
TFIDF改进版:BM25算法介绍及Lucene的实现
优化TF
TF衰减
思考一个问题:一篇文档,里面有提到200次RedCap,一定是2倍相关于另一篇提到100次RedCap吗?
\(TF\)对匹配度的贡献应该是有所衰减的。如何控制衰减曲线的陡峭程度?构造\(TF\)衰减的匹配度函数的一个trick是引入参数\(k\):
这里k相当于一个增长阻力系数,k越大,曲线越平缓。
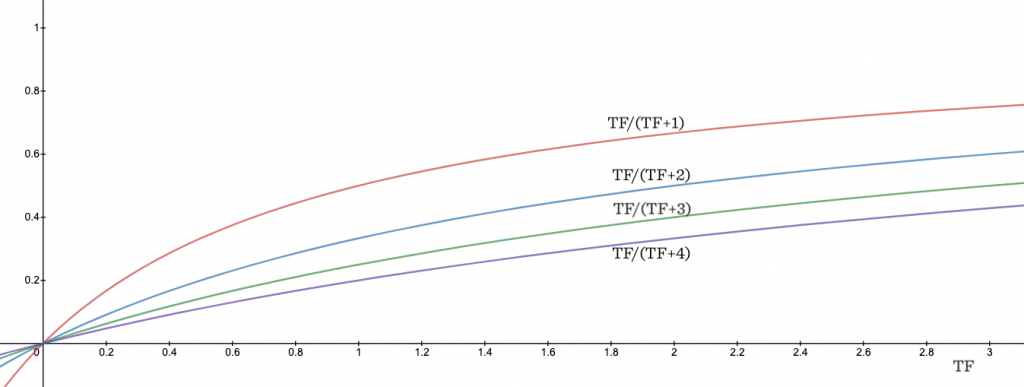
另外,这个计算方法还有个好处是,同1个词被匹配N次的得分,要低于N个词被匹配1次的得分,这也是合乎常理的。
考虑文档长度
考虑一种场景:有一篇文档docA很长,有1000字,里面提到1次RedCap;另外还有篇文档docB很短,里面只有50字,里面提到1次redcap;则我们有理由认为docA很可能实际上并没有与RedCap很相关,而对于docB,RedCap应该是一个很相关的概念。
文档长度docLength(\(dl\))同样是个不应该被忽略的指标。如何判定文档的“长”或“短”呢?一个直接的想法是以语料库中的文档平均长度AveDocLength(\(adl\))作为参照系,高于平均值即判定为长,反之为短。这里我们可以定义文档长度系数DocLengthRatio(\(dlr\)):
回到TF匹配度函数 \(\frac{TF}{(TF + k)}\) ,我们可以改变\(k\)来调整匹配度评分:
- 文档长,\(k\)调大,匹配度降低;
- 文档短,\(k\)调小,匹配度提高;
调整方法可以是对\(k\)乘\(dlr\)。令\(k^\prime\)为调整后的\(k\):
当\(dl = adl\)时,\(dlr = 1\),无影响;
当\(dl \gt adl\)时,\(dlr \gt 1\),\(k^\prime\)增大,匹配度降低;
当\(dl \lt adl\)时,\(dlr \lt 1\),\(k^\prime\)减小,匹配度提高;
此外,\(k^\prime\) 影响了匹配度函数中原本k的值,使得短文档的TF衰减曲线更陡峭,长文档的TF衰减曲线则更为平缓。
文档长度参数化
上面考虑了文档长度(\(dl\))对匹配度评分的负相关性,但文档越长是否总能意味着匹配度越低呢?可能有些文档的长短格外影响匹配度,但有些并不。
因此我们需要一个新的维度来考虑文档的重要程度,和文档长度一起调整匹配度的计算结果。
这里,我们引入一个新的参数\(b(0 \le b \le 1)\)继续调整\(k^\prime\)的值:
很简单粗暴的参数,\(b\)的值越大,文档长度对匹配度的影响越大。
TF对匹配度的贡献最终为:
IDF
经典IDF定义:
而BM25定义为:
上面的\(IDF_{BM25}\)来自于Robertson-Spärck Jones weight和一些简化的假设。这里我们关注其相较于经典IDF定义的实际效果。
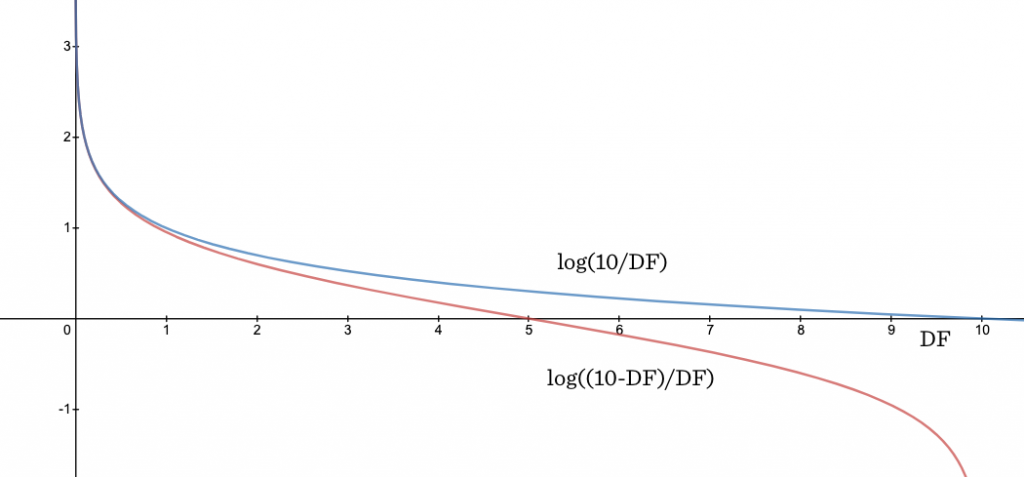
从曲线中可以看到,当\(DF\)达到文档总数\(N\)的\(98\%\)以上时,\(IDF_{BM25}\)指数级下降速度非常快,与此相比,\(70\%\)左右的下降速度较为平缓。对此可以解释为,几乎所有文档都有的词,极大概率是个停用词,而出现在一半多文档中的词,反而有可能是个领域的专有名词,不能给予权重太大的惩罚。
这里还涉及正负号的问题:
当\(DF \gt 2N\)时,\(IDF_{BM25} \lt 0\)。
我们并不希望匹配分数出现负数,原因是查询词在文档中出现了的分数至少不应该小于未出现的分数。
为了规避这个问题,Lucene的实现中将计算公式调整为:
如果忽略上式的0.5,实际上,\(IDF_{Lucene}=\log (N/DF)=IDF\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号