

Entity Framework 与 面向对象
说要分享,我了个*,写了一半放草稿箱了两个星期都快发霉了,趁着周末写完发出来吧。
文章分为五部分:
- 基础、类讲述的是用到的一些EF与面向对象的基础;
- 业务是讲怎么划分设计业务;
- 设计模式和工作模式讲述了在项目中用得比较多的通用的方法;
- 最后的项目迭代这次怎么迭代开发
文章的主要部分讲述的是如何利用Entity Framework同时满足数据存储和面向对象应用的最优化,所以总体上可以看成是一大波:数据库这么设计,然后面向对象那边这么用,可以让数据(更符合范式/效率更高/更方便管理),然后让面向对象利用数据(更方便/更高效/更安全)。
与许多观点不同,我认为ORM不仅不一定会因为“阻抗失配”导致数据库性能下降、潜能得不到发挥,反而觉得ORM可以挖掘出数据库更大的潜能,通过更合理的使用在很多地方提高其使用性能,将数据解放到业务中去。
现在有点晚了,我公司在山上,得赶着下山,没来得及审稿,所以有错误欢迎指正。
个人觉得有点赶,而且有点长,所以排列文本控制得不是很好,有待再继续补充或者修改。
======================分割线,专治强迫症,下面是半个月前的内容-------------------
上次才说要分享去年的项目,这次一下子被新的财务系统耗了三个多月,所以就干脆先分享下新系统中的内容。
总要有一个点开始展开进行分享,所以就从EF来进行展开,反正EF是贯穿头尾的。如果顺利的话或许还可以有《EF 和 业务逻辑》、《EF 和 Web》、《EF 和 小苹果》......
毕竟这篇文章不叫做《Pro EF》之类的讲原理,其目的是讲述在项目中对EF的应用和理解,所以涵盖不全,多多包涵。
ORM比如EF的使用有几重境界,很多来说跟框架本身的能力有关,最好的情况下也不过能停留在挖掘下ORM的功能而已。很多我见到的ORM使用不过是仅仅为了替代SQL,CRUD的思想并没有什么改变,所有很多项目还有Repository一层。
数据库是CRUD的,面向对象是“方法与事件”的,况且它们本身就有“阻抗失配”,就不是一个种族的。这里我并不想说明到底哪个好或者应该如何,我只是想在项目收尾阶段分享一下我在“假如更面向对象”的一次实践。
这次项目是接手去年不成功的财务项目,最终决定由我重做。反正基本上一个人从头到尾,那我就“放肆”下大胆地全OO式地进行。数据作为贯穿项目整体的一方面,已EF为基础,自然占了很重一部分,所以从EF进行扩展也是不错的选择。
第一部分Basic会简单地带过一些我对EF相关基础的“认识”,认识EF的跳过就好了;Class部分特地交代一些面向对象的用法;Business简单说明下在业务中的应用。
项目和示例中都采用Model First,基于EF5、VS 2012、SQL Server 2012。示例会在实际项目和Demo中穿插引用。
最后不得不提到的是,Entity Framework只有与LinQ相伴才能如此愉快地玩耍,所以中间穿插的LinQ就不多提了。
一、基础
Entity Framework Model First在开发过程中适合敏捷的基础是:图形化的设计器、数据库与模型的快速同步。
同步方面,由于我的打算是“更面向对象”,所以同步仅使用用模型生成数据库的方式。首先需要创建项目、在项目中添加ADO.NET Entity Data Model、在数据库服务器中创建相应的数据库。为了方便区分,我使用了相同的命名:

