
Scrapy保存数据到Json文件、MySQL
安装sqlalchemy:
注意:
如果数据库的表格已经存在,可以通过 sqlacodegen模块 生成model。->传送门


sqlacodegen --noviews --noconstraints --noindexes --outfile /Users/_Alex/Desktop/sql_orm.py mysql+pymysql://root:****@localhost/JobboleArticle
保存爬取数据
1、同步保存数据为Json格式
from scrapy.pipelines.images import ImagesPipeline from scrapy.exporters import JsonItemExporter from scrapy.exceptions import DropItem import json import codecs import MySQLdb class JsonWithEncodingPipeline(object): # 使用自定义Json文件保存数据 def __init__(self): self.file = codecs.open('article.json','w',encoding='utf-8') def open_spider(self,spider): pass def spider_closed(self,spider): self.file.close() def process_item(self, item, spider): print('Json---------------------Write') line = json.dumps(dict(item),ensure_ascii=False) + '\n' self.file.write(line) return item class JsonExporterPipeline(): # 使用FeedJsonItenExporter保存数据 def __init__(self): self.file = open('articleExporter.json','wb') self.exporter = JsonItemExporter(self.file,ensure_ascii =False,encoding='utf-8') self.exporter.start_exporting() def process_item(self,item,spider): print('Write') self.exporter.export_item(item) return item def close_spider(self,spider): print('Close') self.exporter.finish_exporting() self.file.close()
2、同步保存数据到MySQL
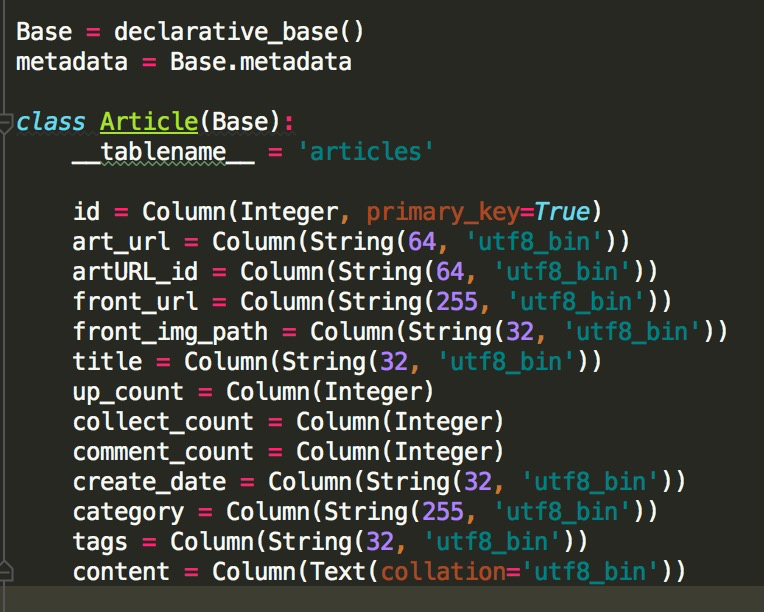
a.编辑sql_orm.py,实现添加数据功能:
#!/usr/bin/env python # -*- coding: utf-8 -*- __author__ = 'Fade Zhao' import sqlalchemy from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String,Text from sqlalchemy.orm import sessionmaker Base = declarative_base() metadata = Base.metadata class Article(Base): __tablename__ = 'articles' id = Column(Integer, primary_key=True) art_url = Column(String(64, 'utf8_bin')) artURL_id = Column(String(64, 'utf8_bin')) front_url = Column(String(255, 'utf8_bin')) front_img_path = Column(String(32, 'utf8_bin')) title = Column(String(32, 'utf8_bin')) up_count = Column(Integer) collect_count = Column(Integer) comment_count = Column(Integer) create_date = Column(String(32, 'utf8_bin')) category = Column(String(255, 'utf8_bin')) tags = Column(String(32, 'utf8_bin')) content = Column(Text(collation='utf8_bin')) class Interface: engine = create_engine("mysql+pymysql://root:zhaoyinghan@localhost/JobboleArticle?charset='utf8'",encoding='utf-8', echo=True)
