

内存管理
本系列博文是《现代操作系统(英文第三版)》(Modern Operating Systems,简称MOS)的阅读笔记,定位是正文精要部分的摘录理解和课后习题精解,因此不会事无巨细的全面摘抄,仅仅根据个人情况进行记录和推荐。由于是英文版,部分内容会使用英文原文。
课后习题的选择标准:尽量避免单纯的概念考察(如:What is spooling?)或者简单的数值计算,而是能够引起思考加深理解的题目。为了保证解答的正确性,每道题都会附上原书解答,而中文部分会适当加入自己的见解。原书答案下载地址(需注册)
注:本文部分内容需要读者对页式、段式、段页式内存管理有基本了解。
概念回顾
交换技术(Swapping):内存紧缩、用于内存管理的位图和链表、匹配算法:首次匹配、下次匹配、最佳匹配、最坏匹配;
虚拟内存:前身是手工完成的覆盖技术(overlays);内存管理单元MMU及地址转换:页表、TLB(转换检测缓冲区,也称为关联存储器,俗称快表)、多级页表;
页面调度算法
共享库(shared libraries)/动态链接库(DLL,Dynamic Link Libraries)
段式内存管理、段页式
1.TLB的译名
如果之前学习过国内的操作系统教材,TLB一般被称为快表,而不是转换检测缓冲区(Translation Lookaside Buffer)或关联存储器(associative memory)。对于国内常见的称呼,容易知道它是做为整个页表的一个部分缓存,从而加快虚地址向实地址转换的速度。因此,它和页表的条目结构很类似。具体解释见于P195~197,另外段式存储管理中也可以使用TLB加速访问。对于不同地方出现的TLB,它缓冲的内容与其应用场景有关(MULTICS、Pentium等等)。可以看出,这个译名比较形象,不过原名更具体些。
2.倒排页表(Inverted Page Tables)
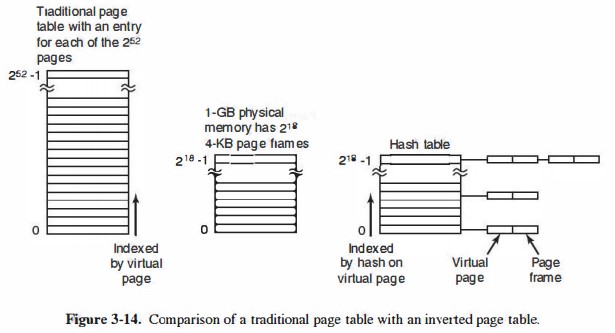
本科时学习“操作系统”的"基本分页存储管理方式"时,对于64位计算机、单个页面4KB(即212B),两级页表已经过大而不能装入内存。汤子瀛版《计算机操作系统》介绍了2种处理方式:使用三级或以上的页表、将寻址空间降低到45位左右而不是64位。前者仍然比较繁琐,后者可行性比较高。那时我就对前者心存疑惑:虽然能够将需要用的页表调入内存,可是它们总大小仍然很大,有没有更好的实现?接下来看一看《现代操作系统》提供的方式:倒排页表。下面这部分内容取自原书P200~201的整理。
先简述下问题所在:64位计算机中,如果页面大小为4KB,那么64位寻址空间需要252个页表项。假设每个页表项大小为8B,那么需要30PB的空间,在目前计算机发展阶段显然是不现实的。
倒排页表是一种解决方案,正如其名所揭示的:普通的页表是将虚地址映射成物理地址,提供的是将页号(page number)转化为页框号(page frame number)的对应;这个转化由MMU完成;而倒排页表正相反,提供的是将页框号转化为页号的对应。页框号是实际内存的大小/页面大小,因此1GB内存只需要262,144个项即可,远远小于252这个数字。