在创建好Model后,在图形设计界面中,右键然后选择将模型同步到数据库中,即可创建相应的SQL;运行该SQL,即可在相应数据库中创建对应的表与关系:

在项目代码层面,在生成Entity Model的同时,会创建一个继承与DbContext的类。该类抽象地说,对应的是指定的数据库,所有对于相关的数据库的访问都“经过”或者“通过”该类。在后来的EF版本中,这个DbContext的派生类基本上都命名为“Entity Model名称+Container”的形式,我习惯称这个类的实例为entities,因为从前的命名方式是“Entity Model名称+Entities”:
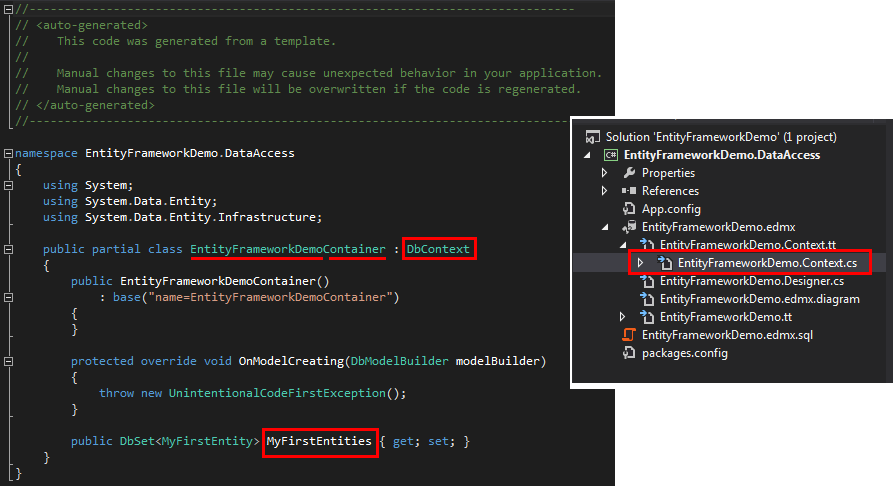
顺便简单地说明下CRUD的简单实现方式:


public MyFirstEntity Create()
{
//创建新的DbContext
var entities = new EntityFrameworkDemoContainer();
//创建新的实体
var newMyFirstEntity = new MyFirstEntity();
//将新对象插入到序列中
entities.MyFirstEntities.Add(newMyFirstEntity);
//执行数据操作
entities.SaveChanges();
//返回最新创建的实体
return newMyFirstEntity;
}
public MyFirstEntity Retrieve(int id)
{
//创建新的DbContext
var entities = new EntityFrameworkDemoContainer();
//查找到实体
var myFirstEntity = entities.MyFirstEntities.First(entity => entity.Id == id);
//返回查找到的实体
return myFirstEntity;
}
public void Update(int id)
{
//创建新的DbContext
var entities = new EntityFrameworkDemoContainer();
//查找到实体
var myFirstEntity = entities.MyFirstEntities.First(entity => entity.Id == id);
//修改实体
/*此处略去修改实体代码*/
//保存修改
entities.SaveChanges();
}
public void Delete(int id)
{
//创建新的DbContext
var entities = new EntityFrameworkDemoContainer();
//查找到实体
var myFirstEntity = entities.MyFirstEntities.First(entity => entity.Id == id);
//删除实体
entities.MyFirstEntities.Remove(myFirstEntity);
//保存修改
entities.SaveChanges();
}
对象与表
