TransE 学习笔记
TransE
paper : Translating Embeddings for Modeling Multi-relational Data
TransE 是由 Antoine Bordes 发表于 2013 年的 NIPS(现 NeurIPS)上的工作,众所周知这篇文章是知识图谱表示学习的开山之作,在之后引爆了 KGE 的热潮。
What is TransE ?
TransE ( Translating Embedding ), an energy-based model for learning low-dimensional embeddings of entities.
核心思想
将 relationship 视为一个在 embedding space 的 translation。如果 ( h , l , t ) 存在,那么:
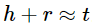
Motivation
-
在 Knowledge Base 中,层次化的关系是非常常见的,translation 是一种很自然的用来表示它们的变换。
-
近期一些学习 word embedding 的研究发现,一些不同类型的实体之间的 1-to-1 的 relationship 可以被模型表示为在 embedding space 中的一种 translation。
TransE
算法过程
TransE的训练算法如下:

输入参数
- Training set : 用于训练的三元组的集合,实体的集合为 E,关系的集合为 L。
- margin : 损失函数中的间隔(这个在原 paper 中描述很模糊)。
- 每个实体或关系的 embedding dim k。
训练过程
初始化
对每一个 entity 和 relation 的 embedding vector 用 xavier_uniform 分布来初始化,然后对它们实施 L1 or L2 正则化。
loop:
-
在 entity embedding 被更新前进行一次归一化,这是通过人为增加 embedding 的 norm 来防止 loss 在训练过程中极小化。
