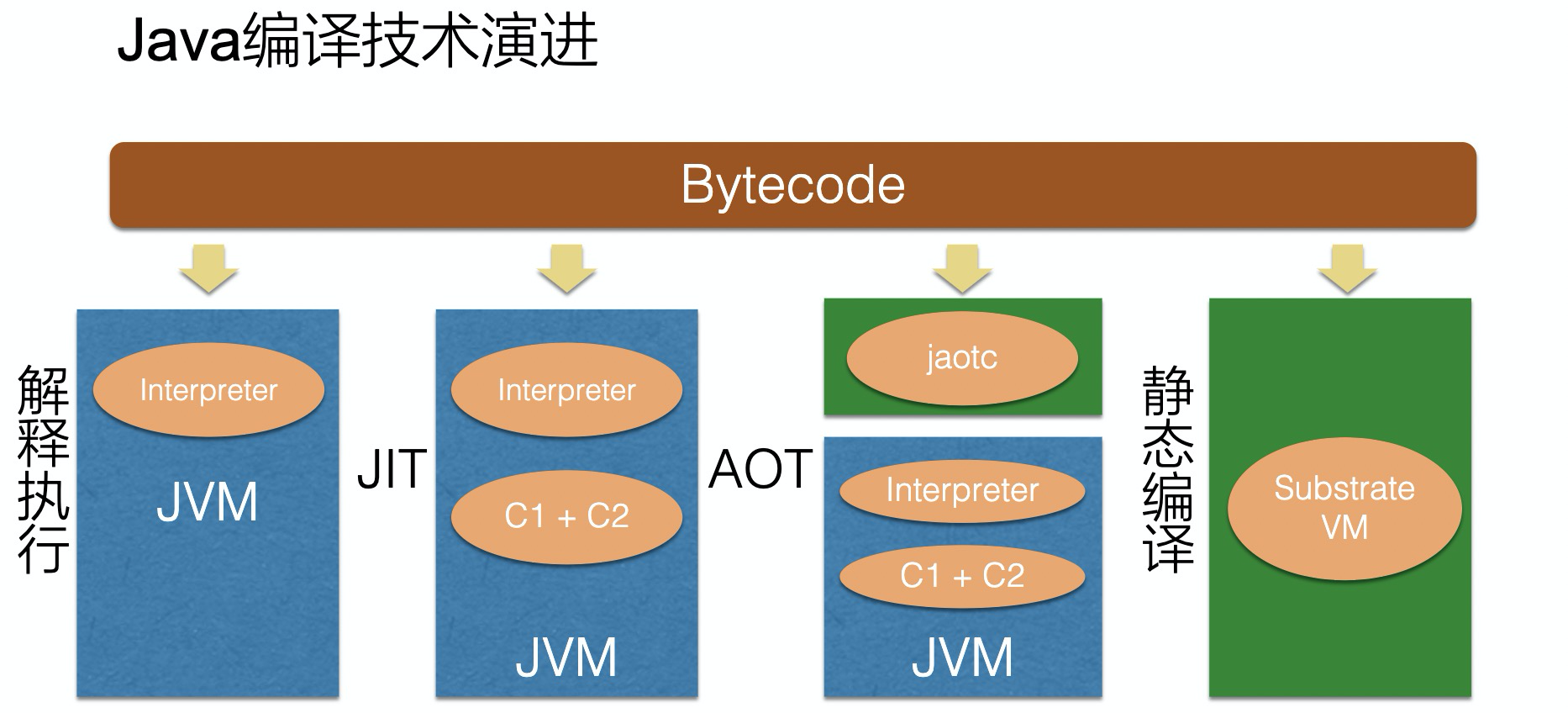
我们的ByteCode字节码在解释执行的过程中,需要由JVM解释执行器边解释边执行,速度上当然最慢。
JIT,实时编译,当函数执行一定次数后就放到C1+C2的编译器中,之后这部分代码就不需要去解释执行了,但编译也是要耗费运行时间,速度也不容乐观。
AOT,先把一部分代码提前由jaotc编译好,在运行时就不需要解释执行这部分代码,但这部分代码在jaotc时拿不到VM runtime。
