
Python对象的循环引用问题
Python对象循环引用
我们来介绍一下 Python 是采用何种途径解决循环引用问题的。
循环引用垃圾回收算法

上图中,表示的是对象之间的引用关系,从自对象指向他对象的引用用黑色箭头表示。每个对象里都有计数器。而图中右侧部分可以很清晰的看到是循环引用的垃圾对象。
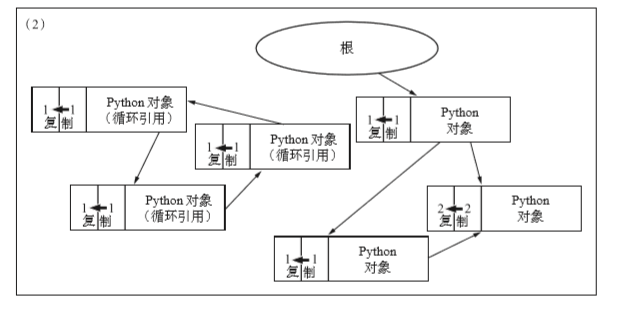
上图,将每个对象的引用计数器复制到自己的另一个存储空间中。
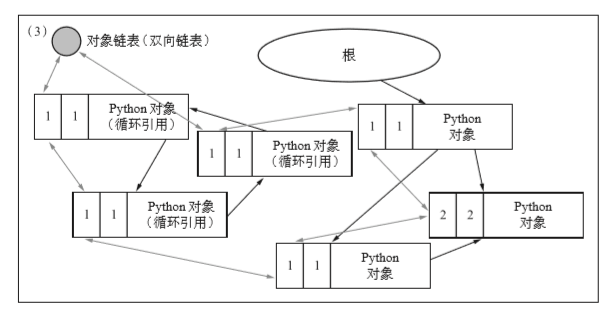
上图其实和图二(图片左上角)没什么区别,只不过更清晰了。因为对象本来就是由对象链表连接的。只不过是把对象链表画了出来。
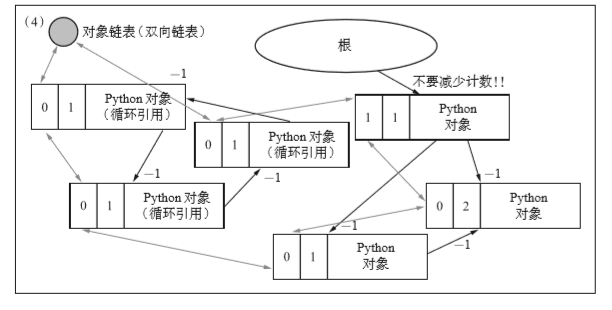
上图中,将新复制的计数器都进行了减量的操作。先不要管为什么,继续往下看。
但是可以看到,由根直接引用的对象中,新复制的计数器并没有减量。
以上操作执行完毕后,再把对象分为可能到达的对象链表和不可能到达的对象链表。
之后将具备如下条件的对象连接到“可能到达对象的链表”。
- 经过 (4) 的减量操作后计数器值大于等于 1。
- 有从活动对象的引用。
再将具备如下条件的对象连接到“不可能到达对象的链表”。
- 经过 (4) 的减量操作后计数器值为 0
- 没有从活动对象的引用
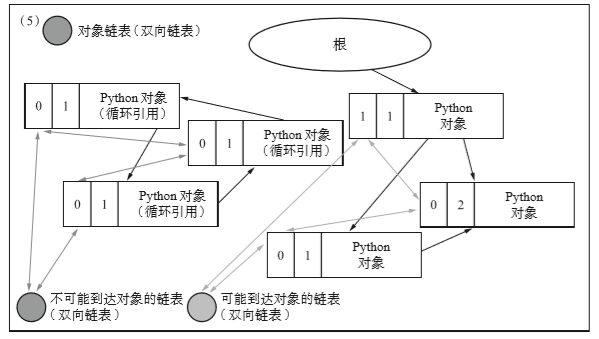
现在上图显示的就是垃圾对象链表和活动对象的链表了。接下来的步骤就是释放不可能到达的对象,再把可能到达的对象连接到对象链表。

这样,Python中只要将“部分标记-清除算法”稍加变形,就解决了循环引用问题。
容器对象
并不是所有的Python对象都会发生循环引用。有些对象可能保留了指向其他对象的引用,这些对象可能引起循环引用。
这些可以保留了指向其他对象的引用的对象 就被称为容器对象。具有代表性的就是元组,字典,列表。
非容器对象有字符串和数值等。这些对象不能保留指向其他对象的引用。
容器对象中都被分配了用于循环引用垃圾回收的头结构体
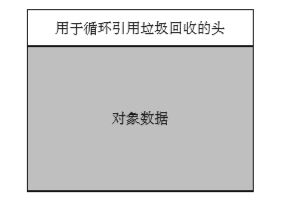
这个用于循环引用垃圾回收的头包含以下信息:
- 用于容器对象双向链表的成员。
- 用于复制引用计数器的成员。
定义如下:Include/objimpl.h
typedef union _gc_head {
struct {
union _gc_head *gc_next; /* 用于双向链表 */
union _gc_head *gc_prev; /* 用于双向链表 */
Py_ssize_t gc_refs; /* 用于复制 */
} gc;
long double dummy;
} PyGC_Head;
结构体 PyGC_Head 里面是结构体 gc 和成员 dummy 的联合体。
在这里成员 dummy 起到了一定的作用:即使结构体 gc 的大小为9字节这样不上不下的 数值,它也会将整个结构体 PyGC_Head 的大小对齐为 long double 型。因为结构体 gc 的大 小不太可能变成这样不上不下的数值,所以事实上 dummy 起到了一个以防万一的作用。
生成容器对象
在生成容器对象时,必须分配用于循环引用垃圾回收的头,在这里由 _PyObject_GC_Malloc() 函数来执行分配头的操作。这个函数是负责分配所 有容器对象的函数。
