

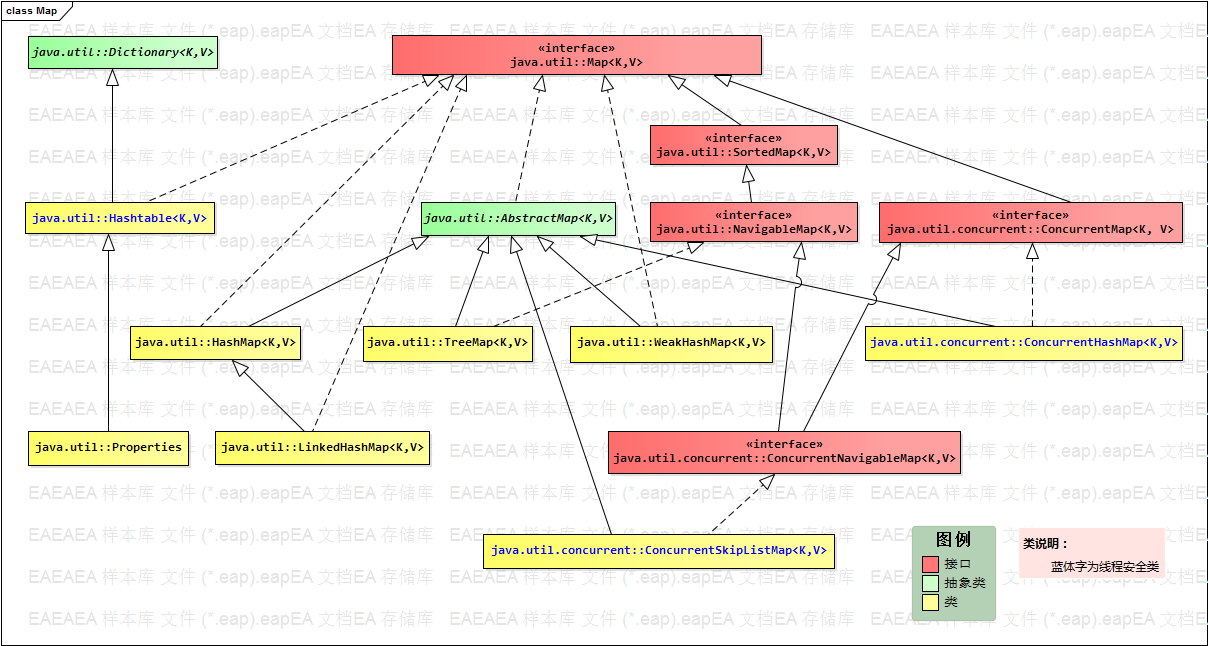
Java 集合框架之 Map
Hashtable
Hashtable 的实例有两个参数影响其性能:初始容量 和加载因子。容量 是哈希表中桶 的数量,初始容量就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。
通常,默认加载因子(.75)在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
初始容量主要控制空间消耗与执行 rehash 操作所需要的时间损耗之间的平衡。如果初始容量大于 Hashtable 所包含的最大条目数除以加载因子,则永远 不会发生 rehash 操作。但是,将初始容量设置太高可能会浪费空间。
Hashtable 是同步的,现在一般情况下,都使用 HashMap ,而不使用陈旧的 Hashtbale,即便需要同步的时候,也是采用加同步的HashMap或者ConcurrentHashMap等实现。
Properties
该类继承自 Hashtable,主要用于读取 Java 的键值格式的配置文件,比如 XML 文件,properties文件。
在该类的注释中,建议使用 setProperties 方法插入键值,而不建议使用 put 和 putAll,因为这两个方法允许调用者插入键值不是 String的项。
HashMap
基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap 的实例有两个参数影响其性能:初始容量 和加载因子。容量 是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子 (.75) 在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
该类不是线程安全的。
TreeMap
由图可知,TreeMap类不仅实现了Map接口,还实现了Map接口的子接口java.util.SortedMap。
基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
在添加、删除和定位映射关系上,TreeMap类要比HashMap类的性能差一些,但是其中的映射关系具有一定的顺序,如果不需要一个有序的集合,则建议使用HashMap类;如果需要进行有序的遍历输出,则建议使用TreeMap类,在这种情况下,可以先使用由HashMap类实现的Map集合,在需要顺序输出时,再利用现有的HashMap类的实例,创建一个具有完全相同映射关系的TreeMap类型的实例。
LinkedHashMap
该类是 Map 接口的哈希表和链表实现。该类维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序),亦即它保留插入的顺序,输出的顺序即为输入时的插入顺序。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序(调用 get 方法)的链表。
默认是按插入顺序排序,如果指定按访问顺序排序,那么调用 get 方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。 可以重写 removeEldestEntry 方法返回 true 值指定插入元素时移除最老的元素。
注意,此实现不是同步的。
WeakHashMap
以弱键实现的基于哈希表的 Map。在 WeakHashMap 中,当某个键不再正常使用时,将自动移除其条目。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。丢弃某个键时,其条目从映射中有效地移除,因此,该类的行为与其他的 Map 实现有所不同。
ConcurrentHashMap
该类是线程安全的 Map 实现。与 Hashtable 相似,但 Hashtable 的 synchronized 是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap 允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对 hash 表的不同部分进行的修改。ConcurrentHashMap 内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
Hashtable 对 get,put,remove 都使用了同步操作,它的同步级别是正对 Hashtable 来进行同步的,也就是说如果有线程正在遍历集合,其他的线程就暂时不能使用该集合了,这样无疑就很容易对性能和吞吐量造成影响,从而形成单点。而ConcurrentHashMap 则不同,它只对 put,remove 操作使用了同步操作,get 操作并不影响。
该类不允许将 null 用作键或值。
ConcurrentSkipListMap
该类是可缩放的并发 ConcurrentNavigableMap 实现。映射可以根据键的自然顺序进行排序,也可以根据创建映射时所提供的 Comparator 进行排序,具体取决于使用的构造方法。
此类实现 SkipLists 的并发变体,为 containsKey、get、put、remove 操作及其变体提供预期平均 log(n) 时间开销。多个线程可以安全地并发执行插入、移除、更新和访问操作。迭代器是弱一致 的,返回的元素将反映迭代器创建时或创建后某一时刻的映射状态。它们不抛出 ConcurrentModificationException,可以并发处理其他操作。升序键排序视图及其迭代器比降序键排序视图及其迭代器更快。
相对于 ConcurrentHashMap,不仅 key 是有序的,而且 ConcurrentSkipListMap 支持更高的并发。ConcurrentSkipListMap 的存取时间是 log(N),和线程数几乎无关。也就是说在数据量一定的情况下,并发的线程越多,ConcurrentSkipListMap 越能体现出他的优势。
注意,调用ConcurrentSkipListMap 的 size 时,由于多个线程可以同时对映射表进行操作,所以映射表需要遍历整个链表才能返回元素个数,这个操作是个O(log(n))的操作。
此类不允许使用 null 键或值。
转载请注明:http://www.cnblogs.com/LeslieXia/p/5788816.html

