

Maven构建Hadoop工程
阅读目录
序
上一篇,我们编写了第一个MapReduce,并且成功的运行了Job,Hadoop1.x是通过ant来管理工程的,后来到了2.x就开始使用maven来管理了。
那么我们就有理由用maven来构建我们的Hadoop工程。
Maven
一:说明
使用前,有必要简单的对maven做个简单的介绍,这样才比较轻松的熟悉本章节。
二:介绍
Maven是基于项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的软件项目管理工具。
Maven 除了以程序构建能力为特色之外,还提供高级项目管理工具。由于 Maven 的缺省构建规则有较高的可重用性,所以常常用两三行 Maven 构建脚本就可以构建简单的项目。由于 Maven 的面向项目的方法,许多 Apache Jakarta 项目发文时使用 Maven,而且公司项目采用 Maven 的比例在持续增长。
Maven这个单词来自于意第绪语,意为知识的积累,最早在Jakata Turbine项目中它开始被用来试图简化构建过程。当时有很多项目,它们的Ant build文件仅有细微的差别,而JAR文件都由CVS来维护。于是Maven创始者开始了Maven这个项目,该项目的清晰定义包括,一种很方便的发布项目信息的方式,以及一种在多个项目中共享JAR的方式。
三:特点
那么,Maven 和 Ant 有什么不同呢?在回答这个问题以前,首先要强调一点:Maven 和 Ant 针对构建问题的两个不同方面。Ant 为 Java 技术开发项目提供跨平台构建任务。Maven 本身描述项目的高级方面,它从 Ant 借用了绝大多数构建任务。因此,由于 Maven 和 Ant代表两个差异很大的工具,所以接下来只说明这两个工具的等同组件之间的区别,如表 1 所示
Maven Ant 标准构建文件 project.xml 和 maven.xml
build.xml 特性处理顺序 最后一个定义起决定作用。
第一个定义最先被处理。
构建规则 构建规则更为动态(类似于编程语言);它们是基于 Jelly 的可执行 XML。 构建规则或多或少是静态的,除非使用<script>任务 扩展语言
插件是用 Jelly(XML)编写的。 插件是用 Java 语言编写的。 构建规则可扩展性 通过定义 <preGoal> 和 <postGoal> 使构建 goal 可扩展。 构建规则不易扩展;可通过使用 <script> 任务模拟 <preGoal> 和 <postGoal> 所起的作用。 Maven是一个项目管理工具,它包含了一个项目对象模型 (Project Object Model),一组标准集合,一个项目生命周期(Project Lifecycle),一个依赖管理系统(Dependency Management System),和用来运行定义在生命周期阶段(phase)中插件(plugin)目标(goal)的逻辑。当你使用Maven的时候,你用一个明确定义的项目对象模型来描述你的项目,然后Maven可以应用横切的逻辑,这些逻辑来自一组共享的(或者自定义的)插件。