

HelloWorld - Linux
说明:本文基于Centos 6.4 32位操作系统(CentOS-6.4-i386-LiveDVD.iso)
一、编写HelloWorld源码
远程连接到Centos机器上,先建立一个文件夹用来存放源码:
使用mkdir 建立目录 (-p参数指定当父目录不存在时先创建父目录)
使用cd命令切换到刚才建立的目录下。
![]()
使用Centos预装的Vim文本编辑器创建HelloWorld.c源码,输入经典的HelloWorld源代码。

1 #include <stdio.h> 2 3 int main() 4 { 5 printf("Hello World!\n"); 6 return 0; 7 }
输入完毕后保存为HelloWorld.c文件。
二、安装GCC
回到控制台输入gcc命令,判断机器上有没有安装gcc编译器,如果没有安装的话则会出现下面的提示:
![]()
要安装gcc很容易。联网状态下输入yum install gcc 来安装gcc:

系统会自动检查需要安装的组件,并在检查完毕后给出提示需要安装那些组件包,并告知需要下载的组件包总大小和安装需占用的磁盘空间:

按y确认后,系统则会下载需要的组件包并进行安装。安装成功后会出现Complete提示,此时输入gcc -v命令则可查看安装的gcc版本。

三、编译源码
如果前面的操作都顺利的话,当前的工作目录应该还在:
/home/root/study/cplusplus/test/HelloWorld
如果不确定的话,可以输入pwd命令来输出当前工作目录。如果当前目录不是上面显示的目录,可以使用cd命令切换到上面的目录。
命令行中输入gcc –o HelloWorld HelloWorld.c执行编译链接。如果一切正常的话,输入ll 命令此,则会看到在当前目录下会多出一个HelloWorld文件。该文件就是生成的可执行文件。

四、运行程序
直接在当前目录下输入./HelloWorld即可看见经典的“Hello World ”输出到屏幕上了。
![]()
需要说明的是,在Linux系统中如果要成功执行一个程序。那么该程序对当前用户来讲必须要有执行的权限,“编译源码”一节图片中红色区域表示HelloWorld这个文件对于root用户的权限是:读、写、执行,对应root用户组成员的权限是读、执行,对于其他用户的权限也是读、执行。为了验证,我们做如下操作:(说明:需先创建一个普通用户且不在root组中,此文中该普通用户名是Taly)
输入su Taly,切换到普通用户下,输入./HelloWorld,程序正常执行。回到root用户角色下,输入命令
chmod 754 HelloWorld 去除其他用户的执行权限,再次使用Taly运行./HelloWorld,此时报权限不足的错误。具体流程如下图:

版权说明:本文章版权归本人及博客园共同所有,未经允许请勿用于任何商业用途。欢迎转载,转载请标明原文出处:
http://www.cnblogs.com/talywy/archive/2013/06/05/3120036.html
使用权限:所有使用者
使用方式:cat [-AbeEnstTuv] [--help] [--version] fileName
说明:把档案串连接后传到基本输出(萤幕或加 > fileName 到另一个档案)
参数:
-n 或 --number 由 1 开始对所有输出的行数编号
-b 或 --number-nonblank 和 -n 相似,只不过对于空白行不编号
-s 或 --squeeze-blank 当遇到有连续两行以上的空白行,就代换为一行的空白行
-v 或 --show-nonprinting ????
(1)一次性显示整个文件的内容
$ cat filename
比如:显示 /etc/profile 内容

(2)创建一个文件,但是不能编辑已存在的文件
$ cat > filename
例如:

注意文件输入的结尾已“ctrl+z”结束
(3)将几个文件合并为一个文件:
$ cat file1 file2 > file

(4) 把 textfile1 和 textfile2 的档案内容加上行号之后将内容附加到 textfile3 里
$ cat-n textfile1 textfile2 >> textfile3

