
four
课堂笔记:
爬虫:爬取数据
互联网:由一堆网络设备把一台一台的计算机互联到一起
互联网建立的目的:数据的传递与共享
上网的全过程:
普通用户:打开浏览器——往目标站点(服务器)发送请求——接收响应数据——渲染到页面上
爬虫程序:模拟浏览器——往目标站点(服务器)发送请求——接收响应数据——提取有用的数据并保存到本地/数据库
浏览器发送的是什么请求:http协议的请求(请求url 请求方式:GET、POST 请求头cookies、user_agent、host)
爬虫全过程:发送请求(请求库)——获取相应数据(服务器为我们提供)——解析并提取数据(解析库)——保存数据(存储库)MogoDB数据库

- Requests模块的详细使用
请求库 ruquests、selenium
解析库 bs4(beautifulsoup4)、Xpath
存储库 MongoDB
爬虫框架(基于面向对象)全用面向对象写的
Ctrl+f 出现搜索框0

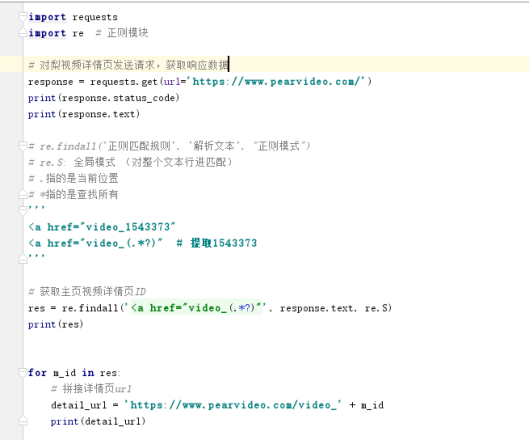
根据每个模块继续补全代码
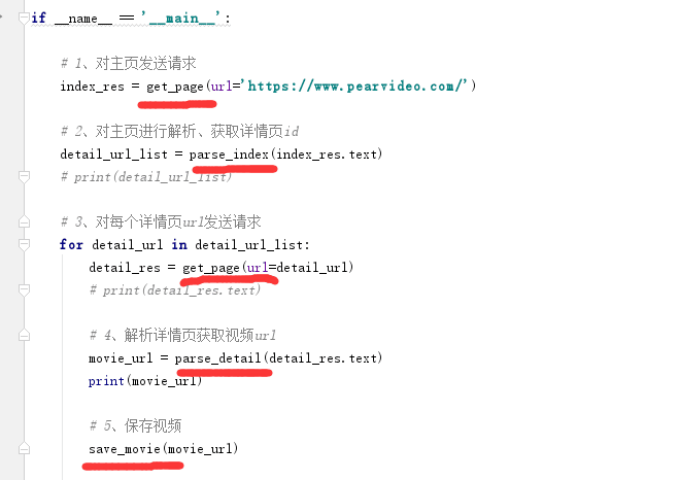


