

开发Web应用时,你经常要加上搜索功能。甚至还不知道要搜什么,就在草图上画了一个放大镜。
说到目前计算机的文字搜索在应用上的实现,象形文字天生就比拼音字母劣势的多,分词、词性判断、拼音文字转换啥的,容易让人香菇。
首先我们来了解下什么是Inverted index,翻译过来的名字有很多,比如反转索引、倒排索引什么的,让人不明所以,可以理解为:一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。而Inverted index 指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。并不是什么高深概念。
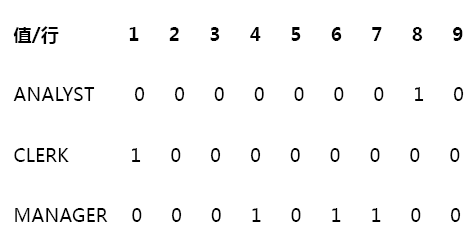
oracle里常用的位图索引(Bitmap index)也可认为是Inverted index。位图索引对于相异基数低的数据最为合适,即记录多,但取值较少。比如一个100W行的表有一个字段会频繁地被当做查询条件,我们会想到在这一列上面建立一个索引,但是这一列只可能取3个值。那么如果建立一个B*树索引(普通索引)是不合适的,因为无论查找哪一个值,都可能会查出很多数据,这时就可以考虑使用位图索引。位图索引相对于传统的B*树索引,在叶子节点上采用了完全不同的结构组织方式。传统B*树索引将每一行记录保存为一个叶子节点,上面记录对应的索引列取值和行rowid信息。而位图索引将每个可能的索引取值组织为一个叶子节点。每个位图索引的叶子节点上,记录着该索引键值的起始截止rowid和一个位图向量串。如果不考虑起止rowid,那么就是取值有几个,就有几个索引,比如上例,虽说有100W条记录,但是针对只有3个可取值的字段来说,索引节点只有3个,类似于下图:
需要注意的是,由于所有索引字段同值行共享一个索引节点,位图索引不适用于频繁增删改的字段,否则可能会导致针对该字段(其它行)的增删改阻塞(对其它非索引字段的操作无影响),是一种索引段级锁。具体请参看 深入解析B-Tree索引与Bitmap位图索引的锁代价。
下面说说笔者知道的一些全文搜索的工具。
文中绿色文字表示笔者并不确定描述是否正确,红色表示笔者疑问,若有知道的同学请不吝赐教,多谢!
- ICTCLAS分词系统
- Postgresql的中文分词
- Elasticsearch
- Quartz.net:用于定时任务,和全文检索无关,我们可以用它来进行定时索引管理,比如说过期店铺的产品索引删除
本来想借着ICTCLAS简单介绍下中文分词的一些原理和算法,不过网上已有比较好的文章了,可参看 ICTCLAS分词系统研究。中文分词基本上是基于词典,[可能]涉及到的知识 —— HMM(隐马尔科夫链)、动态规划、TF-IDF、凸优化,更基础的就是信息论、概率论、矩阵等等,我们在读书的时候可能并不知道所学何用,想较快重温的同学可阅读吴军博士的《数学之美》。这些概念我会择要在后续博文中介绍。下面我们就来看看分词系统在数据库中的具体应用。
在PostgreSQL中,GIN索引就是Inverted index,GIN索引存储一系列(key, posting list)对, 这里的posting list是一组出现键的行ID。 每一个被索引的项目都可能包含多个键,因此同一个行ID可能会出现在多个posting list中。 每个键值只被存储一次,因此在相同的键出现在很多项目的情况下,GIN索引是非常紧凑的(来自PostgreSQL 9.4.4 中文手册)。显然,将之应用到数组类型的字段上是非常合适的。全文检索类型(tsvector)同样支持GIN索引,可以加速查询。听说9.6版本出了一个什么RUM索引,对比GIN,检索效率得到了很大的提升,可参看 PostgreSQL 全文检索加速 快到没有朋友 - RUM索引接口(潘多拉魔盒)。
幸运的是,阿里云RDS PgSQL已支持zhparser(基于SCWS)中文分词插件。
连接要分词的数据库,执行以下语句:

-- 安装扩展
create extension zhparser;
-- 查看该数据库的所有扩展
select * from pg_ts_parser;
-- 支持的token类型,即词性,比如形容词名词啥的
select ts_token_type('zhparser');
-- 创建使用zhparser作为解析器的全文搜索的配置
CREATE TEXT SEARCH CONFIGURATION testzhcfg (PARSER = zhparser);
-- 往全文搜索配置中增加token映射,上面的token映射只映射了名词(n),动词(v),形容词(a),成语(i),叹词(e)和习惯用语(l)6种,这6种以外的token全部被屏蔽。
