

聚集索引表插入数据和删除数据的方式是怎样的
根据《SQLSERVER聚集索引与非聚集索引的再次研究(上)》里说的,聚集索引维护着创建第一个聚集索引时的第一个字段的顺序来排序
当插入记录的时候,或者重新组织索引的时候都会按照字段顺序来排序
今天来做一个实验来验证一下
--------------------------------------------------华丽的分割线------------------------------------------------
先创建一个聚集索引表

1 USE [pratice] 2 GO 3 --DROP TABLE ClusteredTable 4 CREATE TABLE ClusteredTable 5 ( id INT, 6 col2 CHAR(999), 7 col3 VARCHAR(10) 8 )
这个表每个行由int(4字节),char(999字节)和varchar(0字节组成),所以每行为1003个字节,
则8行占用空间1003*8=8024字节加上一些内部开销,可以容纳在一个页面
1 --创建聚集索引 2 CREATE CLUSTERED INDEX CIX ON ClusteredTable(id ASC)
插入数据
1 --由于聚集索引需要有2个数据页才会出现一个索引页,所以这里插入16条记录,16条记录就需要2个数据页 2 DECLARE @i INT 3 SET @i=1 4 WHILE(@i<32) 5 BEGIN 6 INSERT INTO [dbo].[ClusteredTable] ( [id], [col2], [col3] ) 7 VALUES(@i,'xxx','') 8 SET @i=@i+2 9 END
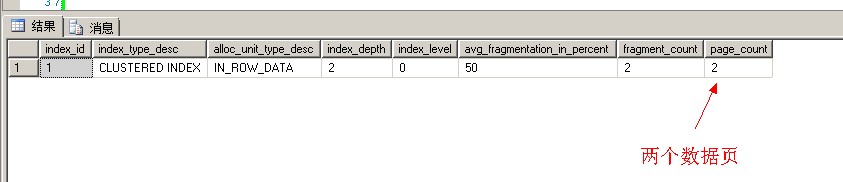
看一下所用的数据页数量
1 SELECT [index_id], [index_type_desc], [alloc_unit_type_desc], [index_depth], 2 [index_level], [avg_fragmentation_in_percent], [fragment_count], 3 [page_count] 4 FROM [sys].[dm_db_index_physical_stats](DB_ID('pratice'), 5 OBJECT_ID('pratice.dbo.ClusteredTable'), 6 NULL, NULL, NULL)
再创建一个表,用来保存DBCC IND的结果
 View Code
View Code执行下面语句,看一下DBCC IND的结果
先说明一下:
PageType 分页类型:1:数据页面;2:索引页面;3:Lob_mixed_page;4:Lob_tree_page;10:IAM页面
IndexID 索引ID,0 代表堆, 1 代表聚集索引, 2-250 代表非聚集索引 大于250就是text或image字段
1 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,ClusteredTable,-1) ') 2 3 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC

看一下页面内容
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE([pratice],1,14623,3) --索引页 4 GO 5 DBCC PAGE([pratice],1,14544,3)--数据页 6 GO 7 DBCC PAGE([pratice],1,37036,3)--数据页 8 GO
聚集索引页面
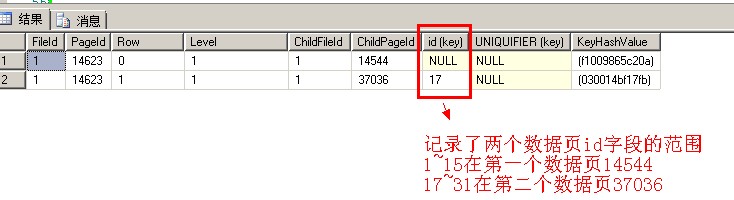
数据页 14544 可以看到14544页里面保存的是1~15的记录 其中字段m_slotCnt = 8 表示本页面存储了8条记录
View Code数据页 37036可以看到14544页里面保存的是17~31的记录 其中字段m_slotCnt = 8 表示本页面存储了8条记录
View Code
---------------------------------------------------------华丽的分割线------------------------------------------------
我们创建一个堆表以作为对比
1 USE [pratice] 2 GO 3 --DROP TABLE HeapTable 4 CREATE TABLE HeapTable 5 ( id INT, 6 col2 CHAR(999), 7 col3 VARCHAR(10) 8 ) 9 10 DECLARE @i INT 11 SET @i=1 12 WHILE(@i<32) 13 BEGIN 14 INSERT INTO [dbo].[HeapTable] ( [id], [col2], [col3] ) 15 VALUES(@i,'xxx','') 16 SET @i=@i+2 17 END
看一下所用的数据页数量
1 SELECT [index_id], [index_type_desc], [alloc_unit_type_desc], [index_depth], 2 [index_level], [avg_fragmentation_in_percent], [fragment_count], 3 [page_count] 4 FROM [sys].[dm_db_index_physical_stats](DB_ID('pratice'), 5 OBJECT_ID('pratice.dbo.HeapTable'), 6 NULL, NULL, NULL)

