

在VMware Workstation的Ubuntu下搭建Hadoop和Ganglia环境
在VMware Workstation的Ubuntu下搭建Hadoop和Ganglia环境
相信大部分朋友对Hadoop肯定不陌生,它是一个开源的分布式计算框架,主要由MapReduce、HDFS、Hbase这几个核心部分组成。Hadoop作为云计算的基础平台,使用它的人越来越多,对于一般人而言,要想搭建真实的集群环境是比较难的,因此想要体验Hadoop,只有在虚拟机中搭建环境了。Hadoop集群环境运行起来之后,实时的获取集群的运行情况是比较重要的,因此需要一款监控工具来进行监控。Ganglia是一个开源的监控平台,可以用它来对Hadoop进行监控,今天就来讲一下如何在Ubuntu下搭建Hadoop环境以及如何利用Ganglia来监视集群运行情况。
一.安装VMWare Workstation和Ubuntu
从网上下载VMWare Workstation和Ubuntu,在这里我用的是VMWare Workstation 8.0.4和Ubuntu 12.04.2(Ubuntu 10貌似很多更新源都停止服务了,所以这里采用Ubuntu 12,注意Ubuntu 12要求vmware版本在8.0以上),相关安装教程可以参考这篇博文:
VMWare下载地址:http://www.itopdog.cn/utilities-operating-systems/virtual-machine/vmware-workstation.html
ubuntu 下载:http://mirrors.163.com/ubuntu-releases/或者http://mirrors.sohu.com/ubuntu-releases/
安装好Ubuntu后,由于ubuntu 12采用的是gnome 3的界面,反映比较慢,建议用回以前的经典界面gnome 2.方法:
需要安装gnome-session-fallback软件:
在命令行下输入
sudo apt-get intall gnome-session-fallback,安装完之后,点击右上角的“设置”图标,选择“Log out”,然后就出现登录初始界面了,点击 小扳手 图标,选择 gnome classic来登录,以后默认就采用经典界面了。




重新计入系统之后,发现界面就发生了变化:
二.安装配置Hadoop
1.准备工作
为了能够正常安装和运行Hadoop,需要做一些准备工作。
1)安装VMWare Tools
安装了VMWare Tools后,可以在宿主机和虚拟机之间直接拷贝文件。安装方法如下:
先依次运行命令:
sudo apt-get install build-essential

就会弹出VMWare Tools所在的文件夹,然后右键VMWare Tools.tar.gz,copy到Home目录下。
再打开Terminal,输入解压命令:

解压完成之后,进入解压目录,进行安装:

然后根据提示不断回车或者输入“yes”或者“no”即可。
当出现如下界面时,表示安装成功:

之后重启系统就可以直接在宿主机和VM之间互相复制粘贴文件了。
2)安装JDK
由于Hadoop是用Java语言编写的,运行时必须要有java环境,因此需要安装JDK。
首先去官网下载JDK安装包,下面是下载地址:
http://www.oracle.com/technetwork/java/javase/downloads/jdk6downloads-1902814.html
下载下来之后,先进入到/usr/lib目录下,建立文件夹java,然后拷贝jdk到java目录下,先赋予可执行权限,再直接一边解压进行安装:

等待片刻安装完之后,输入命令
gedit /etc/profile
来配置环境变量,把下面代码加入到文件末尾保存退出(注意路径里面的1.6.0_45根据个人下载版本而定):
export JAVA_HOME=/usr/lib/java/jdk1.6.0_45 export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
然后输入source /etc/profile使保存生效,再将安装的jdk设置为系统默认的jdk,依次输入以下命令:
sudo update-alternatives --install "/usr/bin/java" "java" "/usr/lib/java/jdk1.6.0_45/bin/java" 300 sudo update-alternatives --install "/usr/bin/javac" "javac" "/usr/lib/java/jdk1.6.0_45/bin//javac" 300 sudo update-alternatives --config java sudo update-alternatives --config javac
注意路径根据个人情况而定。
最后输入java -version,若出现版本信息则安装成功。