-- 词典使用的是内置的simple词典,即仅做小写转换。
ALTER TEXT SEARCH CONFIGURATION testzhcfg ADD MAPPING FOR n,v,a,i,e,l WITH simple;
set zhparser.punctuation_ignore = t; -- 忽略标点符号
现在我们就可以方便的进行中文分词了,比如“select to_tsvector('testzhcfg','南京市长江大桥');”,会拆分为“'南京市':1 '长江大桥':2”。如果要分的更细粒度,那么可以设置复合分词,复合分词的级别:1~15,按位异或的 1|2|4|8 依次表示 短词|二元|主要字|全部字,缺省不复合分词,这是SCWS的配置选项,对应的zhparser选项为zhparser.multi_short、zhparser.multi_duality、zhparser.multi_zmain、zhparser.multi_zall。比如我们要设置短词复合分词,那么就set zhparser.multi_short=on;那么“select to_tsvector('testzhcfg','南京市长江大桥');”得到的分词结果将是“'南京':2 '南京市':1 '大桥':5 '长江':4 '长江大桥':3”,这样就可以匹配到更多的关键词,当然检索效率会变慢。
短词复合分词是根据词典来的,比如词典中有'一次性'、'一次性使用'、’'一次性使用吸痰管'、'使用'、'吸痰管'5个词语,当multi_short=off时,select to_tsvector('testzhcfg','"一次性使用吸痰管"');返回最大匹配的"一次性使用吸痰管",而为on时,返回的是"'一次性':2 '一次性使用吸痰管':1 '使用':3 '吸痰管':4",让人困惑的是,结果里没有提取出'一次性使用'这个词,不知怎么回事。
在产品表上建一列tsv存储产品名称的tsvector值,并对该列建GIN索引。
CREATE OR REPLACE FUNCTION func_get_relatedkeywords(keyword text)
RETURNS SETOF text[] AS
$BODY$
begin
if (char_length(keyword)>0) then
RETURN QUERY select string_to_array(tsv::text,' ') from "Merchandises" where tsv @@ plainto_tsquery('testzhcfg',keyword);
end if;
end
$BODY$
LANGUAGE plpgsql VOLATILE
注意plainto_tsquery和to_tsquery稍微有点区别,比如前者不认识':*',而后者遇到空格会报错。
这会返回所有包含传入关键词的tsvector格式的字符串,所以我们要在业务层分解去重再传递给前端。
1 public async Task<ActionResult> GetRelatedKeywords(string keyword)
2 {
3 var keywords = await MerchandiseContext.GetRelatedKeywords(keyword);
4 if(keywords != null && keywords.Count>0)
5 {
6 //将所有产品的关键词汇总去重
7 var relatedKeywords = new List<string>();
8 foreach(var k in keywords)
9 {
10 for(int i=0;i<k.Count();i++) //pg返回的是带冒号的tsvector格式
11 {
12 k[i] = k[i].Split(':')[0].Trim('\'');
13 }
14 relatedKeywords.AddRange(k);//k可以作为整体,比如多个词语作为一个组合加入返回结果,更科学(这里是拆分后独立加入返回结果)
15 }
16 //根据出现重复次数排序(基于重复次数多,说明关联性高的预设)
17 relatedKeywords = relatedKeywords.GroupBy(rk => rk).OrderByDescending(g => g.Count()).Select(g => g.Key).Distinct().ToList();
18 relatedKeywords.RemoveAll(rk=>keyword.Contains(rk));