[LeetCode 126] - 单词梯II(Word Ladder II)
问题
给出两个单词(start和end)与一个字典,找出从start到end的最短转换序列。规则如下:
- 一次只能改变一个字母
- 中间单词必须在字典里存在
例如:
给出
start = "hit"
end = "cog"
dict = ["hot","dot","dog","lot","log"]
返回
[
["hit","hot","dot","dog","cog"],
["hit","hot","lot","log","cog"]
]
注意
- 所有单词的长度一样
- 所有单词中只有小写字母
初始思路
最直接的想法是从start开始,对每个字母位置从'a'到'z'尝试替换。如果替换字母后的单词在字典中,将其加入路径,然后以新单词为起点进行递归调用,否则继续循环。每层递归函数终止的条件是end出现或者单词长度*26次循环完毕。end出现时表示找到一个序列,对比当前最短序列做相应更新即可。
处理过程中需要注意的主要有几点:
- 不能相同字母替换,如hot第一个位置遍历到h时不应该处理。否则就会不断的在hot上死循环。因此在替换后前要做一次检查。
- 我们要找的是最短的转换方案,所以转换序列不应该出现重复的单词。否则组合将会有无数多种,如例子中的["hit","hot","dot","dog","dot","dog","dog",....."cog"]。这里我们可以使用一个unordered_set容器来保存某次一次替换序列中已出现过的单词,也可以每次使用std:find去搜索当前替换序列。如果使用unordered_set,在递归处理时,和单词序列一样,要在递归后做相应的出栈操作。
- 处理过程中如果发现当前处理序列长度已经超过当前最短序列长度,可以中止对该序列的处理,因为我们要找的是最短的序列。
 递归实现
递归实现提交测试,Judge Small没有问题。Judge Large不幸超时。
优化
观察我们的处理方法,找到可变换后的单词后,我们会马上基于它继续查找。这是一种深度优先的查找方法,即英文的DFS(Depth-first search)。这对找出答案很可能是不利的,如果一开始进入了一条很长的序列,就会浪费了时间。而广度优先BFS(Breadth-first search)的方法似乎更合适,当找到一个序列时,这个序列肯定是最短的之一。
要进行广度优先遍历,我们可以在发现替换字母后的单词在字典中时,不马上继续处理它,而是将其放入一个队列中。通过队列先进先出的性质,就可以实现广度优先的处理了。由于最后要输出的是整个转换序列,为了简单起见,我们可以将当前已转换出的序列放入队列中,即队列形式为std::vector<std::vector<std::string>>,序列的最后一个元素就是下次处理时要继续转换的单词。
使用广度优先遍历后,还有一个特性使得我们可以更方便的处理深度优先中重复单词的问题。当一个单词在某一层(一层即从第一个单词到当前单词的长度一样的序列)出现后,后面再出现的情况肯定不会是最短序列(相当于走了回头路),因此我们可以在处理完一层后直接将已用过的单词从字典中去除。需要注意的是,同一层是不能去除的,如例子中的hot在两个序列的第二层中都出现了。这样我们就需要一个容器把当前层用过的单词保存起来,等处理的层数发生变化时再将它们从字典里移除。
最后要注意的是查找结束的条件。由于找到了一个序列后该序列只是最短的之一,我们还要继续进行处理,直到队列中当前层都处理完毕。所以我们要在找到一个序列后将它的长度记录下来,当要处理的序列长度已经大于该值时,就可以结束查找了。
BFS实现1提交后Judge Large多处理了几条用例,但是最后还是超时了。
再次优化
一个比较明显的优化点是我们把存储序列的vector放到了队列中,每次都要拷贝旧队列然后产生新队列。回想一下我们使用vector的原因,主要是为了能保存序列,同时还能获得当前序列的长度。为了实现这两个目的,我们可以定义如下结构体:
1 struct PathTag 2 { 3 PathTag* parent_; 4 std::string value_; 5 int length_; 6 7 PathTag(PathTag* parent, const std::string& value, int length) : parent_(parent), value_(value), length_(length) 8 { 9 } 10 };
结构体记录了当前单词的前一个单词以及当前的序列长度。有了这个结构体,我们在最后找到end后就可以通过不断往前回溯得出整个路径。而这个路径是反向的,最后还需要做一次倒置操作。改进前面的BFS代码如下(需要注意的是,由于LeetCode里不能使用智能指针,我们通过辅助函数来申请和释放裸指针而不是直接new。如果不关心内存问题的话直接new了不管也可。):
BFS2提交后Judge Large又多处理了几条用例,但是还是没能通过。
使用邻接列表
在继续优化之前,我们先来学习一个图论中的概念 - 邻接列表(Adjacency List)。具体细节可以参见这篇wiki:http://en.wikipedia.org/wiki/Adjacency_list 。简单来说,这是一个存储图中每个顶点的所有邻接顶点的数据结构。如无向图:
a
/ \
b --- c
它的邻接列表为:
a => b, c
b => a, c
c => a, b
具体到本问题,我们可以发现,start到end的所有序列,就是一个这些序列中所有单词为点组成的图。如果我们生成了该图的邻接列表,就可以不断的在每个单词的邻接列表里找到转换的下一个单词,从而最终找到end。那么,我们首先要对字典里的单词生成邻接列表:遍历字典里的单词,针对每个单词用前面逐字母替换的方法找出邻接单词,并保存起来。这里使用一个std::unordered_map<std::string, std::unordered_set<std::string>>来保存邻接列表。
有了邻接列表,寻找序列的方法就发生变化了。我们不再逐个替换字母,而是从start出发,遍历start的邻接顶点,将邻接顶点放入队列中。并重复操作直到队列为空。还有一个发生变化的地方是去重操作。由于不再遍历字典,现在我们发现非同层出现重复的单词就跳过它而不是从字典里删去。
剩下的生成路径的方法仍然和BFS2类似,全部代码如下:
邻接列表BFS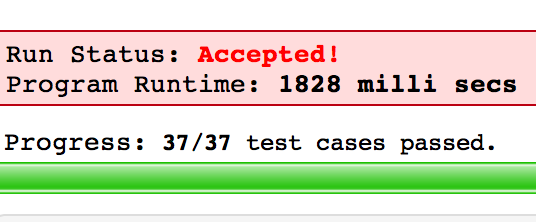
这回终于通过Judge Large了。
一种更快的解决方案
下面再介绍一种更快的解决方案,思路及代码来自niaokedaoren的博客。
前一个解决方案虽然能通过大数据集测试,但是为了保存路径信息我们额外引入了一个结构体而且因为需要用到指针使用了大量的new操作。还有什么不用保存所有路径信息的办法?
niaokedaoren的方案中使用了一个前驱单词表,即记录每一个单词的前驱单词是哪些。这样在遍历完毕后,我们从end出发递归就能把所有路径生成出来。但是由于前驱单词表不能记录当前的层次信息,似乎我们没法完成去重的工作。这个方案的巧妙之处就在于它没有使用我们通常的队列保存待处理的单词,一个单词一个单词先进先出处理的方法,而是使用两个vector来模拟队列的操作。我们从vector 1中遍历单词进行转换尝试,发现能转换的单词后将其放入vector 2中。当vector 1中的单词处理完毕后即为一层处理完毕,它里面的单词就可以从字典里删去了。接着我们对vector 2进行同样处理,如此反复直到当前处理的vector中不再有单词。我们发现vector 1和vector 2在不断地交换正处理容器和待处理容器的身份,因此可以通过将其放入一个数组中,每次循环对数组下标值取反实现身份的交替:
int current = 0;
int previous = 1;
循环
current = !current; previous = !previous;
......
循环结束
完全代码如下:
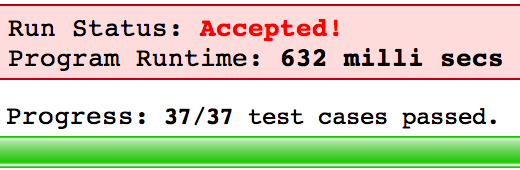
niaokedaoren的方案可以看到处理速度快了不少:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号