Modules/gcmodule.c: _PyObject_GC_Malloc():只有分配头的部分
PyObject * _PyObject_GC_Malloc(size_t basicsize)
{
PyObject *op;
PyGC_Head *g;
g = (PyGC_Head *)PyObject_MALLOC(
sizeof(PyGC_Head) + basicsize);
g->gc.gc_refs = GC_UNTRACKED;
/* 开始进行循环引用垃圾回收:后述 */
op = FROM_GC(g);
return op; }
-
1.首先分配对象,于此同时分配了结构体PyGC_Head。
-
2.将GC_UNTRACKED存入用于循环引用垃圾回收的头内成员gc_refs中。当出现这个标志的时候,GC会认为这个容器对象没有被连接到对象链表。
define _PyGC_REFS_UNTRACKED (-2)
这个_PyGC_REFS_UNTRACKED是GC_UNTRACKED的别名。gc_ref是用于复制对象的引用计数器的成员,不过它是用负值作为标识的。再次说明这里这样做,补另建立对象做这件事情是为了减轻负担。
-
3.最后调用了宏FROM_GC()返回结果。
define FROM_GC(g) ((PyObject *)(((PyGC_Head *)g)+1))
这个宏会偏移用于循环引用垃圾回收的头的长度,返回正确的对象地址。这是因为这项操作,调用方才不用区别对待有循环引用垃圾回收头的容器对象和其他对象。
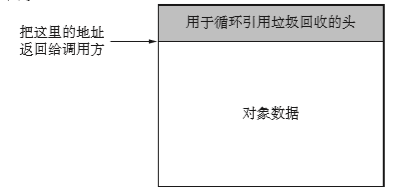
如果结构体 PyGC_Head 的大小没有对齐,FROM_GC() 返回的地址就是没有被对齐的不上 不下的值,因此需要按合适的大小对齐结构体 PyGC_Head 的大小。
追踪容器对象
为了释放循环引用,需要将容器对象用对象链表连接(双向)。再生成容器对象之后就要马上连接链表。下面以字典对象为例:
PyObject * PyDict_New(void)
{
register PyDictObject *mp;
/* 生成对象的操作 */
_PyObject_GC_TRACK(mp);
return (PyObject *)mp;
}
_PyObject_GC_TRACK() 负责连接链表的操作。
#define _PyObject_GC_TRACK(o) do {
PyGC_Head *g = _Py_AS_GC(o);
g->gc.gc_refs = _PyGC_REFS_REACHABLE;
g->gc.gc_next = _PyGC_generation0;
g->gc.gc_prev = _PyGC_generation0->gc.gc_prev; g->gc.gc_prev->gc.gc_next = g;
_PyGC_generation0->gc.gc_prev = g;
} while (0);
这个宏里有一点需要注意的,那就是do--while循环。这里不是为了循环,而是写宏的技巧。读代码时可以将其无视。
我们来看看宏内部_Py_AS_GC()的定义如下:#define _Py_AS_GC(o) ((PyGC_Head *)(o)-1)
- 首先从对象的开头,将头地址偏移相应的大小,取出循环引用垃圾回收的头。
- _PyGC_REFS_REACHABLE 这个标志存入成员 gc_refs 中。标志程序可能到达对象的意思。
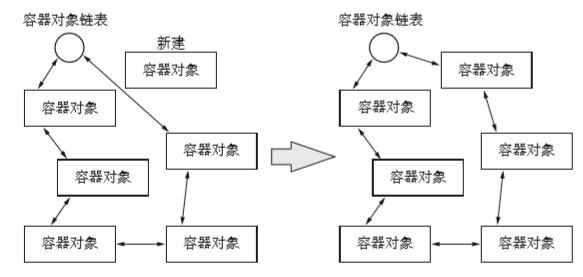