Maven 有一个生命周期,当你运行 mvn install 的时候被调用。这条命令告诉 Maven 执行一系列的有序的步骤,直到到达你指定的生命周期。遍历生命周期旅途中的一个影响就是,Maven 运行了许多默认的插件目标,这些目标完成了像编译和创建一个 JAR 文件这样的工作。此外,Maven能够很方便的帮你管理项目报告,生成站点,管理JAR文件,等等。
安装
一:下载Maven
下载maven,官网地址:http://maven.apache.org/download.cgi
二:配置环境变量
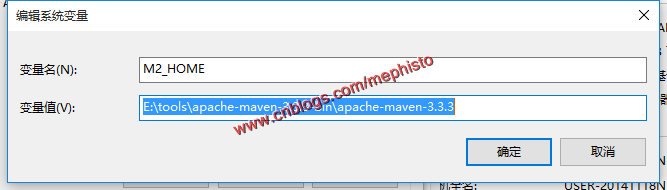
解压压缩包。将解压后的目录配置成环境变量
新建环境变量M2_HOME
在path中加入bin路径:%M2_HOME%\bin;
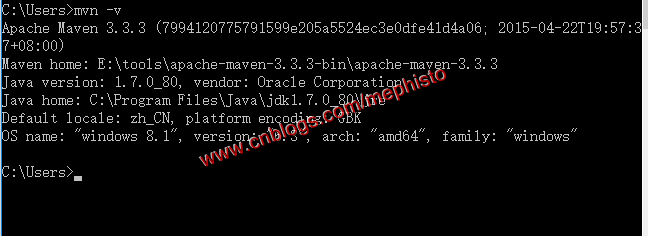
测试是否成功,打开命令行,输入mvn -v,能出现信息就说明ok。
三:安装m2eclipse插件
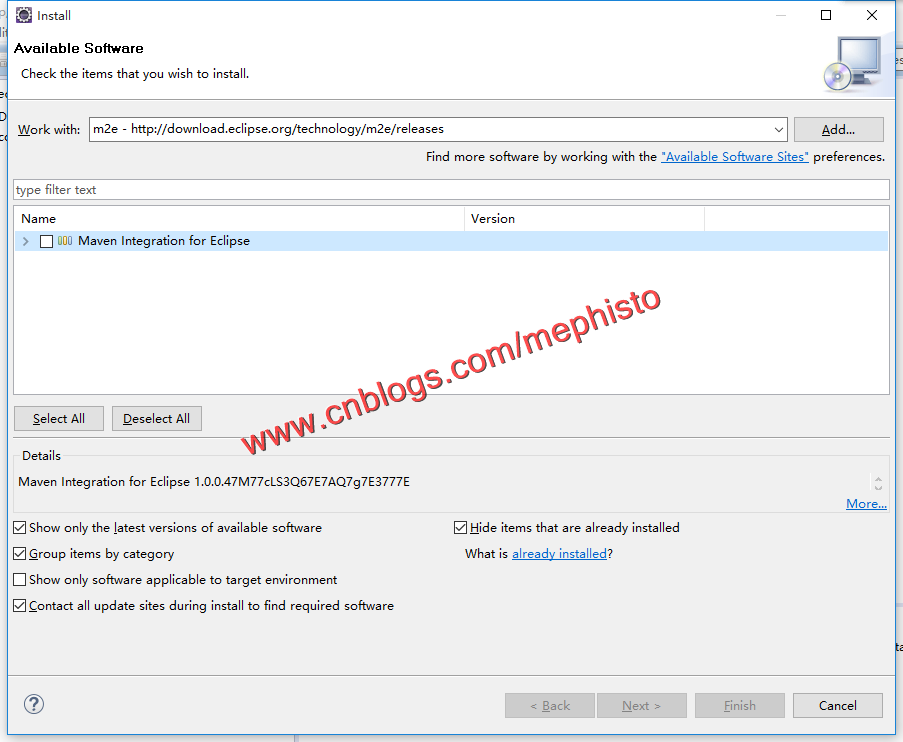
打开eclipse->Help->Install new software
新增一个m2e,下面填写http://download.eclipse.org/technology/m2e/releases,下一步
勾选了,点Finish.我们就可以看到漫长的进度条等待了。

构建
一:新建工程
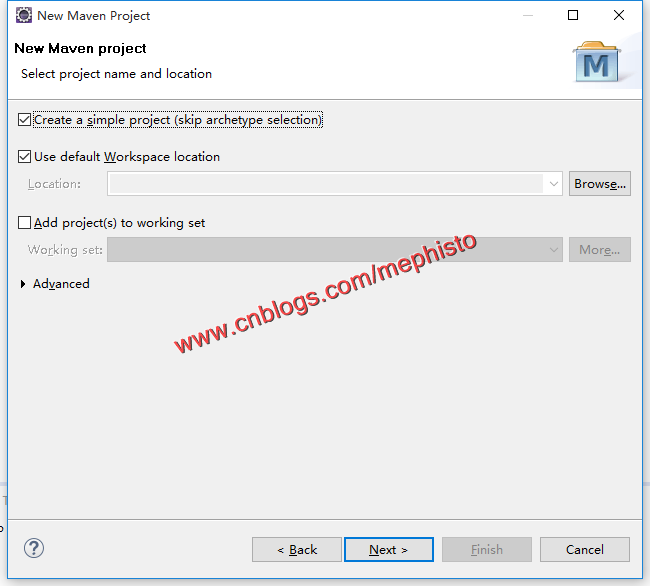