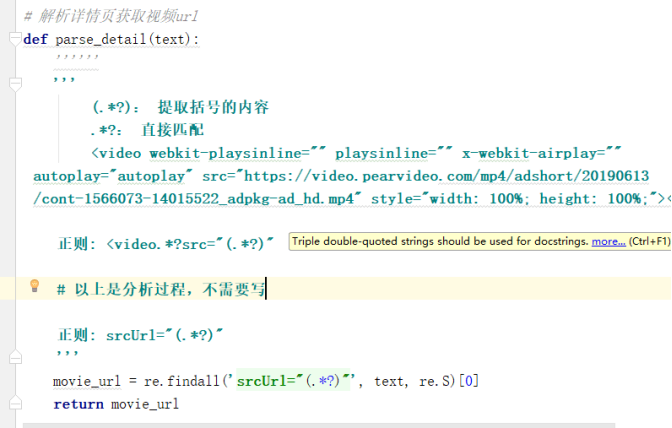

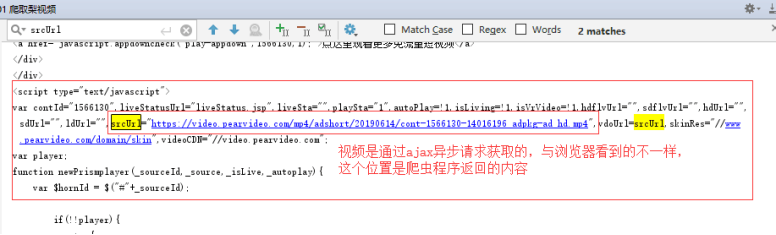
高性能爬虫
异步爬取梨视频
#同步编程(同一时间只能做一件事,做完了才能做下一件事情)
#异步编程 (可以近似的理解成同一时间有多个事情在做,但有先后)
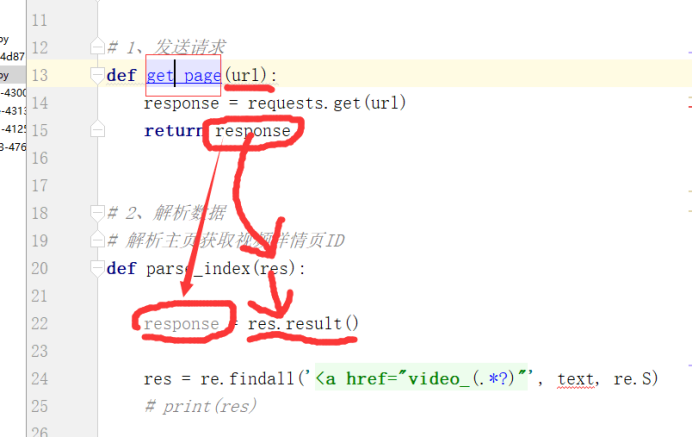
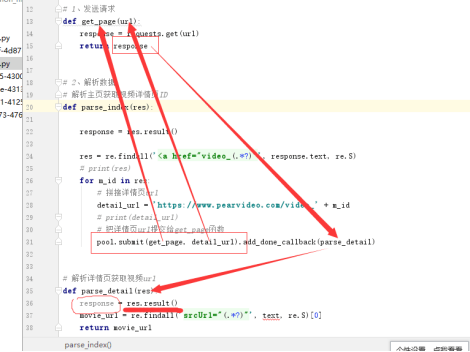
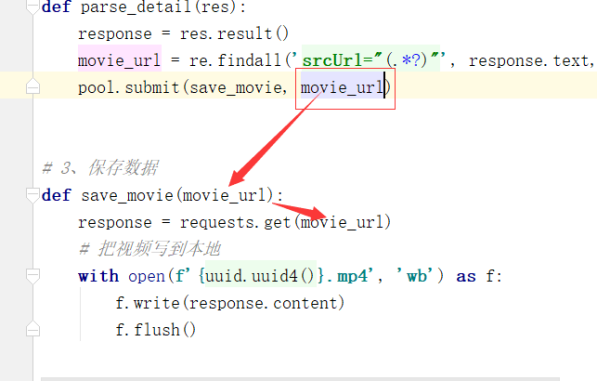


1 import requests 2 import re # 正则模块 3 # uuid.uuid4() 可以根据时间戳生成一段世界上唯一的随机字符串 4 import uuid 5 # 导入线程池模块 6 from concurrent.futures import ThreadPoolExecutor 7 # 线程池限制50个线程 8 pool = ThreadPoolExecutor(50) 9 10 # 爬虫三部曲 11 12 # 1、发送请求 13 def get_page(url): 14 print(f'开始异步任务: {url}') 15 response = requests.get(url) 16 return response 17 18 19 # 2、解析数据 20 # 解析主页获取视频详情页ID 21 def parse_index(res): 22 23 response = res.result() 24 # 提取出主页所有ID 25 id_list = re.findall('<a href="video_(.*?)"', response.text, re.S) 26 # print(res) 27 28 # 循环id列表 29 for m_id in id_list: 30 # 拼接详情页url 31 detail_url = 'https://www.pearvideo.com/video_' + m_id 32 # print(detail_url) 33 # 把详情页url提交给get_page函数 34 pool.submit(get_page, detail_url).add_done_callback(parse_detail) 35 36 37 # 解析详情页获取视频url 38 def parse_detail(res): 39 response = res.result() 40 movie_url = re.findall('srcUrl="(.*?)"', response.text, re.S)[0] 41 # 异步提交把视频url传给get_page函数,把返回的结果传给save_movie 42 pool.submit(get_page, movie_url).add_done_callback(save_movie) 43 44 45 # 3、保存数据 46 def save_movie(res): 47 48 movie_res = res.result() 49 50 # 把视频写到本地 51 with open(f'{uuid.uuid4()}.mp4', 'wb') as f: 52 f.write(movie_res.content) 53 print(f'视频下载结束: {movie_res.url}') 54 f.flush() 55 56 57 if __name__ == '__main__': # main + 回车键 58 59 # 一 往get_page发送异步请求,把结果交给parse_index函数 60 url = 'https://www.pearvideo.com/' 61 pool.submit(get_page, url).add_done_callback(parse_index)
- requests详细使用之访问知乎发现
400 错误 找不到资源
没有带user_agent 请求头 可能会反爬
带请求头突破第一层防御


