

并发、并行、同步、异步、阻塞、非阻塞
最近在写爬虫 ,对于这几个概念比较模糊,所以特意学习了一下。
进程(process):进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。
线程(thread):线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
一个线程可以创建和撤销另一个线程;同一个进程中的多个线程之间可以并发执行。
微线程:又叫协程。 tasklet运行在伪并发中,使用channel机制进行同步数据交换。python中的greenlet提供了微线程的操作。不同于多线程,它给我们提供了一种更加轻量的异步编程模式。
协程(Coroutine)提供了不同于线程的另一种方式,它首先是串行化的。其次,在串行化的过程中,协程允许用户显式释放控制权,将控制权转移另一个过程。释放控制权之后,原过程的状态得以保留,直到控制权恢复的时候,可以继续执行下去。所以协程的控制权转移也称为“挂起”和“唤醒”。
并发(concurrency):并发是指二个和多个事件在同一时间间隔内发生。并发是在逻辑层面上的同时工作。
并行(parallelism):并行是指二个或多个事件在同一时刻发生。 并行是在物理层面上的同时工作。
同步(synchronous):在发出一个功能调用时,在没有得到结果之前,该调用就不返回。
异步(asynchronous):异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
阻塞:阻塞调用是指调用结果返回之前,当前线程会被挂起。函数只有在得到结果之后才会返回。
非阻塞:非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。
要注意同步和异步 与 阻塞和非阻塞 这两组概念之间的区别。
同步IO和异步IO的区别就在于:数据拷贝的时候进程是否阻塞。
阻塞IO和非阻塞IO的区别就在于:应用程序的调用是否立即返回。
对于上面的两句话,你也许会感到疑问,看了下面的内容你就清楚了。
这两组是可以互相组合的。

同步阻塞,同步非阻塞,异步阻塞,异步非阻塞。详细见最后一个链接。
同步阻塞I/O:在这个模型中,用户空间的应用程序执行一个系统调用,这会导致应用程序阻塞。这意味着应用程序会一直阻塞,直到系统调用完成为止(数据传输完成或发生错误)。调用应用程序处于一种不再消费 CPU 而只是简单等待响应的状态,因此从处理的角度来看,这是非常有效的。

同步非阻塞I/O:同步阻塞 I/O 的一种效率稍低的变种是同步非阻塞 I/O。在这种模型中,设备是以非阻塞的形式打开的。这意味着 I/O 操作不会立即完成,需要应用程序调用许多次来等待操作完成。这可能效率不高,因为在很多情况下,当内核执行这个命令时,应用程序必须要进行忙碌等待,直到数据可用为止,或者试图执行其他工作。

异步阻塞I/O:在这种模型中,配置的是非阻塞 I/O,然后使用阻塞 select 系统调用来确定一个 I/O 描述符何时有操作。使 select 调用非常有趣的是它可以用来为多个描述符提供通知,而不仅仅为一个描述符提供通知。对于每个提示符来说,我们可以请求这个描述符可以写数据、有读数据可用以及是否发生错误的通知。

异步非阻塞I/O:异步非阻塞 I/O 模型是一种处理与 I/O 重叠进行的模型。读请求会立即返回,说明 read 请求已经成功发起了。在后台完成读操作时,应用程序然后会执行其他处理操作。当 read 的响应到达时,就会产生一个信号或执行一个基于线程的回调函数来完成这次 I/O 处理过程。在一个进程中为了执行多个 I/O 请求而对计算操作和 I/O 处理进行重叠处理的能力利用了处理速度与 I/O 速度之间的差异。当一个或多个 I/O 请求挂起时,CPU 可以执行其他任务;或者更为常见的是,在发起其他 I/O 的同时对已经完成的 I/O 进行操作。

