

自话粒子群算法(超简单实例)
简介
上次在自话遗传算法中提到后期会写两篇关于粒子群算法和蚁群算法的博文,所以这次给大家带来的是我对粒子群的一些理解,并附带一个相当简单的实例去描述这个算法,我会尽力通俗易懂的把整个算法描述一遍,其实粒子群算法的思想也挺简单的,希望我不要反而写复杂了,下面同样引用百度百科的摘要结束简介部分。
粒子群优化算法(PSO)是一种进化计算技术(evolutionary computation),1995 年由Eberhart 博士和kennedy 博士提出,源于对鸟群捕食的行为研究 。该算法最初是受到飞鸟集群活动的规律性启发,进而利用群体智能建立的一个简化模型。粒子群算法在对动物集群活动行为观察基础上,利用群体中的个体对信息的共享使整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得最优解。
基本思想
正如简介所描述的那样,粒子群算法是模拟群体智能所建立起来的一种优化算法,像后面我向大家介绍的蚁群算法也属于这类算法,粒子群算法可以用鸟类在一个空间内随机觅食为例,所有的鸟都不知道食物具体在哪里,但是他们知道大概距离多远,最简单有效的方法就是搜寻目前离食物最近的鸟的周围区域。
所以,粒子群算法就是把鸟看成一个个粒子,并且他们拥有位置和速度这两个属性,然后根据自身已经找到的离食物最近的解和参考整个共享于整个集群中找到的最近的解去改变自己的飞行方向,最后我们会发现,整个集群大致向同一个地方聚集。而这个地方是离食物最近的区域,条件好的话就会找到食物。这就是粒子群算法,很好理解。
算法描述
所以,我们需要一个pbest来记录个体搜索到的最优解,用gbest来记录整个群体在一次迭代中搜索到的最优解。速度和粒子位置的更新公式如下:
v[i] = w * v[i] + c1 * rand() * (pbest[i] - present[i]) + c2 * rand() * (gbest - present[i])
present[i] = present[i] + v[i]
其中v[i]代表第i个粒子的速度,w代表惯性权值,c1和c2表示学习参数,rand()表示在0-1之间的随机数,pbest[i]代表第i个粒子搜索到的最优值,gbest代表整个集群搜索到的最优值,present[i]代表第i个粒子的当前位置。
我这里打了一个求解y=-x*(x-1) 在[-2,2]上最大值的粒子群算法,选用这个简单的例子主要是能让大家清楚的看到效果和粒子的运动方向,也方便理解我想说的一些观点。代码如下:
 View Code
View Code
/***
* 计算y=-x(x-1)的最大值
* 取值范围x--[-2,2]
* @author BreezeDust
*
*/
public class PSOTest {
int n=2; //粒子个数,这里为了方便演示,我们只取两个,观察其运动方向
double[] y;
double[] x;
double[] v;
double c1=2;
double c2=2;
double pbest[];
double gbest;
double vmax=0.1;
public void fitnessFunction(){//适应函数
for(int i=0;i<n;i++){
y[i]=-1*x[i]*(x[i]-2);
}
}
public void init(){ //初始化
x=new double[n];
v=new double[n];
y=new double[n];
pbest=new double[n];
/***
* 本来是应该随机产生的,为了方便演示,我这里手动随机落两个点,分别落在最大值两边
*/
x[0]=-0.5;
x[1]=2.6;
v[0]=0.01;
v[1]=0.02;
fitnessFunction();
//初始化当前个体极值,并找到群体极值
for(int i=0;i<n;i++){
pbest[i]=y[i];
if(y[i]>gbest) gbest=y[i];
}
System.out.println("start gbest:"+gbest);
}
public double getMAX(double a,double b){
return a>b?a:b;
}
//粒子群算法
public void PSO(int max){
for(int i=0;i<max;i++){
double w=0.4;
for(int j=0;j<n;j++){
//更新位置和速度
v[j]=w*v[j]+c1*Math.random()*(pbest[j]-x[j])+c2*Math.random()*(gbest-x[j]);
if(v[j]>vmax) v[j]=vmax;
x[j]+=v[j];
//越界判断
if(x[j]>2) x[j]=2;
if(x[j]<-2) x[j]=-2;
}
fitnessFunction();
//更新个体极值和群体极值
for(int j=0;j<n;j++){
pbest[j]=getMAX(y[j],pbest[j]);
if(pbest[j]>gbest) gbest=pbest[j];
System.out.println(x[j]+" "+v[j]);
}
System.out.println("======"+(i+1)+"======gbest:"+gbest);
}
}
public static void main(String[] args){
PSOTest ts=new PSOTest();
ts.init();
ts.PSO(100);
}
}
输出结果如下:
View Code
start gbest:0.0
-0.4 0.1