19 return this.Json(new OPResult<IEnumerable<string>> { IsSucceed = true, Data = relatedKeywords.Take(10) }, JsonRequestBehavior.AllowGet);
20 }
21 return this.Json(new OPResult { IsSucceed = true }, JsonRequestBehavior.AllowGet);
22 }
now,我们就初步实现了类似各大电商的搜索栏关键词联想功能:

然而,尚有一些值得考虑的细节。当数据库中产品表越来越大,毫无疑问查询时间会变长,虽然我们只需要前面10个关联词,但可能有重复词,所以并不能简单的在sql语句后面加limit 10。暂时缩小不了查询范围,可以减少相同关键词的数据库查询频率,即在上层加入缓存。key是关键词或关键词组合,value是关联关键词,关键词多的话,加上各种组合那么数据量肯定很大,所以我们缓存时间要根据数据量和用户搜索量定个合适时间。以redis为例:
1 public static async Task SetRelatedKeywords(string keyword, IEnumerable<string> relatedKeywords)
2 {
3 var key = string.Format(RedisKeyTemplates.MERCHANDISERELATEDKEYWORDS, keyword);
4 IDatabase db = RedisGlobal.MANAGER.GetDatabase();
5 var count = await db.SetAddAsync(key, relatedKeywords.Select<string, RedisValue>(kw => kw).ToArray());
6 if (count > 0)
7 db.KeyExpire(key, TimeSpan.FromHours(14), CommandFlags.FireAndForget); //缓存
8 }
9
10 public static async Task<List<string>> GetRelatedKeywords(string keyword)
11 {
12 IDatabase db = RedisGlobal.MANAGER.GetDatabase();
13 var keywords = await db.SetMembersAsync(string.Format(RedisKeyTemplates.MERCHANDISERELATEDKEYWORDS, keyword));
14 return keywords.Select(kw => kw.ToString()).ToList();
15 }
当用户在搜索栏里输入的并非完整的关键词——输入的文字并未精确匹配到数据库里的任一tsvector——比如就输入一个“交”或者“锁型”之类,并没有提供用户预期的自动补完功能(虽然自动补完和关键词联想本质上是两个不同的功能,不过用户可能并不这么想)。我们知道,在关键词后加':*',比如“交:*”,那么是可以匹配到的,如:select '交锁型:2 交锁型股骨重建钉主钉:1 股骨:3 重建:4'::tsvector @@ to_tsquery('交:*'),返回的就是true。然而我们总不能让用户输入的时候带上:*,在代码里给自动附加:*是一种解决方法(select to_tsquery('testzhcfg','股骨重建:*'),结果是"'股骨':* & '重建':*"),然而会带来可能的效率问题,比如select to_tsquery('testzhcfg','一次性使用吸痰管:*'),它会拆分为"'一次性使用吸痰管':* & '一次性':* & '使用':* & '吸痰管':*",并且出于空格的考虑,我们用的是plainto_tsquery,而它是不认识:*的。
当用户输入一些字符的时候,如何判断是已完成的关键词(进行关键词联想)还是未输完的关键词(自动补完),这是个问题。我们可以将用户常搜的一些关键词缓存起来(或者定期从tsv字段获取),当用户输入匹配到多个(>1)缓存关键词时,说明关键词还未输完整,返回关键词列表供用户选择,否则(匹配数量<=1)时,则去查询关联关键词。同样用redis(很幸运,redis2.8版本后支持set集合的值正则匹配):
/// <summary>
/// 获取关键词(模糊匹配)
/// </summary>
public static List<string> GetKeywords(string keyword, int takeSize = 10)
{
IDatabase db = RedisGlobal.MANAGER.GetDatabase();