在设计器中创建相应的Entity,就会在项目中创建相应的Class,同步到数据库后,就会创建相应的Table。Table的名称会是Entity的复数形式,大部分情况下语法是没有错的。

对应地,在上面的CRUD示例中已经说明了如何访问这张表的数据了。
字段与属性
在设计器中,可以为指定的Entity添加属性,添加属性后可以通过Properties进行设计。同步到数据库后,对应的属性会生成对应的Table Column。当然,在项目中,也会在原有的类上添加相应的属性。相关的类型的状态会自动匹配。可以看到用相同颜色标记的对应的对象在不同方面的体现,比如类型、属性名称、可空性(Nullable)。
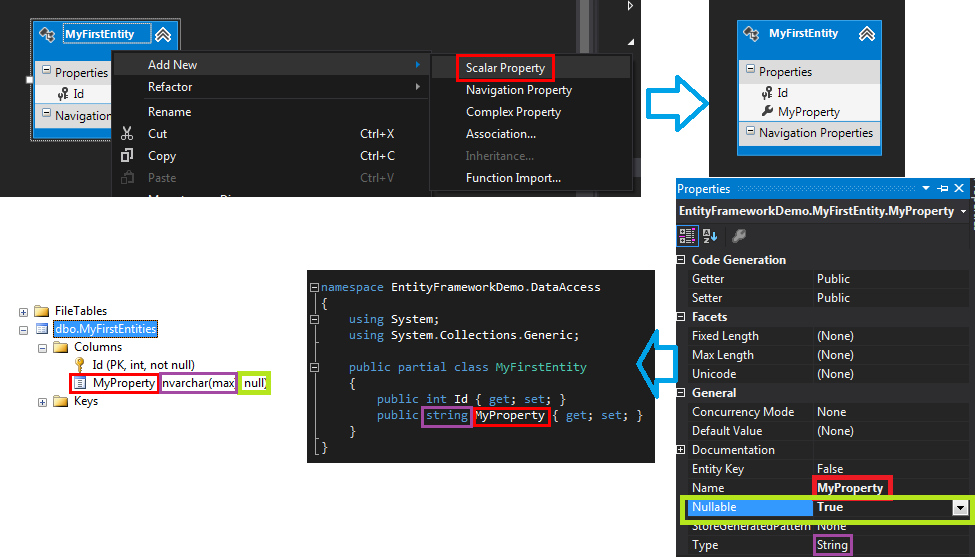
引用与关系
在这里,我创建了第二个实体,然后添加了与第一个实体的关联。在添加关联中,我选择了一对多,并且在设计时,使用了默认生成的“引用名”,先看看结果再讲解:
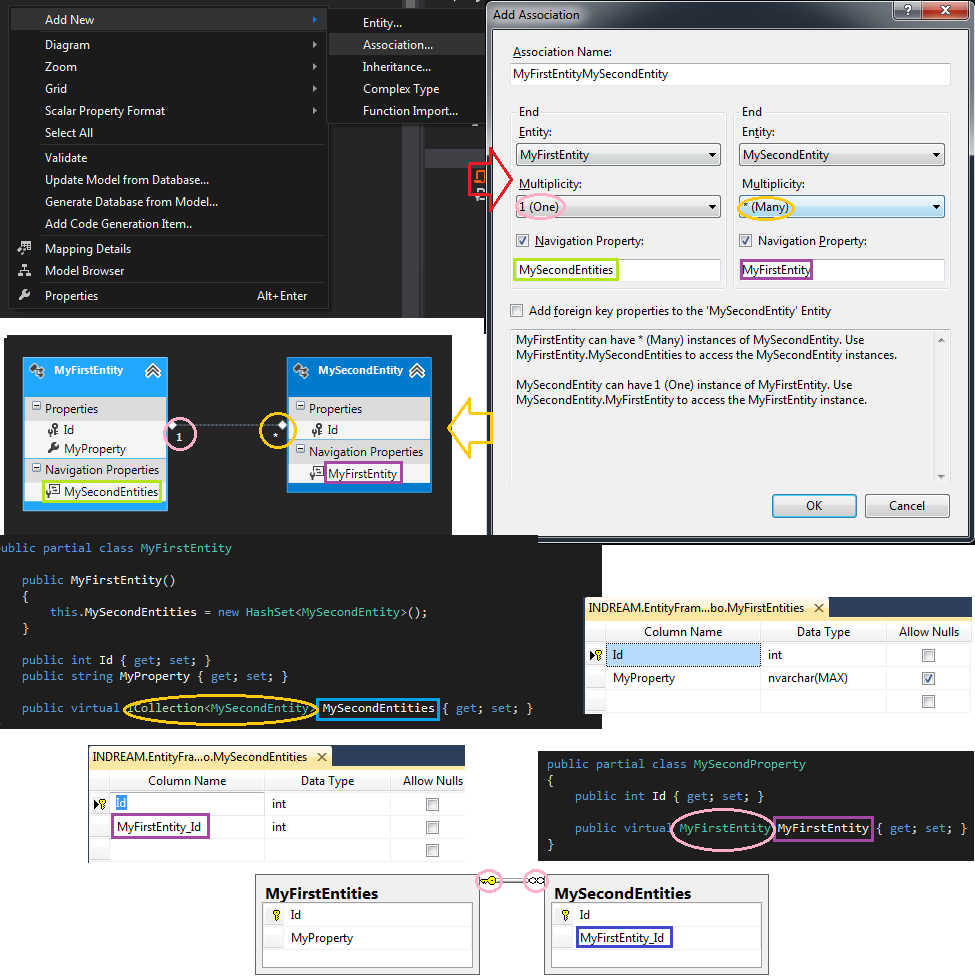
可以看到,在数据库层面,也生成了相应的一对多关系。其实现方法是通过“多”的那张表添加的一个指向“一”表主键的外键而实现的,基本还很好理解。
回到对象层面,可以看到“一”的类MyFirstEntity中多出了一个MySecondEntites的集合属性,要注意命名还是自动复数的。对应的MySecondEntity里也有一个单一的MyFirstEntity属性。
假设myFirstEntity为一个MyFirstEntity的实例,mySecondEntity为一个MySecondEntity的实例。那么,在C#中,访问myFirstEntity中关联的所有MySecondEntity的方式即为:
myFirstEntity.MySecondEntities
同理,在mySecondEntity中访问相关联的myFirstEntity为:
mySecondEntity.MyFirstEntity
要注意的是,在对象层面的关系中,还有“0..1”,即1个或者0个,在数据库实现中,则是一个可空的外键。
注意我在添加关系的时候,并没有勾选“添加外键属性到...”,整个项目中都没有。在以往的经验里,外键容易让开发人员“像操作关系数据库一样操作数据”,导致代码陷入一种很奇怪的情形。
在这里,不得不说到面向对象和关系数据库的“关系”问题。首先插入一个数学式子:
- 用R(A, B)来描述实体(表/类)A与实体B的数量关系
- 如果一个A对应一个B,则R(A, B)为1
- 如果一个A对应多个B,则R(A, B)为n
- 如果A与B没有关系,则R(A, B)为0
- 如果R(A, B), R(B, C) > 0,那么R(A, C) = R(A, B) * R(A, C)
如果用自然语言举例来说,那就是,如果每个A有(关联)一个B,每个B有(关联)一个C,那么每个A有(关联)一个C。
在说到具体事例前,我再探讨一下数据库范式,细就不讲,数据库范式的作用就是为了使得数据冗余最少,这么讲应该没什么歧义。
那么我的结论就来了:使用EF(或者类似ORM)能使得数据库设计更容易实现更高范式。
举个例子,如果每个A对应一个B,每个B对应一个C,...,每个Y对应一个Z;那么,每个A对应一个Z。
如果我拥有一个A的实例a,我需要获取其对应的实例z,那么应该怎么实现?
如果是用SQL,那么问题就变成:“如果我有一个A的主键ID,如何获取相关的Z的Row?”