0.0 -10.751668729351186
======1======gbest:0.0
-0.6822365786740794 -0.2822365786740793
0.0 -5.375834364675593
======2======gbest:0.0
-0.5822365786740794 0.1
0.0 -2.6879171823377965
======3======gbest:0.0
-0.48223657867407943 0.1
-1.3439585911688983 -1.3439585911688983
======4======gbest:0.0
-0.38223657867407945 0.1
-1.2439585911688982 0.1
======5======gbest:0.0
-0.47659030560462123 -0.09435372693054181
-1.143958591168898 0.1
======6======gbest:0.0
-0.37659030560462126 0.1
-1.043958591168898 0.1
======7======gbest:0.0
-0.2765903056046213 0.1
-0.943958591168898 0.1
======8======gbest:0.0
-0.27903394174424034 -0.0024436361396190653
-0.843958591168898 0.1
======9======gbest:0.0
-0.38899022876058803 -0.10995628701634769
-0.7439585911688981 0.1
======10======gbest:0.0
-0.35250959144436234 0.03648063731622572
-0.6439585911688981 0.1
======11======gbest:0.0
........
........
........
........
0.9999990975760489 -1.556071309835406E-6
======98======gbest:1.0
1.0000000029937202 4.411275849326098E-9
1.0000001827158205 1.085139771533034E-6
======99======gbest:1.0
0.9999999993730952 -3.6206249540206964E-9
1.0000001197322141 -6.298360633295484E-8
======100======gbest:1.0
我们可以从打印的数据看出来,刚开始x[0]和x[1]分散在最大值两边,然后x[0]和x[1]逐渐聚集到1的周围,这里,我们已经收敛到x=1这个地方了,这正是我们要求的最大值,其最大值为1,下面是图解过程。
1.初始状态
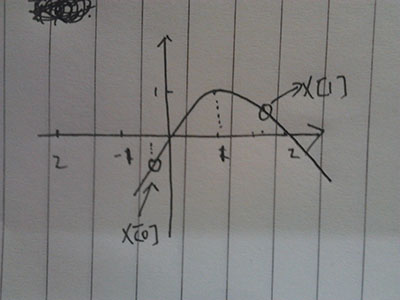
2.第二次x[1]向左边移动了
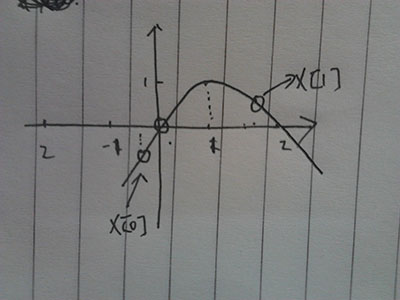
3.最后,两点聚集在1上,上面多个圈是他们聚集的过程,可以看出来,聚集过程是个越来越密集的过程。
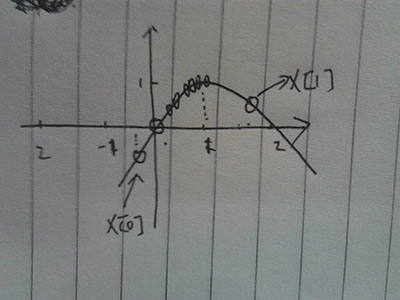
最后
粒子群算法,相对于我上次提到的遗传算法而言编码要简单很多,同样属于进化算法,但是粒子群算法并没有像遗传算法那样有选择交叉变异这样的过程,而更多的是体现在追踪单个粒子和共享集体最优信息来实现向最优空间搜索的形式,但是正由于它不同于遗传算法那样去忽略个体的一些内在联系,所以往往会陷入局部最优,所以,在粒子群算法中加入像遗传算法中的变异或者模拟退火等,可以跳过这个局部最优解。
而惯性权值对于函数收敛速度和是否收敛有很大的决定作用,两个学习参数c1,c2的制定也同等重要,但是即使这样,它也没有遗传算法中会有多个参数去维护,所以整个算法就那一个公式就行了,相当的清晰。在遗传算法中的信息的共享是染色体互相之间通过交叉共享,所以在搜索移动过程显得平均缓慢,而粒子群算法是根据gbest来决定整个集群的单向移动,所以相对遗传算法,它更快的收敛。
这不由得让我想到了熵这个概念,在诸如我们社会甚至宇宙这样复杂的系统,我们都处于一个无序的状态,属于熵增状态,像粒子群,遗传算法,对群体的研究,体现的智能不就是在这个无序的系统提供有序的能量,然后它就逐渐有序了。对于智能,我想我有更深的体会了。这段话属于发神经,不作参考。
注:本博文版权属BreezeDust所有
欢迎转载,转载请注明:http://www.cnblogs.com/BreezeDust/p/3354769.html
C++中const关键字的使用方法,烦透了一遍一遍的搜,总结一下,加深印象!!!
2013-10-06 21:28 by 菜鸟加贝的爬升, 346 阅读, 6 评论, 收藏, 编辑
之前一直在学习C/C++,关于const的使用,这里出现一点,那里出现一点。知识用时方恨少,这一段时间正好各种笔试题,其中关于const的用法也是层出不穷,所以疲于在书本上各种翻,这里汇总一下,加深自己的印象的同时,也方便以后查阅和学习。菜鸟一个,若有错误,望指正!
-
const关键字
常类型是指使用类型修饰符const说明的类型,常类型的变量或对象的值是不能被更新的。不管出现在任何上下文都是为这个目的而服务的。
-
const使用方法
-
定义const对象
const修饰符可以把对象转变成常数对象,意思就是说利用const进行修饰的变量的值在程序的任意位置将不能再被修改,就如同常数一样使用!任何修改该变量的尝试都会导致编译错误:


注意:因为常量在定以后就不能被修改,所以定义时必须初始化:
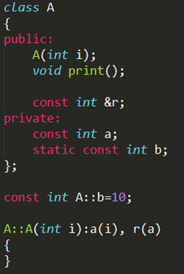
对于类中的const成员变量必须通过初始化列表进行初始化,如下所示:
- const对象默认为文件的局部变量
在全局作用域里定义非const变量时,它在整个程序中都可以访问,我们可以把一个非const变量定义在一个文件中,假设已经做了合适的声明,就可以在另外的文件中使用这个变量:


与其他变量不同,除非特别说明,在全局作用域声明的const变量是定义该对象的文件的局部变量。此变量只存在于那个文件中,不能被其他文件访问。通过指定const变量为extern,就可以在整个程序中访问const对象。


注意:非const变量默认为extern。要使const变量能够在其他文件中访问,必须在文件中显式地指定它为extern。
-
const 引用
const引用是指向const对象的引用:
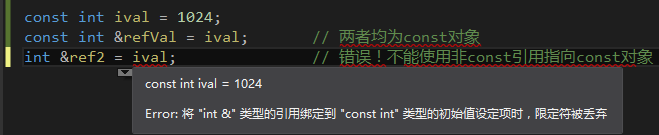

可以读取但不能修改refVal,因此,任何对refVal的赋值都是不合法的。这个限制有其意义:不能直接对ival赋值,因此不能通过使用refVal来修改ival。
同理,用ival初始化ref2也是不合法的:ref2是普通的非const引用,因此可以用来修改ref2指向的对象的值。通过ref2对ival赋值会导致修改const对象的值,为防止这样的修改,需要规定将普通的引用绑定到const对象是不合法的。
const 引用可以初始化为不同类型的对象或者初始化为右值。如字面值常量:
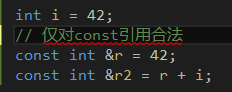
同样的初始化对于非const引用却是不合法的,而且会导致编译时错误。其原因非常微妙,值得解释一下。观察将引用绑定到不同的类型时所发生的事情,最容易理解上述行为。对于下一段代码:

编译器会将这些代码转换为一下形式:
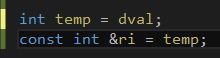 我们发现编译器会创建一个int型的暂时变量存储dval,然后将ri绑定到temp上。
我们发现编译器会创建一个int型的暂时变量存储dval,然后将ri绑定到temp上。
注意:引用在内部存放的是一个对象的地址,它是该对象的别名。对于不可寻址的值,如文字常量,以及不同类型的对象,编译器为了实现引用,必须生成一个临时对象,引用实际上指向该对象,但用户不能访问它。
如果ri不是const,那么可以给ri赋一新值。这样做不会修改dval的,而是修改了temp。期望对ri赋值会修改dval的程序员会发现dval没有被修改。仅允许const引用绑定到需要临时使用的值完全避免了这个问题,直接告诉程序员不能修改,因为const引用是只读的哈~(其实就是避免程序员心理预期产生反差。。。)
注意:非const引用只能绑定到与该引用相同类型的对象。
const引用则可以绑定到不同但相关的类型的对象或绑定到右值。
- const对象的动态数组
如果我们在自由存储区中创建的数组存储了内置类型的const对象,则必须为这个数组提供初始化: 因为数组元素都是const对象,无法赋值。实现这个要求的唯一方法是对数组做值初始化。
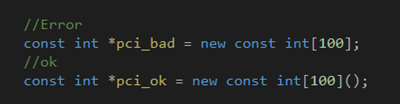
C++允许定义类类型的const数组,但该类类型必须提供默认构造函数:
 这里便会调用string类的默认构造函数初始化数组元素。
这里便会调用string类的默认构造函数初始化数组元素。
-
指针和const限定符的关系(重点!!!!!!!非常容易搞混)
const限定符和指针结合起来常见的情况有以下几种。
- 指向常量的指针(指向const对象的指针)
C++为了保证不允许使用指针改变所指的const值这个特性,强制要求这个指针也必须具备const特性:

这里cptr是一个指向double类型const对象的指针,const先顶了cptr指向的对象的类型,而并非cptr本身,所以cptr本身并不是const。所以定义的时候并不需要对它进行初始,如果需要的话,允许给cptr重新赋值,让其指向另一个const对象。但不能通过cptr修改其所指对象的值。

而我们将一个const对象的地址赋给一个普通的非const指针也会导致编译错误。

不能使用void*指针保存const对象的地址,必须使用const void*类型的指针保存const对象的地址。

下面令人头晕的一个问题来了----à 允许把非const对象的地址赋给指向const对象的指针,例如:
 但是我们不能通过cptr指针来修改dval的值!!!即使它指向的是非const对象。
但是我们不能通过cptr指针来修改dval的值!!!即使它指向的是非const对象。
然后,我们一定要知道,不能使用指向const对象的指针修改基础对象,然而如果该指针指向了非const对象,可用其他方式修改其所指的对象,所以事实上,可以修改const指针所指向的值的,但是不能通过const对象指针来进行而已!如下所示:

通过以上,我们知道指向const对象的指针 确切的讲: 自以为指向const的指针!
- 常指针(const指针)
C++中还提供了const指针——本身的值不能被修改。

我们可以从右往左把上述定义语句读作"指向int型对象的const指针"。与其他const量一样,const指针的值不能被修改,这意味着不能使curErr指向其他对象。Const指针也必须在定义的时候初始化。