再激进就是静态编译技术,不再需要JVM,而是SVM提供运行时环境,直接将Bytecode转化为BinaryCode去执行。
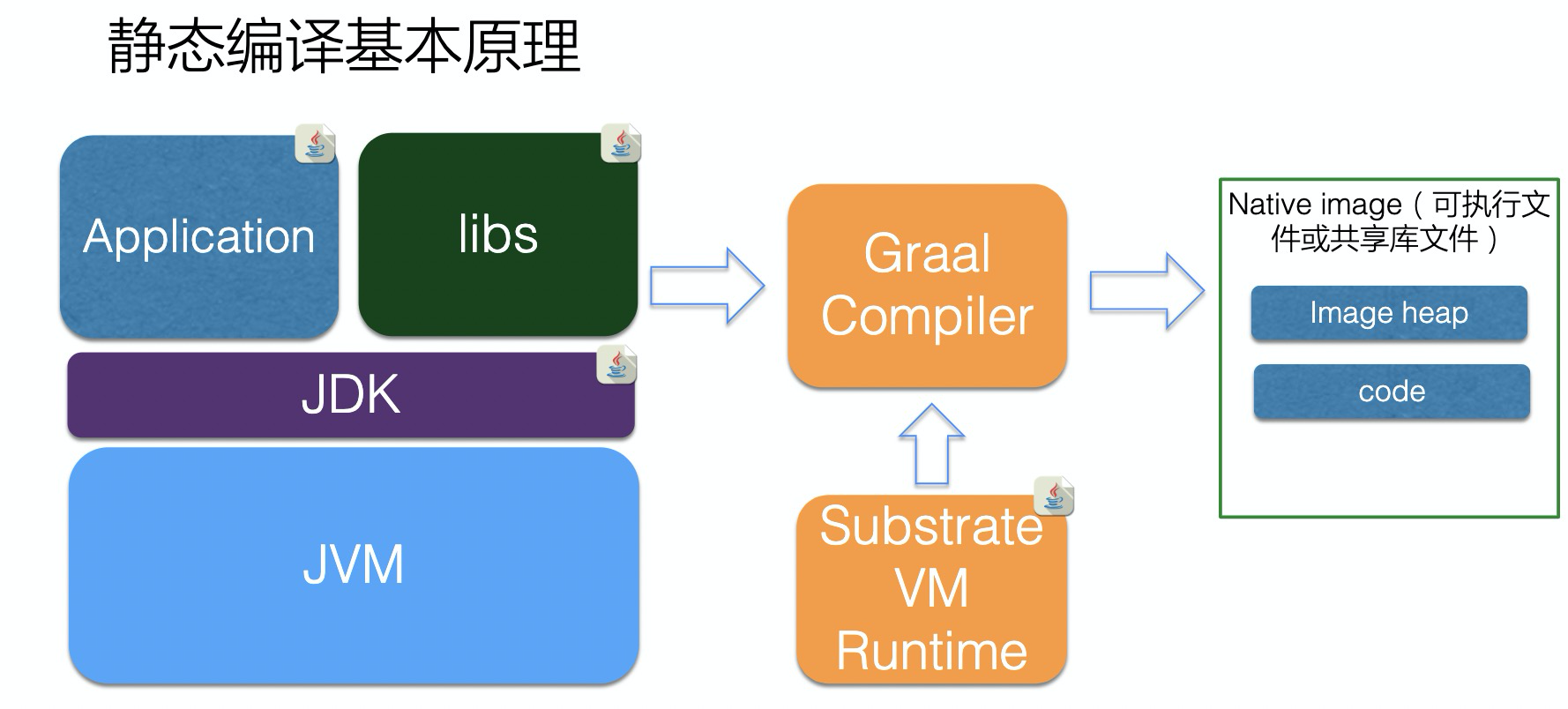
- 静态编译必须遵顼封闭性原则(the closed-world assumption)
- 所有运行时的信息都必须在编译时可见
- 两个基本问题
- 如何确定封闭的边界?
- 如何处理Java的动态特性?