可能是个人并不熟悉SQL,所以在我有限的SQL知识看来,我需要些一段很长很长很长很长很长很长很长很长的SQL才能查到我要的数据。所以一般出现这种情况,我会“*他*的范式!”然后直接拉一条A与Z的关联,虽然不仅没遵循范式,而且连“环”都产生了。
如果在EF,这么简单地写就可以访问到了:
a.B.C.D.E.F.G.H.I.J.K.L.M.N.O.P.Q.R.S.T.U.V.W.X.Y.Z;
当然,实际上还是执行了一段可怕的SQL,但是因为用起来简单了,所以更加不需要随意打破范式了。
如果我经常需要从A访问Z,需要:
a.Z;
那么就应该参考后面的“扩展字段”部分了。
复杂一点,如果R(A, B) = 1, R(B, C) = n,那么对应R(A, C)为n没错;如果R(A, B), R(B, C) = n,那么R(A, C) = n ^2,在C#中访问A的C集合当然用LinQ的SelectMany了;如果从A到Z都那么成倍又需要访问,又不想每次写那么多SelectMany嵌套呢?那就只好参考后面“扩展字段”部分了。
在关系数据库中,“关系”仅仅包含着1对n,n对n为两个1对n组合;而在面向对象里,由于对象更多地接近使用自然语言的方式描述“关系”,其“关系”就变得复杂而不好理解了。更多的内容,还需要讲述完下面“继承与关系”才能比较好展开。
另外可以说明下对关系进行复制,也就是添加关联,可以简单地进行对象复制,而不需要触动到外键:
myFirstEntity.MySecondEntites.Add(newMySecondEntity);
这里示范的是一对多的关系,而一对一的情况下只需要直接赋值即可。
二、类
虽然作为ORM,必然有一半关于关系数据库,另一半关于面向对象,而我确把关于关系数据库的部分放到了“基础”。因为总体来说,我觉得ORM的发展是沿着“SQL=>Data Framework(如ADO.NET)=>OO”的趋势下去的,所以把OO部分放到了“更高级别”的地方。
另外,在这种划分情况下,可以大致地理解为我把“存储在数据库中的”放到了基础,把“另外表现在面向对象中的”放到了后面。
继承与关系
既然是面向对象,那当然要有最基础的关系——继承。
在EF中,可以设计两个类为基类子类关系,甚至一个基类多个子类。
同样在设计器中添加继承即可,可以创建完父类子类后再“添加继承”,或者直接在创建子类的时候选择父类:

在设计时,我们“创建了一个基类和继承与该基类的子类”,而在数据库中则是“创建了一个表以及一张关系与其1对1/0的从表”。在数据库层面,这两张表共用ID,当然了,因为他们是一一对应的关系,同值的主键和直观;在类层面,可以看到只有Base才有ID,Sub在定义上没有,实际上“继承了”Base的ID,也拥有一个ID。
要注意的是,在DbContext处,并没有产生Sub的DbSet序列属性,需要通过Base来才能访问得到Sub,使用OfType<TSub>():
var subs = entities.Bases.OfType<Sub>();
插入Sub实例/行的时候,也需要通过Bases:
entites.Bases.Add(new Sub()); entities.SaveChanges();
访问性
在表里面都不过是数据字段,而在面向对象(基本上指代C#一类传统面向对象语言)中,是有“访问性”一说。
在上面的基础上,我可以把基类设置为抽象类,把字段设置访问性(public/protected/privite/internal),右键相关的实体/字段,选择属性(Properties):

而在数据库部分,则只是比上面多添加了一个SubProperty的Column而已。用相关访问行的方法,可以很好地在应用层保护数据的逻辑安全性。
抽象类保证了无法在绕过子类(不插入表Bases_Subs数据)的情况下创建基类对象(插入Bases数据),保证了数据上的匹配度;而字段访问行则控制了的读写。
扩展字段
不要被小标题迷惑了,跟“C#扩展方法”没有半毛钱关系,也不是同样层面的事物。这里指的是,在不增加数据库字段的情况下扩充类层面的字段。
实现扩展字段的基础,是所有的模板自定义创建类都是partial的。因为每次更改模板,所有在该Data Model文件下的类,包括DbContext都会从T4模板重新生成一次,所以你无法在原有的类基础上进行任何修改,那么默认类为partial则尤为重要。
只要创建一个类,定义为上面Base的partial类,并添加一个ExtendProperty字段,生成表后与之前并没有什么区别,自定义扩展的字段并不会生成到表上:
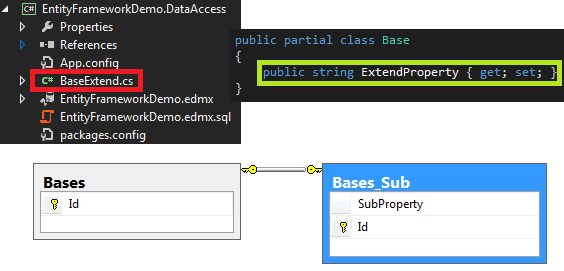
然后,在空数据库的场景下运行了下面这段代码,可以看到当时Watch的结果(我已经把SubProperty的访问性改回了可写):

然后在运行一次下面的比对代码:
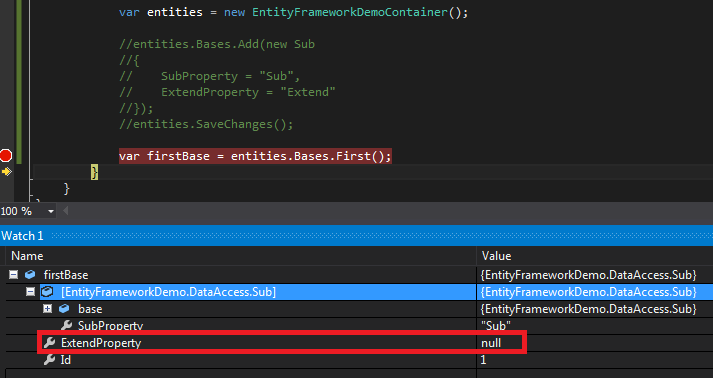
可以看到两次结果截然不同,第二次的ExtendProperty字段为空。因为第一次获取的是一开始插入Base列表的对象,缓存了起来,而第二次是重新重数据库中读取的对象,数据库中并没有该字段,而一开始的缓存中有,所以产生了这项差异。
同时我们可以参考数据库中的数据:
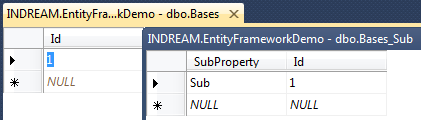
同时也可以注意到,Bases_Sub表的主键是可读写的,而Bases表的主键是自增的。也就是说Bases_Sub表的主键是同步自Bases表对应的条目。
通过扩展字段,我们可以很好地让很多重用性高的访问方式被“优雅地”封装起来,比如下面跟/子节点/孙节点的例子:

在这里,我建议列表中尽量返回LinQ表达式值,而尽量不返回任何包含实例化行为的序列,以进行性能保护。
不应随意使用扩展字段作为LinQ查询条件,因为在数据库中不存在的字段势必会造成全集无索引的遍历。
至于计算出的扩展的字段,我建议尽量使用缓存,而不每次都进行计算。
继承与约束
有了上面的的基础和扩展字段,就可以进行一些“多态”一点的行为。
继续上面的例子,在基类上添加一个抽象方法,然后“迫使”子类必须实现该方法:
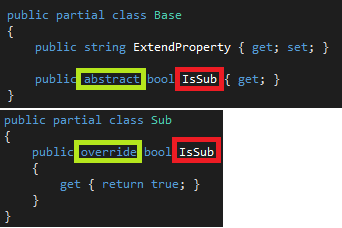
在这里要注意的是Base本身就是虚类,但在partial里不需要重复声明,写上也无妨。
跟上面的扩展出来的字段一样,在表中都不会产生字段。
三、业务
有了上面的建模,之后就是如何使用进行业务操作的问题了。
在一次EF的数据操作中,总体上是包含下面四部分:
- 新建DbContext
- 操作DbContext实例获取数据
- 对数据进行读写
- 通过DbContext保存数据修改
最后一步在写操作的时候才会发生/使用。
其中要注意的是,所有操作都是围绕同一个DbContext实例进行的。
首先看看下面代码,firstBase和firstBase2的值如同上面所设定,显而易见:
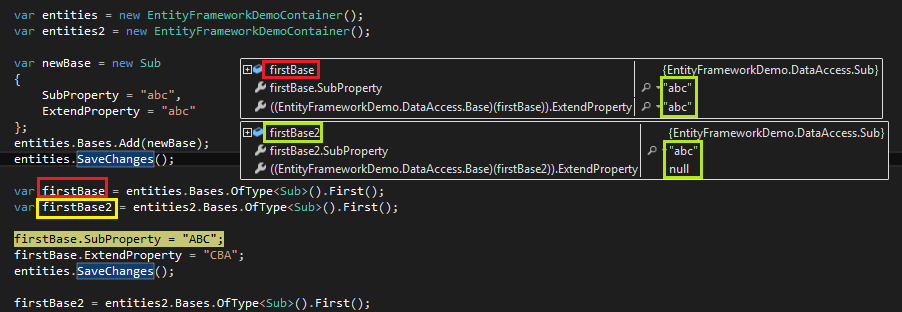
再往下运行才是我想说的重点:

可以看到,即使获取对象在保存对象之后,存在明显的先写后读的关系,不同DbContext(文中的entities和entites2)对象取出的数据所在历史阶段也不一致。
也就是说,一旦一个DbContext获取过某个数据之后,就会产生数据缓存,而该缓存的作用域在于该DbContext上。
同样的道理可以扩充到:对同一个DbContext获取到的对象进行修改,只能通过该DbContext进行保存修改。
特别是还要扩充到:只有来自同一个DbContext的对象才可以进行关联并且保存,否则在保存的时候会发生异常。
正因如此,才会产生下面的“协作与事务”的问题,也是这一节的三个小节衍生源。
实体与劳工
什么是面向对象的工作场景?我看到印象最深刻的解释居然是来自iOS开发的官方入门教程,大致的内容就是说,“你可以认为是一群存在的对象互相协作并完成工作。”翻不出来了,不过大致如此。
在这里我并不想完全“颠覆”纯仓储模式,只是CRUD地工作让我觉得很别扭,当方法足够多的时候难以对业务进行重用等等。而在使用EF的时候我也不再写一个包含Repository的层,因为我觉得很多余,另一个就是我希望尽量地减少层次,以简化系统复杂度。
另外摘录DbContext的注释的第一段话,或许比较有参考价值:

上面说到,一个DbContext实例“已经是”一个工作单元和仓储模式的混合。这也很容易理解,因为一个DbContext实例已经包含了CRUD全功能。不过这个实例如同业务的需求一样,它是完整的,也是“残缺”的。如果只CRUD那么每次业务就是:选取数据=》更新数据=》持久化。而数据只是系统运行时的业务状态值,而不是系统本身。系统的目的是为了实现业务而存在的,而不是持有业务的数据。
回到这里,即时DbContext包含了CRUD,它也没有很好地表达出业务。举例说,用户提交一张申请单,如果我们将其解释为“用户申请XXX”,那么我们希望见到代码中表现出来的不是:
entities.Applications.Add(new Application
{
Title = xxx,
Balance = xxx
});
entities.SaveChanges();
而是:
applicationService.Apply(title, balance);
下者不过是上者的一个封装,但是却又不一样的意义。我们使用OO是为了让代码更贴近现实,而让创造出的系统更加符合现实业务需求。也就是只使用DbContext只能描述对数据的操作,却无法描述业务,所以我们需要一个业务层。
描述业务可以有很多种甚至无数种建模,因为现实中人看问题有很多种角度,比如同为申请单业务,也可以这么理解:
user.ApplyBalance(title, balance);
“让用户去申请”,看似也没错。甚至在建模中可以用很多夸张的、绚丽的设计模式,但那却是最糟糕的设计模式,因为模式太多了、无法维护、浪费代码等等。
我需要一个设计的方式,让总体保持一致,同时易于理解。借鉴DDD,我把在业务中存在的对象划分成了两个角色:实体与劳工。
实体指代的是数据对象,而劳工则是管理、操作、加工数据对象的工作者。“实体”大多数情况下就是一个定义好的EF对象,毕竟我使用EF作为主要的数据操作方式。
这与传统的三层架构很相似,或许是殊途同归。我在劳工使用的后缀为“Manager”,或者少数情况为了细化,同样会使用工作者的命名方式,比如:Helper、Provider、Worker......重要的是,我把它们抽象成了一个显示存在的运行机器或者团队,有着像工程运行一样的从属关系、合作关系。
如果要有个贴切的简述,那就是:劳工是有主动性的有生命的,实体则是劳工们劳作中的操作对象和产出,同时也不排除一个领域的劳工和实体同时存在,比如用户(User)和管理用户的劳工(UserManager)。
职责与封闭
我相信每个劳工的职责都应该是单一的、封闭的,所以将所有劳工都设计成职责单一封闭。而实现的依据便是一开始的需求文档:
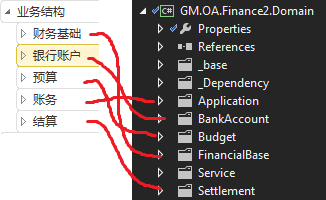
左边是文档中的结构,右边是代码中的结构,基本上能与文档一一对应。实现的类的描述也是尽量语义化,这样做的目的是为了贴合需求,而且减少代码与需求间的阻隔,让代码更易维护。这里我们还是讲EF的文章,所就不多做扩展了。
粗俗地说,可以理解为,『汇率Manager』就只管理汇率,而『申请单Manager』就只管理申请单。