-
采样出一个 mini-batch 的正样本集合
-
将训练集初始化为空集
-
在正样本集合中构造出 negative sample,然后将 positive sample 与 negative sample 都加入到训练集中
-
计算训练集中每一对样本三元组的 Loss, 然后累加起来用于更新 margin matrix, Loss 函数如下:
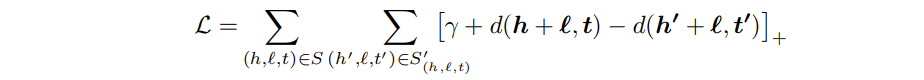
其中距离函数为:
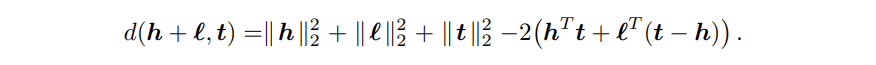
这个过程中,三元组的 energy 就是指的 距离 d, 他衡量了头实体 + 关系与尾实体的距离,可以采用 L1 或 L2 norm。
margin: 它相当于是一个正确 triple 与错误 triple 之前的间隔修正,margin 越大,则两个 triple 之前被修正的间隔就越大,则对于 embedding 的修正就越严格。
错误三元组的构造方法: 将三元组中的头实体、关系和尾实体其中之一随机替换为其他实体或关系来得到。
实验
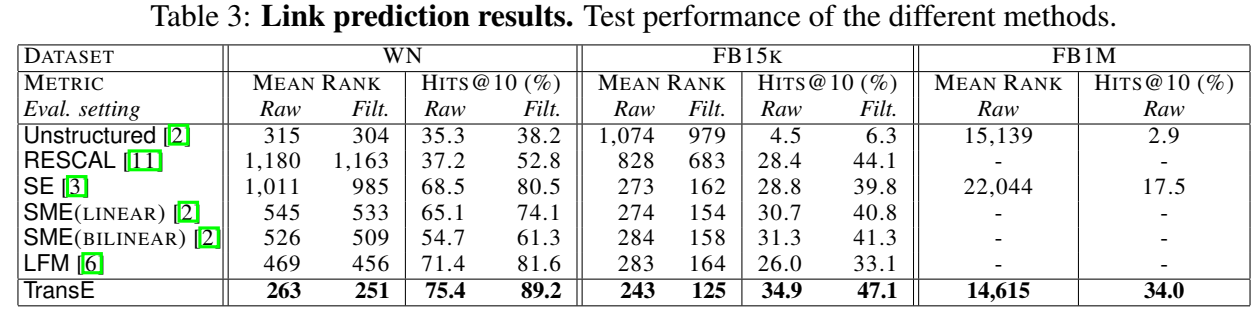
实验进行了 Link Prediction 和尾实体预测的 case study。
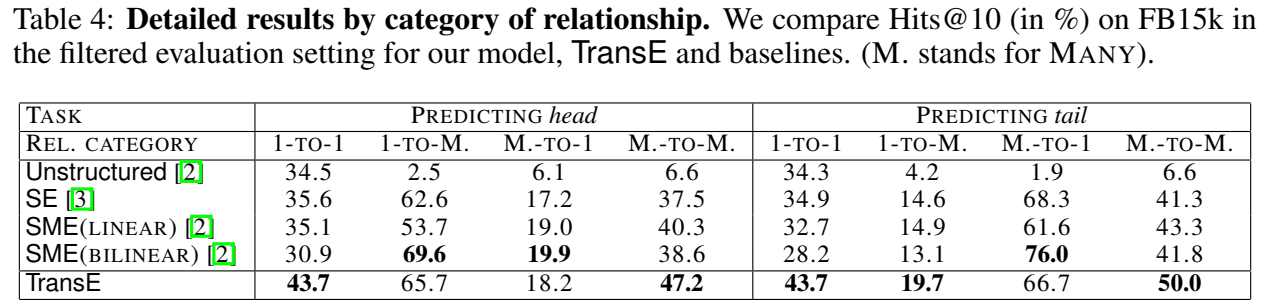
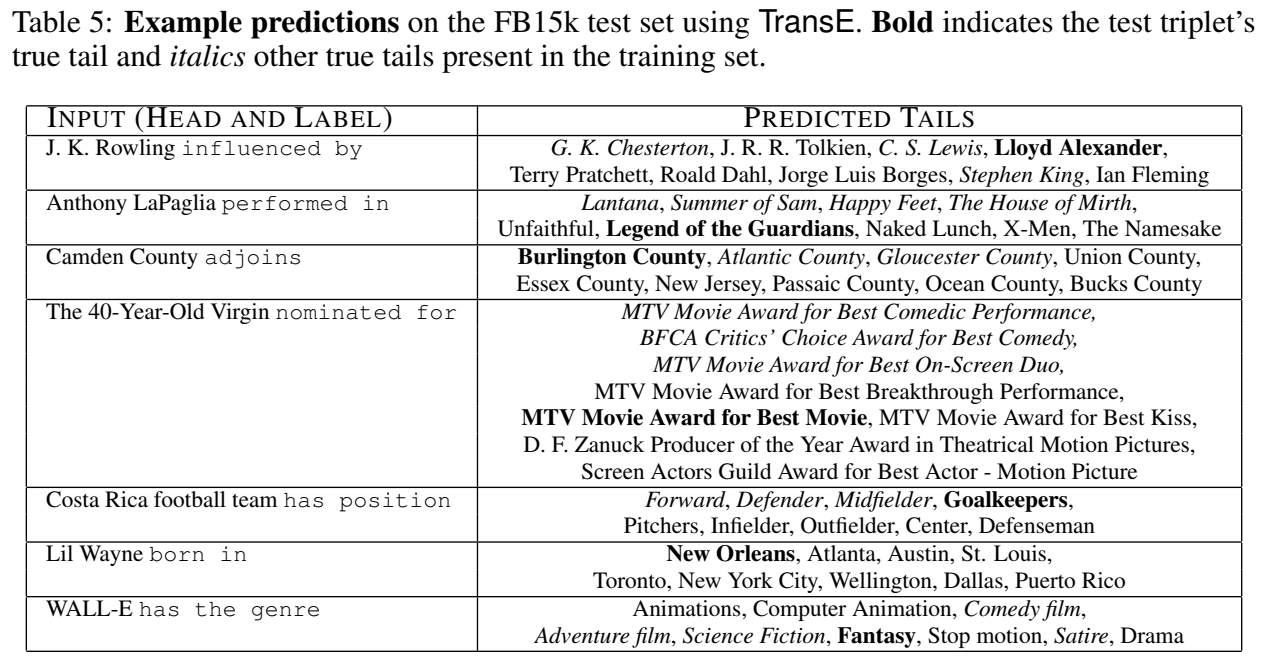
小结
TransE的优点在于与以往模型相比,TransE 模型参数较少,计算复杂度低,却能直接建立实体和关系之间的复杂语义联系,在 WordNet 和 Freebase 等 dataset 上较以往模型的 performance 有了显著提升,特别是在大规模稀疏 KG 上,TransE 的性能尤其惊人。
其缺点在于在处理复杂关系(1-N、N-1 和 N-N)时,性能显著降低。
总的来说,TransE这一经典模型也是知识图谱表示学习的开山之作,值得细品。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号