
five
课堂记录:
Python是由上至下运行的 到你下面变量定义重复了 变成了字符串类型 再往前
get请求直接访问 携带用户的信息(name password)
- requests之POST请求
cookie存在客户端服务器中
Session 维持会话 在服务端存放用户信息 为了密码用户信息的安全 用户体验更好不需再输入密码
Token 减轻服务器压力
Cookie有限制时间 (有效时间),所以post保证每次访问都有一个最新的cookie,以防止cookie失效掉线被检测出
Referer 指的是上一次请求从哪里来
对于爬虫来说分析请求流程是最重要的 “爬虫分析”
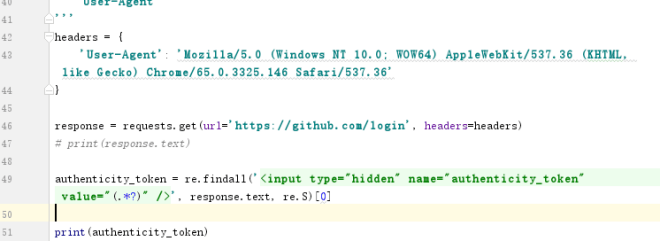
a.访问login页获取token信息
响应头 set—cookie告诉浏览器添加session

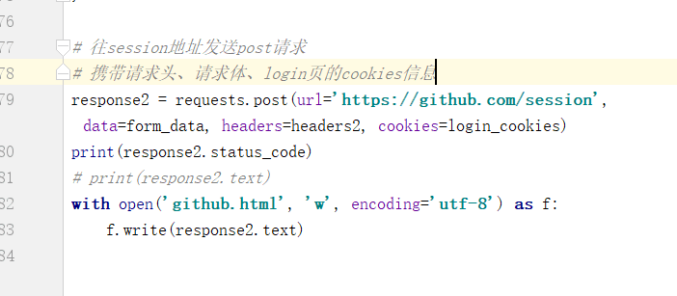
b.往seeion url发送post请求


- Requests高级用法

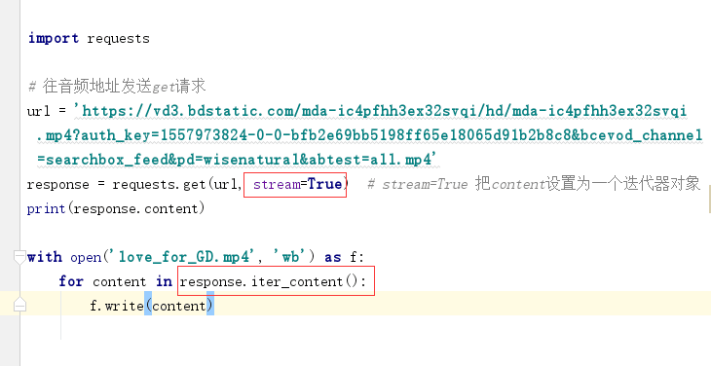
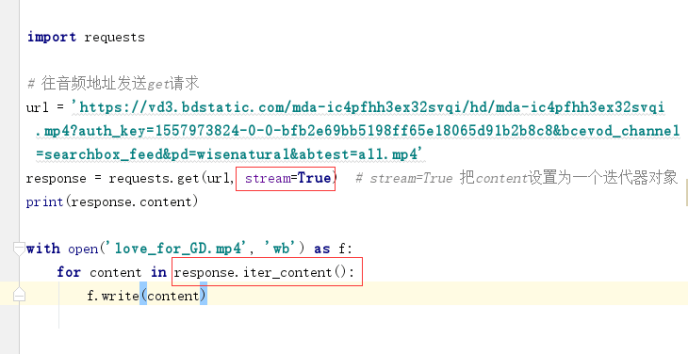
Requests把一大串二进制直流拆分成一段段的
Python生成器 迭代器
https://www.cnblogs.com/wj-1314/p/8490822.html
https http+ssl(携带证书)服务器必须携带上安全认证证书
https://blog.csdn.net/xiaoming100001/article/details/81109617
使用代理
西刺代理
Api接口
最重要的:!!!