劳工们的关系也简单地划分为两种:
- 上下级——A劳工为B劳工的上级,所以A老公包含(has a)B
- 协作——A劳工和B劳工在某些业务中有合作关系,A引用(depend on)B
当然,其中的缺点也就是无法进行循环依赖。
这里有一个灰色地带要划清界限,也就是获取关联数据的问题。
假如你拥有A类的实体a和老公AManager,A与B类有关系,那么应该直接通过a获取相关的b,即 b = a.B; ,而不再通过AManager获取。因为设计中认为,所有与A相关的实体,即A锁拥有的“关系”,都应该是A的特性/属性,是A的一部分。
后面会讲到Entity的设计模式以达成相关任务。
协作与事务
上面或许已经发现一个矛盾了:EF所有原子化的操作都依赖于单一的DbContext实例,如果我把指责拆分并封闭起来,那么他们就必须各自使用自己的DbContext对象,而无法共同处理事务。
以下解决方案可以简单否决:
- 单例DbContext——无法实现业务隔离
- 所有操作都带一个DbContext参数——写死我也
而我能想到的最优雅的解决方案就是:在需要共同执行事务的时候注入DbContext并,并且用事务进行包裹。
首先,在每个劳工都依赖于一个DbContext的情况下,我写了一个公共接口与基类分别为:
 IEfDbContextDependency EfDbContextDependencyBase
IEfDbContextDependency EfDbContextDependencyBase里面重要的是“Inject”一类的代码,作用也就是将DbContext实例注入到劳工中,使得在相关事务中劳工们使用的是同一个DbContext,为了方便,也附带了泛型和集体注入的实现方式。暂时来说个人觉得这是个很别扭的办法,之前一直在寻求一种自动的依赖注入方式,希望至少能将DbContext注入到一次HttpRequest中,有实现方法的朋友可以@下我,不胜感激。
另一件需要提到的就是事务,是这个事务(Transaction),需要使用Transaction才能把一件原子化的事务包装起来,以保证相关业务操作如设想一样,比如申请单如果提交到一半发生异常,那么应该是都不提交。
加上事务后的用法,应该是:
1 voic DoSomeWork()
2 {
3 this.InjectAllDbContextsTemporarily(() =>
4 {
5 using (scope = new TransactionScope())
6 {
7 this.doMyJob();
8 bManager.DoOtherJobs();
9 scope.Complete();
10 }
11 }, bManager);
12 }
也请注意引用System.Transactions。
本例,如果BManager中也有事务会不会有影响呢?不会,因为事务是可以嵌套的,最后执行时会是最外层的TransactionScope.Complete()方法。
四、设计模式
这是我觉得在使用EF时最有趣的地方,因为你可以在数据模型的基础上根据自己的需要,为其添加跟多的业务特性,而无需影响到数据本身。很多时候,因为这些特性,使得你可以更加倾向于就此解决问题,而不打破范式以求全。总体来说,以下设计模式的目的就是为了保持数据与其结构的纯洁性的情况下满足业务的遍历性。
重命名
如果存在一个属性或引用,它的名称不符合业务描述,那么可以将它重命名。
有两种方式,一种是在设计器里,将其重命名,比如A.User改成A.Friend,以符合业务期望的描述。但有时候,这样是不足以满足需求的,那么就使用扩展方法将其重命名:
public partial A
{
public User Friend { get { return this.B } }
}
跨越
参考上面关系部分的说明,如果R(A, C) = 1,存在A.B和B.C,那么我们可以在不创建的A.C真实数据的情形下,创建A.C作为A.B.C的重命名:
public partial A
{
public C C { get { return this.B.C; } }
}
或许以下命名方式会更清晰,获取用户所有书,假设用户所有书都放在一个书柜上:
public partial User
{
public IEnumerable<Book> MyBooks { get { return this.Bookcase.Books; } }
}
计算
在一些带有业务特性的情况下,可以在重命名的基础上添加相关业务操作:
public partial User
{
public string FullName
{
get
{
return String.Format("{0} {1}", this.FirstName, this.LastName);
}
}
}
不过要注意的是,由于通常使用LinQ操作,所以应尽量使用缓存,比如延迟加载:
public partial User
{
public string FullName
{
get
{
if (_fullName == null)
{
_fullName = String.Format("{0} {1}", this.FirstName, this.LastName);
}
return _fullName;
}
}
string _fullName;
}
当然,同时还可以扩充为筛选计算值:
public partial User
{
public User BestFriend
{
get
{
return this.Friends.Max(friend => friend.Wealth + friend.GookLooking + friend.Height);