//这里的pageSize表示单次遍历数量,而不是说最终返回数量
var result = db.SetScan(RedisKeyTemplates.SearchKeyword, keyword + "*", pageSize: Int32.MaxValue);
return result.Take(takeSize).Select<RedisValue, string>(r => r).ToList();
}
当然,也有可能用户输入已经匹配到一个完整关键词,但同时该关键词是另外一些关键词的一部分。我们可以先去缓存里面取关键词,若数量少于10个(页面上提示至多10个),那么就再去看是否有关联关键词补充。
大部分网站搜索还支持拼音搜索,即按全拼或拼音首字母搜索。
对关键词[组合]赋予权重,权重计算可以依据搜索量、搜索结果等,每次返回给用户最有效的前几条。这以后再说吧。
总的来说,数据库自带的全文检索还是建立在字段检索的基础上,适合传统SQL查询场景,而且围绕分词系统的查询方案和逻辑大部分需要自己处理,涉及到稍复杂的应用就力不从心,或者效率低下了(比如上述的自动补完功能),另外分布部署的时候也要在上层另做集群架构。
基于5.4版本
节点:一个运行中的 Elasticsearch 实例称为一个 节点。
集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。一个集群只能有一个主节点。
索引:作为名词时,类似于传统关系型数据库中的一个数据库。索引实际上是指向一个或者多个物理 分片 的 逻辑命名空间 。一个索引应该是(非强制)因共同的特性被分组到一起的文档集合, 例如,你可能存储所有的产品在索引 products 中,而存储所有销售的交易到索引 sales 中。
分片:一个分片是一个 Lucene 的实例(亦即一个 Lucene 索引 ),它仅保存了全部数据中的一部分。索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量;副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
类型:由类型名和mapping组成,mapping类似于数据表的schema,或者说类[以及字段的具体]定义。
技术上讲,多个类型可以在相同的索引中存在,只要它们的字段不冲突,即同名字段类型必须相同。但是,如果两个类型的字段集是互不相同的,这就意味着索引中将有一半的数据是空的(字段将是 稀疏的 ),最终将导致性能问题。——导致这一限制的根本原因,是Lucene没有文档类型的概念,一个Lucene索引(ES里的分片)以扁平的模式定义其中所有字段,即假如该分片里有两个类型A\B,A中定义了a\c两个字符串类型的字段,B定义了b\c两个字符串类型的字段,那么Lucene创建的映射包括的是a\b\c三个字符串类型的字段,如果A\B中c字段类型不一样,那么配置这个映射时,将会出现异常。由此亦知,一个分片可包含不同类型的文档。
文档:一个对象被序列化成为 JSON,它被称为一个 JSON 文档,指定了唯一 ID 。
假如文档中新增了一个未事先定义的字段,或者给字段传递了非定义类型的值,那么就涉及到动态映射的概念了。另外,尽管可以增加新的类型到索引中,或者增加新的字段到类型中,但是不能添加新的分析器或者对现有的字段做改动,遇到这种情况,我们可能需要针对此类文档重建索引。
在 Elasticsearch 中, 每个字段的所有数据 都是 默认被索引的 。 即每个字段都有为了快速检索设置的专用倒排索引。
乐观并发控制,Elasticsearch 使用 version 版本号控制、处理冲突。
Lucene中的[倒排]索引(在Lucene索引中表现为 段 的概念,但Lucene索引除表示所有 段 的集合外,还有一个 提交点 的概念 ),[一旦创建]是不可变的,这有诸多好处:
- 不需要锁;
- 重用索引缓存[,而非每次去磁盘获取索引](即缓存不会失效,因为索引不变),进一步可以重用相同查询[构建过程和返回的数据],而不需要每次都重新查询;
- 允许[索引被]压缩;
但是 数据/文档 变化后,毕竟还是得更新 索引/段 的,那么怎么更新呢?—— 新的文档和段会被创建,而旧的文档和段被标记为删除状态,查询时,后者会被抛弃。
安装Elasticsearch前需要安装JRE(Java运行时,注意和JDK的区别),然后去到https://www.elastic.co/start里,根据提示步骤安装运行即可。(笔者为windows环境)