想更加详细的了解这方面的内容,建议阅读下面的链接内容。本文过于简陋 ^-^,请谅解。下面的才是精华 :
加州大学伯克利分校的学术报告,关于并发与并行的分析:http://www.eecs.berkeley.edu/Pubs/TechRpts/2008/EECS-2008-151.html
网络程序设计中的并发复杂性:http://d.g.wanfangdata.com.cn/Periodical_rjxb201101010.aspx
同步与异步的概念:http://blog.chinaunix.net/uid-21411227-id-1826898.html
进程和线程的区别:http://www.cnblogs.com/lmule/archive/2010/08/18/1802774.html
http://blog.csdn.net/hguisu/article/details/7453390
https://www.ibm.com/developerworks/cn/linux/l-async/
[ASP.NET]从ASP.NET Postback机制,到POST/GET方法
写这篇博客的起源来自于自己最近在学习ASP.NET时对于 PostBack机制的困惑。因为自己在解决困惑地同时,会不断产生新的疑问,因此博客最后深入到了http 包的格式和Internet所使用的TCP/IP模型,算是来了一堂基础复习课。但我相信这些基础的牢固性,会影响到web方向的深入学习,因此整理成文,便于复习,便于探讨。
写博的时候并没有将http协议包格式等底层的东西调整到最前面写,因为我觉得既然我是这样思考的,何不这样呈现?为了便于描述,我用下图这棵树表示写这篇博文的思路,IsPostBack是表面的引起疑问的叶子,顺着这片叶子,可以逐渐追溯到http协议这个树干。“Post与Get方法”那一块被安排在树干上,是因为从这里开始,触及了Web开发的主体;枝叶上的ASP.NET部分,只是基于这个主体又加入自己的技术的延伸。别的技术比如JSP,Struts等Java方向的技术,也是基于这个主体的另一种技术方向的延伸,因此它们都会像树枝一样,从主干上发散开。
博文中有任何觉得不对的地方,欢迎在留言中和我探讨。毕竟我也只是刚接触Web不久的Fresh Man,行文之时,心下惴惴,因此欢迎指出错误和讨论。

PostBack机制
什么是Postback?IsPostBack的作用是什么?
PostBack机制是ASP.NET特有的机制,为什么说特有,我们从web请求和响应说起。

web的基本原理就是请求和响应。以asp为例,Browser端的HTML文本,以及javascript代码,运行后向server端发送script,server端的.asp脚本,接受request,处理后发出respond。这种server端script和client端script交互,完成一次次对于用户操作(提交表单,载入新的URL)的响应。
以一个html文件和asp文件为例:
html代码:

<!DOCtype html PUBLIC "-//W3C//DTD XhTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head><title>order</title></head> <body> <h2>Form Example</h2> <p> Please input and submit <form method="POST" ACTION="Response.asp"> <p> 姓: <input NAME="fname" SIZE="48"/> <p> 名: <input NAME="lname" SIZE="48"/> <p> 称呼: <input NAME="title" type=RADIO VALUE="先生"/>先生 <input NAME="title" type=RADIO VALUE="女士"/>女士 <p><input type=SUBMIT VALUE="提交"/><input type=RESET VALUE="清除"/> </form> </body> </html>
Response.asp脚本代码(VB语言)
<HTML> <HEAD></HEAD> <BODY> <% Title = Request.Form("title") LastName = Request.Form("lname") If Title = "先生" Then Response.Write LastName & "先生" ElseIf Title = "女士" Then Response.Write LastName & "女士" Else Response.Write Request.Form("fname") & " " & LastName End If %> </BODY> </HTML>
可以看到HTML文件的form控件中,"action"属性指定了form提交后处理它的Server端脚本。
而在ASP.NET系统中,我们没有Client端和Server端脚本,我们只有aspx文件,而aspx也会被Render为HTML,在Client端通过浏览器显示,因为浏览器只能识别HTML标签。
下面的例子引自Artech的浅谈ASP.NET的Postback,这篇文章讲解了Postback的实现方式,简单说来:Render之后的HTML会自动加入一个form,其中用hidden的input来存储id和事件参数。在__Postback这个函数中,form中的内容会被提交。Artech所给的aspx代码在Browser端的呈现出来的源码如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <title> Test Page </title> </head> <body> <form name="form1" method="post" action="Default.aspx" id="form1"> <div> <input type="hidden" name="__EVENTTARGET" id="__EVENTTARGET" value="" /> <input type="hidden" name="__EVENTARGUMENT" id="__EVENTARGUMENT" value="" /> <input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="/wEPDwUKMTA0NDQ2OTE5OWRk281L4eAk7iZT10hzg+BeOyoUWBQ=" /> </div> <script type="text/javascript"> <!-- var theForm = document.forms['form1']; if (!theForm) { theForm = document.form1; } function __doPostBack(eventTarget, eventArgument) { if (!theForm.onsubmit || (theForm.onsubmit() != false)) { theForm.__EVENTTARGET.value = eventTarget; theForm.__EVENTARGUMENT.value = eventArgument; theForm.submit(); } } </script> <div> <span id="LabelMessage" style="color:Red;"></span> </div> <div> <input type="submit" name="Button1" value="Button1" id="Button1" /> <input type="button" name="Button2" value="Button2" onclick="javascript:__doPostBack('Button2','')" id="Button2" /> <input type="button" name="Button3" value="Button3" onclick="javascript:__doPostBack('Button3','')" id="Button3" /> </div> </form> </body> </html>
以上代码在Artech博文中也可以找到,我把它贴过来,以方便引述。这段代码是Default.aspx被render到browser端的html源码,Postback的实现机制就是定义了一个form,这个Form中包含隐藏的input,从而保存需要post的值,那么,向哪里post?Form中"action"属性指定了post的目标,那这里呢?我们可以看到其值为"Default.aspx",也就是它自己。这和上面那个ASP的例子中是不同的。
我的理解是:所谓Postback,是指在ASP.NET机制中,不是Client端发post请求到server端脚本,在这个机制中,aspx被render到browser后,其Form的post目标依然是这个aspx。Postback由此得名,因为post回来了。。
因此当我们触发网页的按钮时,若此按钮涉及到后台操作(在后端有C#响应代码,而非仅仅调用前端javascript函数),aspx页面便会重新加载,因为Postback触发了它。(这句话待商榷,我对Postback与page life cycle了解再深刻些后,会再编辑这句话)。
这个机制所需要解决的第一个问题是:当开发人员编写代码时,aspx的加载有两种原因:点击按钮触发post来让aspx加载;用户输入url来加载aspx。对于不同的原因,可能开发人员希望代码进入不同的处理逻辑。IsPostback这个ASP.NET所给的变量,就是用来给developer确定是否这个网页是因为postback而加载,而是通过输入url或者刷新页面的方式来加载。
最简单的例子,在Page_Load()方法里经常会 if(!IsPostBack) BindForm();//给表单所有控件赋值的方法。意思是提交后我就不绑定表单了,而是走Click的具体事件方法。
而IsPostBack是何时被赋值的,ASP.NET代码中是根据什么条件来判断是否是postback的网页,这一个树枝暂时还没有研究下去,如果能有前辈能在留言中给我一些线索的话,感激不尽 :)
有关于Page_Load()方法,它是ASP.NET中的网页载入过程中page load事件的默认响应函数,具体请参见:
ASP.NET 页生命周期概述 以及 [ASP.NET]Page Life Cycle整理
因此Postback的机制本质实现其实是form的post,那么post和get,这些具体是什么?
POST与GET方法
正如之前所说,web实际就是request与respond的交互,那么,这些request与respond,其实就是http包。
对于一个Request,它可能不仅仅是一个要求载入页面的request,也可能是要求发送一些数据的request,或者要求删除服务端一些数据的request,如何区分这些request?http给request定义了四个谓词:POST,GET,PUT,DELETE。从名字就可以看出来他们的功用,分别对应着改,查,增,删。
而最常使用的是GET与POST。
他们的共同点和区别在哪里?
共同点是:GET POST其实都可以实现向服务器传送数据。在HTML中,本身表单form的提交就有两种方式,一种是get的方法,一种是post 的方法。而这两种方法保存参数的方式是不同的,如果使用Fiddler或其他的http包查看工具,可以发现post方法提交的Form,其参数存在body中,而get方法提交的form,其参数则直接加入到url的后面。
通过包来看两者之间本质的差别的例子,可以参见淺談 HTTP Method:表單中的 GET 與 POST 有什麼差別?
通过输入url来访问页面,其request都是get。
两者特性上的差别:form方式因为是将内容放在body中发过去,而get仅仅是发一个get请求过去,内容在url中,因此速度比post快,而安全性则低于post。
GET的response会被cache,而POST的response不会。因为GET的初衷就是获取内容,因此可以通过cache来存储不变的内容,而POST则是用来提交内容,其响应基于所提交的内容可能不断变化。
两者之间其他差别参见下图,图来自[HTTP]Http GET、POST Method