}
}
}
在这种情况下就不那么建议使用延迟加载或者缓存了,如果Max是LinQ方法,或者换成是Where、Select之类的LinQ方法,那么留有LinQ自有的延迟加载特性比较好。
合并
在计算的基础上,可以将两个同类序列合并:
public partial BankAccount
{
public IEnumerable<Record> AllRecords
{
get
{
return this.InputRecords.Union(this.OutputRecords);
}
}
}
封闭
如果对于数据,访问行需要进行限制,已保证业务对数据的读写安全,那么就将其封闭。
假如class Account有一字段Password,而该字段需要进行加密方能存储,那么可以将数据的字段Password的访问行设置为私有的,然后重写其读写方法:
//此部分为EF自动生成部分
public Account
{
public string Password { private get; private set; }
}
public partial Account
{
public EncryptedPassword { get { return this.Password; } }
public SetPassword(string originalPassword)
{
this.Password = EncryptHelper.Encrypt(originalPassword);
}
}
分类
在一个“基类——派生类群”的关系集合里,如果数据的入口为基类的集合,而处理中需要分类,则需要通过继承约束,即多态实现确定其具体特性。
当然,你可以使用typeOf,或者OfType<T>()来进行归类,但前者代码不太美观,后者性能较低,每次都要遍历。
这里是其中一种示例,首先存在以下关系,并通过设计器创建了一个Enum(枚举)。其中环境需要在.NET Framework 4.5+和EF 5+,否则枚举也可以直接在项目中添加而不通过EF设计器:

然后,现有基类的扩展:
public partial class BaseType
{
public abstract MyType Type { get; }
}
然后分别扩展派生类:
public partial class AType
{
public override MyType Type { get { return MyType.A; } }
}
public partial class AType
{
public override MyType Type { get { return MyType.A; } }
}
那么,在使用中,即可分类处理:
var entities = new EntityFrameworkDemoContainer();
var allTypes = entities.BaseTypes;
foreach (var type in allTypes)
{
switch (type.Type)
{
case MyType.A:
Console.WriteLine("It's an A.");
break;
case MyType.B:
Console.WriteLine("It's an B.");
break;
}
}
在实际应用中,还可以定义更多的方法、特性,比如序列化。
归类
当两个没有类型相关的实体拥有相同特性的时候,在针对某项共性的处理中,可以将它们归类。
这种方式通常用共有的接口来实现,用接口来描述(非约束)其共有的特性。
比如存在如下关系:
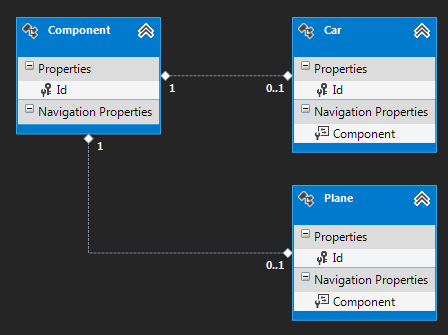
如果我需要遍历所有引用了(依赖于)Component的对象,那么我需要将所有引用者同质化,依次创建以下代码:
public interface IComponentDependency
{
Component Component { get; set; }
}
public partial class Car : IComponentDependency
{
}
public partial class Plane : IComponentDependency
{
}
public partial class EntityFrameworkDemoContainer
{
public IEnumerable<IComponentDependency> AllComponentDependencies
{
get
{
return ((IEnumerable<IComponentDependency>)this.Cars)
.Union(this.Planes);
}
}
}
可以看到,通过创建带有Component的IComponentDependency接口,然后并为Car和Plane添加此接口,变可以将所有Car和Plane归类为ComponentDependencies而不需要通过它们拥有共同的父类实现。而使用方面,则可以:
var entities = new EntityFrameworkDemoContainer();
var allComponentDependencies = entities.AllComponentDependencies;
foreach (var componentDependency in allComponentDependencies)
{
Console.WriteLine("I find a component.");
}
五、业务模式
当所有业务,都是由工作实体(Unit of Work),以上定义的劳工(Worker)进行操作完成的。由于DbContext操作的原子性,不同的Worker间需要共同工作就需要跨越此障碍。