安装完之后我们就可以在通过http://localhost:5601打开kibana的工作台。为了让远程机子可以访问,在启动kibana之前要先设置kibana.yml中的server.host,改为安装了kibana的机器的IP地址,即server.host: "192.168.0.119",注意中间冒号和引号之间要有空格,否则无效,笔者被此处坑成狗,也是醉了。同理,要elasticsearch远程可访问,需要设置elasticsearch.yml中的network.host。
单机上启动多个节点,文档中说 “你可以在同一个目录内,完全依照启动第一个节点的方式来启动一个新节点。多个节点可以共享同一个目录。” 没搞懂什么意思,试了下再开个控制台进入es目录执行命令行,会抛异常。所以还是老老实实按照网上其它资料提到的,拷贝一份es目录先,要几个节点就拷贝几份。。
ES官方给.Net平台提供了两个工具—— Elasticsearch.Net 和 NEST,前者较底层,后者基于前者基础上进行了更高级的封装以方便开发调用。
NEST有个Connection pools,这跟我们平常认为的连接池不是同一个概念,而是一种策略——以什么方式连接到ES——有四种策略:
- SingleNodeConnectionPool:每次连接指向到同一个节点(一般设置为主节点,专门负责路由)
- StaticConnectionPool:如果知道一些节点Uri的话,那么每次就[随机]连接到这些节点[中的一个]
- SniffingConnectionPool:derived from StaticConnectionPool,a sniffing connection pool allows itself to be reseeded at run time。然而暂时并不知道具体用处。。。
- StickyConnectionPool:选择第一个节点作为请求主节点。同样不知用这个有什么好处。。。
下面我们使用ES实现自动补完的功能,顺带介绍涉及到的知识点。
服务器根据用户当前输入返回可能的[用户真正想输的]字符串——"Suggest As You Type"。ES提供了四个Suggester API(可参看 Elasticsearch Suggester详解,这篇文章没有介绍第四个Context Suggester,我会在本节后面稍作描述),本文举例的自动补完,适合使用Completion Suggester(后面会说到使用上存在问题)。
我们先来看类型定义:
1 public class ProductIndexES
2 {
3 public long Id { get; set; }
4 public string ProductName { get; set; }
5 /// <summary>
6 /// 品牌标识
7 /// </summary>
8 public long BrandId { get; set; }
9 public string BrandName { get; set; }
10 /// <summary>
11 /// 店铺标识
12 /// </summary>
13 public long ShopId { get; set; }
14 public string ShopName { get; set; }
15 /// <summary>
16 /// 价格
17 /// </summary>
18 public decimal Price { get; set; }
19 /// <summary>
20 /// 上架时间
21 /// </summary>
22 public DateTime AddDate { get; set; }
23 /// <summary>
24 /// 售出数量
25 /// </summary>
26 public long SaleCount { get; set; }
27 //产品自定义属性
28 public object AttrValues { get; set; }
29 public Nest.CompletionField Suggestions { get; set; }
30 }
若要使用Completion Suggester,类型中需要有一个CompletionField的字段,可以将原有字段改成CompletionField类型,比如ProductName,我们同样可以针对CompletionField设置Analyzer,所以不影响该字段原有的索引功能(CompletionField接受的是字符串数组Input字段,经测试也看不出Analyzer对它的作用(自动补完返回的字符串是Input数组中与用户输入起始匹配的字符串,对分词后的字符串没有体现),所以Analyzer配置项的作用是什么令人费解);或者另外加字段,用于专门存放Input数组,这就更加灵活了,本例采用的是后者。
创建索引:
1 var descriptor = new CreateIndexDescriptor("products")
2 .Mappings(ms => ms.Map<ProductIndexES>("product", m => m.AutoMap()
3 .Properties(ps => ps
4 //string域index属性默认是 analyzed 。如果我们想映射这个字段为一个精确值,我们需要设置它为 not_analyzed或no或使用keyword
5 .Text(p => p
6 .Name(e => e.ProductName).Analyzer("ik_max_word").SearchAnalyzer("ik_max_word")
7 .Fields(f => f.Keyword(k => k.Name("keyword"))))//此处作为演示
8 .Keyword(p => p.Name(e => e.BrandName))
9 .Keyword(p => p.Name(e => e.ShopName))
10 .Completion(p => p.Name(e => e.Suggestions)))));//此处可以设置Analyzer,但是看不出作用
11
12 Client.CreateIndex(descriptor);
第6、7行表示ProductName有多重配置,作为Text,它可以用作全文检索,当然我们希望用户在输入产品全名时也能精确匹配到,所以又设置其为keyword表示是个关键词,这种情况就是Multi fields。不过由于我们设置了SearchAnalyzer,和Analyzer一样,用户输入会按同样方式分词后再去匹配,所以不管是全名输入或者部分输入,都可以通过全文检索到。
接着把对象写入索引,方法如下:
1 public void IndexProduct(ProductIndexES pi)
2 {
3 var suggestions = new List<string>() { pi.BrandName, pi.ShopName, pi.ProductName };
4 var ar = this.Analyze(pi.ProductName);//分词
5 suggestions.AddRange(ar.Tokens.Select(t => t.Token));
6 suggestions.RemoveAll(s => s.Length == 1);//移除单个字符(因为对自动补完来说没有意义)
7 pi.Suggestions = new CompletionField { Input = suggestions.Distinct() };
8
9 //products是索引,product是类型
10 Client.Index(pi, o => o.Index("products").Id(pi.Id).Type("product"));
11 }
假设我新插入了三个文档,三个suggestions里的input分别是["产品"],["产家合格"],["产品测试","产品","测试"],显然,根据上述方法的逻辑,最后那个数组中的后两项是第一项分词出来的结果。
接下来就是最后一步,通过用户输入返回匹配的记录:
1 public void SuggestCompletion(string text)
2 {
3 var result = Client.Search<ProductIndexES>(d => d.Index("products").Type("product")
4 .Suggest(s => s.Completion("prd-comp-suggest", cs => cs.Field(p => p.Suggestions).Prefix(text).Size(8))));
5 Console.WriteLine(result.Suggest);
6 }
好,一切看似很完美,这时候用户输入“产”这个字,我们期望的是返回["产品","产家合格","产品测试"],次一点的话就再多一个"产品"(因为所有input中有两个"产品")。然而结果却出我意料,我在kibana控制台里截图:
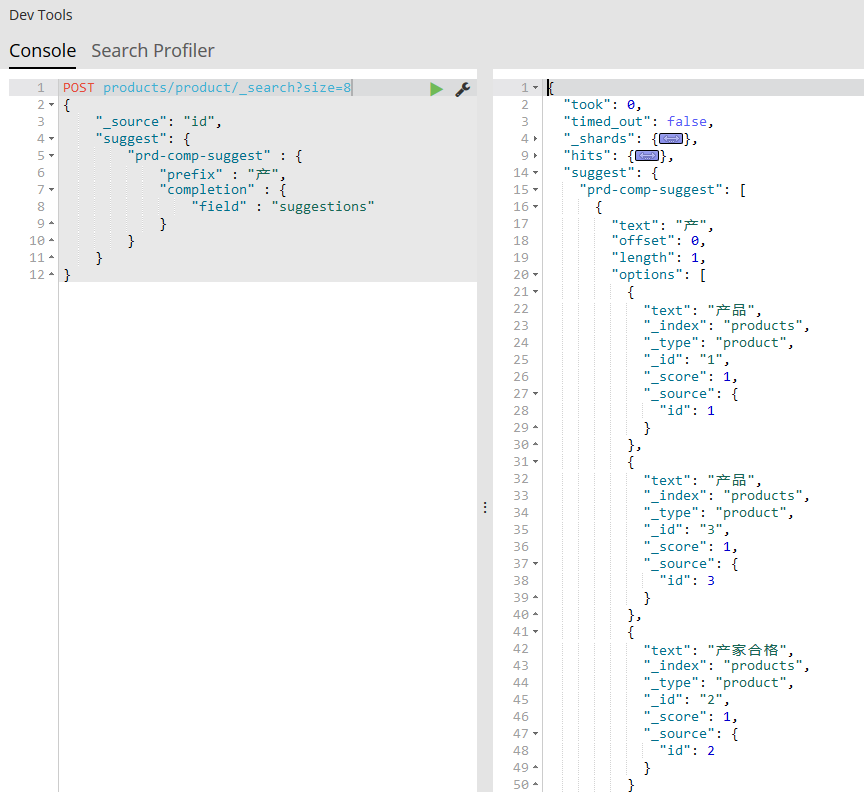
返回的是["产品","产品","产家合格"]。查找资料发现这似乎是ES团队故意为之——如果结果指向同一个文档(或者说_source的值相同),那么结果合并(保留其中一个)——所以Completion Suggester并不是为了自动补完的场景设计的,它的作用主要还是查找文档,文档找到就好,不管你的suggestions里是否还有其它与输入匹配的input。这时聪明的同学可能会说要不不返回_source试试看,很遗憾,官方说_source meta-field must be enabled,而且并没有给你设置的地方。之前有版本mapping时有个配置项是payloads,设置成false貌似可以返回所有匹配的input,还有output什么的,总之还是有办法改变默认行为的,然而笔者试的这个版本把这些都去掉了,不知以后是否会有改变。。。