有一篇文章提到了在使用Ajax时,POST会比GET慢数倍,各位有兴趣可以看一下:打破沙鍋-AJAX POST比GET效率差?
之前提到既然request和response实际就是HTTP包,那POST与GET这些谓词又是如何在包中呈现的?
POST与GET报文格式
以Artech的那个例子为例,那个例子如果运行起来,会看到三个按钮,点击其中一个,会显示哪个按钮的click被fire了:

点击Button3后,request与response在fiddler中的内容如图:

在fiddle中,可以看到POST就出现在Request的第一行中。
Response的Header的内容是:HTTP/1.1 200 OK
一个http请求报文的格式如下图 (图片来自计算机网络应用层之HTTP协议)

分为请求行(Request line),首部行(Header line),空行(Brank line)和实体(body),谓词方法的位置就在请求行的开头。
HTTP响应respond的报文格式如下:

其中200为状态码,表示请求成功。返回内容在实体中呈现,比如之前fiddler的截图,响应包中的内容就是原先那个HTML的内容,也就是说,浏览器收到这个response后,用户会看到整个页面被刷新了一下。
我们知道了http的报文格式,那什么是HTTP协议?
HTTP协议
HTTP是HyperText Transfer Protocol即超文本传输协议的缩写,是Web应用层协议之一。
在说这个之前,先提几个HTTP的特性,这部分引用了Tank的 HTTP协议详解 中部分内容
HTTP协议是无状态的:同一个客户端的这次请求和上次请求是没有对应关系,对http服务器来说,它并不知道这两个请求来自同一个客户端。 为了解决这个问题, Web程序引入了Cookie机制来维护状态。引入了ViewState来存储控件内容或者用户自定义信息。
关于Cookie的介绍,读写方式,以及它在ASP.NET form authentication中所起的作用,参见:Fish Li的细说Cookie。
关于ViewState:我的理解是一种在用户端存储控件内容和一些开发人员自定义内容的机制。其实现方式是在用户端的HTML代码中插入名字为"__ViewState"的hidden input,那些需要存储的内容,都经过Base64编码后以字符串的形式存储在这个hidden input中。因为是以字符串的形式存储在客户端的HTML文件中,因此属于长期储存,不会自动过期或消失,用户甚至可以拷贝下来保存。更多内容,参见 [.NET] ASP.NET 狀態管理(State Management):ViewState。
打开一个网页需要浏览器发送很多次Request:
1. 当你在浏览器输入URL http://www.cnblogs.com 的时候,浏览器发送一个Request去获取 http://www.cnblogs.com 的html. 服务器把Response发送回给浏览器.
2. 浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如图片,CSS文件,JS文件。
3. 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
4. 等所有的文件都下载成功后。 网页就被显示出来了。
由于HTTP是使用TCP作为其运输协议的,因此http协议也需要连接,也需要三次握手的过程。
TCP连接分为持久连接和非持久连接:
在非持久连接的情况下,服务器在发送响应后,关闭TCP连接。我们定义往返时间RTT为一个小分组从客户机到服务器再回到客户所花费的时间。所以RTT包括分组传播时延、排列时延以及分组处理时延。
若http采用非持久连接时,我们可以估算出完成一次传输所消耗的时间:完成了三次握手的前两部分后,客户机将三次握手的第三部分(确认)与一个HTTP请求报文结合起来发送到该TCP连接。一旦请求报文到达服务器,服务器向该TCP连接发送HTML文件。从上面的描述,我们可以知道,对于一个非持久连接,请求一个HTTP请求/响应需要的总时间为两个RTT+服务器传输HTML文件的时间,也就是两个来回所耗的时间加上传输时间。
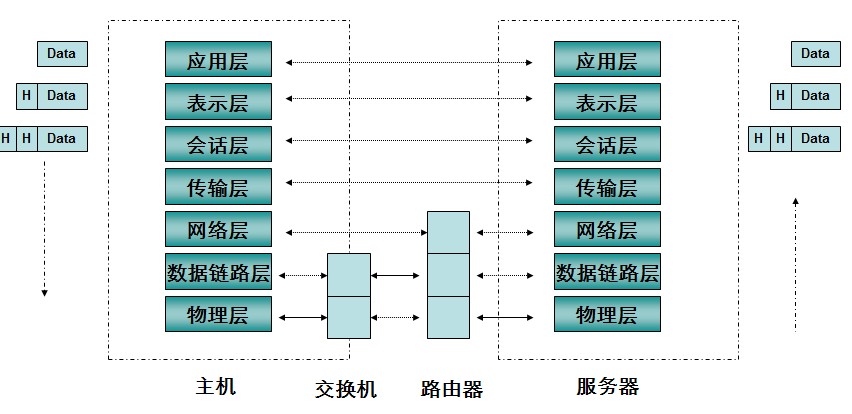
网络分层结构
我们知道互联网的框架主要是两种:OSI的七层框架,和TCP/IP体系结构。而Internet网络体系结构以TCP/IP为核心。基于TCP/IP的参考模型将协议分成四个层次。
这两种模型的对应关系如图,图片来自网络互联参考模型(详解)