再看一下DBCC IND的结果
1 --先清空[DBCCResult]的数据 2 TRUNCATE TABLE [dbo].[DBCCResult] 3 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,HeapTable,-1) ') 4 5 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC

看一下数据页14529里的数据 id从1~13 其中字段m_slotCnt = 7 表示本页面存储了7条记录
View Code看一下数据页14545里的数据 id从15~27 其中字段m_slotCnt = 7 表示本页面存储了7条记录
View Code看一下数据页37037里的数据 只有id为29 和31这两条记录 其中字段m_slotCnt = 2 表示本页面存储了2条记录
View Code------------------------------------------------华丽的分割线------------------------------------------------------------
现在向聚集索引表ClusteredTable插入一条记录,插入id为30的记录
1 INSERT INTO [dbo].[ClusteredTable] ( [id], [col2], [col3] ) 2 SELECT 30,'xxx',''
1 --清空DBCCResult表数据 2 TRUNCATE TABLE [dbo].[DBCCResult] 3 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,ClusteredTable,-1) ') 4 5 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC

可以看到新增加了一页37042
我们看一下聚集索引页14623
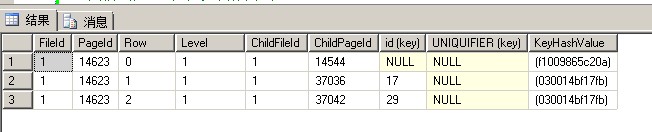
可以看到聚集索引页增加了一行
我们看一下37036页 ,可以看到该页本身存放8条记录,现在存放6条记录 m_slotCnt = 6
View Code我们看一下37042页,可以看到m_slotCnt = 3 ,该页面只有3条记录
View Code原本一页可以容纳8条记录,现在37036页面只能容纳6条记录,造成还有2条记录的剩余空间没有利用,造成浪费
而且聚集索引页的主键列的id字段的范围值也打乱了,需要增加一行来保持索引键列的有序
其实这也属于页拆分的一种,详细可以看一下宋大侠的文章里面关于内部碎片和外部碎片的说法,这里就不讨论了
T-SQL查询高级—SQL Server索引中的碎片和填充因子
------------------------------------------------------------华丽的分割线-----------------------------------------------
其实这里插入到聚集索引表里的记录是会维护数据页和索引页使得id字段保持有序
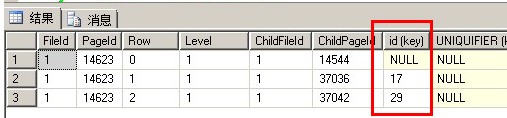

id为30这条记录还是插在了id为31的这条记录前面
这样的话,插入一条记录的同时需要维护索引页和数据页所以开销是比较大的
--------------------------------------------------华丽的分割线----------------------------------------------
那么堆表是怎样处理数据的插入的呢?
现在向堆表[HeapTable]插入一条记录,插入id为26的记录
1 INSERT INTO [dbo].[HeapTable] ( [id], [col2], [col3] ) 2 SELECT 26,'xxx',''
1 --先清空[DBCCResult]的数据 2 TRUNCATE TABLE [dbo].[DBCCResult] 3 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,HeapTable,-1) ') 4 5 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC

可以看到什么页面都没有增加
我们看一下数据页37037里的内容 可以看到m_slotCnt = 3 ,说明这个数据页比没有插入数据之前多了一条记录
View Code按道理,如果按照id字段的顺序插入记录的话,id为26的这条记录应该插入到数据页14545 里id为25的那条记录的后面,但是堆表的结果并非这样
他插入到了数据页37037的id为31的那条记录的后面