劳工们通常有很多相似的工作内容,所以在接口设计的时候可以提供一些公共接口或者实现:
通过ID获取具体实体的接口:
IId获取所有同类实体:
IAll创建、添加、移除:
ICreate IAdd IRemove在项目中,我并没有提供更新的方法,因为严格地分层来说,上层无法跨越业务沾染数据层面的DbContext对象,自然不存在更改Entity的行为。同时也为了业务安全和规范约束,所有更改操作都应该通过业务层面进行操作。如果只是传参实体,业务层则无法把握UI等上层到底对Entity进行了什么修改,甚至有可能对Entity相关的其他Entity进行跨越业务的修改。在一般情况下,连IAdd也不应该有。
借助
当一个Worker需要另一个Worker的协作,则直接依赖并引用对象Worker,即“借助”该Worker。
假设有一更新申请单的方法,需要当前用户方能进行操作,则涉及了UserManager,ApplicationManager共同工作的内容,实现当如下:
IApplicationManagerpublic class ApplicationManager : EfDbContextDependencyBase
, IApplicationManager
{
IUserManager userManager;
public ApplicationManager(IUserManager userManager
, MyContainer entities)
: base(entities)
{
this.userManager = userManager;
}
public Application this[int id]
{
get
{
return this.entities.Applications.FirstOrDefault(application => application.Id == id);
}
}
public void Edit(int applicationId, string content)
{
//获取相关申请单
var application = this[applicationId];
//获取当前用户
var currentUser = userManager.CurrentUser;
//只有当当前用户为申请人才可以修改
if (application.Applicant.Id == currentUser.Id)
{
//修改申请单
...
this.entities.SaveChanges();
}
}
}
引用
当本劳工需所处理的实体产品需要依赖于其他劳工提供的产品,那么就需要同化二者的DbContext。
比如需要添加申请单,那么就需要将当前用户作为申请单的申请人,引用上面的代码并省略一部分:
public partial ApplicationManager
{
public Application Apply(string content)
{
userManager.InjectDbContextTemporarily(this.entities, () =>
{
//获取当前用户,作为申请人
var currentUser = userManager.CurrentUser;
var newApplication = new Application
{
Application = currentUser,
Content = content
};
this.entities.Applications.Add(newApplication);
this.entities.SaveChanges();
return newApplication;
});
}
}
合作
当一个业务,需要多个Worker合作完成,并且该工序具有原子性,则将它们封装在一个事务里。
这里,先用项目中的一段代码进行示范,注释和代码都是项目中的:
Add这是插入一个新的汇率,比如¥兑换$的汇率,同时也要创建$兑换¥的汇率,由于有计算误差和一些买卖差价,所以两个汇率不一定严格按照反比存在,而是手动设定的值,这是业务部分。而在实现部分,可以知道这样的情况下,一个汇率会关联两个汇率规则(¥<=>$、$<=>¥),那么就形成了“环”,插入的时候无法单步执行,所以需要逐步执行(多次SaveChanges())并通过Scope进行封装。我想,在事务方面没什么疑问。
那么,在上文里,说到过,事务是可以嵌套的,而嵌套以最外层的TransactionScope.Complete()为最终执行点。当你需要多个不同的Work共同进行操作,并且该操作具有原子性的时候,你可以在注入DbContext后用TransactionScope将其包裹:
TransferTo这也是项目中的代码,即从一个账户用某个汇率转账一定金额到另一个账户。
六、项目迭代
每次修改Entity Model后,直接运行生成的SQL,就可以获得新的数据库了,但同时也清空了原来的数据。
所以我需要一个初始化开发测试数据的方式,便在项目中添加了初始化方法,创建了一个简单(lou)的初始化工具,方便初始化一些数据:

有了初始化工具后,项目的迭代方式大致是:修改Entity Model =》 重新生成数据库 =》 修改/不修改初始化工具 =》 初始化数据。哪怕是一个字段的修改,都可以马上更新数据库设计,然后继续下一步开发。
当然,这个流程却不适用在生产机上,这是现在遇到的一个难题。如果发布生产后,数据库中有了真实数据,那么更改就要涉及数据迁移的事了,事情就变得不那么简单。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号