- 最后全局性容器对象链表(拥有所有容器对象的全局性容器),把对象连接到这个链表。
这样一来就把所有容器对象都连接到了作为容器对象链表的双向链表中。循环引用垃圾回收就是用这个容器对象链表来释放循环引用对象的。
结束追踪容器对象
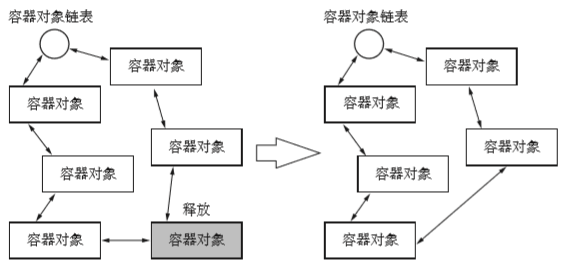
通过引用计数法释放容器对象之前,要把容器对象从容器对象链表中取出。因为呢没有必要去追踪已经释放了的对象,所以这么做是理所应当的。下面以字典对象为例释放字典的函数。
- 使用PyObject_GC_UnTrack() 函数来执行结束追踪对象的操作
- IS_TRACKED()包含在 PyObject_GC_UnTrack(),判断对象是不是正在追踪的对象
- AS_GC() 是之前讲过的宏 _Py_AS_GC() 的别名,包含在IS_TRACKED()里。用于判断对象是不是正在追踪,如果是就结束追踪。
- IS_TRACKED()包含在 PyObject_GC_UnTrack(),判断对象是不是正在追踪的对象
- _PyGC_REFS_UNTRACKED 这里只是将追踪对象以外的标志存入成员gc_refs,并从容 器对象链表中去除而已。
大多数情况下是通过引用计数法的减量操作来释放容器对象的,因为循环引用垃圾回收释放的知识具有循环引用关系的对象群,所以数量并没有那么多。
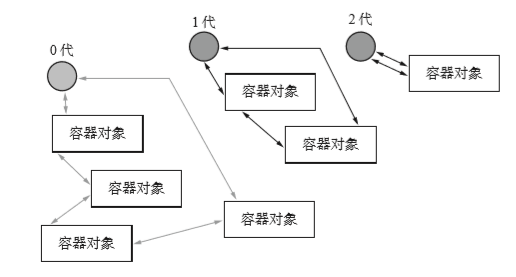
分代容器对象链表
容器对象链表分为三代。循环引用垃圾回收事实上是分带垃圾回收。
系统通过下面的结构体来管理各代容器对象链表。
struct gc_generation {
PyGC_Head head;
int threshold; /* 开始GC的阈值 */
int count; /* 该代的对象数 */
};
- 首先将容器对象连接到成员head
- 设置threshold阈值
- 当count大于阈值的时候启动GC。
- 不同的代阈值是不同的,count也是不同的。

一开始所有容器对象都连接0代对象。之后只有经过循环引用垃圾回收的对象活下来一定次数才能够晋升。
何时执行循环引用垃圾回收
在生成容器对象的时候执行循环引用垃圾回收。代码如下:
Modules/gcmodule.c
PyObject * _PyObject_GC_Malloc(size_t basicsize)
{
PyObject *op;
PyGC_Head *g;
/* 生成对象的操作 */
/* 对分配的对象数进行增量操作 */
generations[0].count++;
if (generations[0].count > generations[0].threshold && enabled && generations[0].threshold && !collecting && !PyErr_Occurred()) {
collecting = 1;
collect_generations();
collecting = 0;
} op = FROM_GC(g);
return op;
}
- 先进性对0代成员count执行增量操作。generations[0].count++;
- 接下来检测0代的count有没有超过阈值。
- 接着确认全局变量enabled是0以外的数值。只有在用户不想运行循环引用垃圾回收的时候,才为0.通过python就可进行设置。
- 确认threshold不为0.