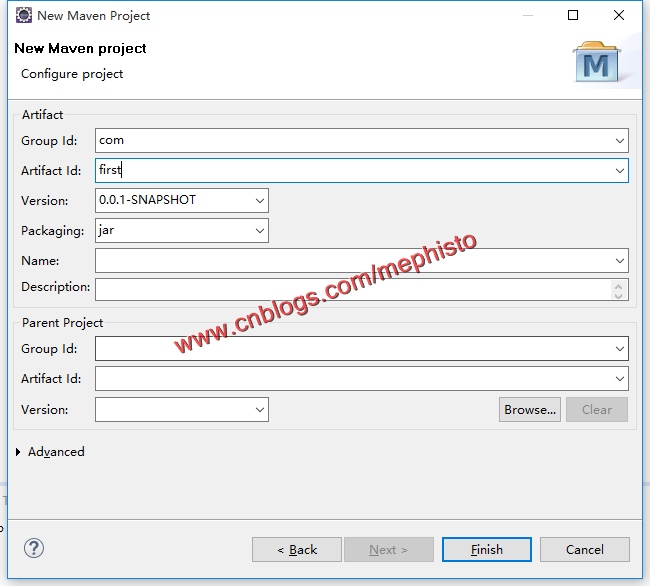
打开Eclipse ->File->New Project->Maven Project
这里我们就偷懒,建立一个simple项目。
输入Group 和Artifact
点击Finish
二:官网依赖库
我们可以直接去官网查找我们需要的依赖包的配置pom,然后加到项目中。
官网地址:http://mvnrepository.com/
三:Hadoop依赖
我们需要哪些Hadoop的jar包?
做一个简单的工程,可能需要以下几个
hadoop-common hadoop-hdfs hadoop-mapreduce-client-core hadoop-mapreduce-client-jobclient hadoop-mapreduce-client-common四:配置
打开工程的pom.xml文件。根据上面我们需要的包去官网上找,找对应版本的,这么我们使用的最新的2.7.1版本。
修改pom.xml如下:
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>2.7.1</version> </dependency> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.7</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency> </dependencies>五:构建完毕
点击保存,就会发现maven在帮我们吧所需要的环境开始构建了。
