python读取pdf
最近项目上有个需求,就是把一批用户申请表(pdf文件)的内容,写入数据库。由于文件数量较大,需要批量处理。
本来以为很简单的事情,结果却因为pdf文件内容格式问题导致部分内容读不到:
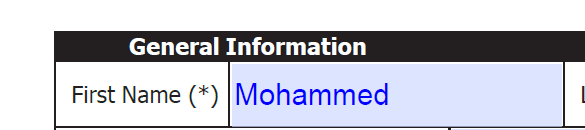
读出内容:First Name (*)
具体的,这种pdf文件是一种表格,需要用户自己填入表格中的一些内容,比如用户姓名。
尝试了各种读取pdf的库,包括pdfminer,pdf2docx,pdfplumber, python-docx,pdf2text,都只能读到表格的固定部分的内容,无法读出用户输入的内容。
使用Adobe Acobat Reader自带的转换为文本功能,发现也是一样。
最后看stackoverflow上说可以用tika这个库试下,居然成功:
First Name: Mohammed
demo code:
from tika import parser # pip install tika
raw = parser.from_file('1.pdf')
print(raw['content'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号