而我们之前应用层的http报文,从最高层往下经历层层封装,最后到达最底层转换为01流。发往目的地,中间会经过交换机和路由器的中转,解包,确认下一个转发地址后再次封包转发。如下图 (图片来自网络互联参考模型(详解))
------------------------------------------------
Felix原创,转载请注明出处,感谢博客园!
Highcharts结合PhantomJS在服务端生成高质量的图表图片
项目背景
最近忙着给部门开发一套交互式的报表系统,来替换原有的静态报表系统。
老系统是基于dotnetCHARTING开发的,dotnetCHARTING的优势是图表类型丰富,接口调用简单,使用时只需绑定数据源即可(指定连接字符和sql语句,简单的配置一下就能出图),支持生成静态图表图片;缺点就是生成好的图是图片,传到了前台就失去了交互性(当然它还提供了一个jsCharting,不过感觉交互性做的还是不够好),再有就是这东东是收费的呀,用的话需要折腾破解版本。
我最终选择了Highcharts(Interactive JavaScript charts for your webpage)来展现前台图表,通过Highcharts良好的交互性实现与服务端的数据交互,将数据可视化。
dotnetCHARTING在数据加载的设计上做的还是很不错的,我在开发过程中借鉴了其处理思想,自己实现了一套数据加载方案,能够很方便的把数据传给Highcharts。这套数据加载方案,简单的说就是指定好数据库连接信息和sql查询信息,服务端采用ADO.NET执行查询生成DataSet,然后分析DataSet将数据转换为Highcharts能够直接使用的json格式。
报表的处理细节还是蛮多的,这里就不在一一讨论了,如题,接下来重点跟大家分享一下,服务端生成图表图片那部分的处理细节。
Highcharts服务端生成图表图片流程简介
生成图片的数据流向倒是比较简单,如下图所示:

ASP.NET在服务端生成图表图片的方式
根据上述生成图片的步骤,核心其实就是对第二步的处理,也就是如何将SVG数据在服务端做处理,生成图表图片。
这样的话,我们的处理思路就很清晰了,直接在服务端把SVG处理为图片不就可以了,这么想,也就这么做,刚好网上也有人这么弄过,于是也就直接借鉴了其代码,代码不上了,介绍下用到的dll:

在nuget中搜索svg,可以找到一个SVG Rendering Library的包,可以用这个包将SVG格式的数据保存为图片,用法也比较简单,大家可以到其官网查阅使用方法。
这个大家不必自己去实现,因为highcharts官网已经给出了第三方的ASP.NET导出图表的模块(他就是基于这个SVG Rendering Library实现的):
https://github.com/imclem/Highcharts-export-module-asp.net
SVG Rendering Library的问题
在使用SVG Rendering Library服务端生成图表图片的过程中,发现一些问题:
- 生成的图片中文字体模糊发虚,整体图片质量差,跟实际在网页中显示的效果差别还真不小
- 图表上数据点的dataLabel无法显示(一开始以为是highcharts配置的问题,后来鉴定是SVG Rendering Library的问题,这个必须修改svg.dll才能解决)
先看一下图片质量的问题,首先是Chrome中实际展现的图表的截图:

在来一张使用svg.dll在后台生成的图:

对比着两张图,可以和明显的看出生成的图片中汉字发虚(尤其是下面的月份)。正是这个原因,促使我去寻找一个更好的方案来替代SVG Rendering Library,以确保服务端生成图表图片的质量。
心想highcharts在浏览器中的显示效果已经不错了,要不做截图,但是截图的话跟服务端也没关系了呀,突然想到了在服务端渲染截图这么个思路。但是具体怎么做呢?先找找资料吧。
神器PhantomJS华丽登场
第一次接触Phantomjs是半年前左右,当时正在开发web漏洞检测工具,需要执行页面上的js,进行分析,没有经验的我,各处找资料,看到PhantomJS后,心想,这货不是已经有人做过了么,干嘛还重复造车轮子,后来随着业务变更,也没有深入研究它。
这次搜索“服务端,截图”这个关键字的时候,再次看到了PhantomJS,对它的印象不深了,先去官网看看介绍吧,PhantomJS: Headless WebKit with JavaScript API,哦,原来是个可以执行js并集成了webkit的动动,只是没有可视化的部分而已。
PhantomJS能干啥呢?
- HEADLESS WEBSITE TESTING(非可视化的Web测试)
- SCREEN CAPTURE,Programmatically capture web contents, including SVG and Canvas.(截屏啊,支持SVG啊,吼吼,这不正是我想要的么)
- PAGE AUTOMATION(页面自动化,可以使用jQuery操作DOM)
- NETWORK MONITORING(监视页面加载,还可以结合Jenkins做自动化分析,流弊啊!)
对Phantomjs做过一番了解后,就确定用它来处理服务端生成图表图片的问题了。我设计的处理流程如下:

画的很挫,能看明白处理过程就好,接下来分享一下具体处理过程中需要解决的问题。
新方案的处理细节
Highcharts中导出图表的配置
图表的其他配置不需要修改,只需修改导出图片的配置即可,导出的配置如下:
var chart = new Highcharts.Chart({ //... exporting: { url: '/Chart/Export', // 导出图表的服务端处理地址 filename: 'chart_from_phantomjs' // 返回下载的文件名 }, //... });
我们使用Chrome调试一下,看看下载图片的时候,Highcharts都向服务端提交了哪些信息,截图如下:

Highcharts向/Chart/Export发送了一个Post请求,提交的信息如上图所示,在服务端,我们需要根据type来生成不同的图片格式,可以通过svg获取Highcharts提交的图表数据。
ASP.NET中SVG的处理
首先直接将Highcharts传递的SVG数据保存为本地文件,PhantomJS需要通过http://xxx/xxx.svg的形式请求SVG图像,直接请求ASP.NET会以将svg数据以文件的形式返回,因此需要对svg的请求做单独处理。代码如下:
/// <summary> /// 处理Svg文件请求,避免直接返回文件 /// </summary> public class SvgHandler : IHttpHandler { public void ProcessRequest(HttpContext context) { var file = context.Server.MapPath(context.Request.Url.AbsolutePath); if (File.Exists(file)) { context.Response.ContentType = "image/svg+xml"; context.Response.WriteFile(file); } else { context.Response.Write("请求的文件不存在"); } } public bool IsReusable { get { return true; } } }
最后在Web.config中配置一下:
<httpHandlers> <add verb="*" path="*.svg" type="Highcharts.Exporting.Helper.SvgHandler, Highcharts.Exporting, Version=1.0.0.0, Culture=neutral"/> </httpHandlers>
ASP.NET与PhantomJS的交互处理
由于PhantomJS是个独立的进程,这样ASP.NET在与之交互的时候需要让PhantomJS一直运行,不然每次启动一个新的进程开销也比较大。
PhantomJS支持js脚本调用,我们可以通过编写脚本实现PhantomJS以服务的方式长期运行,代码篇幅较长,下面会给出源码。
PhantomJS中通过接收post请求,从请求信息中获取url信息,url就是要渲染的SVG地址,将对应SVG渲染截图,并返回BASE64编码的数据处理,代码如下:
page.open(req.post.url,function(status){ if(status !== "success"){ res.send(status); } else { setTimeout(function() { // 发送渲染后的图片 var pic = page.renderBase64('png'); res.send(pic); }, req.post.timeout || 1000); } });
PhantomJS截图服务脚本:点此下载。启动方法:PhantomJS server.js [port]如不指定端口号,则默认使用8000端口:

ASP.NET对PhantomJS返回的图像数据做处理
ASP.NET需要将PhantomJS返回的BASE64数据反编码,得到PNG图像数据,然后结合需要返回的图片类型做格式转换,并以文件的形式返回给客户端浏览器,核心代码如下:
// 提交SvgUrl到PhantomJS,让其生成图片 WebClient webClient = new WebClient(); NameValueCollection postValues = new NameValueCollection(); postValues.Add("url", siteUrl + svgFile); byte[] data = webClient.UploadValues(phantomJSUrl, postValues); // 从返回的Base64编码中获取图片数据 string imageInfo = Encoding.UTF8.GetString(data); if (!String.IsNullOrEmpty(imageInfo)) { data = Convert.FromBase64String(imageInfo); MemoryStream ms = new MemoryStream(); ms.Write(data, 0, data.Length); image = Image.FromStream(ms); ms.Close(); }
返回Highcharts请求的图片信息:
MemoryStream tStream = new MemoryStream(); var image = ImageHelper.SvgImageFromPhantomJs(tSvg); string tExt = "png"; string tTypeString = "-m image/png"; switch (tType) { case "image/png": tTypeString = "-m image/png"; tExt = "png"; break; case "image/jpeg": tTypeString = "-m image/jpeg"; tExt = "jpg"; break; case "application/pdf": tTypeString = "-m application/pdf"; tExt = "pdf"; break; case "image/svg+xml": tTypeString = "-m image/svg+xml"; tExt = "svg"; break; } if (tTypeString != "") {switch (tExt) { case "jpg": image.Save(tStream, ImageFormat.Jpeg); break; case "png": image.Save(tStream, ImageFormat.Png); break; case "pdf": PdfWriter tWriter = null; Document tDocumentPdf = null; try { image.Save(tStream, ImageFormat.Png); tDocumentPdf = new Document(new Rectangle(image.Width, image.Height)); tDocumentPdf.SetMargins(0.0f, 0.0f, 0.0f, 0.0f); iTextSharp.text.Image tGraph = iTextSharp.text.Image.GetInstance(tStream.ToArray()); tGraph.ScaleToFit(image.Width, image.Height); tStream = new MemoryStream(); tWriter = PdfWriter.GetInstance(tDocumentPdf, tStream); tDocumentPdf.Open(); tDocumentPdf.NewPage(); tDocumentPdf.Add(tGraph); tDocumentPdf.CloseDocument(); } catch (Exception ex) { throw ex; } finally { tDocumentPdf.Close(); tDocumentPdf.Dispose(); tWriter.Close(); tWriter.Dispose(); } break; case "svg": MemoryStream tData = new MemoryStream(Encoding.UTF8.GetBytes(tSvg)); tStream = tData; break; } } return tStream;
最后将tStream的图像数据以文件的形式返回给前台:
[HttpPost] [ValidateInput(false)] public ActionResult Export() { string siteUrl = String.Format("{0}://{1}:{2}/", Request.Url.Scheme, Request.Url.Host, Request.Url.Port); MemoryStream tStream = new MemoryStream(); string tType = Request.Form["type"]; string tSvg = Request.Form["svg"]; string tFileName = Request.Form["filename"]; if (String.IsNullOrEmpty(tFileName)) { tFileName = "chart"; } ChartHelper chartHelper = new ChartHelper(); tStream = chartHelper.GetSvgImageFromPhantomJs(siteUrl, tType, tSvg); return File(tStream.ToArray(), tType, tFileName); }
借助PhantomJS生成的图表图片
来一张效果图,跟原来的对比一下:

可见汉字部分清晰了不少吧。
总结
在服务端使用PhantomJS生成图表图片好处就是能将图像渲染到最佳效果(直接使用WebKit内核渲染),缺点就是速度慢了些。
服务端生成Pdf图表可以使用iTextSharp生成。
附ASP.NET导出Highcharts的源码:点此下载