注意:必须要写charset,否则会因为编码问题报错 Session = sessionmaker(bind=engine) def __init__(self): '''初始化''' self.session = self.Session() # 创建表结构 Base.metadata.create_all(self.engine) def add_data(self,date): article = Article(**date) self.session.add(article) self.session.commit()
b. Pipelines.py中通过sqlalchemy添加数据:
class MySQLPipeline(): # 同步将数据写入mysql def __init__(self): self.interface = Interface() def process_item(self,item,spider): self.interface.add_data(dict(item)) return item
c.在settings.py中添加MySQLPipeline
ITEM_PIPELINES = { 'ArticleSpider.pipelines.MySQLPipeline':2, 'ArticleSpider.pipelines.JobBoleImagePipelines': 1, #自定义JobBoleImagePipelinesj继承ImagesPipeline }
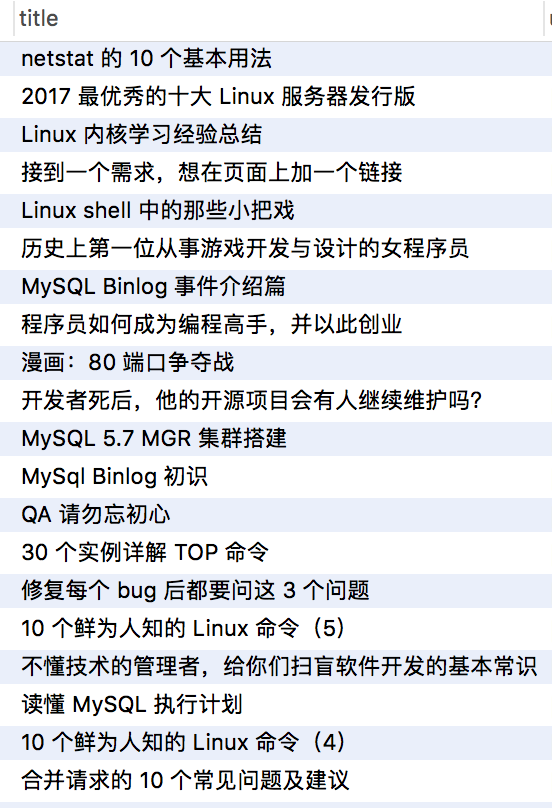
运行爬取伯乐的第一页文章↓
3、异步MySQL 保存数据:
因为我们在用Scrapy进行数据爬取和解析的速度一定是比存储数据库的速度快,当数据库存储量变大后,速度就会变慢,而在插入数据的时候,Scrapy还需要等待,故而浪费了大量的时间,所以我们可以通过异步的存储方式来提高我们的效率。
Twisted框架给我们提供了异步操作关系型数据的方法:
from twisted.enterprise import adbapi class MysqlTwistedPipeline(object): ''' 异步机制将数据写入到mysql数据库中 ''' # 创建初始化函数,当通过此类创建对象时首先被调用的方法 def __init__(self, dbpool): self.dbpool = dbpool # 创建一个静态方法,静态方法的加载内存优先级高于init方法,java的static方法类似, # 在创建这个类的对之前就已将加载到了内存中,所以init这个方法可以调用这个方法产生的对象 @classmethod # 名称固定的 def from_settings(cls, settings): # 先将setting中连接数据库所需内容取出,构造一个地点 dbparms = dict( host=settings["MYSQL_HOST"], db=settings["MYSQL_DBNAME"], user=settings["MYSQL_USER"], passwd=settings["MYSQL_PASSWORD"], charset="utf-8", # 游标设置 cursorclass= MySQLdb.cursors.DictCursor, # 设置编码是否使用Unicode use_unicode=True ) # 通过Twisted框架提供的容器连接数据库,MySQLdb是数据库模块名 dbpool = adbapi.ConnectionPool("MySQLdb", dbparms) return cls(dbpool) def process_item(self, item, spider): # 使用Twisted异步的将Item数据插入数据库 query = self.dbpool.runInteraction(self.do_insert, item) query.addErrback(self.handle_error, item, spider) # 这里不往下传入item,spider,handle_error则不需接受,item,spider) def do_insert(self, cursor, item): # 执行具体的插入语句,不需要commit操作,Twisted会自动进行 insert_sql = """ insert into articles(title) VALUES(%s) """ cursor.execute(insert_sql, (item["title"])) def handle_error(self, failure, item, spider): # 出来异步插入异常 print(failure)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号