- 确认循环引用垃圾回收是否正在执行。
- 最后执行PyErr_Occurred()函数检测有没有发生异常。
- 如果检测全部合格,就开始执行循环引用的垃圾回收。
- 在循环引用的垃圾回收时,将全局变量collecting设置1,调用collect_generations()函数。这就是调用循环引用垃圾回收的部分。
Modules/gcmodule.c
static Py_ssize_t collect_generations(void)
{
int i;
Py_ssize_t n = 0;
for (i = NUM_GENERATIONS-1; i >= 0; i--) {
if (generations[i].count > generations[i].threshold) {
n = collect(i); /* 执行循环引用垃圾回收! */ break;
}
}
return n;
}
在这里检查各代的计数器和阈值,对超过阈值的代执行GC,这样一来循环引用垃圾回 收的所有内容就都装入了程序调用的 collect() 函数里。
循环引用的垃圾回收
来看一下collect()Modules/gcmodule.c
static Py_ssize_t collect(int generation)
{
int i;
PyGC_Head *young; /* 即将查找的一代 */
PyGC_Head *old; /* 下一代 */
PyGC_Head unreachable; /* 无异样不能到达对象的链表 */
PyGC_Head finalizers;
/* 更新计数器 */
if (generation+1 < NUM_GENERATIONS) generations[generation+1].count += 1;
for (i = 0; i <= generation; i++)
generations[i].count = 0;
/* 合并指定的代及其以下的代的链表 */
for (i = 0; i < generation; i++) {
gc_list_merge(GEN_HEAD(i), GEN_HEAD(generation));
}
/* 给old变量赋值 */
young = GEN_HEAD(generation);
if (generation < NUM_GENERATIONS-1)
old = GEN_HEAD(generation+1);
else
old = young;
update_refs(young); /*把引用计数器复制到用于循环引用垃圾回收的头里 */
subtract_refs(young); /* 删除实际的引用 */
/* 将计数器值为0的对象移动到不可能到达对象的链表 */ gc_list_init(&unreachable);
move_unreachable(young, &unreachable);
/* 将从循环引用垃圾回收中幸存的对象移动到下一代 */
if (young != old)
gc_list_merge(young, old);
/* 移出不可能到达对象的链表内有终结器的对象 */ gc_list_init(&finalizers);
move_finalizers(&unreachable, &finalizers); move_finalizer_reachable(&finalizers);
/* 释放循环引用的对象群 */
delete_garbage(&unreachable, old);
/* 将finalizers链表注册为“不能释放的垃圾” */ (void)handle_finalizers(&finalizers, old);
}
- 首先将一个老年代的技术局执行增量操作,将制定的代的计数器设置为0。之后所指定的代及其以下代的链表合并到自己所属的代。
- 然后把引用计数器复制到用于循环引用垃圾回收的头里。从这个计数器删除实际的引用。循环引用的对象的计数器值会变为0。
- 之后把从GC中幸存下来的对象联通链表一起合并到下一代。让其晋升。
- 由于某些原因,程序无法释放有终结器的循环引用对象,所以要将其移除。
循环引用中的终结器
循环引用垃圾回收把带有终结器的对象排除在处理范围之外。这是为什么?
当然是因为太复杂了。哈哈
举个栗子假设两个对象是循环引用关系,如果他们都有自己的终结器那么先调用那个好?
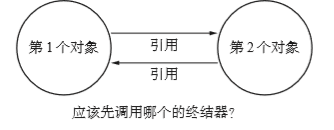
在第一个对象最终化后,第二个对象也最终化。那么或许在最终化的过程中又用到了第一个对象。也就是说我们绝对不能先最终化第一个对象。
所以在循环引用的垃圾回收中,有终结器的循环引用垃圾对象是排除在GC的对像范围之外的。
但是有终结器的循环引用对象,能够作为链表在Python内进行处理。如果出现有终结器的循环引用垃圾对象,我们就需要利用这项功能,从应用程序的角度去除对象的循环引用。
python关于GC的模块
gc.set_debug()(可以查看垃圾回收的信息,进而优化程序)
Python采用引用计数法,所以回收会比较快。但是在面临循环引用的问题时候,可能要多费一些时间。
在这种情况下,我们可以使用gc模块的set_debug()来查找原因,进而进行优化程序。
import gc
gc.set_debug(gc.DEBUG_STATS)
gc.collect()
# gc: collecting generation 2...
# gc: objects in each generation: 10 0 13607
# gc: done, 0.0087s elapsed.
一旦用set_debug()设定了gc.DEBUG_STATS标志,那么每次进行循环引用垃圾回收,就会输出一下信息。
1. GC 对象的代
2. 各代内对象的数量
3. 循环引用垃圾回收所花费的时间
当然除了DEBUG_STATS以外,还可以设置各种标志,关于这些标志可以查看源码或者官方文档。
gc.collect()
经过第一步的优化后,如果还是不行,就要用到gc.collect()。
使用gc.collect()就能在应用程序运行的过程中,任意时刻执行循环引用垃圾回收了。
也就是说,我们人为的选择最合适的时间去进行循环引用的GC。
gc.disable()
一旦调用 gc.disable(),循环引用垃圾回收就停止运作了。也就是说,循环引用的垃圾对象群一直不会得到释放。 然而从应用程序整体的角度来看,如果循环引用的对象的大小可以忽视,那么这个方法 也不失为一个好方法。这就需要我们自己来权衡了。
posted on 2019-01-01 23:08 Léon_The_Pro 阅读(6297) 评论(1) 编辑 收藏 举报