指针本身是const的试试并没有说明是否能用改真真修改其所指向的对象的值。指针对象的值能否修改完全取决于该对象的类型。
- 指向常量的常指针(指向const对象的const指针)
如下可以这样定义:
 这样pi_ptr首先是一个const指针,然后其指向一个const对象~~~
这样pi_ptr首先是一个const指针,然后其指向一个const对象~~~
- 函数和const限定符的关系(另一难点!!!理解)
在一个类中,任何不会修改数据成员的函数都应该声明为const类型。如果在编写const成员函数时,不慎修改了数据成员,或者调用了其它非const成员函数,编译器将指出错误,这无疑会提高程序的健壮性。使用const关键字进行说明的成员函数,称为常成员函数。只有常成员函数才有资格操作常量或常对象,没有使用const关键字说明的成员函数不能用来操作常对象。常成员函数说明格式如下:
其中,const是加在函数说明后面的类型修饰符,它是函数类型的一个组成部分,因此,在函数实现部分也要带const关键字。下面举一例子说明常成员函数的特征。
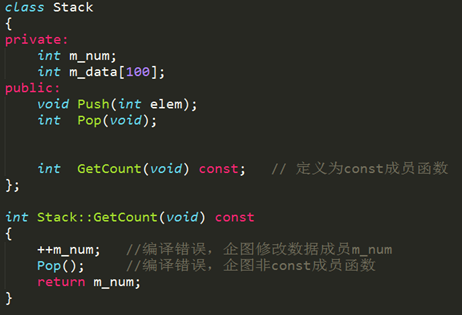
既然const是定义为const函数的组成部分,那么就可以通过添加const实现函数重载咯。
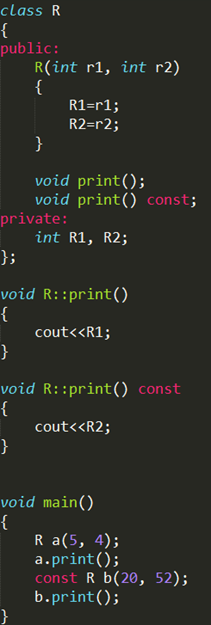
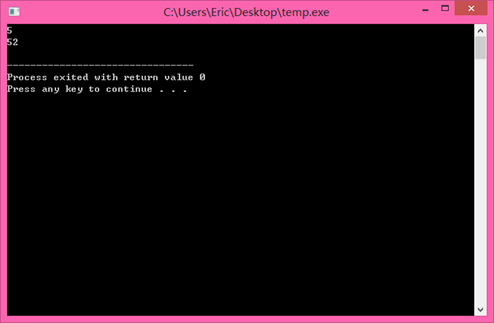
其中print成员函数就实现了两个版本~~~ 重载哦,输出结果为 5,52。 const对象默认调用const成员函数。
const修饰函数返回值其实用的并不是很多,它的含义和const修饰普通变量以及指针的含义基本相同。如下所示:
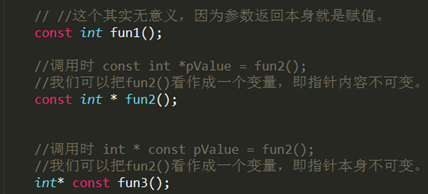
一般情况下,函数的返回值为某个对象时,如果将其声明为const时,多用于操作符的重载。通常,不建议用const修饰函数的返回值类型为某个对象或对某个对象引用的情况。原因如下:如果返回值为某个对象为const(const A test = A 实例)或某个对象的引用为const(const A& test = A实例) ,则返回值具有const属性,则返回实例只能访问类A中的公有(保护)数据成员和const成员函数,并且不允许对其进行赋值操作,这在一般情况下很少用到。