3)安装和配置Hadoop
先从Hadoop官网或者镜像网站上下载Hadoop的相应版本,下面是下载地址:
http://archive.apache.org/dist/hadoop/core/
我下载的是hadoop-0.20.203.0rc1.tar.gz,然后直接拖到ubuntu的Desktop上,再在/usr目录下建立hadoop文件夹,
将hadoop-0.20.203.0rc1.tar.gz文件直接解压到到/usr/hadoop目录下。

解压之后,需要配置系统环境变量:
运行命令 sudo gedit /etc/profile
添加如下内容(注意HADOOPHOME是自己的hadoop文件夹所在路径):
export HADOOPHOME=/usr/hadoop/hadoop-0.20.203.0 export PATH=$HADOOPHOME/bin:$PATH
添加完之后source /etc/profile,以保存更改。
然后需要更改hadoop文件夹的所属者,将所属者赋予当前用户,我的当前用户是zwl(这个步骤很重要,否则集群运行时会提示权限不够):
sudo chown -hR zwl /usr/hadoop
接下来需要配置/usr/hadoop/hadoop-0.20.203.0/conf/hadoop-env.sh文件:
在文件中添加内容:
export JAVA_HOME=/usr/lib/java/jdk1.6.0_45
然后需要修改/usr/hadoop/hadoop-0.20.203.0/conf/目录下的core-site.xml、hdfs-site.xml、mapred-site.xml这三个文件:
三个文件的内容修改为下:
core-site.xml

<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/tmp</value> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
hdfs-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
在进行这些配置之后需要安装ssh,输入命令 sudo apt-get install ssh和sudo apt-get install rsync,完成之后输入命令
ssh localhost如果没有提示错误则安装成功,然后需要为ssh设置免密码登录和设置权限,依次输入下面两条命令:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
chmod 700 ~/.ssh
chmod 644 ~/.ssh/authorized_keys
现在就可以启动hadoop集群了:
先输入到目录/usr/hadop/hadoop-0.20.203.0命令下,输入命令进行格式化:
bin/hadoop namenode -format
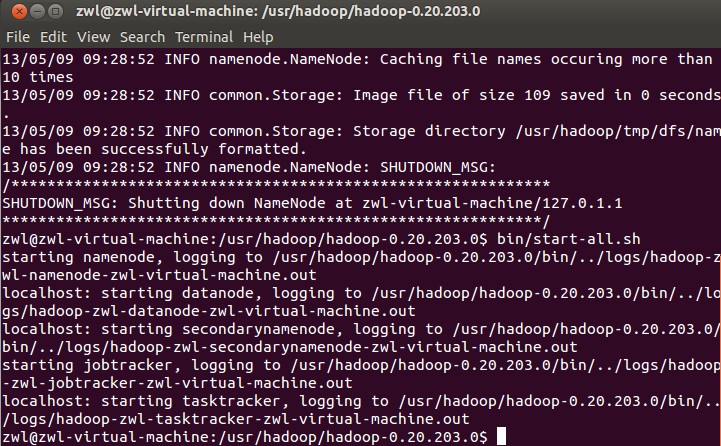
然后启动集群:bin/start-all.sh,,如果提示以下信息则表示安装成功:
关闭集群可以通过命令bin/stop-all.sh来关闭。
至此hadoop集群的安装和配置已经完成,接下来需要安装和配置Ganglia
三.安装和配置Ganglia
1.安装ganglia-monitor ganglia-webfrontend gmetad
运行命令 sudo apt-get install ganglia-monitor ganglia-webfrontend gmetad进行安装。
安装过程中会弹出提示让重新启动apache2,选择“Yes”:

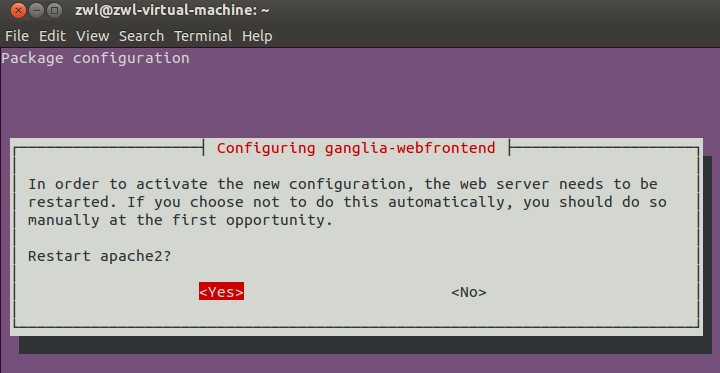
完了之后会提示配置ganglia-webfrontend,选择“Yes“:
在这个过程会自动安装rrdtool,php这些东西,安装完成之后,需要进行一些配置:
先需要配置gmetad.conf
sudo gedit /etc/ganglia/gmetad.conf
如果里面存在
datasource "my cluster" localhost

则不用更改,否则添加进去
然后配置gmond.conf
sudo gedit /etc/ganglia/gmond.conf
找到cluster块,将name设置成 "my cluster"。

然后重启gmond和gmetad:
sudo /etc/init.d/gmetad restart
sudo /etc/init.d/ganglia-monitor restart
然后需要配置apche2:
sudo gedit /etc/apache2/httpd.conf,添加ServerName localhost:80进去保存。
再将默认的ganglia-webfrontend文件夹复制到apache的www目录下
sudo cp -r /usr/share/ganglia-webfrontend /var/www/ganglia
之后输入命令sudo /etc/init.d/apache2 restart来重启apache,
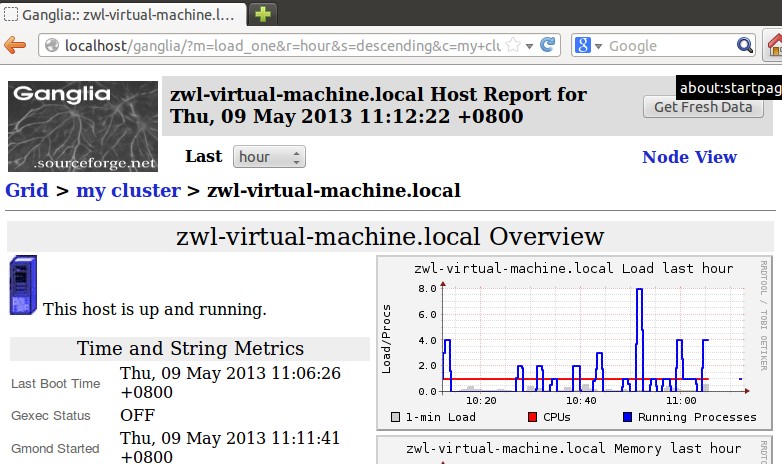
再输入http://localhost/ganglia就可以看到ganglia的首页了。

ganglia安装成功之后,就需要进行一些配置让它来监控hadoop,这里主要修改/usr/hadoop/hadoop-0.20.203.0/conf/
目录下的hadoop-metrics2.properties文件,将这个文件的最下面六行注释去掉,改成:
namenode.sink.ganglia.servers=239.2.11.71:8649 datanode.sink.ganglia.servers=239.2.11.71:8649 jobtracker.sink.ganglia.servers=239.2.11.71:8649 tasktracker.sink.ganglia.servers=239.2.11.71:8649 maptask.sink.ganglia.servers=239.2.11.71:8649 reducetask.sink.ganglia.servers=239.2.11.71:8649
保存关闭之后就可以对hadoop集群进行监控了。
注意我这里所有的配置都是针对hadoop的伪分布式模式的,伪分布式模式就是Namenode和datanode都在一台机器上,模拟成分布式。
关于hadoop和Ganglia的配置就讲到这里了,若有地方有问题,最好查阅官方文档。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号