Completion only retrieves one result when multiple documents share same output
这么看来,Suggester更像自定义标签(依据标签搜索文档,Completion Suggester只是可以让我们只输入标签的一部分而已)。所以说自动补全的功能还是得另外实现咯?要么以后有精力看下ES的源码看怎么修改吧。。
在Completion Suggester基础上,ES另外提供了Context Suggester,有两种context:category 和 geo,在查询时带上context即可取得与之相关的结果。意即在标签基础上再加一层过滤。
相关性:与之对应的重要概念就是评分,主要用在全文检索时。Elasticsearch 的相似度算法 被定义为检索词频率/反向文档频率, TF/IDF。默认情况下,返回结果是按相关性倒序排列的。
缓存:当进行精确值查找时, 我们会使用过滤器(filters)。过滤器很重要,因为它们执行速度非常快 —— 不会计算相关度(直接跳过了整个评分阶段)而且很容易被缓存。一般来说,在精确查找时,相关度是可以忽略的,排序的话我们更多的是根据某个字段自定义排序,所以为了性能考虑,我们应该尽可能地使用过滤器。
在给内容建索引时可以实时建立,也可以异步[批量]创建,后者的话我们常用计划任务的方式,涉及到的工具比较常见的是Quartz.Net。
以下对Quartz.Net的描述基于2.5版本。
Quartz.Net支持多个trigger触发同一个job,但不支持一个trigger触发多个job,不明其意。
Quartz.Net的job和trigger声明方式有多种,可以通过代码
IJobDetail job = JobBuilder.Create<IndexCreationJob>().Build(); ITrigger trigger = TriggerBuilder.Create().StartNow().WithSimpleSchedule(x => x.WithIntervalInSeconds(600).RepeatForever()).Build(); _scheduler.ScheduleJob(job, trigger);
或者通过xml文件。若是通过xml文件,则要指定是哪个xml文件,也可以设置xml文件的watch interval,还可以设置线程数量等等(大部分都有默认值,可选择设置),同样可以通过代码
XMLSchedulingDataProcessor processor = new XMLSchedulingDataProcessor(new SimpleTypeLoadHelper());
ISchedulerFactory factory = new StdSchedulerFactory();
IScheduler sched = factory.GetScheduler();
processor.ProcessFileAndScheduleJobs(IOHelper.GetMapPath("/quartz_jobs.xml"), sched);
以上代码即表示读取根目录下的quartz.jobs.xml获取job和trigger的声明。还有另一种代码方式:
var properties = new NameValueCollection(); properties["quartz.plugin.jobInitializer.type"] = "Quartz.Plugin.Xml.XMLSchedulingDataProcessorPlugin"; properties["quartz.plugin.jobInitializer.fileNames"] = "~/quartz_jobs.xml"; properties["quartz.plugin.jobInitializer.failOnFileNotFound"] = "true"; properties["quartz.plugin.jobInitializer.scanInterval"] = "600"; ISchedulerFactory sf = new StdSchedulerFactory(properties); _scheduler = sf.GetScheduler();