个人认为,这个解决思路的妙处在于:32位下,页表项总和比较少,至多两级页表也已够用;而64位下,内存的大小(也即物理地址空间)与寻址空间(虚地址空间)相比反而显得小了,这样干脆来个倒转,不失为一个很好的方法。
当然这种解法虽然节约了大量的存储空间,但是内存管理中需要的是将虚地址转化成物理地址的机制,而不是正相反啊?这种映射是单向的,总不能每次转化都把这个表遍历一次吧?那样做的开销实在是太大了。
一种解决方法是使用TLB,但是TLB也有失效(miss)的时候,这时还是需要进行查找。一个可行的方法是将所有用到的虚地址hash掉,形成一个hash表来加速查找,同样哈希值的虚地址形成一个链。如果hash表的槽数与物理内存的页框数一样多,那么哈希表各表项平均长度为1,这样提高了查找速度。这个解决方法的演变可以见下图3-14。
3.LRU和NFU的算法实现
(1)LRU算法实现
LRU,汤子瀛《计算机操作系统》译为“最近最久未使用”,也即在缓冲的所有页面中,缺页中断发生时,将最久未被使用的页面置换出去。不过按照字面意思,Least Recently Used似乎应是《现代操作系统》中译版的“最近最少使用”,似乎是需要统计页面使用频率的。这里有必要先探讨下这个翻译问题。这个翻译的区别在于,副词least修饰的是recently还是used。P206原文:
A good approximation to the optimal algorithm is based on the observation that pages that have been heavily used in the last few instructions will probably be heavily used again in the next few. Conversely, pages that have not been used for ages will probably remain unused for a long time. This idea suggests a realizable algorithm: when a page fault occurs, throw out the page that has been unused for the longest time. This strategy is called LRU (Least Recently Used) paging.
这前半段和后半段意思并不是很一致。按照前半段的意思,用的最多的(heavily used)最应该保留;而后半段,也即LRU的定义,反而是指“最久未使用”。假设这样一种情况,内存只能容纳两个页,如果考察的时间跨度大于2,对于0,0,...,0,1的页面访问序列,此时访问页面2,前半段会认为0的使用频率最高,应该保留0,而后半段认为0是最久未被使用的,应该保留1。这样就产生了矛盾。不过既然是一个近似,按后半段更合适一些,这样反而显得“最近最久未使用”是一个更合适的译法。《现代操作系统》提到的3种算法,其实都是符合定义的:
一种实现是用一个特殊链表,将最近最多使用的放在表头,最近最少使用的放在表尾,每次使用到的页面如果在链表中,就把它取出并放到表头。不过这个实现一方面很耗时,并且实际上是“最近最久未使用”。