等待构建完毕。
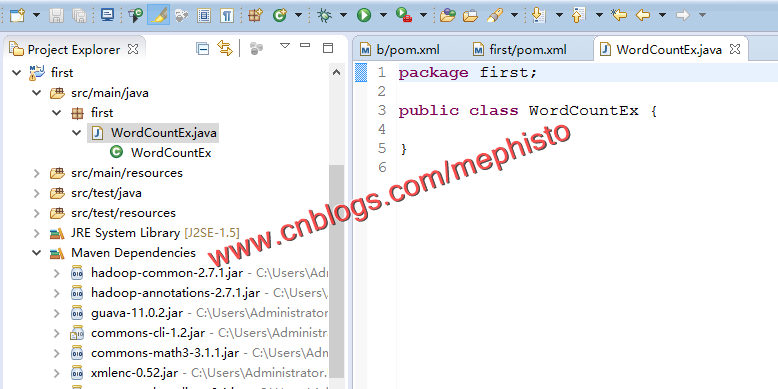
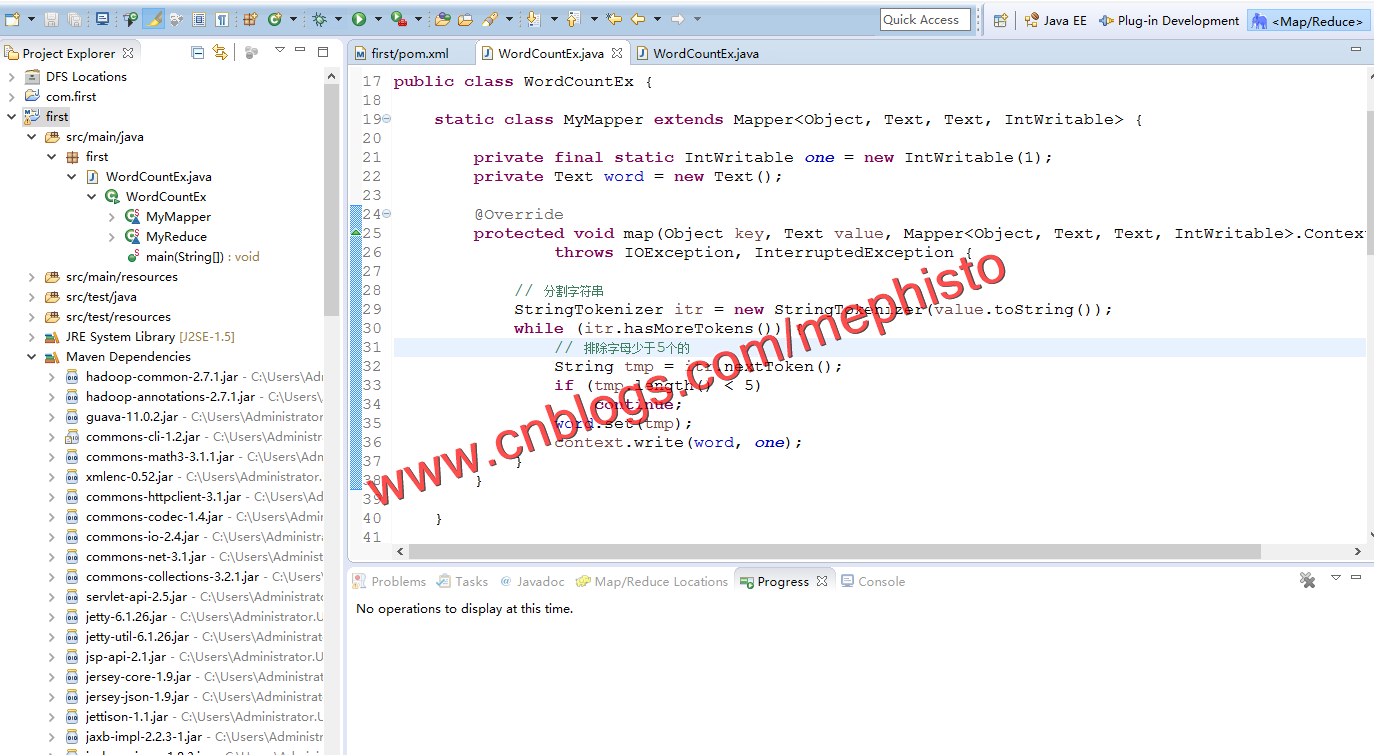
六:新建WordCountEx类
在src/main/java下新建WordCountEx类
将我们上篇编写的WordCountEx类的内容替换进来,记得package的名字别换了,测试的时候方便测试。
七:导出Jar包
点击工程,右键->Export,如下:
八:执行
将导出的jar包放到H31的/var/tmp下
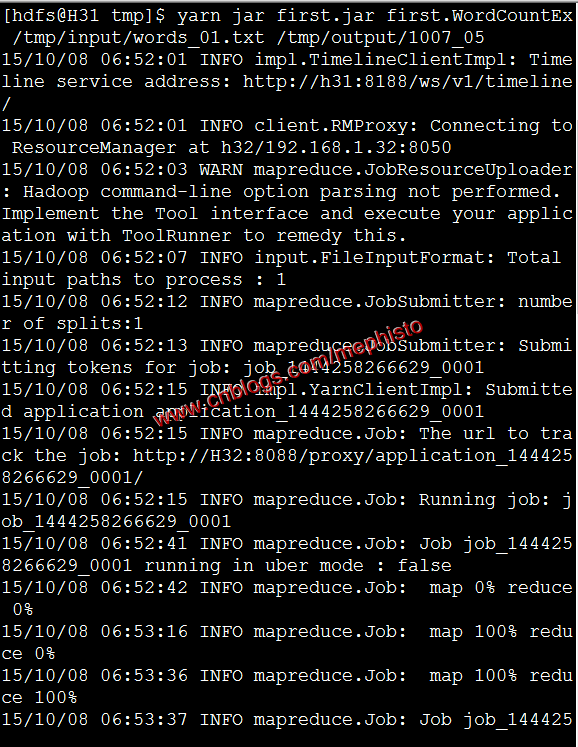
执行命令,发现很顺利的就成功了。
yarn jar first.jar first.WordCountEx /tmp/input/words_01.txt /tmp/output/1007_05
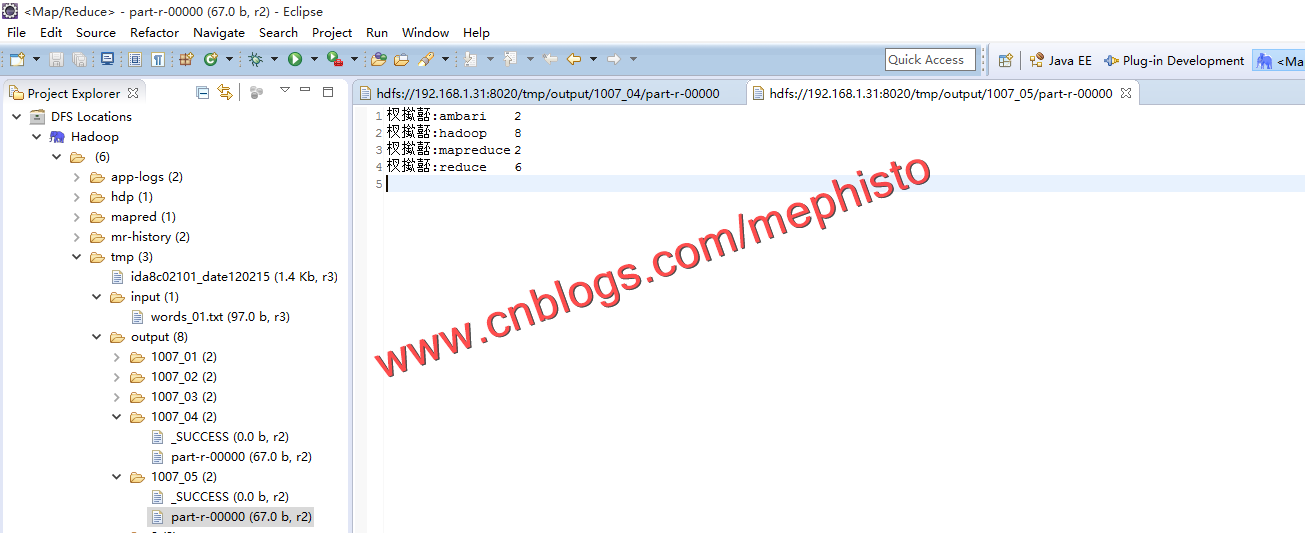
九:结果
我们看下输出的结果,和上一篇我们的输出结果是一致的。
--------------------------------------------------------------------
到此,本章节的内容讲述完毕。



示例下载
Github:https://github.com/sinodzh/HadoopExample/tree/master/2015/first
系列索引



 浙公网安备 33010602011771号
浙公网安备 33010602011771号