爬取西刺免费代理进行代理测试
https://www.cnblogs.com/kermitjam/p/10863916.html?tdsourcetag=s_pctim_aiomsg#_label5
- selenium模块
https://www.cnblogs.com/kermitjam/p/10863922.html?tdsourcetag=s_pctim_aiomsg
什么是selenium?为什么用?如何用?
自动化测试工具 通过你写好的代码 自动驱动浏览器 帮你模拟人的行为去执行某些自定义好的操作。
Selenium可帮你自动执行js(java script)代码 requests模块是不可以帮你执行js代码的
网页滚动条滑倒下面 再次为你发送异步请求 执行js代码 返回更多商品信息
Requests要分析很多登录流程 过程很麻烦
Selenium优点:在页面中执行js代码,跳过登陆验证
Requests弄块要分析大量复杂通信流程,过程很麻烦,使用selenium可以轻松跳过登陆验证
Selenium缺点:浏览器会加载css、js、图片、视频...数据,爬虫效率比requests模块慢
使用方法:
下载selenium模块
下载浏览器驱动(这里使用谷歌浏览器)
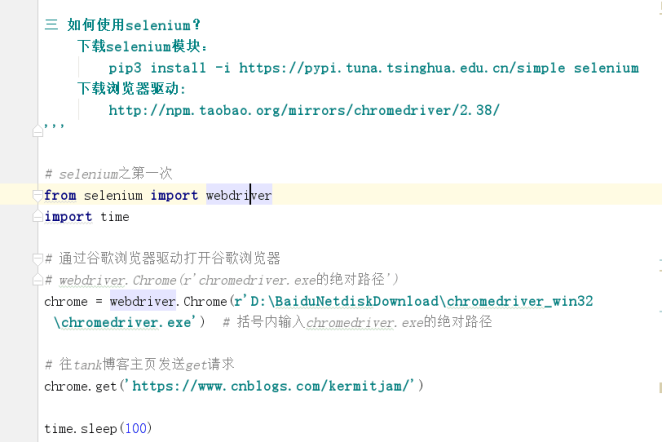
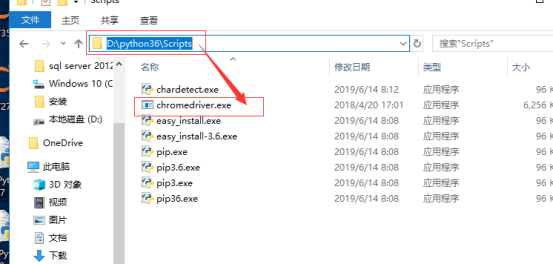
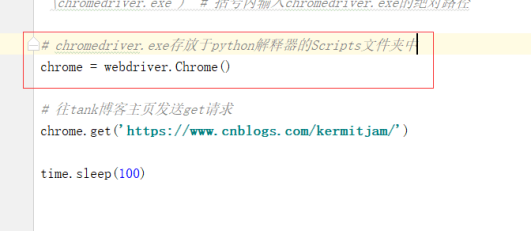
或者将谷歌浏览器驱动放到自己的py解释器script里:
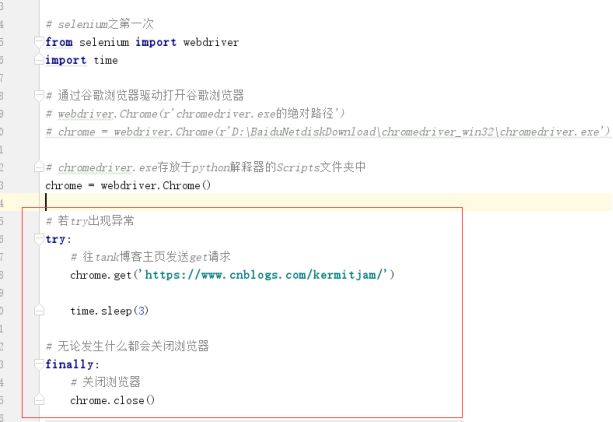
from selenium import webdriver # 用来驱动浏览器的
from selenium.webdriver import ActionChains # 破解滑动验证码的时候用的 可以拖动图片
调用得到一个动作链对象 破解滑动验证码的时候用的,可以拖动图片
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作 通过keys操作回车键等按键
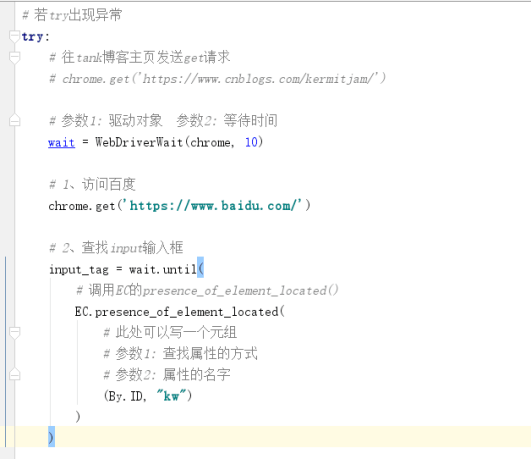
from selenium.webdriver.support import expected_conditions as EC # 和下面WebDriverWait一起用的
EC是expected_conditions的别名
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素import time
输入框自动输入标签 自动键盘enter访问网页:

访问京东主页


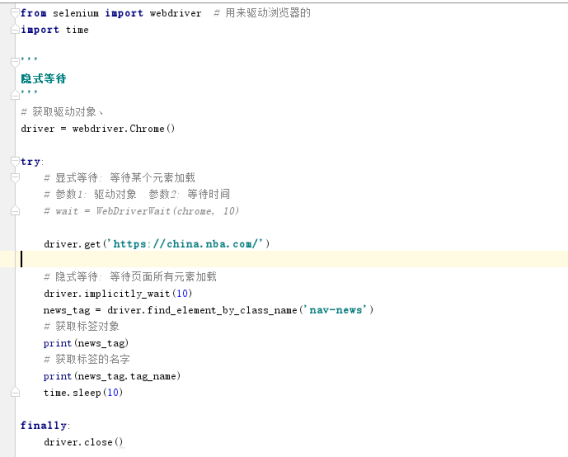
隐式等待
基本选择器
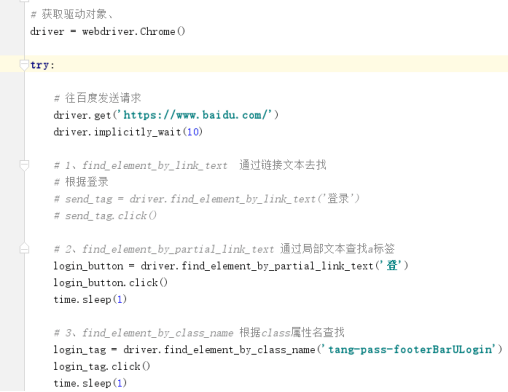
自动输入为你打开 登录 输入信息


 浙公网安备 33010602011771号
浙公网安备 33010602011771号