一种硬件实现是使用一个计数器,每次执行指令自增1,每个页表项中提供一位来容纳这个值,每次访问时就把计数器的值存到访问的页表项中。淘汰页面时选择最小的即可。虽然很符合“最近最少使用”的含义,缺点是消耗了很多存储空间;另外,计数器的溢出也是个问题。同样是“最近最久未使用”。
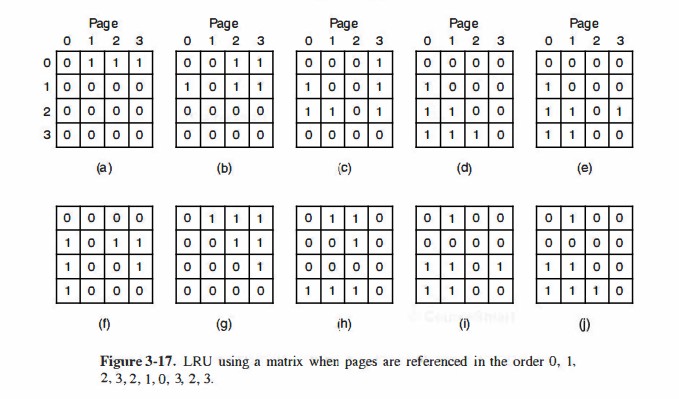
另一种硬件实现则比较精巧。对于n个页框的机器,提供一个n*n的矩阵,初始化为全0。当访问页框k时,将这个矩阵第k行全设为1,第k列全设为0,此时(k,k)是0。在任意时刻,哪一行的二进制数最小,那么它就是将被淘汰的页面。可以发现,这种做法中,最后被访问的页面会把它所在的行变为最大的(k列全为0,代表此列的大小影响不计;仅有k行全1,必然最大)。同时,页面的使用频率越高,那么它就能“保持”的较大。即使上文中探讨的作为0,0,...0,1这种序列,仍然是保持1替换0,还是“最近最久未使用”。原书对这个实现的图3-17:
(2)NFU算法实现(原书P206~207)
LRU的实现比较复杂,而且可能需要借助特殊的硬件。一种软件实现被称为NFU(Not Frequently Used,最不常用),每个页面使用一个计数器,每次时钟中断时,将页面的R位(是否被引用,0或1)加到计数器上。缺页中断时置换计数器值最小的。
这种实现的坏处是它“从不忘记任何事情”,简单地说就是在之前计数器值比较高的页面,即使不再访问,仍然会保持这个值;而别的页面在后续始终无法超过。对NFU做一个小修改,就可以很好的模拟LRU:将R位增加前先计数器右移、R位增加到计数器左边的最高位而不是右边的最低位。修改后的算法称为老化(aging)算法。图3-18是一个运行实例,其蕴含的特征是:越高位越新,最近的使用权重最大;早期的使用记录会随着右移而舍弃。
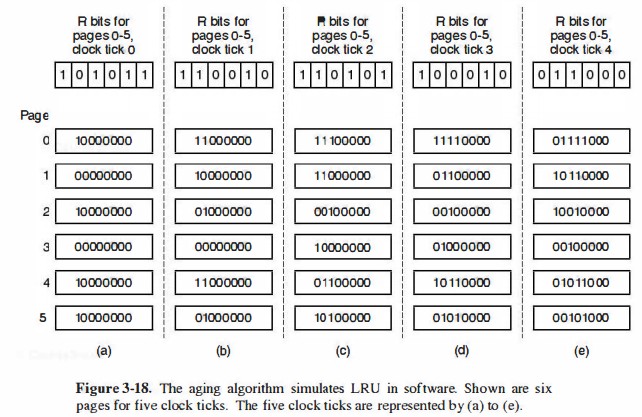
从中也可看出NFU与LRU的第一个区别:对于(e),LRU只能从3和5中二选一,3和5都在2个时钟前访问过,而NFU会明确地唤出3。另一个区别是NFU只能追踪有限次(相较于LRU的前两种实现,要少一些),比如图中的8次。前第9次和前1000次的访问情况是无关紧要的。
4.页的大小
如何确定页的大小?以前我只知道应该综合考虑,但是如何考虑?原书P219~220是一个很好的借鉴。
假设页面大小为p字节,内存中共有n个段。
首先考虑页内碎片。平均来看页内碎片占了页的1/2大小,那么一共浪费了np/2的空间。
页面越小,进程运行时所需内存越小,只需把足够的页面装载如内存即可;反之则越大。然而,页面越小,需要的页表项越多,页表也越大。在页传输这个数量级时,磁盘传输的时间主要花在寻道和旋转延迟上,页面大小不是关键因素,比如,装入64个512B页面需要64*10ms,而4个8KB可能只需要4*12ms。
进程切换时,也表也需要重新装载,页面越小,装入页表越耗时。
最后一点可以用数学分析。如果进程大小平均s字节,页面大小p字节,每个页表项需要e字节,那么进程需要的页数为s/p,占用了se/p的页表空间, 页内碎片在最后一页浪费的是p/2,那么由于页表和页内碎片一共的全部开销为:
利用求导的方法,可以解出最小化开销overhead的p值:
对于s = 1MB和页表项为8B,最优页面大小是4KB。
5.有页式、段式、段页式,为什么没有页段式?