以上600表示makes it watch for changes every ten minutes (600 seconds)
当然我们可以通过配置文件(同声明job和trigger的xml文件,两者目的不同),如:
<configSections>
<section name="quartz" type="System.Configuration.NameValueSectionHandler"/>
</configSections>
<quartz>
<add key="quartz.scheduler.instanceName" value="ExampleDefaultQuartzScheduler"/>
<add key="quartz.threadPool.type" value="Quartz.Simpl.SimpleThreadPool, Quartz"/>
<add key="quartz.threadPool.threadCount" value="10"/>
<add key="quartz.threadPool.threadPriority" value="2"/>
<add key="quartz.jobStore.misfireThreshold" value="60000"/>
<add key="quartz.jobStore.type" value="Quartz.Simpl.RAMJobStore, Quartz"/>
<!--*********************Plugin配置**********************-->
<add key="quartz.plugin.xml.type" value="Quartz.Plugin.Xml.XMLSchedulingDataProcessorPlugin, Quartz" />
<add key="quartz.plugin.xml.fileNames" value="~/quartz_jobs.xml"/>
</quartz>
或者单独一个文件quartz.config:
# You can configure your scheduler in either <quartz> configuration section # or in quartz properties file # Configuration section has precedence quartz.scheduler.instanceName = QuartzTest # configure thread pool info quartz.threadPool.type = Quartz.Simpl.SimpleThreadPool, Quartz quartz.threadPool.threadCount = 10 quartz.threadPool.threadPriority = Normal # job initialization plugin handles our xml reading, without it defaults are used quartz.plugin.xml.type = Quartz.Plugin.Xml.XMLSchedulingDataProcessorPlugin, Quartz quartz.plugin.xml.fileNames = ~/quartz_jobs.xml # export this server to remoting context #quartz.scheduler.exporter.type = Quartz.Simpl.RemotingSchedulerExporter, Quartz #quartz.scheduler.exporter.port = 555 #quartz.scheduler.exporter.bindName = QuartzScheduler #quartz.scheduler.exporter.channelType = tcp #quartz.scheduler.exporter.channelName = httpQuartz
不需要特意指定是放在配置节中,还是quartz.config中,或者两者皆有,Quartz.Net会自动加载配置项。代码和配置方式也可以混着使用,总之给人的选择多而杂,加之官方文档并不完善,初次接触容易让人困惑。
参考资料:
HBuilder处理git冲突,同 10_Eclipse中演示Git冲突的解决
PostgreSQL的全文检索插件zhparser的中文分词效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号