这样的一个const引用传递和最普通的函数按值传递的效果是一模一样的,他禁止对引用的对象的一切修改,唯一不同的是按值传递会先建立一个类对象的副本, 然后传递过去,而它直接传递地址,所以这种传递比按值传递更有效.另外只有引用的const传递可以传递一个临时对象,因为临时对象都是const属性, 且是不可见的,他短时间存在一个局部域中,所以不能使用指针,只有引用的const传递能够捕捉到这个家伙.
- const定义的常量在超出其作用域之后其空间会被释放,而static定义的静态常量在函数执行后不会释放其存储空间。
- static表示的是静态的。类的静态成员函数、静态成员变量是和类相关的,而不是和类的具体对象相关的。即使没有具体对象,也能调用类的静态成员函数和成员变量。一般类的静态函数几乎就是一个全局函数,只不过它的作用域限于包含它的文件中。
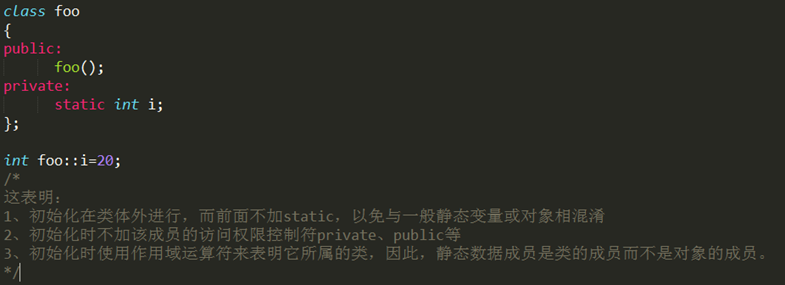
- 在C++中,static静态成员变量不能在类的内部初始化。在类的内部只是声明,定义必须在类定义体的外部,通常在类的实现文件中初始化,如:double Account::Rate=2.25; static关键字只能用于类定义体内部的声明中,定义时不能标示为static
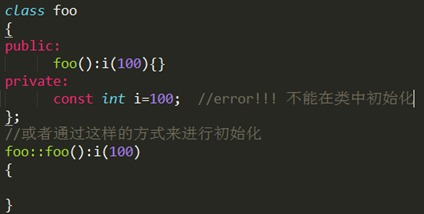
- 在C++中,const成员变量也不能在类定义处初始化,只能通过构造函数初始化列表进行,并且必须有构造函数。
- const数据成员,只在某个对象生存期内是常量,而对于整个类而言却是可变的。因为类可以创建多个对象,不同的对象其const数据成员的值可以不同。所以不能在类的声明中初始化const数据成员,因为类的对象没被创建时,编译器不知道const数据成员的值是什么。
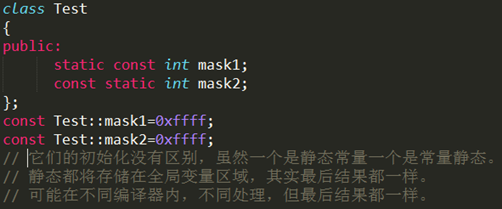
- const数据成员的初始化只能在类的构造函数的初始化列表中进行。要想建立在整个类中都恒定的常量,应该用类中的枚举常量来实现,或者static const。
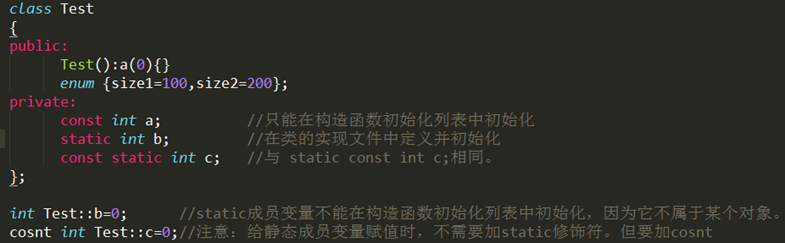
- const成员函数主要目的是防止成员函数修改对象的内容。即const成员函数不能修改成员变量的值,但可以访问成员变量。当方法成员函数时,该函数只能是const成员函数。
- static成员函数主要目的是作为类作用域的全局函数。不能访问类的非静态数据成员。类的静态成员函数没有this指针,这导致:1、不能直接存取类的非静态成员变量,调用非静态成员函数2、不能被声明为virtual
其中关于static、const、static cosnt、const static成员的初始化问题:
类中的static变量是属于类的,不属于某个对象,它在整个程序的运行过程中只有一个副本,因此不能在定义对象时 对变量进行初始化,就是不能用构造函数进行初始化,其正确的初始化方法是:
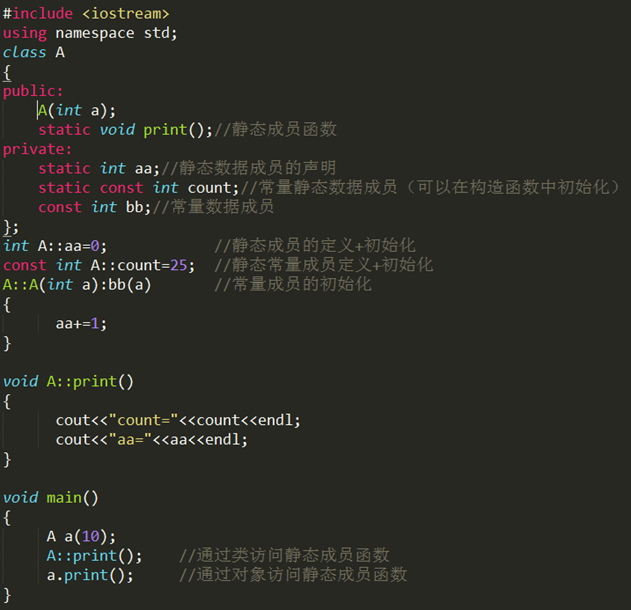
如果函数需要传入一个指针,面试官可能会问是否需要为该指针加上const,把const加在指针不同的位置有什么区别;如果写的函数需要传入的参数是一个复杂类型的实例,面试官可能会问传入值参数或者引用参数有什么区别,什么时候需要为传入的引用参数加上const。
const是用来声明一个常量的,当你不想让一个值被改变时就用const,const int max和int const max 是没有区别的,都可以。不涉及到指针const很好理解。一旦涉及到指针,则比较容易出问题。
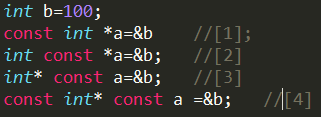
如果const位于星号的左侧,则const就是用来修饰指针所指向的变量,即指针指向的对象为常量;如果const位于星号的右侧,const就是修饰指针本身,即指针本身是常量。
因此,[1]和[2]的情况相同,都是指针所指向的内容为常量(const放在变量声明符的位置无关),这种情况下不允许对内容进行更改操作,如不能*a = 3 ;[3]为指针本身是常量,而指针所指向的内容不是常量,这种情况下不能对指针本身进行更改操作,如a++是错误的;[4]为指针本身和指向的内容均为常量。
如果理解了上面的所有信息,我相信应该问题不大。仅供参考~~~ 希望大家热烈讨论哈。 好了,先写到这里,在以后需要补充我再加东西吧。。。敲得手疼~~~ ~!!!
《编程珠玑》中“位图排序”引发的一系列实验
问题:
一个文件有8*106个正整数,每个数都小于107。文件中所有整数都是唯一的。要求对这些整数排序,按升序把排序的结构输出到磁盘上。
解决问题的方案有很多,下面我们介绍几种典型的方案。
1、高效的“位图排序”
特殊要求:最多有大约1M的内存空间可用!
如果在这个限制下,快速的对这些整数进行排序,一个优秀的解决方案是使用“位图排序”。
位图排序的思想就是在内存中申请一块连续的空间作为位图,初始时将位图的每一位都置为0。然后依次读取待排序的整数,将整数对应的位设置为1。最后按顺序扫描位图,如果某一位为1,输出到已排序文件。
比如待排序的数据S={3,0,4,1,7,2,5},最大为7,我们可以设置一个八位的位图B,将位图的每一位初始为0。对S中的每一个整数d,设置B[d]=1,即B=[1,1,1,1,1,1,0,1],最后扫描位图,对位图的每一位i,如果B[i]==1,则输出i到已排序文件,排序后的S={0,1,2,3,4,5,7}。
整个过程只需要遍历一遍待排序文件和位图,时间复杂度O(n),需要的辅助空间为(max(S)/8)字节。
程序代码:
bitmap_sort.c