这是我本科时学习操作系统的又一个疑惑。其实从技术角度来说,是可以实现的;读完《现代操作系统》有了新的体会:页式更接近于硬件底层,对于程序员是透明的,你很少感受到它的存在;而段这个概念就比较熟悉了,数据段、代码段、段保护机制这些经常被提起。段是逻辑抽象,更贴近人的思考方式而不是计算机的运作方式。页式、段式、段页式都是在现实中常用的,而且《现代操作系统》的作者Andrew提到:Pentium的设计者面对相互冲突的目标:纯页式、纯段式、段页式管理,高效而简洁的实现,相当值得称赞("
All in all, one has to give credit to the Pentium designers. Given the conflicting goals of implementing pure paging, pure segmentation, and paged segments,
while at the same time being compatible with the 286, and doing all of this efficiently, the resulting design is surprisingly simple and clean",如何使用段页式管理系统提供纯段式和纯页式请参考原书3.7.3节)
可以看出,对于软件设计,应该让逻辑层在较高的位置,贴近硬件的机制在较低的位置——这就是段页式的处理;而不是相反,也就没有了使用所谓的页段式的必要了。
课后习题选
16.The TLB on the VAX does not contain an R bit. Why?
译:
为什么VAX上的TLB没有R位?
Answer:
The R bit is never needed in the TLB. The mere presence of a page there means the page has been referenced; otherwise it would not be there. Thus the bit is completely redundant. When the entryis written back to memory, how-ever, the R bit in the memory page table is set.
分析:
题目提到VAX这个机型其实是误导。一般页表中都有R位(Referrence,最近是否访问过)和M位(Modified,最近是否修改过),这两位在一些调度算法中要用到;而TLB中必然保存的是最近引用过的页,任何机型的TLB都没有R位的必要。
21.Suppose that the virtual page reference stream contains repetitions of long sequences of page references followed occasionally by a random page reference. For example, the sequence: 0, 1, ... , 511,431, 0, 1, ... , 511, 332, 0, 1, ... consists of repetitions of the sequence 0, 1, ... , 511 followed by a random reference to pages 431 and 332.
(a) Why won't the standard replacement algorithms (LRU, FIFO, Clock) be effective in handling this workload for a page allocation that is less than the sequence length?
(b) If this program were allocated 500 page frames, describe a page replacement approach that would perform much better than the LRU, FIFO, or Clock algorithms.
译:
对于一个页面访问序列,会有一个长的重复序列0,1,...,511,末尾一个随机数字,因此这个序列形如0, 1, ... , 511,431, 0, 1, ... , 511, 332, 0, 1, ... 。问题(a)为什么在负载小于重复序列的时候,标准的页面置换算法(LRU、FIFO、Clock)对于这种序列非常低效?(b)如果这个程序只有500个页框,请描述一种好的页面置换算法。
Answer:
(a) Every reference will page fault unless the number of page frames is 512,the length of the entire sequence.
(b) If there are 500 frames, map pages 0–498 to fixed frames and vary only one frame.
分析:
(a)就不再赘述了,对于(b),其实是完全与提到的标准算法不一样的,更接近于最优算法的实现,也即在能够预计未来的情况下进行页面管理。
35.A machine language instruction to load a 32-bit word into a register contains the 32-bit address of the word to be loaded. What is the maximum number of page faults this instruction can cause?
译:
一条机器指令,其功能是把一个32位字的数据装入寄存器,指令本身包含了要装入的字所在的32位地址。这个过程最多会引起几次缺页中断?
分析:
原文稍有点拗口,需要仔细分析。首先装载指令时,如果它是跨页的,会引起两次缺页中断;其次,如果数据所在地址也跨页了,又将引起两次。如果数据必须对齐,那么后者只有一次中断;但是32位的指令未必要对齐,包括Pentium上也是这样。
勘误
1.P250习题19,"a 256-KB main memory"应为256-MB,这个推论根据原书答案的计算过程而来。
作者:五岳
出处:http://www.cnblogs.com/wuyuegb2312
对于标题未标注为“转载”的文章均为原创,其版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号