用字典存放请求头
Headers={ ‘user-agent’:’ ’}

- params参数之访问蔡徐坤url

携带cookies
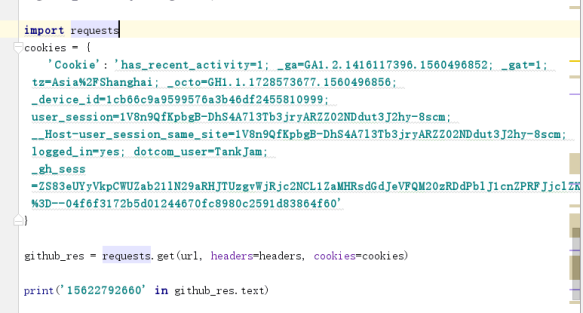
携带登录cookies破解github登陆验证
Headers拼接cookies 或者 将cookies定义成一个字典

headers拼接cookies
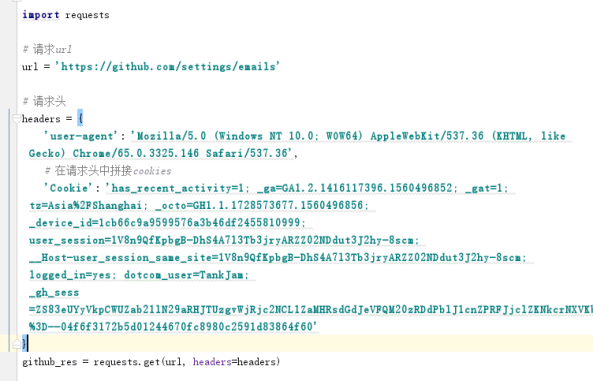
将cookies单独定义成一个字典
- 附例(爬取豆瓣top250信息)
通过正则解析提取数据!!电影详情页url、图片链接、电影名称、电影评分、评价人数
1 '''''' 2 ''' 3 主页: 4 https://movie.douban.com/top250 5 GET 6 User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36 7 8 re正则: 9 # 电影详情页url、图片链接、电影名称、电影评分、评价人数 10 <div class="item">.*?href="(.*?)">.*?src="(.*?)".*?<span class="title">(.*?)</span>.*?<span class="rating_num".*?>(.*?)</span>.*?<span>(.*?)人评价 11 ''' 12 import requests 13 import re 14 url = 'https://movie.douban.com/top250' 15 headers = { 16 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36' 17 } 18 # 1、往豆瓣TOP250发送请求获取响应数据 19 response = requests.get(url, headers=headers) 20 21 # print(response.text) 22 23 # 2、通过正则解析提取数据 24 # 电影详情页url、图片链接、电影名称、电影评分、评价人数 25 movie_content_list = re.findall( 26 # 正则规则 27 '<div class="item">.*?href="(.*?)">.*?src="(.*?)".*?<span class="title">(.*?)</span>.*?<span class="rating_num".*?>(.*?)</span>.*?<span>(.*?)人评价', 28 29 # 解析文本 30 response.text, 31 32 # 匹配模式 33 re.S) 34 35 for movie_content in movie_content_list: 36 # 解压赋值每一部电影 37 detail_url, movie_jpg, name, point, num = movie_content 38 data = f'电影名称:{name}, 详情页url:{detail_url}, 图片url:{movie_jpg}, 评分: {point}, 评价人数: {num} \n' 39 print(data) 40 41 # 3、保存数据,把电影信息写入文件中 42 with open('douban.txt', 'a', encoding='utf-8') as f: 43 f.write(data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号