#include <stdio.h> #include "data_size.h" #define SHIFT 5 #define MASK 0x1F int a[1+MAX_DATA/32]; void set(int i) { a[i>>SHIFT] |=1<<(i& MASK ); } int test(int i) { return a[i>>SHIFT] & (1<<(i& MASK )); } int main(int argc,char** argv) { int i=0; FILE *fin=NULL,*fout=NULL; for(i=0;i<1+MAX_DATA/32;i++) a[i]=0; if((fin=fopen(argv[1],"r"))==NULL) { printf("error!\n"); return 1; } while(fscanf(fin,"%d",&i)!=EOF) set(i); if((fout=fopen(argv[2],"w"))==NULL) { printf("error!\n"); return 1; } for(i=0;i<MAX_DATA;i++) if(test(i)) fprintf(fout,"%d\n",i); fclose(fin); fclose(fout); return 0; }
data_size.h
#ifndef DATA_SIZE_H_ #define DATA_SIZE_H_ #define SIZE 8000000 #define MAX_DATA 10000000 #endif
生产待排序文件数据的程序见附录。
测试(用time命令统计运行时间):(2次)
编译之后的可执行程序:bitmapsort 待排序文件:data.txt 输出文件:data2.txt
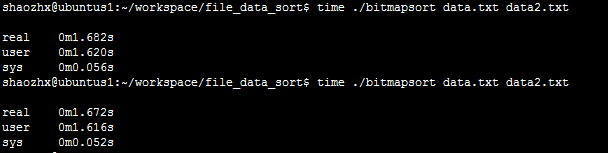
注:linux的time统计程序的运行时间,其统计结果包含以下数据:
1)实际时间(real time): 从command命令行开始执行到运行终止的消逝时间;
2)用户CPU时间(user CPU time): 命令执行完成花费的用户CPU时间,即命令在用户态中执行时间总和;
3)系统CPU时间(system CPU time): 命令执行完成花费的系统CPU时间,即命令在核心态中执行时间总和
2、linux排序命令
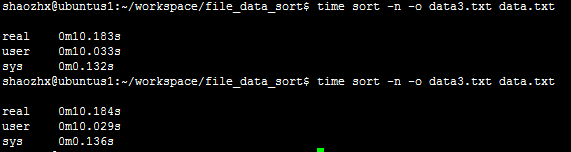
$ time sort -n -o data3.txt data.txt
使用linux的sort命令进行排序。
-n :使用“纯数字”进行排序(默认是以文字型态来排序的);
-o : 把排序结果输出到文件,而不是控制台
测试:(2次测试)
待排序文件:data.txt 输出文件:data3.txt
3、C标准库的qsort()函数
qsort包含在<stdlib.h>头文件中,此函数根据你给的比较条件进行快速排序,通过指针移动实现排序。排序之后的结果仍然放在原数组中。使用qsort函数必须自己写一个比较函数。
函数原型:
void qsort ( void * base, size_t num, size_t size, int ( * comparator ) ( const void *, const void * ) );
base :数组起始地址
num:数组元素个数
siz:每一个元素的大小
comparator:函数指针,指向比较函数
qsort.c
#include <stdio.h> #include <stdlib.h> #include "data_size.h" int intcomp(const void *x, const void *y) { return *(int *)x-*(int *)y; } int a[SIZE]; int main(int argc, char** argv) { FILE *fin=NULL,*fout=NULL; if((fin=fopen(argv[1],"r"))==NULL) { printf("open file error!\n"); return 1; } int i=0; while(fscanf(fin,"%d",&a[i])!=EOF) i++; qsort(a,SIZE,sizeof(int),intcomp); if((fout=fopen(argv[2],"w"))==NULL) { printf("open file error!\n"); return 1; } for(i=0;i<SIZE;i++) fprintf(fout,"%d\n",a[i]); return 0; }
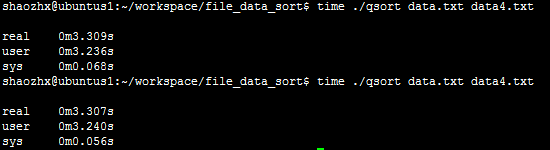
测试:(2次)
编译之后的可执行程序:qsort 待排序文件:data.txt 输出文件:data4.txt
4、C++标准库中set容器来进行排序
因为待排序的整数都是唯一的,并且set容器内部会按照一定的顺序组织内部的数据。我们可以用set容器来进行排序。
set_sort.cpp
#include <iostream> #include <fstream> #include <set> using namespace std; int main(int argc,char **argv) { int i=0,n=0; set<int> s; set<int>::iterator it; ifstream in(argv[1]); if(!in.is_open()) { cout<<"error"<<endl; return 1; } while(!in.eof()) { in>>n; s.insert(n); } ofstream out(argv[2]); if(!out.is_open()) { cout<<"error"<<endl; return 1; } for(it=s.begin();it!=s.end();++it) { out<<*it<<endl; } in.close(); out.close(); return 0; }
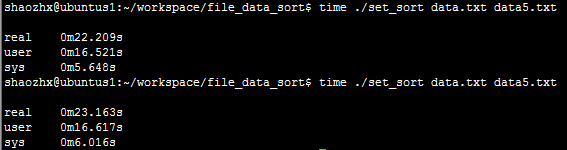
测试:
编译之后的可执行程序:set_sort 待排序文件:data.txt 输出文件:data5.txt
总结
上面四个程序的排序结果都正确,已用diff命令对比过。
从上面的运行时间,我们可以看出:
位图排序、C标准库qsort(排序)、系统命令排序、C++标准库set容器排序,它们的排序运行时间依次增高。
在特殊要求“最多有大约1M的内存空间可用!”的情况下,位图排序是一个非常优秀的排序方法,其运行速度快且占用内存小,但是前提是,待排序的数据都是整数,且不存在重复。
附录:
生产包含8*106个正整数 且 每个数都小于107的排序文件。
#include <stdio.h> #include <stdlib.h> #include <time.h> #include "data_size.h" int a[MAX_DATA]; void swap(int i,int j) { int temp=a[j]; a[j]=a[i]; a[i]=temp; } int main(int argc, char **argv) { int i=0; printf("%x\n",RAND_MAX); printf("%ld\n",time(NULL)); srand(time(NULL)); for(i=0;i<MAX_DATA;i++) { a[i]=i; } for(i=0;i<SIZE;i++) { int j=rand()%MAX_DATA; swap(i,j); } FILE * fin=NULL; if((fin=fopen(argv[1],"w"))==NULL) { printf("error!\n"); return 1; } for(i=0;i<SIZE;i++) { fprintf(fin,"%d\n",a[i]); } fclose(fin); printf("success!\n"); return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号