这说明堆表的记录插入只会插入到堆中的最后一个数据页里的最后,所以插入数据基本上没有开销
-------------------------------------------------华丽的分割线---------------------------------------------
而园子里有人针对聚集索引表作出下面讨论:
插入是会分配新的page,而不是在原来的有碎片的page里面插入数据
只有说经常更新行打小不固定的表的时候,碎片空隙保持一定的冗余,防止页拆分Shiite有一定好处的
不过我不认同您对数据插入一定会分配新的页的说法,当页内空间足够是不用分配新的页的。如果每插入一条数据分配一个新的页。那岂不是一个100W行的表会有100W页?那SQL Server可以退出历史舞台了.....
可以看到刚才我在聚集索引表里插入id为30的那条记录,结果造成分配了一个新的page,为什麽??因为原本只能容纳8条记录的页面
不能再容纳新的记录了,只能够分配一个新的page,分配的时候也造成了页拆分
而插入是不是一定会分配新的page呢?
证明:证明的方法很简单,只需要在数据页37042里再插入一条记录,看会不会分配新的page就可以了
数据页37042现在有3条记录,id分别为29,30,31
现在插入id为32这条记录
1 INSERT INTO [dbo].[ClusteredTable] ( [id], [col2], [col3] ) 2 SELECT 32,'xxx',''
1 SELECT [index_id], [index_type_desc], [alloc_unit_type_desc], [index_depth], 2 [index_level], [avg_fragmentation_in_percent], [fragment_count], 3 [page_count] 4 FROM [sys].[dm_db_index_physical_stats](DB_ID('pratice'), 5 OBJECT_ID('pratice.dbo.ClusteredTable'), 6 NULL, NULL, NULL) 7 8 9 --先清空[DBCCResult]表的数据 10 TRUNCATE TABLE [dbo].[DBCCResult] 11 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,ClusteredTable,-1) ') 12 13 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC
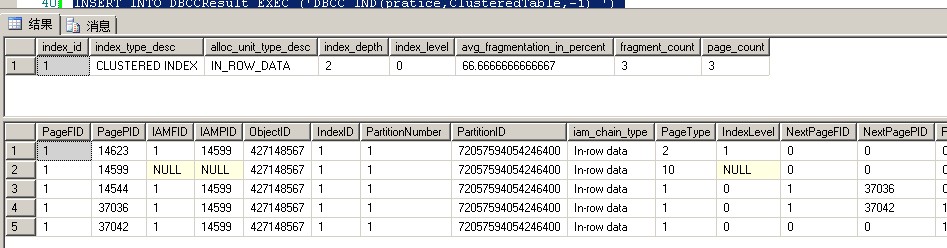
看一下数据页37042这个页面 m_slotCnt = 4 说明37042这个页面有4条记录
View Code现在我们插入6条记录,让数据超过数据页面本身的承载能力,让他分配新的数据页
1 INSERT INTO [dbo].[ClusteredTable] ( [id], [col2], [col3] ) 2 SELECT 33,'xxx','' UNION ALL 3 SELECT 34,'xxx','' UNION ALL 4 SELECT 35,'xxx','' UNION ALL 5 SELECT 36,'xxx','' UNION ALL 6 SELECT 37,'xxx',''
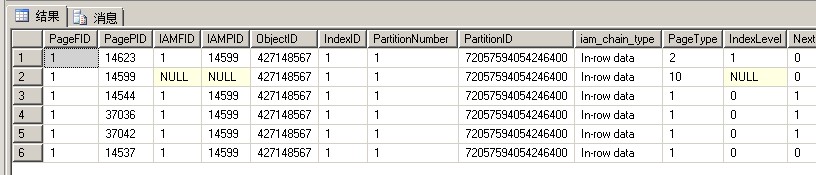
聚集索引页面

从上面两张图可以看到,分配了一个新的数据页14537,因为数据页37042已经超过8条记录了,所以必须要分配一个新的数据页,同时聚集索引页也会增加一条记录
数据页14537的内容,m_slotCnt = 1 只有一条记录
View Code堆表跟聚集索引表一样,当数据页面不能承载页面本身的数据量的时候就会分配一个新的数据页,由于篇幅关系,这里就不测试了
-----------------------------------------------------华丽的分割线------------------------------------------------------------
那么重组索引/重建索引对于上面解决那个页拆分有没有帮助呢? 对于数据页37036,页面数据还没有填满的情况
我们先使用重组索引
其实对于数据页37036的情况,我们也可以理解为在数据页37036里删除了两条记录,使得数据页37036里的记录数不足8条
很多书本上说,如果表空间还剩下很多的话,最好在表上建立一个聚集索引,然后重组索引,重组索引之后一些数据页面剩余的页面空间
就可以利用起来
先重组一下索引
1 USE [pratice] 2 GO 3 ALTER INDEX [CIX] ON ClusteredTable REORGANIZE
我们看一下重组索引之后,数据页和聚集索引页面变成什么样子了???
1 --先清空[DBCCResult]表的数据 2 TRUNCATE TABLE [dbo].[DBCCResult] 3 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,ClusteredTable,-1) ') 4 5 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC

聚集索引页面

可以看到数据页14537这个页面不见了,聚集索引页的索引键列(id)的范围值重新排序了
因为刚才在数据页37036里遭遇了页拆分,所以这里只需要查看数据页37036和数据页37042里的内容就可以了
数据页37036,可以看到 m_slotCnt = 8 ,数据页37036里的记录又填充满了,id的范围从17~30
View Code
数据页37042,可以看到 m_slotCnt = 7,id的范围从31~37
View Code
重组索引之后无论是数据页还是索引页,里面的数据都按照id列的顺序填充满并排好序了
那么“重组索引之后一些数据页面剩余的页面空间就可以利用起来”是真的
------------------------------------------------------------华丽的分割线--------------------------------------------------------
那么重建索引呢??跟重组索引有什么区别??
先drop掉ClusteredTable表,然后又创建ClusteredTable表,插入数据,建表和建索引的步骤跟文章开头一样,这里就不写了
按照前面的做法,令第二个数据页面只剩下两条记录没有填满,这里由于篇幅关系就不写了,文章开头都有步骤

下面这幅图是我插入了id为30的记录之后,ClusteredTable表中存在的索引页和数据页,可以看到增加了一个数据页37036
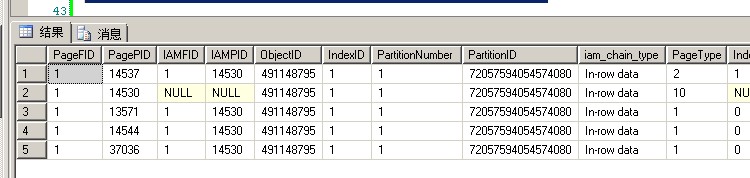
可以看到数据页37036里的内容, m_slotCnt = 3 记录有3条,id分别为:29,30,31
View Code再插入6条记录
1 INSERT INTO [dbo].[ClusteredTable] ( [id], [col2], [col3] ) 2 SELECT 33,'xxx','' UNION ALL 3 SELECT 34,'xxx','' UNION ALL 4 SELECT 35,'xxx','' UNION ALL 5 SELECT 36,'xxx','' UNION ALL 6 SELECT 37,'xxx','' UNION ALL 7 SELECT 38,'xxx',''
可以看到多了一个数据页面14539
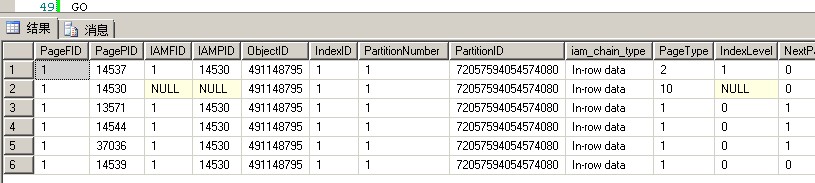
数据页面14539只有一条记录,m_slotCnt = 1
View Code
现在来重建一下索引
1 USE [pratice] 2 GO 3 ALTER INDEX [CIX] ON ClusteredTable REBUILD
我们看一下重组索引之后,数据页和聚集索引页面变成什么样子了???

数据页14539这个页面不见了,更重要的是原本4个数据页面现在只有3个,还有大家留意一下索引页和数据页的pageid,跟之前完全不一样
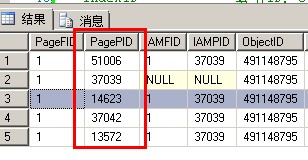
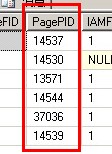
我们看一下聚集索引页面和数据页面有什么变化
聚集索引页面
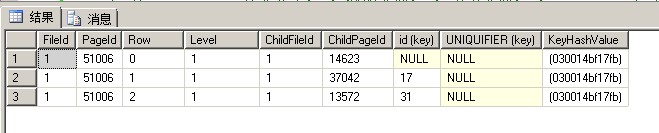
数据页14623, m_slotCnt = 8
View Code数据页37042, m_slotCnt = 8
View Code数据页14623, m_slotCnt = 7
View Code
从上面数据页面和聚集索引页面的结果看,重建索引和重组索引基本上是一样的效果,只是,重建索引会把索引页和数据页删除,然后分配新的索引页和数据页
所以重建索引开销还是比较大的
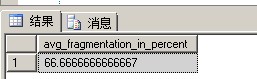
这里宋大侠有一个建议:
当[dm_db_index_physical_stats]DMV里的[avg_fragmentation_in_percent]字段大于30%的时候使用索引重建
当[avg_fragmentation_in_percent]等于小于30%的时候使用索引重组
[avg_fragmentation_in_percent]>30%就重建索引
[avg_fragmentation_in_percent]<=30%就重组索引
1 SELECT [avg_fragmentation_in_percent] 2 FROM [sys].[dm_db_index_physical_stats](DB_ID('pratice'), 3 OBJECT_ID('pratice.dbo.ClusteredTable'), 4 NULL, NULL, NULL)
---------------------------------------------------华丽的分割线--------------------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号