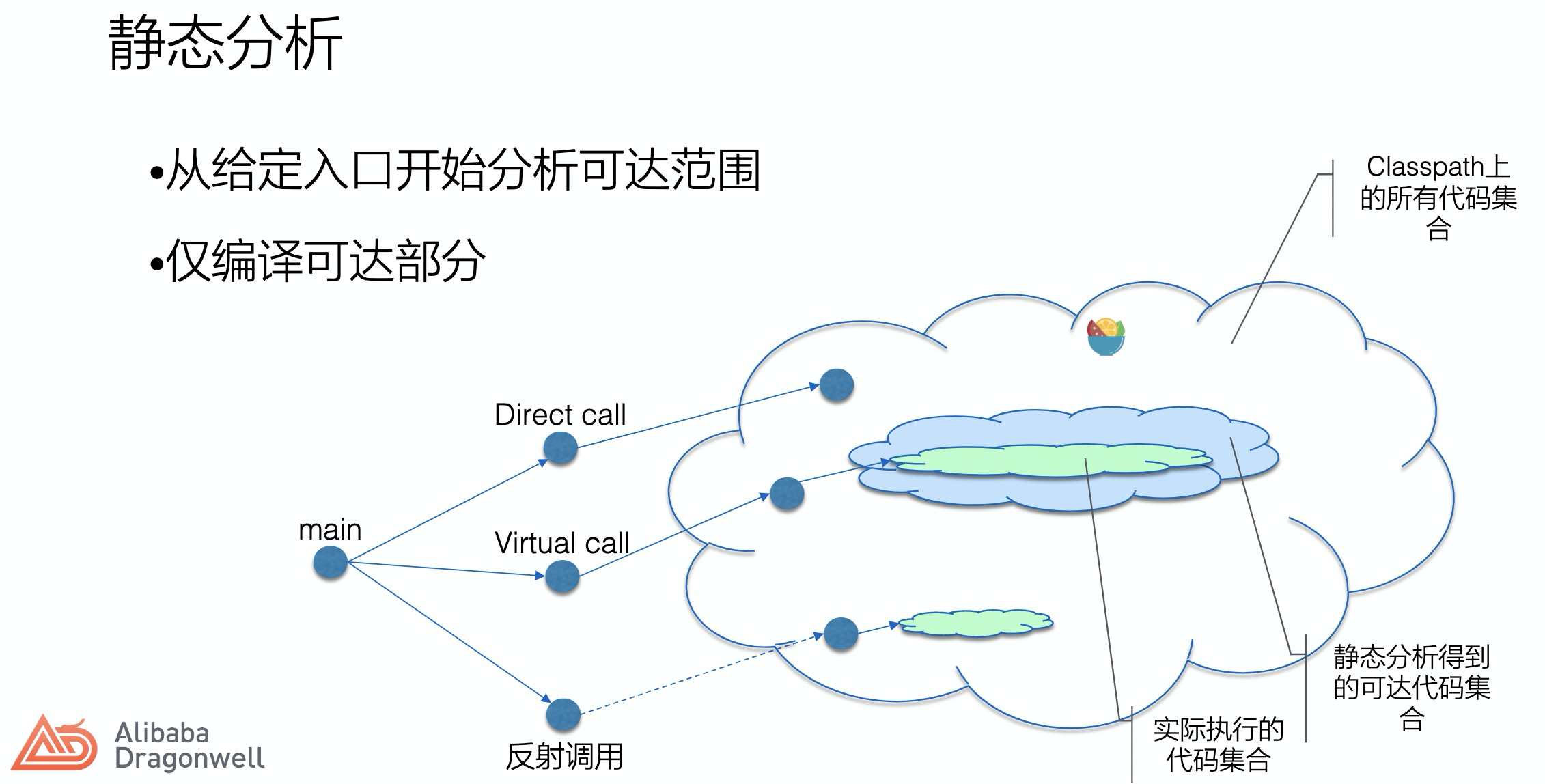
如何在静态编译时确定运行状态,在C/C++中,数组的大小必须定义为一个常量,本质即编译时可见,对于Java反射调用的类如何去保障编译时可见。
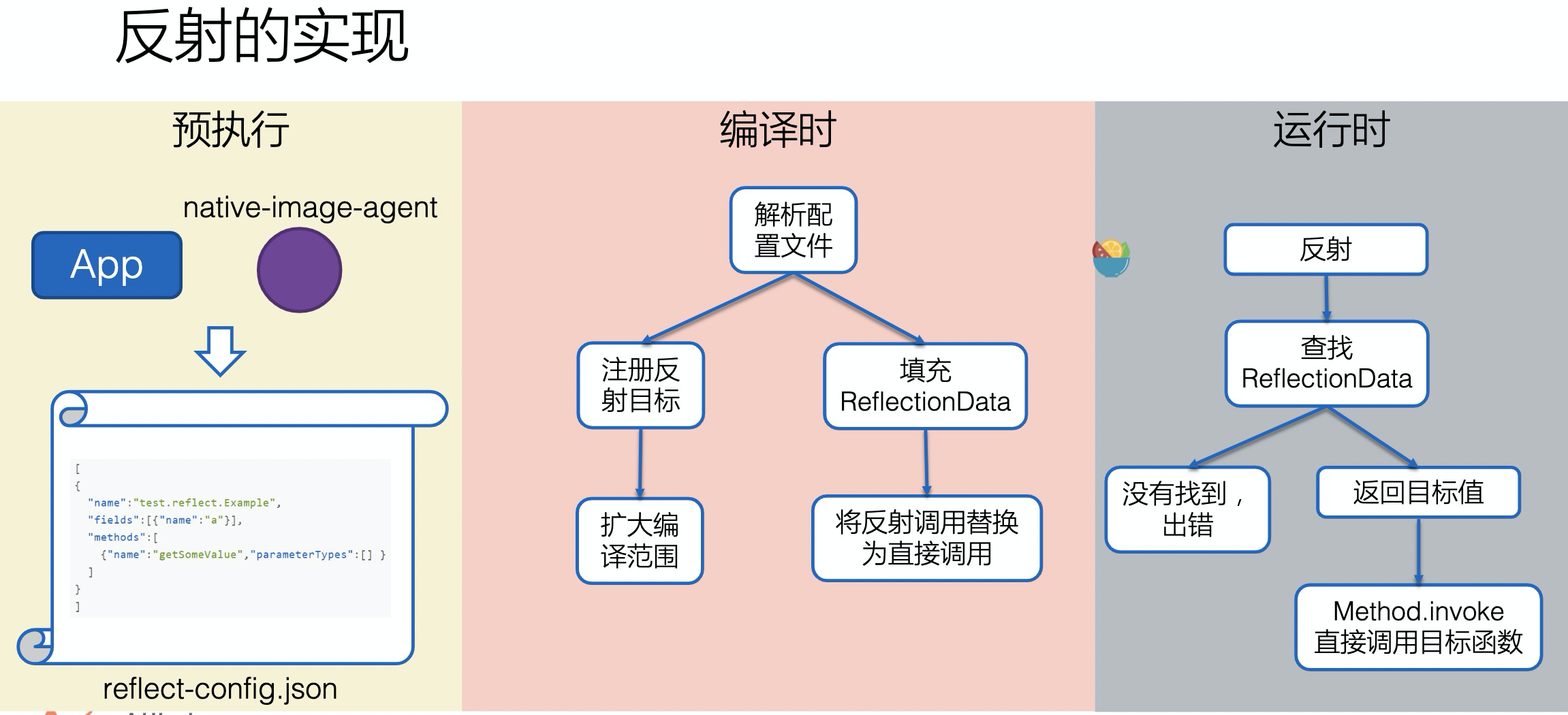
针对反射的情况,Graal VM通过预执行给出了需要反射加载的类与方法,编译时填充到缓冲区RelectionData,并且将反射替换为直接方法调用,在运行时从缓存中查找执行。
一个大前提就是需要预执行去扫描这部分反射调用的对象方法,如果扫不到,就需要自己手动去添加配置。
关于性能报告的可以自己去查看大会PPT。
作者: AntzUhl
首发地址博客园:http://www.cnblogs.com/LexMoon/
代码均可在Github上找到(求Star) : Github
个人博客 : http://antzuhl.cn/
公众号 |
 |
赞助
支付宝 |
微信 |
 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号